3.4 Protéines
Objectifs d’apprentissage
À la fin de cette section, vous serez en mesure de faire ce qui suit :
- Décrire les fonctions des protéines dans la cellule et dans les tissus
- Discuter de la relation entre les acides aminés et les protéines
- Expliquer les quatre niveaux d’organisation des protéines
- Décrire les liens entre la forme et la fonction des protéines
Les protéines sont l’une des molécules organiques les plus abondantes dans les systèmes vivants et possèdent la gamme de fonctions la plus diversifiée de toutes les macromolécules. Les protéines peuvent être structurelles, régulatrices, contractiles ou protectrices. Elles peuvent servir au transport, au stockage ou aux membranes, ou encore être des toxines ou des enzymes. Chaque cellule d’un système vivant peut contenir des milliers de protéines, chacune ayant une fonction unique. Leurs structures, comme leurs fonctions, sont très variées. Elles sont toutes, cependant, des polymères d’acides aminés disposés dans une séquence linéaire.
Types et fonctions des protéines
Les enzymes, produites par les cellules vivantes, sont des catalyseurs de réactions biochimiques (comme la digestion) et sont généralement des protéines complexes ou conjuguées. Chaque enzyme est spécifique du substrat (un réactif qui se lie à une enzyme) sur lequel elle agit. L’enzyme peut contribuer aux réactions de décomposition, de réarrangement ou de synthèse. Les enzymes qui décomposent leurs substrats sont appelées enzymes cataboliques. Les enzymes qui construisent des molécules plus complexes à partir de leurs substrats sont des enzymes anaboliques, et les enzymes qui affectent le taux de réaction sont des enzymes catalytiques. Il est à noter que toutes les enzymes augmentent la vitesse de réaction et sont donc des catalyseurs organiques. Un exemple d’enzyme est l’amylase salivaire, qui hydrolyse son substrat, l’amylose, un composant de l’amidon.
Les hormones sont des molécules de signalisation chimique, généralement de petites protéines ou des stéroïdes, sécrétées par les cellules endocrines qui agissent pour contrôler ou réguler des processus physiologiques spécifiques, notamment la croissance, le développement, le métabolisme et la reproduction. Par exemple, l’insuline est une hormone protéique qui aide à réguler le taux de glucose dans le sang. Le Tableau 3.1 énumère les principaux types et fonctions des protéines.
Tableau 3.1 Types de protéines et leurs fonctions

Les protéines ont des formes et des poids moléculaires différents. Certaines protéines ont une forme globulaire, tandis que d’autres sont de nature fibreuse. Par exemple, l’hémoglobine est une protéine globulaire, alors que le collagène, présent dans notre peau, est une protéine fibreuse. La forme des protéines est essentielle à leur fonction, et de nombreux types de liaisons chimiques permettent de maintenir cette forme. Les changements de température, de pH et l’exposition à des produits chimiques peuvent entraîner des modifications permanentes de la forme de la protéine, conduisant à une perte de fonction ou à une dénaturation. Toutes les protéines sont composées de différents arrangements des 20 mêmes types d’acides aminés. Deux nouveaux acides aminés rares ont été découverts récemment (la sélénocystéine et la pyrrolysine), et d’autres découvertes pourraient s’ajouter à la liste.
Acides aminés
Les acides aminés sont les monomères qui composent les protéines. Chaque acide aminé a la même structure fondamentale, qui consiste en un atome de carbone central, ou carbone alpha (α), lié à un groupe amino (NH2), à un groupement carboxyle (COOH) et à un atome d’hydrogène. Chaque acide aminé possède également un autre atome ou groupe d’atomes lié à l’atome central, appelé groupe R (Figure 3.22).
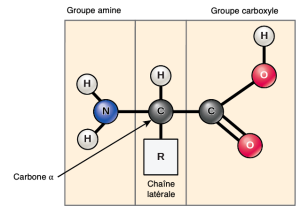
Les scientifiques utilisent le nom « acide aminé » parce que ces acides contiennent à la fois un groupe amino et un groupe acide carboxyle dans leur structure de base. Comme nous l’avons mentionné, il y a 20 acides aminés communs présents dans les protéines. Neuf d’entre eux sont des acides aminés essentiels pour l’humain, car le corps humain ne peut pas les produire et nous les obtenons par notre alimentation. Pour chaque acide aminé, le groupe R (ou chaîne latérale) est différent (Figure 3.23).
