Sensitivity Analysis
- Relative error analysis
- Condition number
We consider the OLS problem:
![\[\min _x\|A x-y\|_2\]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f445eb139d8919dd47278d7531bc7be5_l3.png "Rendered by QuickLaTeX.com")
with
 the data matrix (known);
the data matrix (known); is the measurement (known);
is the measurement (known); is the vector to be estimated (unknown).
is the vector to be estimated (unknown).
We assume that  is full column rank. Then, the solution
is full column rank. Then, the solution  to the OLS problem is unique, and can be written as a linear function of the measurement vector
to the OLS problem is unique, and can be written as a linear function of the measurement vector  :
:

with 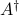 the pseudo-inverse of . Again, since is full column rank,
the pseudo-inverse of . Again, since is full column rank,

We are interested in analyzing the impact of perturbations in the vector , on the resulting solution  . We begin by analyzing the absolute errors in the estimate and then turn to the analysis of relative errors.
. We begin by analyzing the absolute errors in the estimate and then turn to the analysis of relative errors.
Bound on the absolute error
We first try to find a bound on the error in the solution given a bound on the error in the input. Let us assume a simple model of potential perturbations: we assume that  belongs to a unit ball:
belongs to a unit ball:  , where
, where  is given. We will assume
is given. We will assume  for simplicity; the analysis is easily extended to any .
for simplicity; the analysis is easily extended to any .
Let us define  to be the estimate corresponding to the measurement
to be the estimate corresponding to the measurement  , that is:
, that is:

Since  , we have
, we have

We obtain that

where  is the matrix norm, which is defined for a matrix
is the matrix norm, which is defined for a matrix  as
as

In other words,  is simply the maximum output norm that we can attain with a unit-norm input. (The matrix norm can be computed from an SVD of the matrix .)
is simply the maximum output norm that we can attain with a unit-norm input. (The matrix norm can be computed from an SVD of the matrix .)
The interpretation is that  is the largest absolute error that can result from an absolute error in the input that is bounded by
is the largest absolute error that can result from an absolute error in the input that is bounded by  .
.
Bound on the relative error analysis
We now turn to the problem of analyzing the impact of relative errors in the measurement, on the relative error in the solution.
To simplify, let us assume that the matrix is square ( ) and full rank (invertible). The development before simplifies to
) and full rank (invertible). The development before simplifies to

so that

Likewise, the equation  allows to bound
allows to bound  with respect to
with respect to  :
:

Combining the two inequalities we obtain:

Condition number
As seen above, when is square and invertible, the quantity

measures the sensitivity to relative errors in the system  .
.
The quantity above is called the condition number of . The condition number is always greater than . The closer to , the more confident we can be about the solution  when is subject to small relative errors. We can generalize this notion to non-necessarily square matrices that have full rank.
when is subject to small relative errors. We can generalize this notion to non-necessarily square matrices that have full rank.
Many practical algorithms to solve linear equations (or OLS) use the condition number (or an estimate) to evaluate the quality of the solution.