10. NORMALIZATION
10.2.2: Boyce-Codd Normal Form (BCNF)
Initial research into normal forms led to 1NF, 2NF, and 3NF, but later1 it was realized that these were not strong enough. This realization led to BCNF which is defined very simply:
A relation R is in BCNF if R is in 1NF and every determinant of a non-trivial functional dependency in R is a candidate key.
BCNF is the usual objective of the database designer; BCNF is based on the notions of candidate key (CK) and functional dependency (FD). When we investigate a relation to determine whether it is in BCNF or not, we must know what attributes or attribute combinations are CKs for the relation, and we must know the FDs that exist in the relation. Our knowledge of the semantics of a relation guides us in determining CKs and FDs.
Recall that a CK is an attribute, or attribute combination, that uniquely identifies a row. Also, recall a CK is minimal – no attribute can be removed without losing the property of being a key.
Recall that a FD X –> Y in a relation R means that for each row in the relation R that has the same value for X the value of Y must also be the same. Recall that when we consider a FD X –> Y we refer to the left-hand side, attribute X, as the determinant. We are concerned with minimal FDs – all attributes comprising the determinant are required for the FD property to hold. If X –> Y is a FD, then the determinant augmented with any other attribute is also a FD, but it would not be a minimal FD.
We consider several examples. We keep the examples simple and to the point, each relation involves very few attributes. This is of course unrealistic – in practice relations usually have many attributes. However, the examples illustrate one point each, and more attributes in the relations may cloud the issues. Each example begins with a relation that is in 1NF.
In general, when we determine the relation under consideration is not in BCNF we obtain BCNF relations by decomposing the relation into two or more relations that are in BCNF. In this process we say we take a projection of the original relation on a subset of its attributes and at the same time we eliminate any duplicate rows. An important property of the decomposition is that it must be lossless – the new relations will have attributes in common that can be used to join the new relations whereby we can realize the original relation. All rows of the original relation are obtained in the join, and no new or spurious rows are generated – we get back the original relation exactly.
In Example 1 we have a ‘good’ relation, one that is in BCNF. Hence, no decomposition is required. We discuss the CDs and FDs for the relation thereby knowing it is in BCNF.
Example 2 presents a relation that is not in BCNF. There is a type of redundancy present in its data. We illustrate how to decompose the relation into two relations that are each in BCNF. This example illustrates a type of dependency known as a partial functional dependency.
Example 3 presents another relation that is not in BCNF. There is a type of redundancy present in its data. We illustrate how to decompose the relation into two relations that are each in BCNF. This example illustrates a type of dependency known as a transitive functional dependency.
Our last example is a case where FDs involve overlapping candidate keys, and where FDs exist amongst attributes that make up CKs. There is a type of redundancy present which is not related to 2NF and 3NF. BCNF gives us a theoretical basis for recognizing the source of the redundant data.
EXAMPLE 1.
Consider the Employee relation below that depicts sample data for 5 employees. The semantics are quite simple: for each employee identified by a unique employee number we store the employee’s first name and last name.
|
id |
first |
last |
|
1 |
Joe |
Jones |
|
2 |
Joe |
Smith |
|
3 |
Susan |
Smith |
|
4 |
Abigail |
McDonald |
|
5 |
Abigail |
McDonald |
Candidate Keys.
The hypothetical company that uses this relation identifies employees by an identification number that is assigned by the Human Resources Department, and they ensure each employee has a different id from every other employee. Clearly id is a candidate key.
When an employee is hired they have a first and last name, and the company has no control over these names. As the sample data shows, more than one employee can have the same first name (id 1 and 2), can have the same last name (id 2 and 3), and can even have the same first and last names (id 4 and 5). So, id is the only candidate key for this relation.
Functional Dependencies.
Since each row/employee has a unique identifier, it is easy to see there are two FDs for this relation:
-
-
- id –> first
- id –> last
-
There are no other FDs. For example, we cannot have first –> last. The sample data shows there can be many last names associated with any one first name.
These two FDs are minimal as the determinant, id, cannot be reduced at all.
BCNF?
In this example we have one candidate key, id, and this attribute is the determinant in all FDs. Therefore, Employee relation is in BCNF; it is a ‘good’ relation.
This relation has a ‘nice’ simple structure; there is one candidate key which is the determinant for every FD.
EXAMPLE 2.
Consider the following relation named Enrollment:
|
stuNum |
courseId |
birthdate |
|
111 |
2914 |
Jan 1, 1995 |
|
113 |
2914 |
Jan 1, 1998 |
|
113 |
3902 |
Jan 1, 1998 |
|
118 |
2222 |
Jan 1, 1990 |
|
118 |
3902 |
Jan 1, 1990 |
|
202 |
1805 |
Jan 1, 2000 |
The semantics of this relation are:
-
-
- Each row represents an enrollment of a student in a course.
