Trustless Systems

This might seem like a bit of an odd thing to put in to a book about trust systems, but it’s a bit of an odd book, so that’s one thing. Actually, trustless systems are, despite the idea that they might be trust-free, taking trust to a different kind of consideration. When we talk about trustless systems, we’re mostly thinking about blockchains, and this chapter will look at those. After which, we’ll have a little journey into things like zero trust security. It’ll be fun.
Trustless Systems and Blockchain
But before I go any further in this chapter, it is important to give a huge thank you to Professor Nitin Kale who over the course of two wonderful and engaging SAP bootcamps explained more about blockchains than I could ever do, and graciously agreed to read and comment on a draft of this chapter for me.
Back in the financial crisis days of 2008, a paper was released by a certain Satoshi Nakamoto. It was entitled A Peer-to-Peer Electronic Cash System and it described in quite a lot of detail a process by which one could create a system of electronic money. Money is odd stuff – it requires certain things before it can actually be considered to be money – things like exchangeability, ownership, non-repudiation, and value (perhaps through scarcity, perhaps because it takes an effort to make or get it, and so on. Nakamoto’s idea was to have a consensus-based hashed linked list to allow for these things to be achieved. The money was called Bitcoin, but the technology that it is based on is called a blockchain.

Plenty of things have been written about blockchains, Bitcoin, Ethereum and so on, and indeed many many different electronic money systems exist. As well, many different blockchains exist, both public and private, to do all kinds of interesting things beyond money: smart contracts, real estate, international shipping and more. I don’t need to add much more to that collection of literature, so this chapter is going to very quickly describe how blockchains work and a few use cases that are interesting from the point of view of trust (and no trust) and not go all in on how the idea might change the world and the way we work, live and play (If you’re looking for utopianism you may have spotted by now that I’m not that into it).
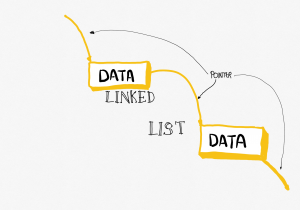
A blockchain is a hashed linked list. To a computer scientist (me!) this is not entirely new – I learned about linked lists when I was an undergrad (at Stirling University) in the 1980s – but the way in which the blockchain works is quite intriguing because of the way it brings in cryptography and things like proof of work (PoW). Let’s go through this from first-ish principles, starting with the concept of linked lists and going from there.
Imagine a scavenger hunt. You have to solve a clue to find the next clue, and so on, through a big ‘chain’ of clues until you get to the final prize. Each clue in the chain has a small prize associated with it so that getting there first is fun. It’s a race, but when you find a clue you leave it where it is so that the other people playing have a chance to solve it too (but take the prize!). Each clue points to the next clue, and so on.
This chain of clues is akin to a linked list. Except that a linked list is stored in a computer. And you don’t need to solve clues (usually – we’ll get back to this later though). The way it works is very similar: each item in the list has some data associated with it (the data can be anything you like, just like the prizes in the treasure hunt – names, addresses, pictures, whatever, it’s just data). It also has a pointer to the next item in the list. A pointer in computing terms is just like an address. It tells the computer where the next item is in memory or storage or wherever, much like the clue in the scavenger hunt ‘points’ to the next clue.
And that’s it. We have in each item two distinct things (see figure 10.3):
- The data;
- The pointer to the next item in the list.
You can get a bit more clever because sometimes it would be nice to be able to go backwards and forwards in the list (say, when you’re searching for stuff, or re-arranging the list in some way, which we won’t talk about because it can get interesting quite quickly!). In that case the items in the list contain:
- A pointer to the previous item in the list;
- The data;
- A pointer to the next item in the list.
It’s pretty neat actually, there’s all kinds of different structures you can make out of it if you add more pointers and so on, but I think this is good enough for now.
So that’s a linked list, but what about a hashed linked list? It’s pretty straightforward, it just brings in a bit of cryptography for a few different purposes. The first of these is that you’d know if something changed. To get to understanding that, let’s quickly talk about Hashes.
A hash function is a function that takes data of any length and reduces it to data of a fixed length. Any length is not an exaggeration. You can hash single words and you can hash entire encyclopedias and the end result is a single fixed length piece of data. It should also be deterministic, which means that the same input will always give you the same output.
But blockchains use cryptographic hashes. So what does this mean? Basically it adds a few requirements to that fixed length, deterministic one.
The first of these is called pre-image resistance (I know, it’s funny how different fields all have their own little ways of talking). Pre-image resistance goes like this: If you’ve got a hash (call it h) it’s difficult to find a piece of data (which in the hash world is called a message, so we’ll call it m) that will give you that hash value when you pass it through the hash function. This means that the function is basically one-way – you can get a hash from a message, but you can’t get the message from the hash easily.
