8.6 Hypothesis Tests for a Population Mean with Known Population Standard Deviation
LEARNING OBJECTIVES
- Conduct and interpret hypothesis tests for a population mean with known population standard deviation.
Some notes about conducting a hypothesis test:
- The null hypothesis [latex]H_0[/latex] is always an “equal to.” The null hypothesis is the original claim about the population parameter.
- The alternative hypothesis [latex]H_a[/latex] is a “less than,” “greater than,” or “not equal to.” The form of the alternative hypothesis depends on the context of the question.
- The form of the alternative hypothesis tell us if the test is left-tail, right-tail, or two-tail. The alternative hypothesis is the key to conducting the test and finding the correct p-value.
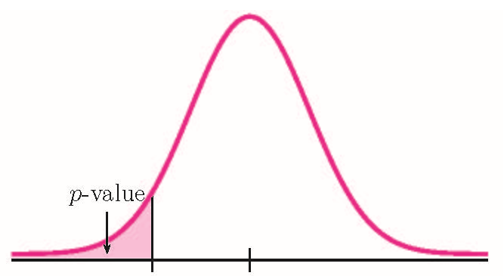
- If the alternative hypothesis is a “less than”, then the test is left-tail. The p-value is the area in the left-tail of the distribution.
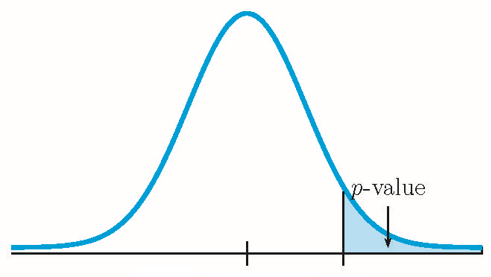
- If the alternative hypothesis is a “greater than”, then the test is right-tail. The p-value is the area in the right-tail of the distribution.
- If the alternative hypothesis is a “not equal to”, then the test is two-tail. The p-value is the sum of the area in the two-tails of the distribution. Each tail represents exactly half of the p-value.
- Think about the meaning of the p-value. A data analyst (and anyone else) should have more confidence that they made the correct decision to reject the null hypothesis with a smaller p-value (for example, 0.001 as opposed to 0.04) even if using a significance level of 0.05. Similarly, for a large p-value such as 0.4, as opposed to a p-value of 0.056 (a significance level of 0.05 is less than either number), a data analyst should have more confidence that they made the correct decision in not rejecting the null hypothesis. This makes the data analyst use judgment rather than mindlessly applying rules.
- The significance level must be identified before collecting the sample data and conducting the test. Generally, the significance level will be included in the question. If no significance level is given, a common standard is to use a significance level of 5%.
- An alternative approach for hypothesis testing is to use what is called the critical value approach. In this book, we will only use the p-value approach. Some of the videos below may mention the critical value approach, but this approach will not be used in this book.
EXAMPLE
Suppose the hypotheses for a hypothesis test are:
[latex]\begin{eqnarray*} H_0: & & \mu=5 \\ H_a: & & \mu \lt 5 \end{eqnarray*}[/latex]
Because the alternative hypothesis is a [latex]\lt[/latex], this is a left-tailed test. The p-value is the area in the left-tail of the distribution.

EXAMPLE
Suppose the hypotheses for a hypothesis test are:
[latex]\begin{eqnarray*} H_0: & & \mu=0.5 \\ H_a: & & \mu \neq 0.5 \end{eqnarray*}[/latex]
Because the alternative hypothesis is a [latex]\neq[/latex], this is a two-tailed test. The p-value is the sum of the areas in the two tails of the distribution. Each tail contains exactly half of the p-value.

EXAMPLE
Suppose the hypotheses for a hypothesis test are:
[latex]\begin{eqnarray*} H_0: & & \mu=10 \\ H_a: & & \mu \lt 10 \end{eqnarray*}[/latex]
Because the alternative hypothesis is a [latex]\lt[/latex], this is a left-tailed test. The p-value is the area in the left-tail of the distribution.

