Chapter 3: Phonetics
3.10 Syllables
Spoken language syllables
While spoken language words can be decomposed into phones, there seem to be other layers of structure that are relevant to how spoken languages function. One such layer is made up of units called syllables. Thus, words can contain multiple syllables, and each syllable can contain multiple phones. Of course, some words may have only one syllable, such as the English words [bæt] bat and [prɪnts] prints, and some syllables may have only one phone, such as the English words [o] owe and [ɔ] awe.
As a unit of structure, syllables are often abbreviated with the Greek letter sigma σ, and within a transcription, the boundaries between syllables are notated with the IPA symbol [.], as in the transcription [kæ.nə.də] Canada. Note that the syllable boundary mark [.] is only needed between syllables; nothing extra is needed to mark the beginning of the first syllable or the end of the last syllable.
The loudest, most prominent position within a syllable is called the nucleus (abbreviated here as Nuc), which is usually filled by a vowel in most languages. However, some languages, like English, allow syllabic consonants in the nucleus, as in the English word [br̩d] bird and the second syllables of [bɒ.tl̩] bottle and [bɒ.tm̩] bottom. Some languages make more extensive use of syllabic consonants, such as Tashlhiyt Berber (a.k.a. Shilha, a Northern Berber language of the Afro-Asiatic family, spoken in Morocco), which allows syllabic sonorants (fairly typical in the world’s languages) as well as syllabic obstruents (quite rare in the world’s languages), as in the words [tʁ̩.fl̩] ‘she surprised’, [ts̩.kr̩] ‘she did’, [tb̩.dɡ̩] ‘it was wet’, and [tk̩.ti] ‘she remembered’ (Ridouane 2014).
The remaining phones in the syllable (if any) make up the margins: the onset (Ons) on the left of the nucleus and the coda (Cod) on the right. The margins of the syllable can each be empty, or they may contain one or more consonant phones. A margin with only one phone is called simple, and a margin with two or more phones is called complex.
Thus, in the English word [ə.prot͡ʃ] approach, the first syllable [ə] has no onset or coda, while the second syllable [prot͡ʃ] has a complex onset [pr] and a simple coda [t͡ʃ] (recall that an affricate counts as a single phone not two).
Syllable structure is often shown graphically in a tree diagram, as in Figure 3.38, with each syllable having its own σ node, connected down to the next level of onsets, nuclei, and codas, which are in turn connected down to the level of the phones that they contain. Sometimes, the word level is also shown explicitly above the syllables, abbreviated here as Wd.
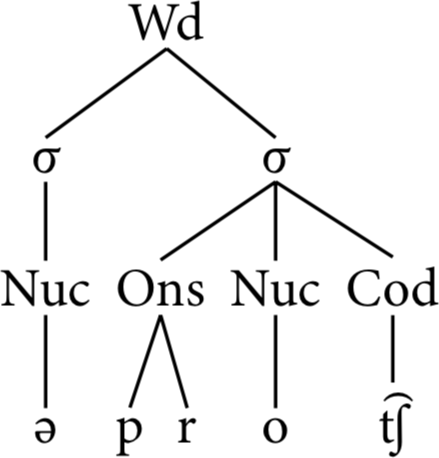
The most common analysis of syllables is that every syllable must have a nucleus, which always contains at least one phone. Though affricates count as a single phone in margins, diphthongs usually count as two phones, but the details of how to treat such complex phones depend on the language and the assumptions underlying the analysis.
Note that while speakers often have consistent intuitions about how many syllables a word has and where the boundaries are, the physical reality of their speech does not always match these intuitions. For example, some English speakers claim that the word hire has one syllable [haɪr], while higher has two [haɪ.r̩], and yet, when these speakers hear recorded samples of their own pronunciation of these two words, they often cannot reliably distinguish one from the other. Many other English speakers think both words have one syllable or both have two syllables. There are lots of similar English words with this murky behaviour, mostly words with a diphthong followed by an approximant: [aʊr]/[paʊr] hour/power, [aʊl]/[taʊl] owl/towel, [vaɪl] vile/vial, etc.
Because of these and other issues, syllables have a somewhat questionable status. It seems that they are more abstract and conceptual rather than concrete and physical. They seem to be a way for speakers to organize phones into useful linguistic units for the purposes of production or processing, which may not necessarily have a consistent measurable impact on the actual pronunciation. That is, syllables may have psychological reality without having physical reality.
Syllable structure can be notated in plain text without tree diagrams using CV-notation, with one C for each phone in the margins and one V for each phone in the nucleus (note that V is typically used in the nucleus even if it represents a syllabic consonant). Thus, the syllable structure of [ə.prot͡ʃ] could be represented as V.CCVC rather than with a full tree diagram like Figure 3.38.