- A student is identified by their student number.
- A course is identified by a course identifier.
- A student can only enroll in a course once. Hence the combinations {stuNum,courseId} are unique.
- The birthdate column holds the date of birth for the student of that row. When the same student number appears in more than one row then the birthdate appears redundantly.
- A course can have many students registered in it
-
Candidate Keys.
It should be clear that several rows may exist for any given student number, and several rows may exist for any given course number. Also, since we cannot control when someone is born there can be many rows for a value of birthdate. All this just means that no single attribute uniquely identifies a row and so no single attribute can be a CK. Any CKs for this relation must be composite – comprising more than one attribute. It should be fairly clear, given the semantics of the relation, the only attribute combination that is a CK is {stuNum, courseId}. For any given value of {stuNum, courseId} there can be at most one row.
Functional Dependencies.
This relation is quite simple in that there is just one FD: stuNum –> birthdate. If a specific student number appears in more than one row, the value stored for birthdate must be the same in all such rows.
BCNF?
Enrollment has one CK: {stuNum, courseId}, and has one FD (stuNum –> birthdate) where the determinant is not a candidate key. Therefore, Enrollment is not in BCNF.
In this relation we have an attribute that does not describe the whole key – it describes a part of the key. In normalization theory the FD stuNum –> birthdate is called a partial functional dependency as its determinant is a subset of a candidate key.
When you think of the Enrollment relation now, you should consider that it is about two very different things:
-
-
- Enrollment presents enrollment information.
- Enrollment presents information about students (their birthdates).
-
Decomposition.
We now consider how Enrollment can be replaced by two relations where the new relations are each in BCNF. Above we mentioned that Enrollment is about two very different things – what we need to do is arrange for two relations, one for each of these concerns.
Consider the following two relations as a decomposition of the above, where we have placed information about enrollments in one relation and information about students in another relation. Note that these two relations have the stuNum attribute in common.
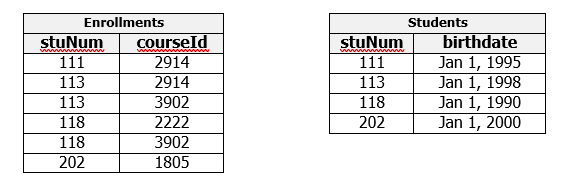
Enrollments and Students can be joined on stuNum to reproduce the exact information in Enrollment. Because we have not lost any information, and noting that the FD has been preserved, these two relations are equivalent to the one we started with.
-
-
- Enrollments has one candidate key: {stuNum, courseId}, and no FDs. Therefore, Enrollments is in BCNF.
- Students has one CK: stuNum, and has one FD: stuNum –> birthdate. Therefore, Students is in BCNF.
-
EXAMPLE 3.
Consider the following relation named Course.
|
courseId |
teacherId |
lastName |
|
2914 |
11 |
Smith |
|
3902 |
22 |
Jones |
|
3913 |
11 |
Smith |
|
4902 |
33 |
Jones |
|
4906 |
11 |
Smith |
|
4994 |
22 |
Jones |
The purpose of this relation is to record who is teaching courses. Note that a teacher’s id and last name may appear in several rows – this information is repeated for each course the teacher is teaching. For example, teacher 11 (Smith) is teaching 3 courses (2914, 3913, 4906) and so we see the same id and last name in three rows.
The semantics of this relation are:
-
-
- Each course is identified by a course identifier.
- For each course there is one row.
- Each teacher is identified by a teacher identifier.
- Each course has one teacher, and so for each course one teacher Id is recorded.
- A teacher may teach several courses.
- A teacher’s last name must be the same in every row where the teacher’s Id appears. This point leads to redundant data in the relation.
-
Candidate Keys.
The semantics of the relation are that there is one row per course, and so a course id uniquely identifies a row; so, courseId is a candidate key. No other attribute or combination can be a candidate key for this relation.
Functional Dependencies.
It is stated there is one teacher per course and so for each courseId there is at most one teacherId, and so we have courseIdteacherId. The opposite, teacherIdcourseId, does not hold for this relation since a teacher can teach more than one course.
Another FD that is present is teacherIdlastName. This is because for each teacher there is a single last name. Note the opposite, lastNameteacherId does not hold in this relation. The sample data shows multiple teachers who have the same last name.
Note that since courseIdteacherId and teacherIdlastName, it must be true we have the FD courseIdlastName. For each course we have one teacher and so one last name. For any value of course id there will only be one value for teacher last name. In relational database theory the FD courseIdlastName is called a transitive functional dependency – lastName is dependent on courseId but this dependency is via teacherId.