Steps to Conduct a Hypothesis Test for a Population Mean with Known Population Standard Deviation
- Write down the null and alternative hypotheses in terms of the population mean [latex]\mu[/latex]. Include appropriate units with the values of the mean.
- Use the form of the alternative hypothesis to determine if the test is left-tailed, right-tailed, or two-tailed.
- Collect the sample information for the test and identify the significance level [latex]\alpha[/latex].
- When the population standard deviation is known, we use a normal distribution with [latex]\displaystyle{z=\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}}[/latex] to find the p-value. The p-value is the area in the corresponding tail of the normal distribution.
- Compare the p-value to the significance level and state the outcome of the test:
- If p-value[latex]\leq \alpha[/latex], reject [latex]H_0[/latex] in favour of [latex]H_a[/latex].
- The results of the sample data are significant. There is sufficient evidence to conclude that the null hypothesis [latex]H_0[/latex] is an incorrect belief and that the alternative hypothesis [latex]H_a[/latex] is most likely correct.
- If p-value[latex]\gt \alpha[/latex], do not reject [latex]H_0[/latex].
- The results of the sample data are not significant. There is not sufficient evidence to conclude that the alternative hypothesis [latex]H_a[/latex] may be correct.
- If p-value[latex]\leq \alpha[/latex], reject [latex]H_0[/latex] in favour of [latex]H_a[/latex].
- Write down a concluding sentence specific to the context of the question.
USING EXCEL TO CALCULE THE P-VALUE FOR A HYPOTHESIS TEST ON A POPULATION MEAN WITH KNOWN POPULATION STANDARD DEVIATION
The p-value for a hypothesis test on a population mean is the area in the tail(s) of the distribution of the sample mean. When the population standard deviation is known, use the normal distribution to find the p-value.
The p-value is the area in the tail(s) of a normal distribution, so the norm.dist(x,[latex]\mu[/latex],[latex]\sigma[/latex],logic operator) function can be used to calculate the p-value.
- For x, enter the value for [latex]\overline{x}[/latex].
- For [latex]\mu[/latex], enter the mean of the sample means [latex]\mu[/latex]. Note: Because the test is run assuming the null hypothesis is true, the value for [latex]\mu[/latex] is the claim from the null hypothesis.
- For [latex]\sigma[/latex], enter the standard error of the mean [latex]\displaystyle{\frac{\sigma}{\sqrt{n}}}[/latex].
- For the logic operator, enter true. Note: Because we are calculating the area under the curve, we always enter true for the logic operator.
Use the appropriate technique with the norm.dist function to find the area in the left-tail or the area in the right-tail.
EXAMPLE
Jeffrey, as an eight-year old, established a mean time of 16.43 seconds with a standard deviation of 0.8 seconds for swimming the 25-meter freestyle. His dad, Frank, thought that Jeffrey could swim the 25-meter freestyle faster using goggles. Frank bought Jeffrey a new pair of goggles and timed Jeffrey swimming the 25-meter freestyle 15 different times. In the sample of 15 swims, Jeffrey’s mean time was 16 seconds. Frank thought that the goggles helped Jeffrey swim faster than 16.43 seconds. At the 5% significance level, did Jeffrey swim faster wearing the goggles? Assume that the swim times for the 25-meter freestyle are normally distributed.
Solution:
Hypotheses:
[latex]\begin{eqnarray*} H_0: & & \mu=16.43 \mbox{ seconds} \\ H_a: & & \mu \lt 16.43 \mbox{ seconds} \end{eqnarray*}[/latex]
p-value:
From the question, we have [latex]n=15[/latex], [latex]\overline{x}=16[/latex], [latex]\sigma=0.8[/latex] and [latex]\alpha=0.05[/latex].