A syllable with no coda, such as a CV or V syllable, like English [si] see and [o] owe, is often referred to as an open syllable, while a syllable with a coda, such as CVC or VC, like English [hæt] hat and [it] eat, is a closed syllable. A syllable with no onset, such as V or VC, like English [o] owe and [it] eat, is called onsetless. There is no special term for a syllable with an onset.
Crosslinguistic patterns in spoken language syllable types
Spoken languages generally prefer onsets and disprefer codas. This means that it is common for languages to require onsets, but it seems like there are no languages that require codas. Conversely, it is common for languages to prohibit codas, but there are no languages that prohibit onsets. These possibilities can be notated using parentheses to show what is allowed but not required. So we find languages whose syllables are all of the type CV(C); that is, they have a required onset and nucleus but an optional coda. However, there seem to be no mirror image languages whose syllables can all be classified as (C)VC, with an optional onset but a required nucleus and coda.
In addition, spoken languages generally prefer simple margins to complex margins. Thus, in languages that allow codas, some allow only simple codas and prohibit complex codas; if a language allows complex codas, it also allows simple codas. Similarly for onsets: some languages prohibit complex onsets, and if a language allows complex onsets, it also allows simple onsets.
Finally, there seems to be no strong relationships between complex onsets and complex codas: some languages allow complex onsets, some allow complex codas, some allow both, and some allow neither. All together, these trends give us a range of possible languages based on what kinds of syllable structures they allow and prohibit.
Syllabification and sonority
The way that phones are associated to appropriate positions in syllable structure is called syllabification. Syllabification is often based at least partially on the sonority of the phones, which is an abstract measure of their relative prominence that corresponds roughly to loudness. A sonority hierarchy is an ordering of phones by their sonority. Vowels are at the top of scale as the most sonorous phones, which is why they can occupy the privileged nucleus position in a syllable, while obstruents are at the bottom of the scale as the least sonorous, so they are typically relegated to the margins of a syllable.
There are some crosslinguistic patterns in sonority, but languages can differ in how they categorize some phones by sonority, so there is no one true universal sonority hierarchy. Some languages may use sonority to distinguish plosives from fricatives, or voiceless from voiced obstruents, or nasal stops from lateral approximants, and some languages may even have some sonority categories reversed from other languages.
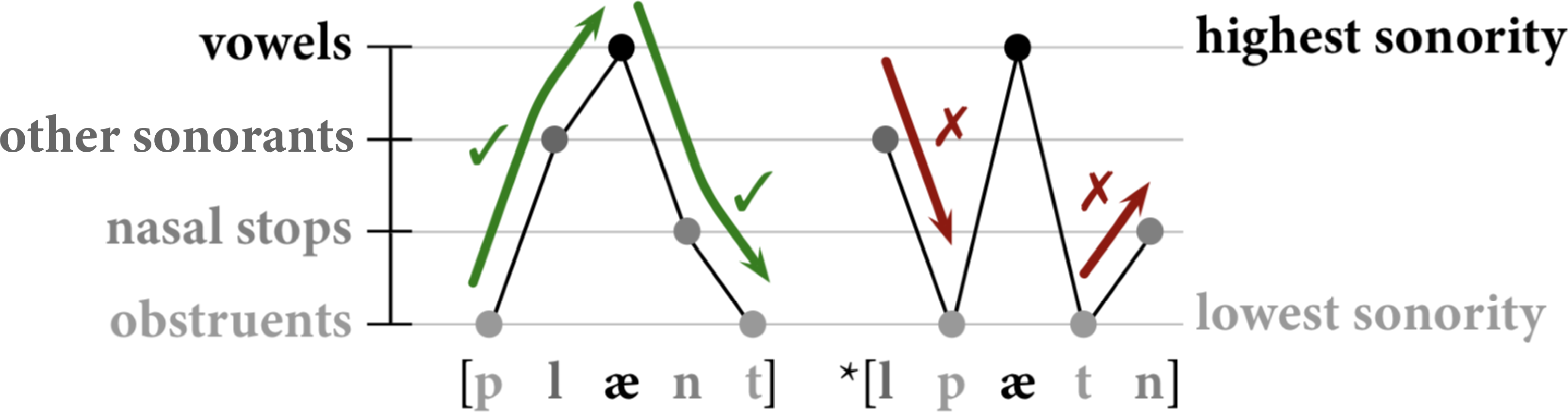
Based on a language’s own sonority hierarchy, its syllables usually obey the sonority sequencing principle (SSP), which requires sonority to rise through the onset of a syllable, hit its peak in the nucleus, and then fall through the coda. Thus, the English syllable [plænt] plant is a well-formed syllable according to the SSP, because obstruents have the lowest sonority in English, followed by nasal stops, followed by other sonorants, followed by vowels at the top of the sonority hierarchy. Reversing the segments in the onset and coda, to create the attempted syllable *[lpætn], violates the SSP, because the onset has falling sonority rather than rising, and the coda has rising sonority rather than falling. The difference in sonority between these two words is graphed in Figure 3.39.
