Chapter 4: Phonology
4.7 Phonological rules
Eliminating redundancy with faithfulness
If we write out our analysis of the French sonorants as descriptions of how to pronounce the three phonemes, we get statements like the following:
- /m/ is pronounced as [m̥] word-finally after a voiceless obstruent
- /m/ is pronounced as [m] elsewhere
- /l/ is pronounced as [l̥] word-finally after a voiceless obstruent
- /l/ is pronounced as [l] elsewhere
- /ʀ/ is pronounced as [ʀ̥] word-finally after a voiceless obstruent
- /ʀ/ is pronounced as [ʀ] elsewhere
Note the massive amount of redundancy in these statements. First, every phoneme /X/ has a statement of the same exact form: “/X/ is pronounced [X] elsewhere”. This is because of how we chose to represent the phoneme, using the same symbol as the default allophone. If we consistently do this for every phonemicization, then we will always have this kind of statement for the default pronunciation for every phoneme.
Since we will always have this default statement, we don’t need to list it explicitly. Instead, we can simply treat it as an inherent part of how phonology works: every phoneme is always pronounced as its matching default allophone “elsewhere”. This is sometimes called the principle of faithfulness: if a phoneme occurs in an environment not covered by any other statement for the pronunciation of that phoneme, then it is pronounced the same (its pronunciation is “faithful” to its phoneme). Thus, we can remove every instance of this default statement, relying instead on the principle of faithfulness to universally give us the default allophones for every phoneme in every spoken language. This leaves us with the following three statements for French:
- /m/ is pronounced as [m̥] word-finally after a voiceless obstruent
- /l/ is pronounced as [l̥] word-finally after a voiceless obstruent
- /ʀ/ is pronounced as [ʀ̥] word-finally after a voiceless obstruent
Eliminating redundancy with natural classes
There is still some remaining redundancy. All three of these statements have the same form: “/X/ is pronounced [X̥] word-finally after a voiceless obstruent”. This is another pattern, and part of phonology (and linguistics in general) is finding patterns and reducing them down to simpler descriptions and explanations.
Note that /m/, /l/, and /ʀ/ are all sonorants. This has the beginnings of a natural class, but natural classes need to be exhaustive, and there are other sonorants in French. For example, we see [n] and [j] in the data, and these are presumably allophones of /n/ and /j/, which would need to be included in any natural class of sonorant phonemes. This leaves us with two options: either there are three independent statements about some sonorants as above, one for each of /m/, /l/, and /ʀ/, that coincidentally all have the exact same basic form, or there is a single statement we can construct that covers all sonorants, including /n/ and /j/.
Each option makes a different prediction about the pronunciation of French. If /m/, /l/, and /ʀ/ behave completely independent of /n/ and /j/, then we predict that /n/ and /j/ would not have voiceless allophones if they are word-final after a voiceless obstruent. If instead there is a single pattern that applies to all sonorants, we predict that /n/ and /j/ should have voiceless allophones in exactly the same environments that /m/, /l/, and /ʀ/ do.
Nothing in the given data can help us decide between these two options, because there are no words with /n/ or /j/ in the relevant environment in data. In fact, French phonotactics prevent that from ever happening anyway, so can unfortunately never test our predictions!
Eliminating redundancy with simplicity
Since we have two competing analyses that both account for the given data, and no other data can be found to contradict either analysis, we can follow the principle of simplicity and pick the analysis with the fewest statements. This allows us to simplify our three statements down to just one, something like the following:
- a sonorant is pronounced as voiceless word-finally after a voiceless obstruent
Note that this says nothing about what happens to the place and manner of articulation of the sonorants, just their phonation. We should assume that statements like these only affect exactly what they say; everything else must remain faithful (unchanged). We do not want /m/ turning into any random voiceless phone! We specifically want it to be pronounced as [m̥], so only its phonation differs.
Writing phonological rules
These kinds of statements are often called phonological rules, and there is a shorthand notation we can use to reduce them down to a form that is easier to deal with. We can use an arrow [latex]\rightarrow[/latex] to replace “is pronounced as” and use a slash / to separate the change in the rule from the environment where the rule applies. Finally, we can replace the wordy description of the environment “word-finally after a voiceless obstruent” with the simplified notation we used in the phoneme diagrams, using an underline ▁ to represent the position in the environment where the phoneme must be to undergo the rule and the hash # to indicate word boundaries.
