[In progress] Chapter 13: Psycholinguistics and Neurolinguistics
13.2 Evidence for phonemes as mental categories
In Chapter 4, you learned that every human language has a phonology, but that the phonology of each language is distinct. For example, two sounds that are allophones of a single phoneme in one language might be separate phonemes in another language. The conclusion that we reach, then, is that each language has its own way of organizing speech sounds into a phonological system. This system is part of the mental grammar of a speaker of that language. In this section, we will examine some evidence from psycholinguistic and neurolinguistic experiments that provide further support for phonology as something that the mind and brain do.
Chapter 4 defined a phoneme as the smallest unit in a language that can create contrast, such that exchanging one phoneme for another can create a minimal pair. The English words pat (/pæt/) and bat (/bæt/) differ only in the initial phoneme (/p/ or /b/), but have different meanings. This makes them a minimal pair, and the fact that we can make a minimal pair shows us that /p/ and /b/ are separate phonemes in English. Another way of thinking about phonemes is to say that a phoneme is a mental category of speech sounds (signed languages also have categories that permit variation, so this isn’t something special about spoken language). It was also noted in Chapter 4 that English voiceless stops like /p/ are produced with aspiration (written [pʰ]) at the beginning of a stressed syllable. But the difference between an aspirated and unaspirated voiceless bilabial stop ([pʰ] vs. [p]) cannot create contrast in English. This is because [pʰ] and [p] are two variants of a single phoneme. When a speaker of English hears either [pʰ] or [p], the mind of that speaker maps the sound onto the same category /p/. Of course there are many other languages that treat [pʰ] and [p] as separate phonemes, for example Hindi and Thai.
We can make conclusions about the categories a speaker of a given language has in their mind by doing phonological analysis. We can look for minimal pairs, for example, or try to characterize the phonological environments in which a given speech sound appears. But in this chapter we are exploring the idea that these categories are exist in the mind and brain of a speaker. We might ask then, can we find evidence that our brains map sounds to the category they belong to. In other words, we might ask whether our brains treat sounds that vary a little bit in their acoustic qualities as the same, because they are examples of one phoneme.
One group of researchers (Phillips et al., 2000) looked for this kind of evidence by examining whether our brains show a ‘surprise’ response to a new sound that is in a different phonological category to the others.
How to be a linguist: The use of electro/magneto-encephalography in linguistics
You have likely seen visual representations of electroencephalographic (EEG) recordings in medical or scientific settings. These look like wavy lines and are recordings of electrical activity from electrodes placed on the surface of the scalp. The overall character of the wavy lines varies depending on a number of factors, for example whether the person whose scalp is being recorded is awake, asleep, or having a neurological problem like a seizure. Psycholinguists, however, are typically interested not in these overall differences but in very small changes in the electrical field generated by the brain in response to a stimulus. These are called Event-Related Potentials, or ERPs. To compare ERPs to different stimuli, researchers must typically collect a number of responses from one participant, and collect responses from a number of participants. In the end, an average response to a stimulus might look something like the following:
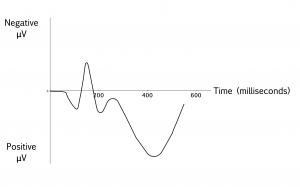
Notice that in this diagram, negative electrical potentials are plotted up; this is merely a convention in this type of research. The horizontal axis represents time, beginning at the time the stimulus is presented to participants.
Several decades of research into Event-Related Potentials have shown that there are characteristic brain responses to, for example, seeing a printed word on a computer screen or hearing a spoken word of a vocal language. Researchers have shown that ERPs are sensitive to, for example, whether a word is expected versus unexpected in a sentence (see e.g., DeLong, Urbach and Kutas 2005), or when it is an ungrammatical continuation of a sentence versus a grammatical continuation (see e.g., Friederici, Hahne and Mecklinger, 1996), etc.
ERPs are a useful source of information to psycho- and neurolinguists because they record the brain’s activity with high temporal resolution: they record the brain’s responses as they are happening with timing accurate down to the millisecond. However, although differences in ERPs can be found at different electrode locations on the scalp, typical ERP studies cannot tell us very much about where in the brain the critical response is happening. In other words, its spatial resolution is poor.