The second quality we’re looking for is called second pre-image resistance. This basically means that if you have a message, which we will call m1, then it should be difficult to find another message (call it m2) that gives you the same hash. This is also called weak collision resistance because in hash world, a collision is two messages having the same hash (which then we have to do something about, like create a bucket of messages that have the same hash).

Why is it called weak collision resistance? Because we have a strong collision resistance too! This is quite similar but it says that for two messages (we’ll call them m1 and m2 again) that are different, then it should be difficult to find a hash for m1 that is the same as the hash for m2. This sounds the same as the weak one but isn’t quite, if you think about it carefully.
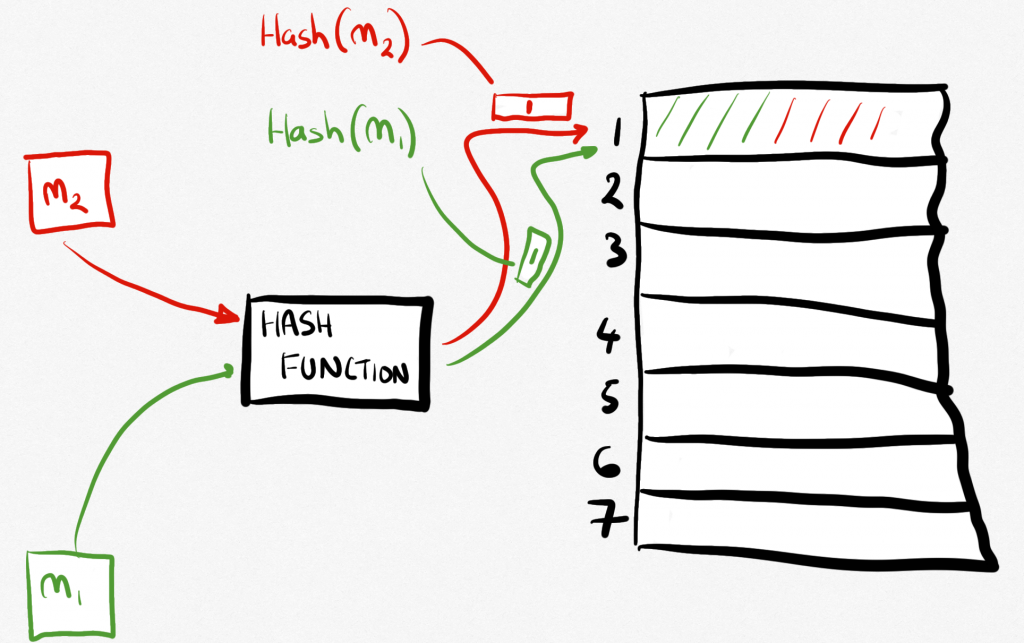
Those things all say difficult which basically means very hard but also in more technical terms means ‘would take an awfully long time’.
There’s also something called the avalanche effect which is nice to have. It basically says that a small change in message (say from “Steve is wonderful!” to “Steve is wonderful?”) would result in wildly different hashes from the hash function[1]. Finally, the function has to be uniform, which means that the probability of one hash number is the same as all others. This will come in useful in a moment.
Why are all these things important? Because when the function meets them, there’s very little chance that an attacker can get a hash and find out what it is the hash of, as well it would be really easy for anyone to know if the message was somehow changed (because the hash would be very different).
Bitcoin (and lots of other blockchains) uses the SHA-256 hash function, which is from a family of functions called SHA-2, which was developed by the US National Security Agency. It’s pretty secure. The number of possible hashes is 2 to the power 256 (  – see Figure 10.5) which is quite a large number. The hashes are all 64 hexadecimal characters long. It meets the properties we talked about just now.
– see Figure 10.5) which is quite a large number. The hashes are all 64 hexadecimal characters long. It meets the properties we talked about just now.

Smashing, now you know all about hashing!
Bitcoin, if you are interested, uses this SHA-256 function to encrypt usernames (so that there’s privacy) as well as for something called proof of work. Which we’ll get to in a bit.
Okay, so now that we’re okay with cryptographic hashing, how does this work with the linked list thing? The first thing to bear in mind is that we want to be able to know if someone changes stuff. If they can do it without us spotting it, then we have a problem. In an electronic cash example, you could send money to someone and then go back and change the fact that you had sent it after you got the thing you were paying for. This is clearly not a good thing. So we’re looking for some guarantees that if someone tries to change stuff, we’ll know. Secondly, we’re looking for guarantees that what has happened will stay happened. You may have spotted that our cryptographic hash stuff helps there.
