14 Chemistry of nucleic acid bases, nucleotides & polynucleotides

Friedrich Miescher (1844-1895)
Nucleic acids, RNA and DNA, which are the biochemical macromolecules encoding genetic information, have been known as chemicals since the 19th century. Friedrich Miescher (Figure 14.1) first isolated them from nuclei of white blood cells in 1869. He called it “nuclein”. However, their vast biological significance was not appreciated until the 1940s.
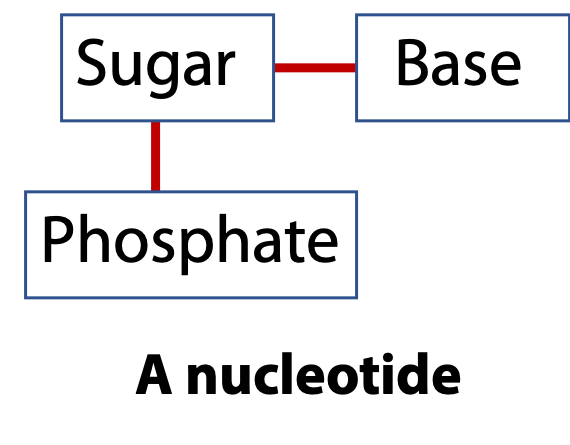
Nucleic acids are linear polymers like proteins. Proteins are made by connecting amino acids via peptide bonds. Nucleic acids are made by connecting nucleotides via phosphodiester bonds. The repeating unit is the nucleotide. The nucleotide, in turn, is built from three components: a sugar, a base, and a phosphate group (Figure 14.2). There are two types of the nucleic acid sugars and four different bases.
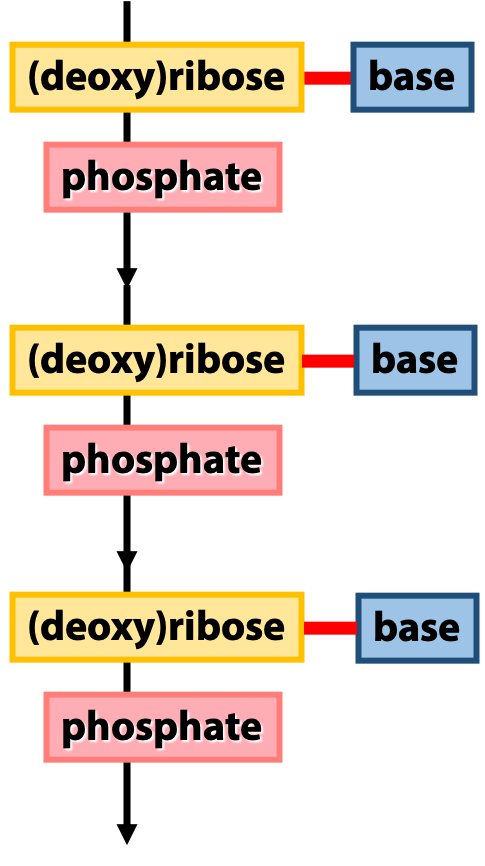
Figure 14.3 shows an overview of the architecture of nucleic acids. The backbone of a nucleic acid is built from the sugars, linked together by the phosphates. We call this the “sugar-phosphate backbone”. The bases (which carry the genetic sequence information) are linked to the sugars. We can think of the sugar-phosphate backbone as analogous to the peptide backbone of a protein, and the bases as analogous to the amino acid side-chains. (This is just a rough analogy
a
Sugars

D-Ribose is the sugar in RNA. It’s a pentose aldose sugar. As shown in Figure 14.4, it forms a furanose ring. In the nucleic acids, it is in the beta anomeric form.
DNA is deoxyribonucleic acid and its sugar is D-2-deoxyribose. It’s an unusual sugar: one of the -OH groups – the one at C2 – is missing. Instead, that carbon is -CH2 (Figure 14.4). That’s why it is called deoxyribose: an oxygen atom is missing. Deoxyribose is a reduced sugar: one C is reduced from -CH(OH) to -CH2 (methylene). As we will see later, this difference causes DNA to have very different properties from RNA. Deoxyribose, the DNA sugar, is so peculiar that its structure wasn’t figured out until about 1930, long after most other sugar structures were known. Both ribose and deoxyribose occur in their β-furanose form.