This gives us the following shorthand rule:
- sonorant [latex]\rightarrow[/latex] voiceless / voiceless obstruent ▁ #
There are more advanced ways we can simplify phonological rules, but for the purposes of this textbook, this form will be sufficient. We now have the following basic template for a phonological rule, containing three key components: the target (indicated here by A), the change (B), and the environment (C ▁ D).
A [latex]\rightarrow[/latex] B / C ▁ D
The target of a phonological rule is the natural class of phonemes that are changed into their appropriate allophones. The change caused by a phonological rule is the list of all phonetic properties that describe how the allophones consistently differ from the target phonemes. Finally, the environment is the same as what we used for talking about the distribution of allophones. As we have seen, most environments typically only reference something on the immediate left and/or immediate right, though more complicated environments are possible.
Generative phonology and levels of representation
In some versions of phonology, phonemes, allophones, and phonological rules are not just convenient descriptions of patterns, but crucial objects in the theory, sometimes proposed to represent some aspect of cognitive reality. One of the most common such versions of phonology is generative phonology, initially developed in the 1950s and 1960s (Chomsky 1951, Chomsky et al. 1956, Halle 1959, Chomsky and Halle 1968), building upon ideas developed in the first half of the 20th century (Saussure 1916, Bloomfield 1939, Swadesh and Voegelin 1939, Trubetzkoy 1939, Jakobson 1942, Harris 1946/1951, Wells 1949) and ultimately reflecting ideas from the work of Dakṣiputra Pāṇini, a grammarian in ancient India (ca. 500 BC) who developed concepts and methods for the analysis of Sanskrit that can still be seen in modern linguistics.
In generative phonology, words have at least two distinct phonological forms. One is an approximation of the pronunciation (narrow or broad, as needed), which we have been representing in square brackets with phones. This representation is called the surface representation (SR) or phonetic representation. Because it is made up of phones, the SR is a relatively concrete representation, something directly observable and measurable. Here, all of the data we have been looking at are given SRs.
The second representation is made up of phonemes and is called the underlying representation (UR) or phonemic representation. Because the UR is made up of phonemes, it is an abstract object in our theoretical analyses of a language. As with phonemes, there is debate about whether URs also correspond to any sort of cognitive reality, but whether or not they do, they are useful tools for describing the phonology of a language. Here, we would have to rewrite all of our data using phonemes instead of allophones.
Thus, for every word in Georgian, we would replace every clear [l] with its phoneme /ɫ/. So the URs for [t͡ʃoli] ‘wife’ and [xeli] ‘hand’ would be /t͡ʃoɫi/ and /xeɫi/.
Similarly, to get the URs for the French data, we would replace all of the voiceless sonorants with their corresponding phonemes: the UR of [ɛtʀ̥] ‘to be’ would be /ɛtʀ/, the UR of [pœpl̥] ‘people’ would be /pœpl/, and the UR [ʀitm̥] ‘rhythm’ would be /ʀitm/. Note URs are enclosed with slashes, because they are made up of phonemes.
In generative phonology, the relationship between URs and SRs is not just a static link. Instead, URs are treated as inputs to a process that “generates” the SRs as output, by actively changing the phonemes into their appropriate allophones. This model is designed to mimic how language presumably works: we begin with some mental representation of a word in our mind, and then sometime later, we articulate that word. This overall process is called a phonological derivation, and the individual components of this process that change the phonemes are our phonological rules. This model is represented graphically in the following diagram.
