Linear Functions
- Linear and affine functions
- First-order approximation of non-linear functions
- Other sources of linear models
Linear and affine functions
Definition
Linear functions are functions which preserve scaling and addition of the input argument. Affine functions are ‘‘linear plus constant’’ functions.
Formal definition, linear and affine functions. A function  is linear if and only if
is linear if and only if  preserves scaling and addition of its arguments:
preserves scaling and addition of its arguments:
- for every
 , and
, and  ,
,  ; and
; and - for every
 ,
,  .
.
A function is affine if and only if the function  with values
with values  is linear.
is linear. 
An alternative characterization of linear functions is given here.
Examples: Consider the functions  with values
with values
 ,
, ,
, .
.
The function  is linear;
is linear;  is affine; and
is affine; and  is neither.
is neither.
Connection with vectors via the scalar product
The following shows the connection between linear functions and scalar products.
A function is affine if and only if it can be expressed via a scalar product:

for some unique pair  , with
, with  and
and  , given by
, given by  , with
, with  the
the  -th unit vector in
-th unit vector in  ,
,  , and
, and  . The function is linear if and only if
. The function is linear if and only if  .
.
The theorem shows that a vector can be seen as a (linear) function from the ‘‘input“ space to the ‘‘output” space  . Both points of view (matrices as simple collections of numbers, or as linear functions) are useful.
. Both points of view (matrices as simple collections of numbers, or as linear functions) are useful.
Gradient of an affine function
The gradient of a function at a point  , denoted
, denoted  , is the vector of first derivatives with respect to
, is the vector of first derivatives with respect to  (see here for a formal definition and examples). When
(see here for a formal definition and examples). When  (there is only one input variable), the gradient is simply the derivative.
(there is only one input variable), the gradient is simply the derivative.
An affine function , with values  has a very simple gradient: the constant vector
has a very simple gradient: the constant vector  . That is, for an affine function , we have for every :
. That is, for an affine function , we have for every :

Example: gradient of a linear function.
Interpretations
The interpretation of  are as follows.
are as follows.
- The is the constant term. For this reason, it is sometimes referred to as the bias, or intercept (as it is the point where intercepts the vertical axis if we were to plot the graph of the function).
- The terms
 ,
,  , which correspond to the gradient of , give the coefficients of influence of
, which correspond to the gradient of , give the coefficients of influence of  on
on 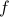 . For example, if
. For example, if  , then the first component of has much greater influence on the value of
, then the first component of has much greater influence on the value of  than the third.
than the third.
Example: Beer-Lambert law in absorption spectrometry.
First-order approximation of non-linear functions
Many functions are non-linear. A common engineering practice is to approximate a given non-linear map with a linear (or affine) one, by taking derivatives. This is the main reason for linearity to be such a ubiquitous tool in Engineering.
One-dimensional case
Consider a function of one variable  , and assume it is differentiable everywhere. Then we can approximate the values function at a point
, and assume it is differentiable everywhere. Then we can approximate the values function at a point  near a point
near a point 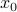 as follows:
as follows:

where  denotes the derivative of at .
denotes the derivative of at .
Multi-dimensional case
With more than one variable, we have a similar result. Let us approximate a differentiable function by a linear function  , so that and coincide up and including to the first derivatives. The corresponding approximation is called the first-order approximation to at
, so that and coincide up and including to the first derivatives. The corresponding approximation is called the first-order approximation to at  .
.
The approximate function must be of the form

where and . Our condition that coincides with up and including to the first derivatives shows that we must have

where  the gradient, of at . Solving for we obtain the following result:
the gradient, of at . Solving for we obtain the following result:
The first-order approximation of a differentiable function at a point is of the form

where  is the gradient of at .
is the gradient of at .
Example: a linear approximation to a non-linear function.
Other sources of linear models
Linearity can arise from a simple change of variables. This is best illustrated with a specific example.
Example: Power laws.