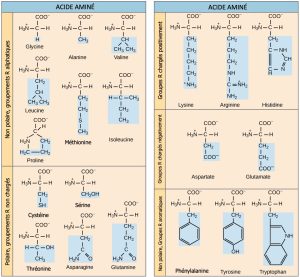
La nature chimique de la chaîne latérale détermine la nature de l’acide aminé (c’est-à-dire s’il est acide, basique, polaire ou non polaire). Par exemple, le groupe R de l’acide aminé glycine est un atome d’hydrogène. Les acides aminés tels que la valine, la méthionine et l’alanine sont de nature non polaire ou hydrophobe, tandis que les acides aminés tels que la sérine, la thréonine et la cystéine sont polaires et ont des chaînes latérales hydrophiles. Les chaînes latérales de la lysine et de l’arginine étant chargées positivement, ces acides aminés sont également des acides aminés basiques. La proline possède un groupe R lié au groupe amino, formant une structure en anneau. La proline est une exception à la structure standard de l’acide aminé, car son groupe aminé n’est pas séparé de la chaîne latérale (Figure 3.23).
Les acides aminés sont représentés par une lettre majuscule ou une abréviation de trois lettres. Par exemple, la lettre V ou le symbole à trois lettres val représentent la valine. Tout comme certains acides gras sont essentiels à un régime alimentaire, certains acides aminés sont également nécessaires. Ces acides aminés essentiels pour l’humain comprennent l’isoleucine, la leucine et la cystéine. Les acides aminés essentiels sont ceux qui sont nécessaires à la construction des protéines dans l’organisme, mais pas ceux que l’organisme produit. Les acides aminés essentiels varient d’un organisme à l’autre.
La séquence et le nombre d’acides aminés déterminent en fin de compte la forme, la taille et la fonction de la protéine. Une liaison covalente, ou liaison peptidique, s’attache à chaque acide aminé, à partir duquel une réaction de déshydratation se forme. Le groupe carboxyle d’un acide aminé et le groupe amino de l’acide aminé entrant se combinent, libérant une molécule d’eau. La liaison qui en résulte est la liaison peptidique (Figure 3.24).
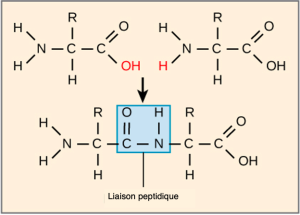
Les produits formés par ces liaisons sont des peptides. Au fur et à mesure que d’autres acides aminés se joignent à cette chaîne en croissance, la chaîne résultante est un polypeptide. Chaque polypeptide possède un groupe amino libre à l’une de ses extrémités. Cette extrémité est le terminal N, ou terminal amino, et l’autre extrémité a un groupe carboxyle libre, également le terminal C ou carboxyle. Bien que les termes « polypeptide » et « protéine » soient parfois utilisés de manière interchangeable, un polypeptide est techniquement un polymère d’acides aminés, tandis que le terme protéine est utilisé pour un ou plusieurs polypeptides qui se sont combinés, qui ont souvent des groupes prosthétiques non peptidiques liés, qui ont une forme distincte et qui ont une fonction unique. Après la synthèse des protéines (traduction), la plupart des protéines sont modifiées. Ces modifications sont connues sous le nom de modifications post-traductionnelles. Ils peuvent subir un clivage, une phosphorylation ou nécessiter l’ajout d’autres groupes chimiques. Ce n’est qu’après ces modifications que la protéine est complètement fonctionnelle.
Lien avec l’évolution
Signification évolutive du cytochrome
Le cytochrome c est un composant important de la chaîne de transport d’électrons, qui fait partie de la respiration cellulaire, et il est normalement situé dans l’organite cellulaire, la mitochondrie. Cette protéine possède un groupe prosthétique hème, et l’ion central de l’hème se réduit et s’oxyde alternativement lors du transfert d’électrons. Parce que le rôle de cette protéine essentielle dans la production d’énergie cellulaire est crucial, elle n’a que très peu évolué depuis des millions d’années. Le séquençage des protéines a montré qu’il existe une homologie considérable de la séquence des acides aminés du cytochrome c entre les différentes espèces. En d’autres termes, nous pouvons évaluer la parenté évolutive en mesurant les similitudes ou les différences entre les séquences d’ADN ou de protéines de diverses espèces.
