Principal Component Analysis
- Projection on a line via variance maximization
- Principal component analysis
- Explained variance
Projection on a line via variance maximization
Consider a data set of  points
points  ,
,  in
in  . We can represent this data set as a
. We can represent this data set as a  matrix
matrix ![X = [x_1, \cdots, x_n]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a7b88dd9bcb896b3b6dfa52866eede46_l3.png "Rendered by QuickLaTeX.com") , where each is a -vector. The variance maximization problem is to find a direction
, where each is a -vector. The variance maximization problem is to find a direction  such that the sample variance of the corresponding vector
such that the sample variance of the corresponding vector  is maximal.
is maximal.
Recall that when  is normalized, the scalar
is normalized, the scalar  is the component of
is the component of  along , that is, it corresponds to the projection of on the line passing through
along , that is, it corresponds to the projection of on the line passing through  and with direction .
and with direction .
Here, we seek a (normalized) direction such that the empirical variance of the projected values  , , is large. If
, , is large. If  is the vector of averages of the ‘s, then the average of the projected values is
is the vector of averages of the ‘s, then the average of the projected values is  . Thus, the direction of maximal variance is one that solves the optimization problem
. Thus, the direction of maximal variance is one that solves the optimization problem

The above problem can be formulated as

where

is the  sample covariance matrix of the data.
sample covariance matrix of the data.
We have seen the above problem before, under the name of the Rayleigh quotient of a symmetric matrix. Solving the problem entails simply finding an eigenvector of the covariance matrix  that corresponds to the largest eigenvalue.
that corresponds to the largest eigenvalue.
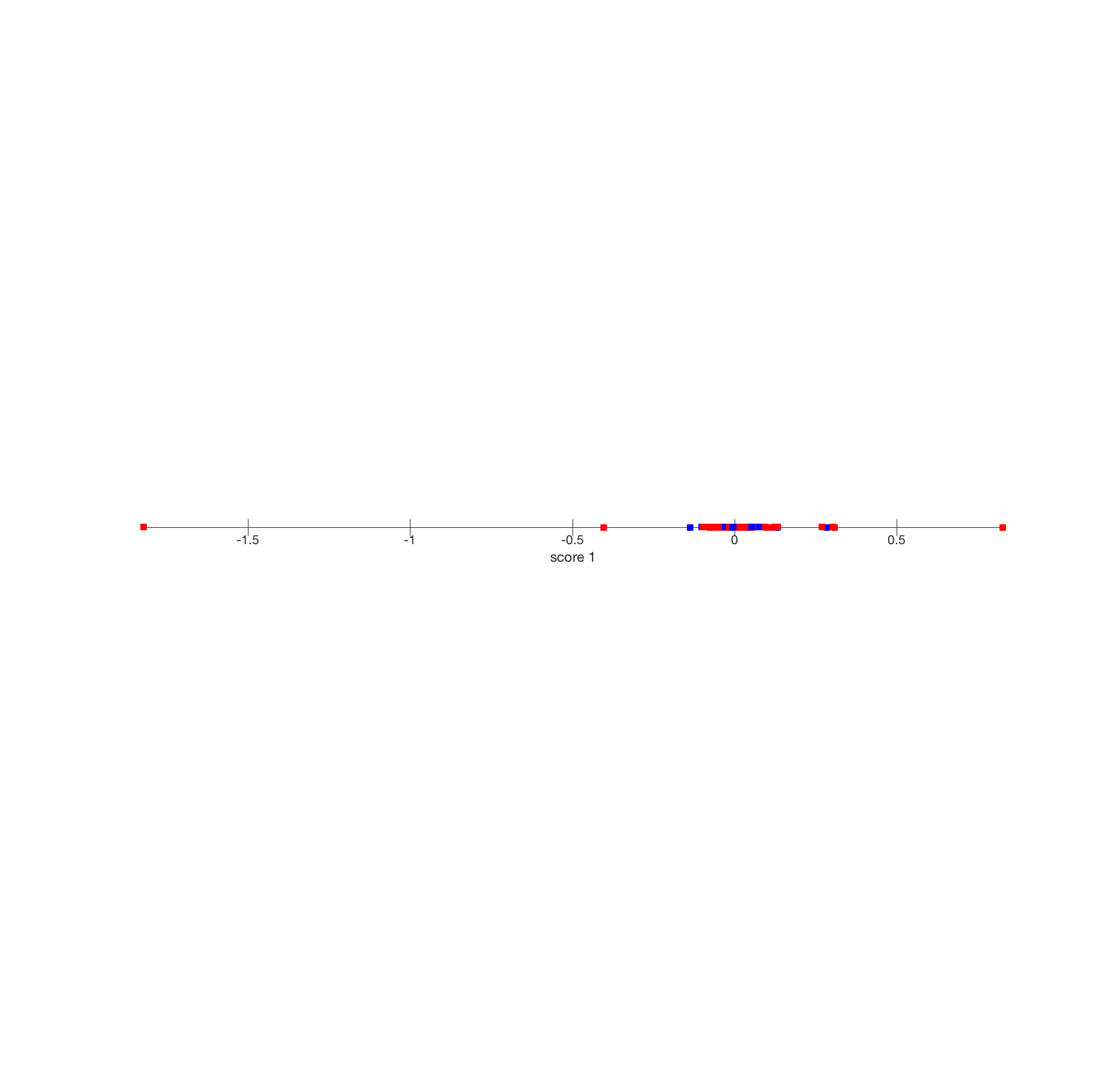
 |
Maximal variance direction for the Senate voting data. This image shows the scores assigned to each Senator along the direction of maximal variance,  , , with , , with  a normalized eigenvector corresponding to the largest eigenvalue of the covariance matrix . Republican Senators tend to score negatively, while we find many Democrats on the positive score (obviously the sign