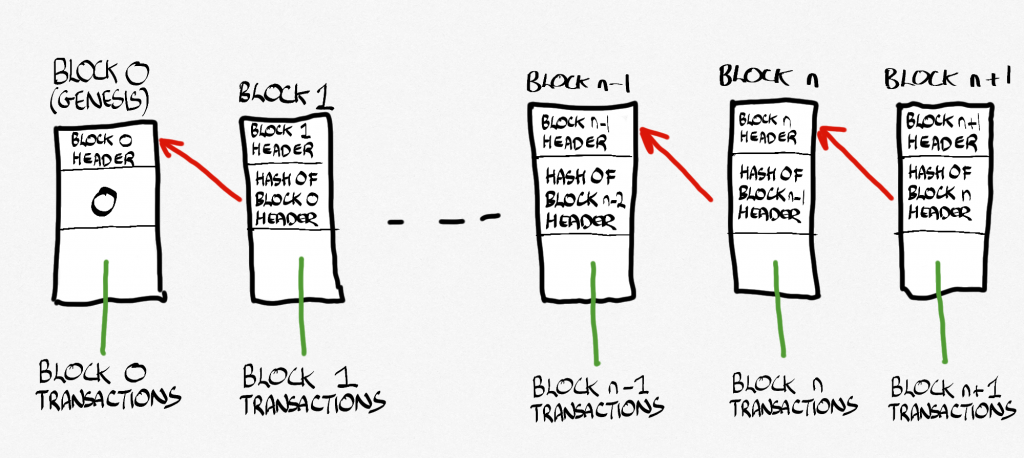
As far as blockchains are concerned, the links in the linked list point backwards. That means that every block of data has a pointer to the block that came before it, not after it like in the scavenger hunt. All the way back to the first block, which is called the genesis block. Imagine a murder mystery where you work backward from what happened (the victim is dead) to how it happened (the actual murder). Okay, so that wasn’t a brilliant example but you get the idea.
Why do the links point backwards? Because we want to be able to look back through the history of all the things that happened so that we know that they did. If we see a transaction, say, and the hashes for that data are correct (it hasn’t been changed) they we ‘know’ that the transaction happened.
Now, if you look at pictures of blockchains on the web you will likely see the pointer going forwards. This is not really how it works (they basically point backwards – the pointer is a hash of the block header from the previous block), but there you are.
Here’s a fifty-thousand foot view of what happens in practice. Every so often a block gets created (we’ll come to that in a second). That block contains a set of transactions (in Bitcoin they would be someone sending money to someone else, for instance). We know the block that came before (everyone can have a copy of the entire chain if they want). We don’t need to actually point to it like we would in a regular linked list. What we do is hash the header of that block (you can see a header in Figure 10.8). This gives us a hash that we can include in the new block as part of its data. The rest of the data is pretty much transactions, which are stored in the form of what is called a Merkle Tree (the details of which aren’t really that important here). This is itself hashed (so that we can know what length it will be, you see, as well as knowing if something gets changed, because if it did, the hash would change). The hash of that gets put into the header of the block. There are a few bits of metadata that help the chain figure out what version it is, when it was made, and something called nBits, which relates to proof of work, and these are also stored in the block’s header.
And then there is one small thing called a nonce (fun fact: nonce means number used once. Oh, the fun computer scientists have).
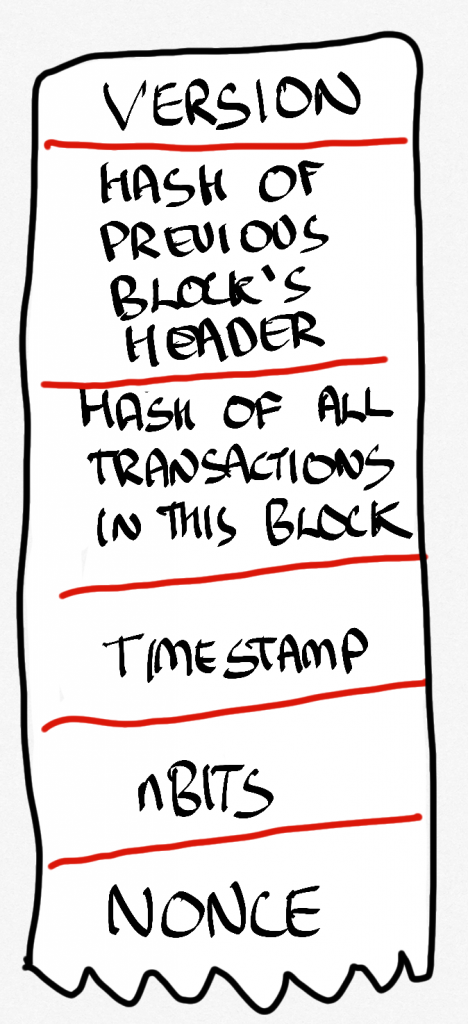
Here’s where the proof of work thing comes in. You see, there is a reward (in Bitcoins if we look at that blockchain) for actually creating blocks, it’s called mining. If it was really easy to make blocks, everyone would do it and the cash would be effectively worthless: neither rare nor hard to get.