Les scientifiques ont déterminé que le cytochrome c humain contient 104 acides aminés. Pour chaque molécule de cytochrome c provenant de différents organismes que les scientifiques ont séquencés à ce jour, 37 de ces acides aminés apparaissent dans la même position dans tous les échantillons de cytochrome c. Cela indique qu’il pourrait y avoir eu un ancêtre commun. En comparant les séquences protéiques de l’homme et du chimpanzé, les scientifiques n’ont pas trouvé de différence de séquence. Lorsque les chercheurs ont comparé les séquences de l’homme et du singe rhésus, la seule différence se situait au niveau d’un acide aminé. Dans une autre comparaison, le séquençage entre l’homme et la levure montre une différence en 44e position.
Structure des protéines
Comme nous l’avons vu précédemment, la forme d’une protéine est essentielle à sa fonction. Par exemple, une enzyme peut se lier à un substrat spécifique dans un site actif. Si ce site actif est modifié en raison de changements locaux ou de changements dans la structure globale de la protéine, l’enzyme peut être incapable de se lier au substrat. Pour comprendre comment la protéine obtient sa forme ou sa conformation finale, nous devons comprendre les quatre niveaux de structure des protéines : primaire, secondaire, tertiaire et quaternaire.
Structure primaire
La séquence unique des acides aminés dans une chaîne polypeptidique constitue sa structure primaire. Par exemple, l’insuline, hormone pancréatique, comporte deux chaînes polypeptidiques, A et B, qui sont reliées entre elles par des liaisons disulfures. L’acide aminé N terminal de la chaîne A est la glycine, tandis que l’acide aminé C terminal est l’asparagine (Figure 3.25). Les séquences d’acides aminés des chaînes A et B sont uniques à l’insuline.
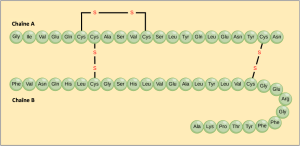
Le gène codant la protéine détermine en fin de compte la séquence unique de chaque protéine. Une modification de la séquence nucléotidique de la région codante du gène peut conduire à l’ajout d’un acide aminé différent à la chaîne polypeptidique en croissance, ce qui entraîne une modification de la structure et de la fonction de la protéine. Dans la drépanocytose, la chaîne β de l’hémoglobine (dont une petite partie est représentée à la Figure 3.26) présente une substitution d’un seul acide aminé, ce qui entraîne une modification de la structure et de la fonction de la protéine. Plus précisément, la valine de la chaîne β remplace l’acide aminé glutamique. Le plus remarquable est qu’une molécule d’hémoglobine est composée de deux chaînes alpha et de deux chaînes bêta qui comprennent chacune environ 150 acides aminés. La molécule compte donc environ 600 acides aminés. La différence structurelle entre une molécule d’hémoglobine normale et une molécule drépanocytaire – qui réduit considérablement l’espérance de vie – réside dans un seul acide aminé sur les 600. Ce qui est encore plus remarquable, c’est que trois nucléotides codent chacun ces 600 acides aminés, et qu’un seul changement de base (mutation ponctuelle), 1 sur 1800 bases, est à l’origine de la mutation.

En raison de la modification d’un acide aminé de la chaîne, les molécules d’hémoglobine forment de longues fibres qui déforment les globules rouges biconcaves, ou en forme de disque, et leur donnent une forme de croissant ou de « faucille » qui obstrue les vaisseaux sanguins (Figure 3.27). Cela peut entraîner une myriade de problèmes de santé graves tels que l’essoufflement, les vertiges, les maux de tête et les douleurs abdominales chez les personnes touchées par cette maladie. William Warrick Cardozo a montré que la drépanocytose est une maladie héréditaire, ce qui signifie que la différence dans la région d’encodage du gène spécifique est transmise des parents aux enfants. L’hérédité de ces caractéristiques est déterminée par une combinaison de gènes des deux parents, et ces très petites différences peuvent avoir des répercussions importantes sur les organismes.

Structure secondaire
Le repliement local du polypeptide dans certaines régions donne lieu à la structure secondaire de la protéine. Les structures les plus courantes sont l’hélice α et le feuillet β plissé (Figure 3.28). Les deux structures sont maintenues en forme par des liaisons hydrogène. Les liaisons hydrogène se forment entre l’atome d’oxygène du groupe carbonyle d’un acide aminé et un autre acide aminé situé quatre acides aminés plus loin dans la chaîne.