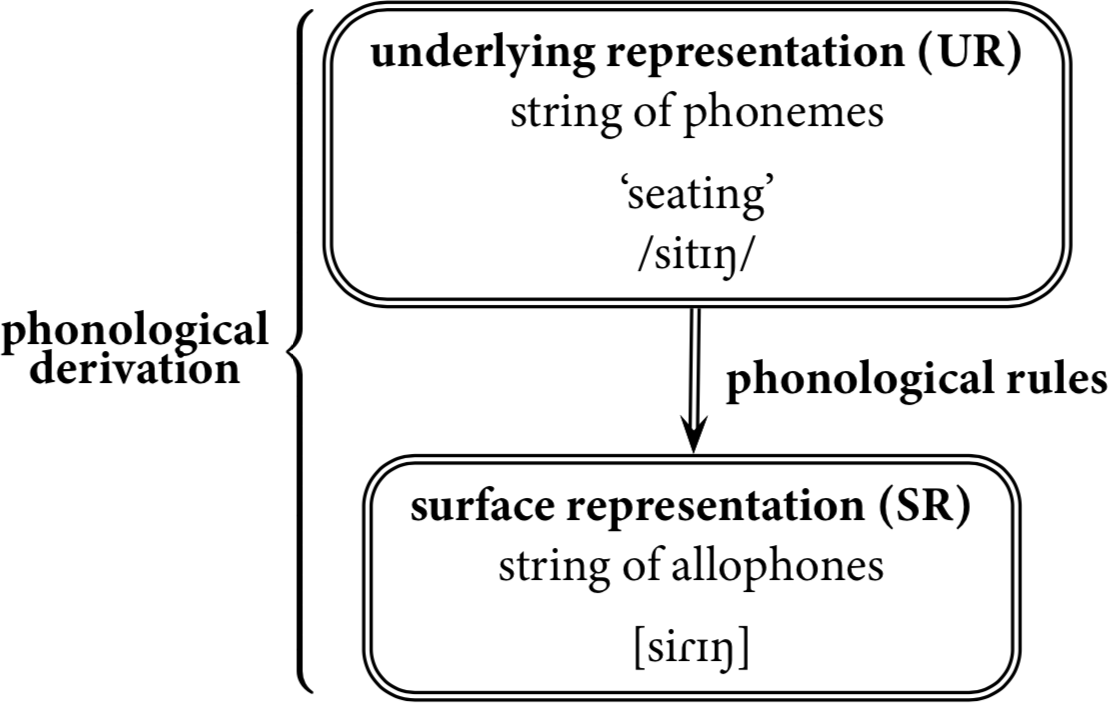
Note that this is a simplification of generative phonology, but the full explanation is beyond the scope of this textbook. Generative phonology actually rejected the original concept of phoneme, so some purists would say that URs in generative phonology are not made of phonemes. However, the usage of the term phoneme has evolved since then, and many linguists now use it as it is used here. Just be aware that this is not universally accepted, and if you are learning phonology in a course, you should use the terminology endorsed by your instructor.
Check your understanding
References
Bloomfield, Leonard. 1939. Menomini morphophonemics. In Études phonologiques dédiées à la mémoire de M. le prince N. S. Trubetzkoy, vol. 8, 105–115. Jednota českých matematiků a fyziků.
Chomsky, Noam. 1951. The morphophonemics of Modern Hebrew. Master’s thesis, University of Pennsylvania, Philadelphia.
Chomsky, Noam and Morris Halle. 1968. The sound pattern of English. New York: Harper & Row.
Chomsky, Noam, Morris Halle, and Fred Lukoff. 1956. On accent and juncture in English. In For Roman Jakobson: Essays on the occasion of his sixtieth birthday, ed. Morris Halle, Horace Lunt, Hugh MacLean, and Cornelis van Schooneveld, 65–80. The Hague: Mouton.
Halle, Morris. 1959. The sound pattern of Russian: A linguistic and acoustical investigation. The Hague: Mouton.
Harris, Zellig S. 1946/1951. Methods in structural linguistics. Chicago: University of Chicago Press.
Jakobson, Roman. 1942. The concept of phoneme. In On language, ed. Linda R. Waugh and Monique Moville-Burston, 218–241. Cambridge, MA: Harvard University Press.
Saussure, Ferdinand de. 1916. Cours de linguistique générale. Paris: Payot.
Swadesh, Morris and Charles F. Voegelin. 1939. A problem in phonological alternation. Language 15: 1–10.
Trubetzkoy, Nikolai Sergeyevich. 1939. Grundzüge der Phonologie, Travaux du Cercle linguistique de Prague, vol. 7. Prague: Jednota českých matematiků a fyziků.
Wells, Rulon S. 1949. Automatic alternations. Language 25(2): 99–116.
