Chapter 4: Phonology
4.6 Another example of phonemic analysis
More than two phones of interest
The Georgian case is a pretty straightforward example, with only two phones of interest that have fairly clear distributions and phonetic similarity. However, we often encounter more difficult cases, maybe because there are many phones of interest or because the distributions and/or phonetic similarity may be less clear.
Consider the following data for how some speakers pronounce French (a Western Romance language of the Indo-European family, spoken in France and elsewhere in the world; data adapted from Katamba 1989). The phones of interest are the voiced sonorants [m], [l], and [ʀ] and the voiceless sonorants [m̥], [l̥], and [ʀ̥]. Note that [ʀ] represents a voiced uvular trill and the ring diacritic [ ̥ ] under a symbol indicates that the phone is voiceless rather than voiced.
| [ʀym] | ‘cold/flu’ | [il] | ‘island’ |
| [mɛʀ] | ‘mother’ | [tabl] | ‘table’ |
| [tɛʀm] | ‘term’ | [kasabl] | ‘breakable’ |
| [film] | ‘film’ | [ɛl] | ‘she’ |
| [limite] | ‘limited’ | [klemã] | ‘merciful’ |
| [liʀ] | ‘to read’ | [simetʀikmã] | ‘symmetrically’ |
| [lɛvʀ] | ‘lip’ | [ɛtʀ̥] | ‘to be’ |
| [plɛziʀ] | ‘pleasure’ | [ʃifʀ̥] | ‘number/figure’ |
| [tʀivjal] | ‘trivial’ | [mɛtʀ̥] | ‘to put’ |
| [ʀali] | ‘race-meeting’ | [mɛkɔnɛtʀ̥] | ‘to fail to recognize’ |
| [ʀymatismal] | ‘rheumatic’ | [pœpl̥] | ‘people’ |
| [ʀɔ̃fle] | ‘to snore’ | [ɔ̃kl̥] | ‘uncle’ |
| [ekʀiʀ] | ‘to write’ | [tãpl̥] | ‘temple’ |
| [tɔʀdʀ] | ‘to wring’ | [ʀitm̥] | ‘rhythm’ |
| [pɛʀs] | ‘Persian’ | [ʀymatism̥] | ‘rheumatism’ |
Now we just follow the same steps we did for Georgian.
Step 1: Identify and organize the phones of interest
Here, we have a lot of data to sort through, and six phones to consider. But the phones neatly separate into either three pairs ([m]-[m̥], [l]-[l̥], and [ʀ]-[ʀ̥]) or two triplets ([m]-[l]-[ʀ] and [m̥]-[l̥]-[ʀ̥]). Since it’s usually easiest to analyze a pair, we can start with just one pair and see if we can find any patterns. We will choose [m] and [m̥] first.
Step 2: Identify the individual environments of the phones of interest
For each phone in our chosen pair, we write down the individual environments it occurs in, word by word (again, at an introductory level, we will normally only ever need to consider the immediate right and left environment). So for [ʀym] ‘cold/flu’, we would write down y▁# in the column for [m], because [ʀym] has [m] between [y] and the end of the word. Then for the next word [mɛʀ] ‘mother’, we would write down #▁ɛ in the column for [m]. And so on, until we have the following full list of environments:
| [m] | [m̥] |
|---|---|
| y▁# | t▁# |
| #▁ɛ | s▁# |
| ʀ▁# | |
| l▁# | |
| i▁i | |
| y▁a | |
| s▁a | |
| e▁ã | |
| i▁e | |
| k▁ã |
Step 3: Determine overlap in environments
To check whether the phones are in contrastive distribution, we need to see if there is any overlap in the environments on the two lists. If both phones have some of the exact same environments, then there is a good chance they are allophones of separate phonemes.
There are no exact matches, but we do see some similarities in some left and right right environments. For example, we see that both [m] and [m̥] occur after [s]. However, voiced [m] only does so when followed by the vowel [a], as in [ʀymatismal] ‘rheumatic’, while voiceless [m̥] only does so at the end of the word, as in [ʀymatism̥] ‘rheumatism’.
Similarly, we see that both [m] and [m̥] occur at the end of the word, but with restrictions. Voiced [m] is only word-final when it is preceded by [y] or [l], as in [ʀym] ‘cold/flu’ and [film] ‘film’, while voiceless [m̥] is only word final when preceded by [t] or [s], as in [ʀitm̥] ‘rhythm’ and [ʀymatism̥] ‘rheumatism’. It is probably no coincidence that the difference in the voicing of the two phones of interest happens to match the voicing on the phone on its left in these cases.
Since there are apparent patterns to how these two phones are distributed, rather than them being able to occur in the same environments, they appear not to be in contrastive distribution, so we would continue on to Step 4.
Step 4: Simplify the environments
This is not a lot to go on, because there is so little data for [m̥], but it seems like both the left and right sides matter for the distribution of [m̥], since it consistently has a natural class on the left (voiceless obstruents) and a word boundary on the right. There is not much of a pattern to the distribution of [m], since it has a mix of various natural classes on both sides. So as a first guess, we might say that [m̥] occurs only word-finally when immediately preceded by a voiceless obstruent, while [m] occurs instead either after voiced phones (regardless of what comes after) or before any phone at all (that is, it is not word-final). This is complementary distribution.