Chaque tour hélicoïdal d’une hélice alpha comporte 3,6 résidus d’acides aminés. Les groupes R du polypeptide (les groupes variants) dépassent de la chaîne d’hélice α. Dans le feuillet β plissé, la liaison hydrogène entre les atomes du squelette de la chaîne polypeptidique forme les « plis ». Les groupes R sont attachés aux carbones et s’étendent au-dessus et au-dessous des plis. Les segments plissés s’alignent parallèlement ou antiparallèlement les uns aux autres et des liaisons hydrogène se forment entre l’atome d’hydrogène partiellement positif du groupe amino et l’atome d’oxygène partiellement négatif du groupe carbonyle du squelette peptidique. Les structures en hélice α et en feuillets β sont présentes dans la plupart des protéines globulaires et fibreuses et jouent un rôle structurel important.
Structure tertiaire
La structure tridimensionnelle unique du polypeptide est sa structure tertiaire (Figure 3.29). Cette structure est en partie due aux interactions chimiques à l’œuvre sur la chaîne polypeptidique. Les interactions entre les groupes R créent principalement la structure tertiaire tridimensionnelle complexe de la protéine. La nature des groupes R des acides aminés concernés peut s’opposer à la formation des liaisons hydrogène que nous avons décrites pour les structures secondaires standard. Par exemple, les groupes R de même charge se repoussent et ceux de charge différente s’attirent (liaisons ioniques). Lors du repliement des protéines, les groupes R hydrophobes des acides aminés non polaires se trouvent à l’intérieur de la protéine, tandis que les groupes R hydrophiles se trouvent à l’extérieur. Les scientifiques appellent également les premiers types d’interaction des interactions hydrophobes. L’interaction entre les chaînes latérales de cystéine forme des liaisons disulfures en présence d’oxygène, la seule liaison covalente qui se forme lors du repliement des protéines.
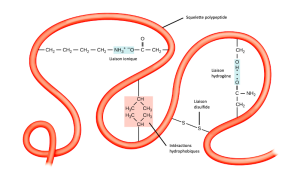
Toutes ces interactions, faibles et fortes, déterminent la forme tridimensionnelle finale de la protéine. Lorsqu’une protéine perd sa forme tridimensionnelle, elle peut ne plus être fonctionnelle.
Structure du quaternaire
Dans la nature, certaines protéines sont formées de plusieurs polypeptides, ou sous-unités, et l’interaction de ces sous-unités forme la structure quaternaire. De faibles interactions entre les sous-unités contribuent à stabiliser la structure globale. Par exemple, l’insuline (une protéine globulaire) possède une combinaison de liaisons hydrogène et disulfure qui lui permet de s’agglutiner en forme de boule. L’insuline est au départ un polypeptide unique et perd certaines séquences internes en présence de modifications post-traductionnelles après avoir formé les liaisons disulfures qui maintiennent les chaînes restantes ensemble. La soie (une protéine fibreuse), en revanche, a une structure en feuillets β qui résulte de la liaison hydrogène entre différentes chaînes.
La Figure 3.30 illustre les quatre niveaux de structure des protéines (primaire, secondaire, tertiaire et quaternaire).

Dénaturation et repliement des protéines
Chaque protéine possède une séquence et une forme uniques que des interactions chimiques maintiennent ensemble. Si la protéine est soumise à des changements de température, de pH ou à une exposition à des produits chimiques, la structure de la protéine peut changer, perdant sa forme sans perdre sa séquence primaire dans ce que les scientifiques appellent la dénaturation. La dénaturation est souvent réversible, car la structure primaire du polypeptide est conservée dans le processus si l’agent dénaturant est retiré, ce qui permet à la protéine de reprendre sa fonction. Parfois, la dénaturation est irréversible et entraîne une perte de fonction. La friture d’un œuf est un exemple de dénaturation irréversible des protéines. La protéine de l’albumine contenue dans le blanc d’œuf liquide se dénature lorsqu’elle est placée dans une poêle chaude. Toutes les protéines ne se dénaturent pas à des températures élevées. Par exemple, les bactéries qui survivent dans les sources chaudes ont des protéines qui fonctionnent à des températures proches de l’ébullition. L’estomac est également très acide, son pH est bas et il dénature les protéines dans le cadre du processus de digestion ; cependant, les enzymes digestives de l’estomac conservent leur activité dans ces conditions.
Le pliage des protéines est essentiel à leur fonctionnement. Les scientifiques pensaient à l’origine que les protéines elles-mêmes étaient responsables du processus de pliage. Ce n’est que récemment que les chercheurs ont découvert qu’elles sont souvent aidées dans le processus de repliement par des protéines auxiliaires, ou chaperons (ou chaperonines), qui s’associent à la protéine cible pendant le processus de repliement. Ils agissent en empêchant l’agrégation des polypeptides qui composent la structure complète de la protéine et se dissocient de la protéine une fois que la protéine cible est repliée.