Another method that, like EEG, has excellent temporal resolution is magnetoencephalography (MEG). This method examines changes in the magnetic field generated by the brain (which is of course related to the electrical field). The main advantage of MEG over EEG is that MEG allows researchers to draw better conclusions about where in the brain the response of interest originated.
Previous research in ERPs had shown that there is a measurable brain response to auditory stimuli (sounds) that stand out from the rest. For example, if you have people listen to tones, where most of the tones have an identical frequency but a small proportion have a different frequency, the tones in the minority are associated with a specific brain reaction that gets called the Mismatch Negativity: Mismatch because the tone mismatches what is normally heard, and negativity because the measured brain reaction is a negative-going wave in the measured electrical signal. The Mismatch Negativity can be measured even if a person is not really paying attention to the sounds, for example if they are watching a silent movie during the experiment (see Näätänen and Kreegipuu, 2012 for a review findings regarding the Mismatch Negativity).
Using magnetoencephalography (MEG), Phillips and colleagues (2000) asked whether presenting stimuli that had the structure in terms of phonological category, but importantly not in terms of a mere acoustic difference, would elicit the MEG version of the Mismatch Negativity, called the Mismatch Field. The specific contrast they examined was a voicing contrast – whether a sound would be categorized as /dæ/ or /tæ/. The difference between these two comes down to a difference in the time between the release of the stop consonant and the beginning of voicing the vowel, or the Voice Onset Time. Critically, speakers of English perceive a /t/ sound when Voice Onset time is above about 25ms, and a /d/ sound when it is below – the switch is sharp rather than gradual. But within those categories, the millisecond value of VOT can vary. Take a look at this figure. Each dot represents one syllable sound, with the vertical axis representing Voice Onset Time. You can see that there is a variety of Voice Onset Times in the diagram. None of them would stand out in particular if we hadn’t marked the perceptual boundary between /ta/ and /da/ with a dotted line. The green dots represent sounds that would be identified as /ta/ and the blue dots as /da/. This diagram shows that the important many-to-one relationship isn’t there when considering acoustic values only. But from a phonological point of view, there are a lot of sounds in the /d/ category and only a couple in the /t/ category.
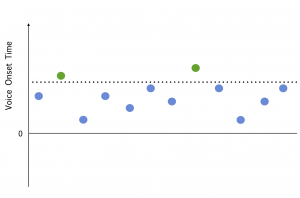
By presenting their participants with sounds that varied in their millisecond value of VOT, but where only a small subset crossed the boundary to be perceived as /t/, Phillips et al. were able to test whether a mismatch effect would occur at the phonological level. This is because the critical many-to-one relationship that leads to a Mismatch Negativity only existed at the phonological level, not at a purely acoustic level. Phillips et al. found a phonological Mismatch Negativity, and they further showed that this effect originated in a part of the brain that processes auditory information. The fact that the Mismatch Negativity was present in this part of the brain shows that the brain processes phonological contrasts quite ‘early’ in perceptual processing, before other brain areas more typically associated with language processing get involved.
References
DeLong, K. A., Urbach, T. P., & Kutas, M. (2005). Probabilistic word pre-activation during language comprehension inferred from electrical brain activity. Nature Neuroscience, 8(8), 1117–1121. https://doi.org/10.1038/nn1504
Friederici, A. D., Hahne, A., & Mecklinger, A. (1996). Temporal structure of syntactic parsing: Early and late event-related brain potential effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22(5), 1219–1248. https://doi.org/10.1037/0278-7393.22.5.1219
Näätänen, R., & Kreegipuu, K. (2011). The Mismatch Negativity (MMN). Oxford University Press. https://doi.org/10.1093/oxfordhb/9780195374148.013.0081
Phillips, C., Pellathy, T., Marantz, A., Yellin, E., Wexler, K., Poeppel, D., McGinnis, M., & Roberts, T. (2000). Auditory Cortex Accesses Phonological Categories: An MEG Mismatch Study. Journal of Cognitive Neuroscience, 12(6), 1038–1055.