The Bases
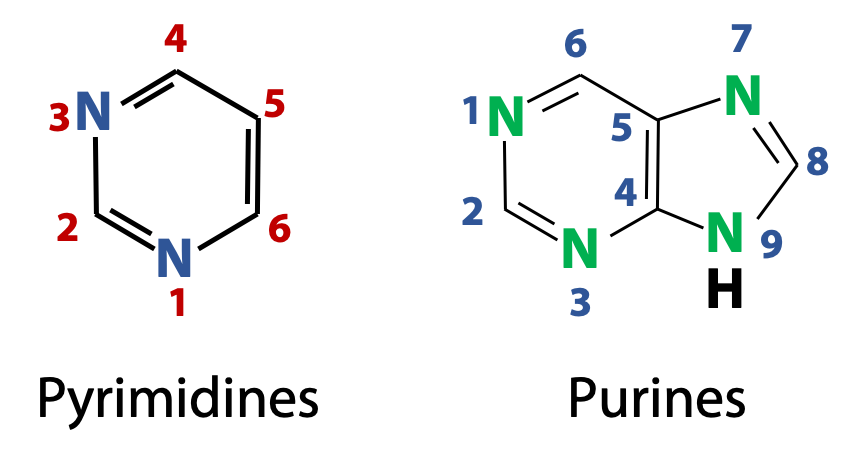
The nitrogenous bases found in nucleic acids are derivatives of two parent compounds, pyrimidines and purines (Figure 14.5). The numbering convention used for pyrimidine and purine heterocycles are shown in the figure. (What’s a heterocycle? It’s just like an aromatic ring, such as benzene, except that there are heteroatoms in the ring. Heteroatoms are non-carbon atoms, such as N, O, and S. But we will only see N atoms in the rings of the nucleic acid bases).
Pyrimidine bases of RNA and DNA
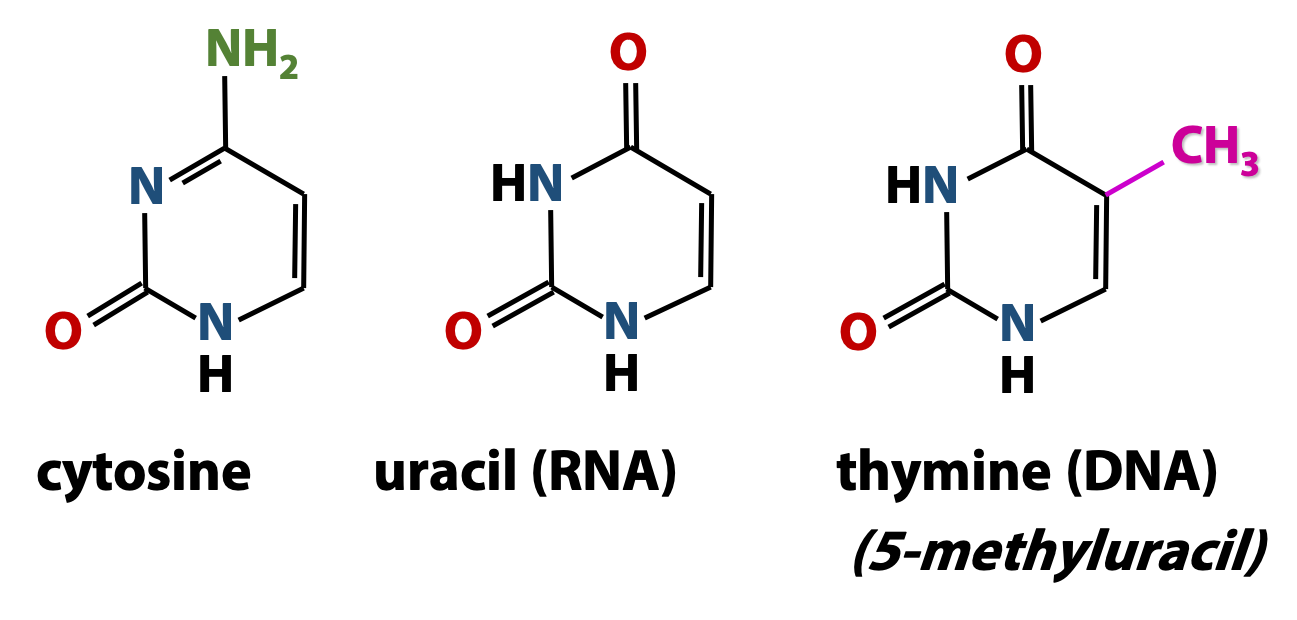
Both DNA and RNA contain two major pyrimidine bases (Figure 14.6). One of them, cytosine (C) is found in both DNA and RNA, but the second pyrimidine is different in DNA from what is found in RNA: thymine (T) in DNA and uracil (U) in RNA. Thymine is just like uracil, except that it has a methyl group at position 5. Therefore, thymine is also called “5-methyluracil”. Thymine takes the place of uracil in DNA because thymine has greater resistance to photochemical mutation from things like UV radiation from the sun.