This is a test on a population mean where the population standard deviation is known ([latex]\sigma=0.8[/latex]). So we use a normal distribution to calculate the p-value. Because the alternative hypothesis is a [latex]\lt[/latex], the p-value is the area in the left-tail of the distribution.
| Function | norm.dist | Answer |
| Field 1 | 16 | 0.0187 |
| Field 2 | 16.43 | |
| Field 3 | 0.8/sqrt(15) | |
| Field 4 | true |
So the p-value[latex]=0.0187[/latex].
Conclusion:
Because p-value[latex]=0.0187 \lt 0.05=\alpha[/latex], we reject the null hypothesis in favour of the alternative hypothesis. At the 5% significance level there is enough evidence to suggest that Jeffrey’s mean swim time with the goggles is less than 16.43 seconds.
NOTES
- The null hypothesis [latex]\mu=16.43[/latex] is the claim that Jeffrey’s mean swim time with the goggles is 16.43 seconds (the same as it is without the googles).
- The alternative hypothesis [latex]\mu \lt 16.43[/latex] is the claim that Jeffrey’s swim time with the goggles is less than 16.43 seconds.
- The p-value is the area in the left tail of the sampling distribution, to the left of [latex]\overline{x}=16[/latex]. In the calculation of the p-value:
- The function is norm.dist because we are finding the area in the left tail of a normal distribution.
- Field 1 is the value of [latex]\overline{x}[/latex]
- Field 2 is the value of [latex]\mu[/latex] from the null hypothesis. Remember, we run the test assuming the null hypothesis is true, so that means we assume [latex]\mu=16.43[/latex].
- Field 3 is the standard deviation for the sample means [latex]\displaystyle{\frac{\sigma}{\sqrt{n}}}[/latex]. Note that we are not using the standard deviation from the population ([latex]\sigma=0.8[/latex]). This is because the p-value is the area under the curve of the distribution of the sample means, not the distribution of the population.
- The p-value of 0.0187 tells us that under the assumption that Jeffrey’s mean swim time with goggles is 16.43 seconds (the null hypothesis), there is only a 1.87% chance that the mean time for the 15 sample swims is 16 seconds or less. This is a small probability, and so is unlikely to happen assuming the null hypothesis is true. This suggests that the assumption that the null hypothesis is true is most likely incorrect, and so the conclusion of the test is to reject the null hypothesis in favour of the alternative hypothesis.
- The Type I error for this problem is to conclude that Jeffrey swims the 25-meter freestyle, on average, in less than 16.43 seconds (the alternative hypothesis) when, in fact, he actually swims the 25-meter freestyle, on average, in 16.43 seconds (the null hypothesis). That is, reject the null hypothesis when the null hypothesis is actually true.
- The Type II error for this problem is to conclude that Jeffrey swims the 25-meter freestyle, on average, in 16.43 seconds (the null hypothesis) when, in fact, he actually swims the 25-meter freestyle, on average, in less than 16.43 seconds (the alternative hypothesis). That is, do not reject the null hypothesis when the null hypothesis is actually false.
TRY IT
The mean throwing distance of a football for Marco, a high school freshman quarterback, is 40 yards with a standard deviation of 2 yards. The team coach tells Marco to adjust his grip to get more distance. The coach records the distances for 20 throws with the new grip. For the 20 throws, Marco’s mean distance was 41.5 yards. The coach thought the different grip helped Marco throw farther than 40 yards. At the 5% significance level, is Marco’s mean throwing distance higher with the new grip? Assume the throw distances for footballs are normally distributed.
Click to see Solution
Hypotheses:
[latex]\begin{eqnarray*} H_0: & & \mu=40 \mbox{ yards} \\ H_a: & & \mu \gt 40 \mbox{ yards} \end{eqnarray*}[/latex]
p-value:
From the question, we have [latex]n=20[/latex], [latex]\overline{x}=41.5[/latex], [latex]\sigma=2[/latex] and [latex]\alpha=0.05[/latex].