themselves don’t count here, as we could switch to a normalized eigenvector corresponding to the largest eigenvalue of the covariance matrix . Republican Senators tend to score negatively, while we find many Democrats on the positive score (obviously the sign themselves don’t count here, as we could switch to  ; only the order is important). Hence the direction could be interpreted as revealing the party affiliation. The two Senators that are in the opposite group (especially Sen. Chaffee) have indeed sometimes voted against their party. ; only the order is important). Hence the direction could be interpreted as revealing the party affiliation. The two Senators that are in the opposite group (especially Sen. Chaffee) have indeed sometimes voted against their party.Note that the largest absolute score obtained in this plot is about 18 times bigger than that observed on the projection on a random direction. This is consistent with the fact that the current direction has a maximal variance. |
{kind=link}
Principal component analysis
Main idea
The main idea behind principal component analysis is to first find a direction that corresponds to maximal variance between the data points. The data is then projected on the hyperplane orthogonal to that direction. We obtain a new data set and find a new direction of maximal variance. We may stop the process when we have collected enough directions (say, three if we want to visualize the data in 3D).
It turns out that the directions found in this way are precisely the eigenvectors of the data’s covariance matrix. The term principal components refers to the directions given by these eigenvectors. Mathematically, the process thus amounts to finding the eigenvalue decomposition of a positive semi-definite matrix, the covariance matrix of the data points.
Projection on a plane
The projection to use to obtain, say, a two-dimensional view with the largest variance, is of the form  , where
, where ![P=[u_1, u_2]^T](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-33198b1cc2cc0c0d8902a4462b528a33_l3.png "Rendered by QuickLaTeX.com") is a matrix that contains the eigenvectors corresponding the first two eigenvalues.
is a matrix that contains the eigenvectors corresponding the first two eigenvalues.
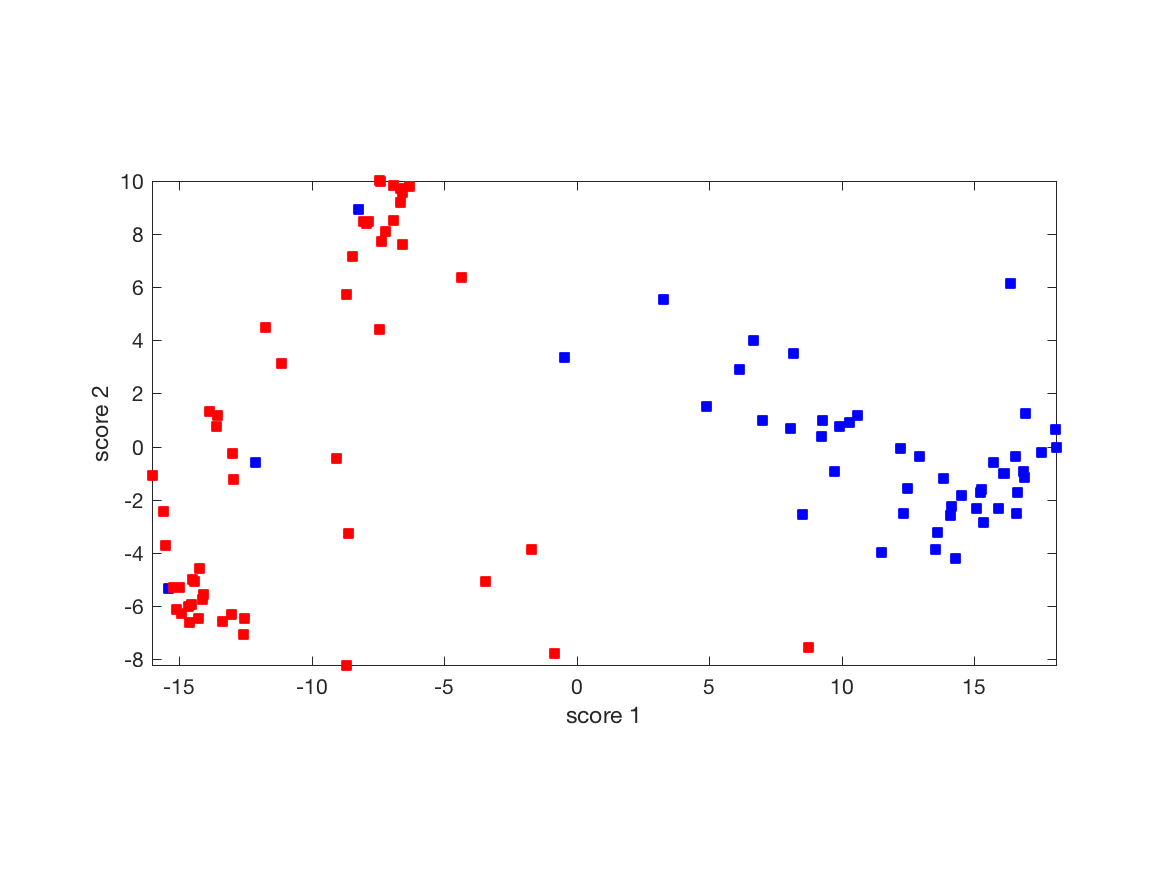 |