Tautomers
Nucleotide bases may exist in two or more tautomeric forms depending on the pH. Tautomerism is a form of chemical equilibrium which we encounter repeatedly in biochemistry. We can define tautomers as isomers which differ only in the positions of protons (and, as a consequence, double bonds). The heavy atom “skeleton” of the compound remains unchanged. (Don’t confuse tautomers with resonance hybrids. When we draw a pair of resonance forms of a molecule, we are just indicating two different valence-bond representations of a single chemical species – no atoms are moved.)
Tautomeric forms of cytosine

Nucleic acid bases are heterocycles “decorated” with -OH and -NH2 groups. As a result, there are a lot of opportunities for tautomeric equilibria. Figure 14.7 shows three forms of cytosine. The -OH group undergoes keto/enol tautomerism, and the -NH2 group undergoes amino/imino tautomerism, as shown. The form shown in the middle (amino + keto) is predominant.
Purine bases of RNA and DNA

There are two purine bases in RNA and DNA (Figure 14.8). They are adenine and guanine. Adenine is 6-aminopurine. Guanine is 6-oxo-2-aminopurine. Purines are bigger than pyrimidines. The purine ring is a fused (joined together) bicyclic (two rings) heterocycle. The six-membered ring on the left is just like pyrimidine. The five-membered ring on the right is just like imidazole (the side chain of the amino acid histidine). There are four N atoms and five C atoms in the purine ring system. Note that there are no N-N bonds: the N atoms are always separated by at least one C atom. (Some of the common names of the bases reflect the circumstances of their discovery. Guanine was first isolated from guano (bird manure), and thymine from thymus tissue).
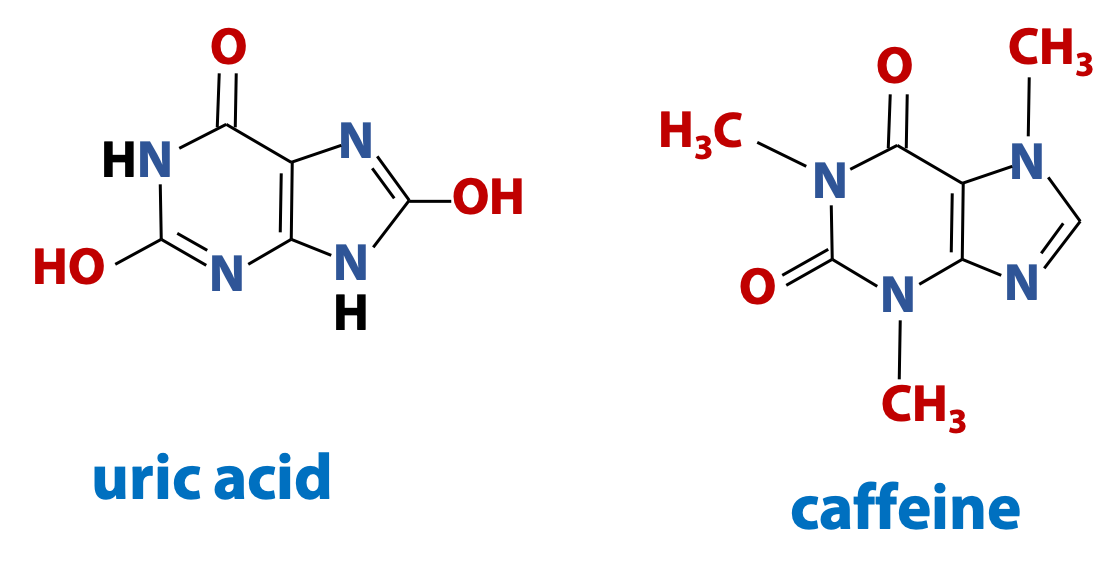
Purines are important molecules in biochemistry. They are components of nucleic acids and they are also found in many other biological contexts (Figure 14.9).