This is a test on a population mean where the population standard deviation is known ([latex]\sigma=2[/latex]). So we use a normal distribution to calculate the p-value. Because the alternative hypothesis is a [latex]\gt[/latex], the p-value is the area in the right-tail of the distribution.
| Function | 1-norm.dist | Answer |
| Field 1 | 41.5 | 0.0004 |
| Field 2 | 40 | |
| Field 3 | 2/sqrt(20) | |
| Field 4 | true |
So the p-value[latex]=0.0004[/latex].
Conclusion:
Because p-value[latex]=0.0004 \lt 0.05=\alpha[/latex], we reject the null hypothesis in favour of the alternative hypothesis. At the 5% significance level there is enough evidence to suggest that Marco’s mean throwing distance is greater than 40 yards with the new grip.
NOTES
- The null hypothesis [latex]\mu=40[/latex] is the claim that Marco’s mean throwing distance with the new grip is 40 yards (the same as it is without the new grip).
- The alternative hypothesis [latex]\mu \gt 40[/latex] is the claim that Marco’s mean throwing distance with the new grip is greater than 40 yards.
- The p-value is the area in the right tail of the normal distribution. To calculate the area in the right-tail of a normal distribution, we use 1-norm.dist.
- Field 1 is the value of [latex]\overline{x}[/latex]
- Field 2 is the value of [latex]\mu[/latex] from the null hypothesis.
- Field 3 is the standard deviation for the sample means [latex]\displaystyle{\frac{\sigma}{\sqrt{n}}}[/latex].
- The p-value of 0.0004 tells us that under the assumption that Marco’s mean throwing distance with the new grip is 40 yards, there is only a 0.047% chance that the mean throwing distance for the 20 sample throws is more than 40 yards. This is a small probability, and so is unlikely to happen assuming the null hypothesis is true. This suggests that the assumption that the null hypothesis is true is most likely incorrect, and so the conclusion of the test is to reject the null hypothesis in favour of the alternative hypothesis.
EXAMPLE
A local college states in its marketing materials that the average age of its first-year students is 18.3 years with a standard deviation of 3.4 years. But this information is based on old data and does not take into account that more older adults are returning to college. A researcher at the college believes that the average age of its first-year students has changed. The researcher takes a sample of 50 first-year students and finds the average age is 19.5 years. At the 1% significance level, has the average age of the college’s first-year students changed?
Solution:
Hypotheses:
[latex]\begin{eqnarray*} H_0: & & \mu=18.3 \mbox{ years} \\ H_a: & & \mu \neq 18.3 \mbox{ years} \end{eqnarray*}[/latex]
p-value:
From the question, we have [latex]n=50[/latex], [latex]\overline{x}=19.5[/latex], [latex]\sigma=3.4[/latex] and [latex]\alpha=0.01[/latex].
This is a test on a population mean where the population standard deviation is known ([latex]\sigma=3.4[/latex]). In this case, the sample size is greater than 30. So we use a normal distribution to calculate the p-value. Because the alternative hypothesis is a [latex]\neq[/latex], the p-value is the sum of area in the tails of the distribution.

Because there is only one sample, we only have information relating to one of the two tails, either the left tail or the right tail. We need to know if the sample relates to the left tail or right tail because that will determine how we calculate out the area of that tail using the normal distribution. In this case, the sample mean [latex]\overline{x}=19.5[/latex] is greater than the value of the population mean in the null hypothesis [latex]\mu=18.3[/latex] ([latex]\overline{x}=19.5>18.3=\mu[/latex]), so the sample information relates to the right-tail of the normal distribution. This means that we will calculate out the area in the right tail using 1-norm.dist. However, this is a two-tailed test where the p-value is the sum of the area in the two tails and the area in the right-tail is only one half of the p-value. The area in the left tail equals the area in the right tail and the p-value is the sum of these two areas.