BCNF?
Hopefully you agree the only FDs are these:
-
-
- courseId –> teacherId
- teacherId –> lastName
- courseId –> lastName
-
The only candidate key is courseId, and there is a FD, teacherId –> lastName, where the determinant is not a candidate key. Therefore, Course is not BCNF.
When you think of the Course relation now, you should see that it is about two very different things:
-
-
- Course presents teacher information (teacherId) for courses
- Course presents information about teachers (their last names)
-
Decomposition.
Course can be replaced by two relations where the new relations are each in BCNF. Above we mentioned that Course is about two very different things – what we need to do is arrange for two relations, one for each of these concerns.
Consider the following two relations as a decomposition of the above where we have placed information about courses in one table and information about teachers in another table. These relations have a common attribute, teacherId.
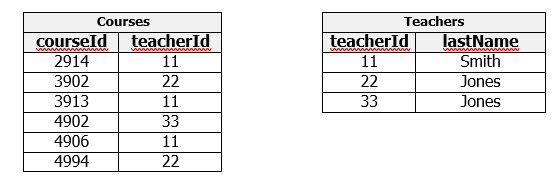
Courses and Teachers can be joined on teacherId to reproduce exactly the information in Course. Because we have not lost any information and noting that the FD has been preserved as well, these two relations are equivalent to the one we started with.
-
-
- Courses has one candidate key: courseId. The only FD is courseId –> teacherId. Therefore, Courses is in BCNF.
- Teachers has one candidate key: teacherId. There is one FD: teacherId –> lastName. Therefore, Teachers is in BCNF.
-
EXAMPLE 4.
This example uses a relation that contains data obtained from a 2011 Statistics Canada survey. Each row gives us information about the percentage of people in a Canadian province who speak a language considered their mother tongue2. The ellipsis “…” indicate there are more rows.
|
provCode |
provName |
language |
percentMotherTongue |
|
MB |
Manitoba |
English |
72.9 |
|
MB |
Manitoba |
French |
3.5 |
|
MB |
Manitoba |
non-official |
21.5 |
|
SK |
Saskatchewan |
English |
84.5 |
|
SK |
Saskatchewan |
French |
1.6 |
|
SK |
Saskatchewan |
non-official |
12.7 |
|
NU |
Nunavut |
English |
28.1 |
|
… |
… |
… |
… |
The ProvinceLanguageStatistics relation has redundant data. In the rows listed above we see that each province name and each province code appear multiple times.
Candidate Keys.
There can be more than one row for any province, but for the combination of province and language there can be only one row and so there are two composite candidate keys:
-
-
- {provCode, language}
- {provName, language}
-
Functional Dependencies.
Since province codes and province names are unique, we have the FDs:
-
-
- provCode –> provName
- provName –> provCode
-
For each combination of province and language there is one value for percent mother tongue, and so we have FDs:
-
-
- provCode,language –> percentMotherTongue
- provName,language –> percentMotherTongue
-
BCNF?
The first two FDs listed above have determinants that are subsets of candidate keys. Therefore, ProvinceLanguageStatistics is not BCNF.
The ProvinceLanguageStatistics relation has information about two different things:
-
-
- It has information about provinces (names/codes).
- It has information about mother tongues in the provinces.
-
Decomposition.
To obtain BCNF relations we must decompose ProvinceLanguageStatistics into two relations; for example, consider Province and ProvinceLanguages below:
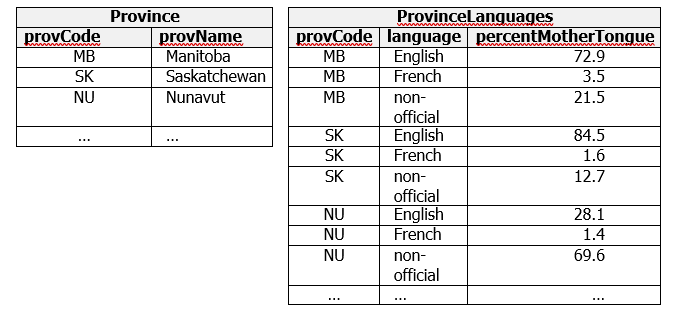
These relations can be joined on provCode to produce exactly the information shown in ProvinceLanguageStatistics.
- Province has two CKs: provCode and provName, and has two FDs:
-
- provCode –>provName
- provName –> provCode.
-
Therefore, Province is in BCNF.
- ProvinceLanguages has one CK: {provCode,language}, and one FD:
-
- {provCode,language} –> percentMotherTongue.
-
Therefore, ProvinceLanguages is in BCNF.