For information only – not to be examined: Uric acid is the major form of nitrogenous waste eliminated by birds and reptiles. And 1,3,7-trimethylxanthine, is the purine that better known as caffeine. Chocolate contains a closely-related purine called theobromine (3,7-dimethylxanthine). [There is no bromine atom in theobromine, so where does that name come from? Well, theobroma cacao is the Latin name that Linnaeus gave to the cocoa tree. “Theo-broma” in Greek is “food of the gods”].
Nucleosides
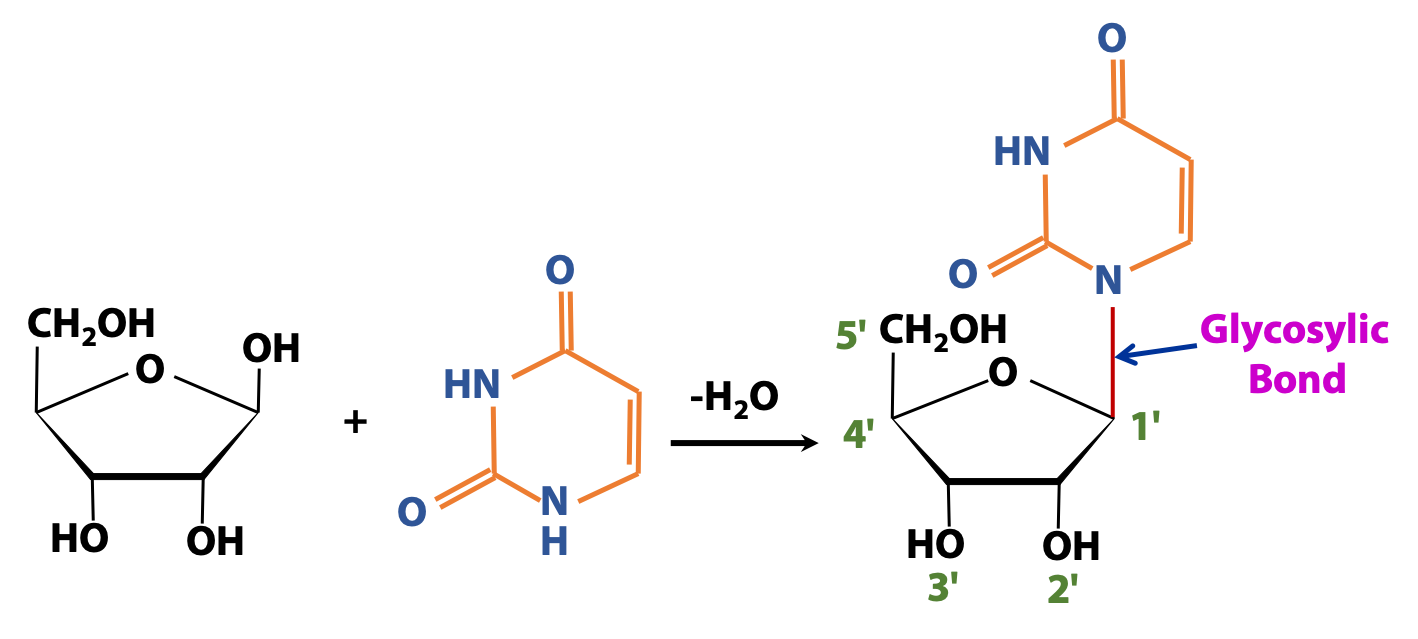
Base + sugar = Nucleoside.
Figure 14.10 shows an example of a nucleoside, a special type of glycoside found in nucleic acid. The sugar shown is ribose. The base is uracil. Uracil is an amine (-NH). (The amino group is part of a heterocyclic ring.) We form a glycosidic linkage (highlighted in red) (specifically called a glycosylic bond to designate the C-N linkage) between the anomeric C of ribose and the ring N of uracil, to form a nucleoside.
Tricky point: There are two different -NH groups on uracil, but only one is involved in the glycosidic bond in a nucleoside. The other possibility might be chemically realistic, but it’s not found in any biochemicals.
Numbering: We have seen how we number the C atoms in a sugar: 1, 2, 3, …
Once we form a nucleoside, it gets potentially confusing, because we need to number the positions on the sugar and also on the base. To avoid confusion, we will distinguish the positions on the sugar by adding a “prime” superscript, when we discuss nucleosides. So the sugar positions are called 1′, 2′, 3′ …

Figure 14.11 shows how the purine and pyrimidine bases are joined to the sugar. The -NH at position 9 of purines links to the anomeric carbon of ribose/ deoxyribose. Look at how that differs between pyrimidines (N1) versus purines (N9).