| Function | 1-norm.dist | Answer |
| Field 1 | 19.5 | 0.0063 |
| Field 2 | 18.3 | |
| Field 3 | 3.4/sqrt(50) | |
| Field 4 | true |
So the area in the right tail is 0.0063 and [latex]\frac{1}{2}[/latex](p-value)[latex]=0.0063[/latex]. This is also the area in the left tail, so
p-value[latex]=0.0063+0.0063=0.0126[/latex]
Conclusion:
Because p-value[latex]=0.0126 \gt 0.01=\alpha[/latex], we do not reject the null hypothesis. At the 1% significance level there is not enough evidence to suggest that the average age of the college’s first-year students has changed.
NOTES
- The null hypothesis [latex]\mu=18.3[/latex] is the claim that the average age of the first-year students is still 18.3 years.
- The alternative hypothesis [latex]\mu \neq 18.3[/latex] is the claim that the average age of the first-year students has changed from 18.3 years.
- In a two-tailed hypothesis test that uses the normal distribution, we will only have sample information relating to one of the two tails. We must determine which of the tails the sample information belongs to, and then calculate out the area in that tail. The area in each tail represents exactly half of the p-value, so the p-value is the sum of the areas in the two tails.
- If the sample mean [latex]\overline{x}[/latex] is less than the population mean [latex]\mu[/latex] in the null hypothesis ([latex]\overline{x} \lt \mu[/latex]), then the sample information belongs to the left tail.
- We use norm.dist([latex]\overline{x}[/latex],[latex]\mu[/latex],[latex]\sigma/\mbox{sqrt}(n)[/latex],true) to find the area in the left tail. The area in the right tail equals the area in the left tail, so we can find the p-value by adding the output from this function to itself.
- If the sample mean [latex]\overline{x}[/latex] is greater than the population mean [latex]\mu[/latex] in the null hypothesis ([latex]\overline{x} \gt \mu[/latex]), then the sample information belongs to the right tail.
- We use 1-norm.dist([latex]\overline{x}[/latex],[latex]\mu[/latex],[latex]\sigma/\mbox{sqrt}(n)[/latex],true) to find the area in the right tail. The area in the left tail equals the area in the right tail, so we can find the p-value by adding the output from this function to itself.
- If the sample mean [latex]\overline{x}[/latex] is less than the population mean [latex]\mu[/latex] in the null hypothesis ([latex]\overline{x} \lt \mu[/latex]), then the sample information belongs to the left tail.
- The p-value of 0.0126 is a large probability compared to the 1% significance level, and so is likely to happen assuming the null hypothesis is true. This suggests that the assumption that the null hypothesis is true is most likely correct, and so the conclusion of the test is to not reject the null hypothesis. In other words, the claim that the average age of first-year students is 18.3 years is most likely correct.
Watch this video: Hypothesis Testing: z-test, right tail by ExcelIsFun [33:47]
Watch this video: Hypothesis Testing: z-test, left tail by ExcelIsFun [10:57]
Watch this video: Hypothesis Testing: z-test, two tail by ExcelIsFun [9:56]
Concept Review
The hypothesis test for a population mean is a well established process:
- Write down the null and alternative hypotheses in terms of the population mean [latex]\mu[/latex]. Include appropriate units with the values of the mean.
- Use the form of the alternative hypothesis to determine if the test is left-tailed, right-tailed, or two-tailed.
- Collect the sample information for the test and identify the significance level.
- When the population standard deviation is known, find the p-value (the area in the corresponding tail) for the test using the normal distribution.
- Compare the p-value to the significance level and state the outcome of the test.
- Write down a concluding sentence specific to the context of the question.
Attribution
“9.6 Hypothesis Testing of a Single Mean and Single Proportion“ in Introductory Statistics by OpenStax is licensed under a Creative Commons Attribution 4.0 International License.