Two-dimensional projection of the Senate voting matrix: This particular planar projection uses the two eigenvectors corresponding to the largest two eigenvalues of the data’s covariance matrix. It seems to allow to cluster of the Senators along party lines and is therefore more informative than, say, the plane corresponding to the two smallest eigenvalues. |
{kind=link}
Explained variance
The total variance in the data is defined as the sum of the variances of the individual components. This quantity is simply the trace of the covariance matrix since the diagonal elements of the latter contain the variances. If has the EVD  , where
, where  contains the eigenvalues, and
contains the eigenvalues, and  an orthogonal matrix of eigenvectors, then to total variance can be expressed as the sum of all the eigenvalues:
an orthogonal matrix of eigenvectors, then to total variance can be expressed as the sum of all the eigenvalues:

When we project the data on a two-dimensional plane corresponding to the eigenvectors  associated with the two largest eigenvalues
associated with the two largest eigenvalues  , we get a new covariance matrix
, we get a new covariance matrix  , where
, where ![P = [u_1. u_2]^T](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-0425ba2f788ff0c768baac812d990cf6_l3.png "Rendered by QuickLaTeX.com") the total variance of the projected data is
the total variance of the projected data is

Hence, we can define the ratio of variance ‘‘explained’’ by the projected data as the ratio:

If the ratio is high, we can say that much of the variation in the data can be observed on the projected plane.
 |
This image shows the eigenvalues of the covariance matrix of the Senate voting data, which contains the covariances between the votes of each pair of Senators. Clearly, the eigenvalues decrease very fast. One is tempted to say that In this case, the ratio of explained to total variance is almost  , which indicates that ‘‘most of the information’’ is contained in the first eigenvalue. Since the corresponding eigenvector almost corresponds to a perfect ‘‘party line’’, we can say that party affiliation explains most of the variance in the Senate voting data. , which indicates that ‘‘most of the information’’ is contained in the first eigenvalue. Since the corresponding eigenvector almost corresponds to a perfect ‘‘party line’’, we can say that party affiliation explains most of the variance in the Senate voting data. |