However, the SSP is not absolute. Many languages allow portions of a syllable to have a sonority plateau (when two adjacent segments have the same sonority, as in English [ækt] act, with two voiceless plosives in the coda), and some may have even looser syllable structure, allowing one or more sonority reversals, as in Georgian [ɡvphrt͡skhvni] გვფრცქვნი ‘you (singular) are peeling us’, which has a single complex onset [ɡvphrt͡skhvn-] which rises from obstruents to the rhotic [r] and then reverses direction to fall back to obstruents before rising again to the nasal stop.
Signed language syllables
As discussed at the beginning of Section 3.8, signs may be able to similarly be decomposed into syllable-like structures. However, it is important to note that the actual structure of signs and signed languages is not derived from spoken languages. Whatever parallels or analogies we might find between the two modalities are incidental, or perhaps derived from some deeper, more abstract cognitive principles of linguistic organization. Crucially, we cannot just directly import the theories and structures of spoken languages into the analysis of signed languages. We have to take into account the differences in modality.
A common analysis of the internal structure of signs is to treat them as sequences of two types of units: static states (sometimes called holds, positions, or postures, roughly equivalent to a combination of the location and orientation parameters) and dynamic states (essentially the movement parameter) (Liddell 1984, Liddell and Johnson 1986, 1989, Johnson and Liddell 2010, Sandler 1986, 1989, 1993, Perlmutter 1992, van der Hulst 1993), with handshape often being a relatively stable property over an entire syllable (Mandel 1981). The exact nature and composition of these units varies from model to model, but they generally share the same basic division between some type of static unit and some type of dynamic unit.
Many linguists additionally argue that the dynamic units are more sonorous than the static units (Brentari 1990, Corina 1990, Perlmutter 1992, Sandler 1993). In this view, the less sonorous static units are like syllable margins (and thus, comparable to consonants), while the more sonorous dynamic units are like syllable nuclei (and thus, comparable to vowels).
However, there is a lot of disagreement about what kind of syllabic model (if any) is appropriate for the analysis of signed languages. Linguists might just be forcing signed languages to fit within their understanding of how spoken languages work, or maybe there could genuinely be something more fundamental that underlies both signed and spoken languages that results in something like syllables as a natural organizational unit in both modalities. This is still a rich and open area of study in linguistics with many unanswered questions.
Check your understanding
References
Brentari, Diane. 1990. Theoretical foundations of American Sign Language phonology. Doctoral dissertation, University of Chicago, Chicago.
Corina, David P. 1990. Reassessing the role of sonority in syllable structure: Evidence from visual gestural language. In CLS 26-II: Papers from the parasession on the syllable in phonetics and phonology, ed. Michael Ziolkowski, Manuela Noske, and Karen Deaton, 33–43. Chicago: Chicago Linguistic Society.
Johnson, Robert E. and Scott K. Liddell. 2010. Toward a phonetic representation of signs: Sequentiality and contrast. Sign Language Studies 11(2): 241–274.
Liddell, Scott K. 1984. THINK and BELIEVE: Sequentiality in American Sign Language. Language 60(2): 372–399.
Liddell, Scott K. and Robert E. Johnson. 1986. American Sign Language compound formation processes, lexicalization, and phonological remnants. Natural Language & Linguistic Theory 4(4): 445—513.
Liddell, Scott K. and Robert E. Johnson. 1989. American Sign Language: The phonological base. Sign Language Studies 64: 195–278.
Mandel, Mark. 1981. Phonotactics and morphophonology in American Sign Language. Doctoral dissertation, University of California, Berkeley.
Perlmutter, David M. 1992. Sonority and syllable structure in American Sign Language. Linguistic Inquiry 23(3): 407–422.
Ridouane, Rachid. 2014. Tashlhiyt Berber. Journal of the International Phonetic Association 44(2): 207–221.
Sandler, Wendy. 1986. The spreading hand autosegment of American Sign Language. Sign Language Studies 50(1): 1–28.
Sandler, Wendy. 1989. Phonological representation of the sign: Linearity and nonlinearity in American Sign Language. No 32 in Publications in Language Sciences. Dordrecht: Foris.
Sandler, Wendy. 1993. A sonority cycle in American Sign Language. Phonology 10(2): 243–279.
van der Hulst, Harry. 1993. Units in the analysis of signs. Phonology 10(2): 209–241.