Table 14.1 lists the names of the bases and the nucleosides. You need to learn these names; they are used all the time in nucleic acid biochemistry and molecular biology.

We distinguish the deoxynucleosides (DNA) from the nucleosides (RNA) by adding the prefix “deoxy”, and we abbreviate them as dA, dG, dC. But thymidine is found in DNA only, not RNA. So we don’t normally talk about “deoxythymidine”. We just call it thymidine. It’s assumed to be deoxy.
Phosphate esters

As we have seen earlier, phosphoric acid is a triprotic acid: it has three dissociable protons. An organic acid like acetic acid, with only one dissociable proton, can only form a monoester. But phosphoric acid can form monoesters, diesters, or triesters (Figure 14.12). The monoesters and diesters are common in biochemistry, but triesters do not occur.
Nucleotides

Base + Sugar + Phosphate → Nucleotide
Adding a mole of phosphate to the sugar converts a nucleoside into a nucleotide (Figure 14.13). Nucleotides are phosphorylated nucleosides. The figure shows a nucleotide in which phosphate is added to the 5′ -OH group of the sugar. It is a deoxyribose 5′-phosphate.
Polynucleotides
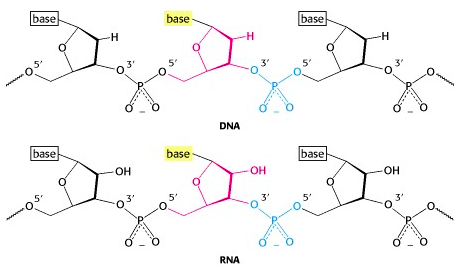
We can link the sugar of a nucleotide to another via a phosphodiester bond. Actually, there are several ways we could do that … but only one way is found in nucleic acids.
A phosphate group bridges between the 5′-OH of one nucleotide unit and the 3′-OH of another (Figure 14.14).
Each linkage is an ester linkage, so we call this a phosphodiester bond. As we form the chain (which we call a polynucleotide, analogous to the polypeptide chain in a protein), we see that we have a 5′ end and a 3′ end (analogous to the amino and carboxyl ends of a polypeptide chain).
Note: The phosphodiester bond is between the 5′ and the 3′ -OH groups. The 2′-OH of RNA is not involved! So the linkage pattern is the same for DNA (which does not even have a 2′ -OH) as it is for RNA.
The backbones of both nucleic acids are hydrophilic and are formed by alternating pentose and phosphate residues. The -OH groups of the sugar residues form H-bonds with water while the phosphate groups are completely ionized and negatively charged at pH 7.
Nucleotide sequences are written from 5′ to 3′
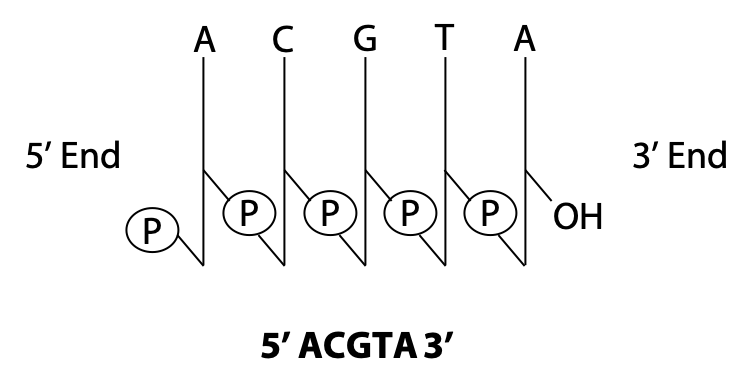
We can use shorthand to represent a polynucleotide. In the stick diagram in Figure 14.15, the vertical sticks represent the sugars, and the diagonal slashes represent the phosphodiester bonds. The letters at the top represent the bases.
We can also write down only the sequence, as shown in Figure 14.15. By convention, we write nucleic acid sequences from 5′ to 3′, left to right. (This is just like the convention that we write polypeptides from the amino end to the carboxylate end.) It is very important to get this correct. 5′ACGTA 3′ is a different polynucleotide from 5′ ATGCA 3′!