Step 5: Organize the phones into phonemes
Since [m̥] and [m] seem to be in complementary distribution and are phonetically similar (they are both bilabial nasal stops, differing only in phonation), it seems reasonable to analyze [m̥] and [m] as allophones of the same phoneme.
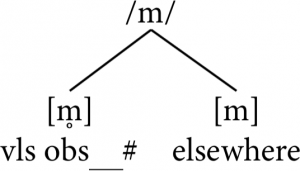
Step 6: Identify the default allophone and finalize the analysis
The default allophone appears to be [m], since it occurs in two distinctly different environments, while [m̥] only occurs in one. Thus, we would propose a single phoneme /m/ with two allophones: [m̥] occurring word-finally when immediately preceded by a voiceless obstruent (abbreviated vls obs▁# here) and [m] occurring elsewhere as the default.
Repeat Steps 2–6 for [l] and [l̥]
This seems like a reasonable analysis, so we can continue working through the phones of interest in pairs. The next pair to analyze is [l] and [l̥], so we cycle back and repeats Steps 2–6. This gives us the following list of environments for [l] and [l̥]:
| [l] | [l̥] |
|---|---|
| i▁m | p▁# |
| #▁i | k▁# |
| #▁ɛ | |
| p▁ɛ | |
| a▁# | |
| a▁i | |
| i▁# | |
| b▁# | |
| ɛ▁# | |
| k▁e | |
| f▁e |
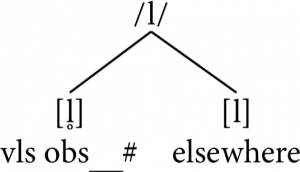
We see the same pattern of complementary distribution as for the bilabial nasals: the voiceless lateral [l̥] occurs word-finally when immediately preceded by a voiceless obstruent, while the voiced lateral occurs everywhere else, either after any voiced phone, or before any phone (to prevent it from being word-final). We would end up with a parallel analysis to the nasals, with /l/ as the phoneme, having a voiceless allophone [l̥] in one environment (word-final while immediately after a voiceless obstruent) and a default voiced allophone [l] everywhere else:
Repeat Steps 2–6 for [ʀ] and [ʀ̥]
Then we do the same for [ʀ] and [ʀ̥], but first, note how /m/ and /l/ have the same basic pattern: one exact same kind of allophone (voiceless) in the exact same environment (word-final immediately after a voiceless consonant), and the exact same kind of default allophone (voiced). Note only that, /m/ and /l/ are part of a natural class: they are both sonorant consonants. But the remaining pair of phones we need to analyze, [ʀ] and [ʀ̥], are also sonorant consonants.
This is unlikely to be a coincidence, so we can make a prediction, even before we look at the data. We predict that [ʀ] and [ʀ̥] should pattern just like the other two pairs of sonorants, with the two phones being in complementary distribution, and with the voiceless phone occurring only word-finally immediately after a voiceless obstruent and the voiced phone occurring elsewhere (after a voiced phone or before any phone at all). In the following list of environments for [ʀ] and [ʀ̥], the predicted pattern is exactly what we find:
| [ʀ] | [ʀ̥] |
|---|---|
| #▁y | t▁# |
| ɛ▁# | f▁# |
| ɛ▁m | |
| i▁# | |
| v▁# | |
| t▁i | |
| #▁a | |
| #▁ɔ̃ | |
| k▁i | |
| ɔ▁d | |
| d▁# | |
| ɛ▁s |
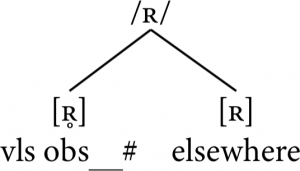
Thus, we end up with the same basic analysis as for the previous pairs: the two phones of interest [ʀ] and [ʀ̥] are allophones of /ʀ/, with the voiceless allophone occurring word-finally immediately after a voiceless obstruent and the voiced allophone as the default, occurring everywhere else:
Is there more?
This analysis is nice, but it still seems like we are missing something. Why do these three phonemes have the same basic pattern for their allophones? Why do they have a voiceless allophone in this particular environment and not somewhere else? Is there a reason the environment for the voiceless allophone also mentions voicelessness? Recall how the environment for one of the Georgian laterals similarly shared a phonetic property with the allophone that occurred there. Can we somehow represent the larger pattern in the overall distribution of French sonorants generally? Right now, the distributions are still specified for each individual phoneme separately, creating a lot of redundancy in our analysis. The next stage of our phonological analysis in Section 4.7 will help answer these questions!
Check your understanding
References
Armagost, James L. 1985. On predicting voiceless vowels in Comanche. In Kansas Working Papers in Linguistics 10(2), Studies in Native American Languages 4, 1–15. Lawrence, KS: University of Kansas.
Katamba, Francis. 1989. An introduction to phonology. London: Longman.
Onn, Farid Mohamed. 1976. Aspects of Malay phonology and morphology. Doctoral dissertation, University of Illinois at Urbana-Champaign.