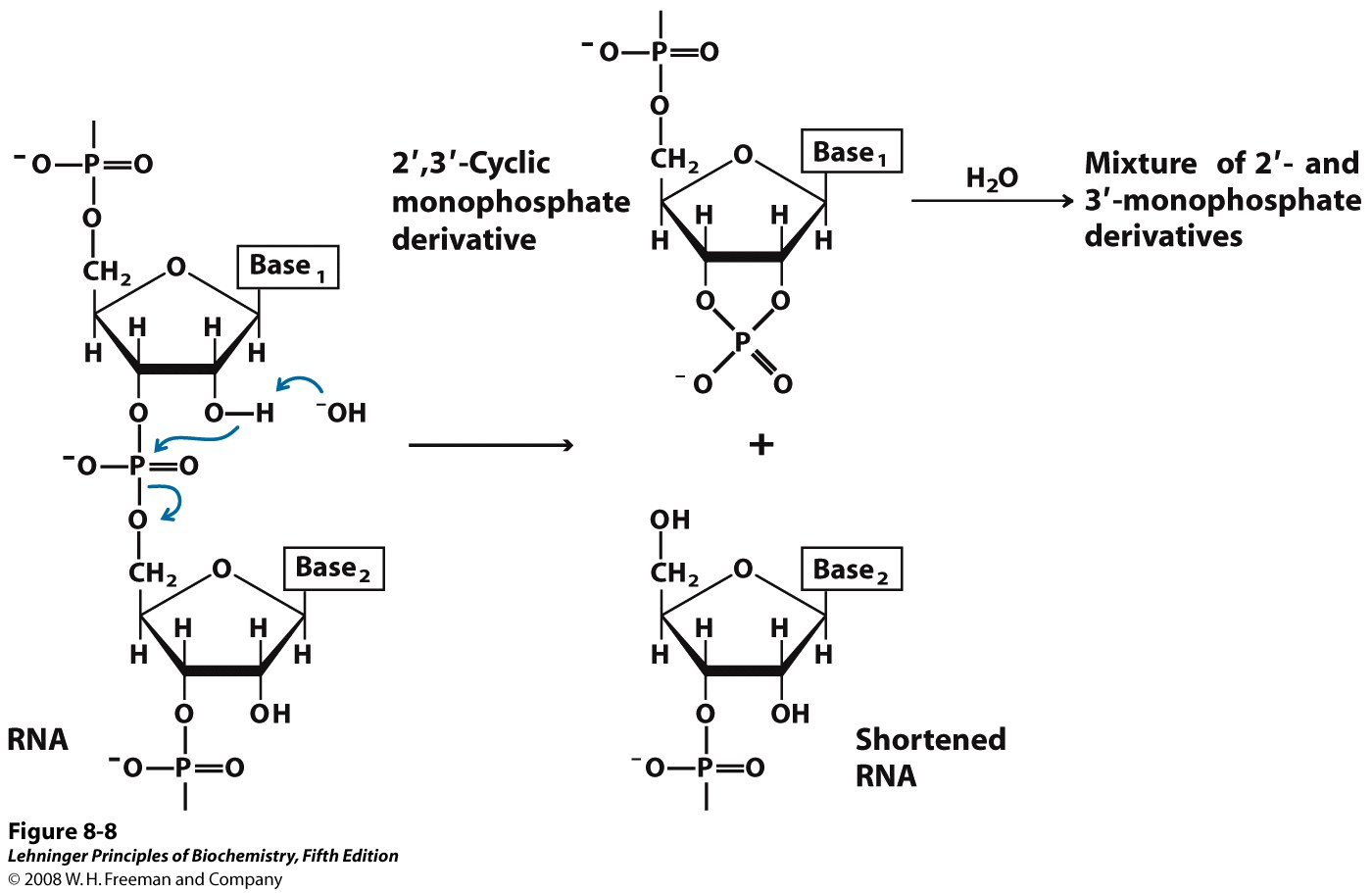
RNA is very easily hydrolyzed; DNA is much more stable
RNA is hydrolyzed rapidly under alkaline conditions, but DNA is not. The 2′ hydroxyl of RNA, (which is absent from DNA) acts as a nucleophile in an intramolecular displacement to hydrolyze the phosphodiester bond of RNA (Figure 14.16). This inherent instability in RNA means that RNA must be handled and stored very carefully. (For example, the Pfizer and Moderna vaccines to the coronavirus responsible for COVID-19 are RNA-based, requiring special care and complicating access to vaccination)
Self-assessment Questions
1.
2.
3.