So, to complete the block, the miner has to find a number (the Nonce) that would mean that when the block data (which is the transactions, the hash of the previous block and the Nonce) is hashed it has a set of, for example, 4 or 5 or whatever zeros in front of it (or some other kind of pattern). Remember that nBits in the header? In a nutshell, that is the number of zeros we’re looking for. It changes as the blockchain gets older.
Remember that the hash function is uniform: the probability of one hash is the same as for any other hash. So how do you find a hash with lots of leading zeroes? Start with the Nonce being 0, hash the whole thing, and see what you get. If you don’t get what you are looking for, add one to the Nonce (now we have a Nonce of 1) and hash it again. And so forth.
Basically, count up from 0 until you find the first hash that has several preceding zeros. You can (and miners do) split up that counting, so for instance you could have ten machines, one of which starts with a Nonce of zero, the next with a Nonce of, say, 1,000,000, the next with a Nonce of 2,000,000 and so on. Which (if the hash space was ten million) would effectively do the search in around a tenth of the time. But the hash space is actually , which I am reliably told is larger than the number of grains of sand on the planet. This led me to wonder who counted them, but no-one has been able to answer that question. Anyway, it’s huge, but there’s no way to find the thing you’re looking for other than starting at the bottom and going up.
This, naturally, can take time and it takes huge quantities of computing power (seriously, these miners have massive numbers of highly optimized machines basically searching for the right Nonce.
And when they have found the right Nonce, they push the block, the Nonce and the hash out to the community. It gets checked and, if they all agree that it is correct, and it is the first one there, it gets put on the chain ready for the process to start all over again.

That search is called proof of work and it’s how miners prove they didn’t cheat and mess about with the data in the transactions, for one thing. It is rewarded with new coins (which is why it is called mining) as well as promised transaction fees from the people whose data is in the transactions for the block. In effect you can offer nothing, but it’s unlikely that any miner will choose to take that transaction and put it in a block because it’s worthless to them. Which brings us to the final aspect of all this, the mempool, which is a big collection of all the transactions that have been put in play by people (like writing a cheque, really, for instance) that haven’t been mined (put into a block) yet. If they’re not in a block on the chain, they haven’t actually happened. Miners pick the juiciest (best paying) transactions and put them in blocks to mine (find the Nonce) and get rewarded for doing so.
If you have been paying attention you will notice that I said “the first one there” when I talked about the community verifying the work done. That’s because there are lots of miners, all of whom are beavering away at finding those happy Nonces. It’s a race. First to get there wins everything. And if you’re not first, the block you were working so hard on empties back into the mempool and you start again.
Phew. Blockchains in something like ten minutes.
I should probably talk about proof of stake whilst I am here. You see, proof of work has some serious shortcomings. For one thing it takes huge amounts of power to keep all those miners’ computers going. Seriously. Bitcoin, for instance, has an annual carbon footprint around the same size as New Zealand (if you want to see the statistics, here is a good place: https://digiconomist.net/bitcoin-energy-consumption). For a single transaction, the carbon footprint is equivalent to almost 700,000 VISA transactions. We’re not talking small change here.
At this point, take a thought as to the environmental impact of Bitcoin alone. To a certain extent, this is in the realm of “just because we can do something doesn’t mean that we should”.
Naturally this is very expensive. Which means that miners sell the bitcoins they are rewarded with to pay for it all with money in the ‘real world’ (technically, it’s FIAT money). This has a few different effects. The first is that it devalues the worth of the currency itself (in this case Bitcoin). The second, more serious, goes a bit like this…
There is a limit on the amount of Bitcoin out there. It’s built in to the system itself. Eventually, the miners will run out of coins to mine. This means that the only reward they will get for creating blocks is that which the transacting parties are willing to pay. This will decrease over time rather than increase (at this point the transacting parties are the ones with the power) and so, eventually, will the number of miners (it’s not financially viable).
Here’s the thing. Bitcoin, indeed all blockchains, are only secure against attack from anyone who has less than 51% of the miners. If someone is in that position, they can create their own transactions, invalidating anyone else’s, and no-one would be able to stop them. Naturally this is something of an issue if, for instance, you’re only left with a couple of miners doing all the work.
Sooner or later, it’s always all about trust. Bet you knew I would get to that. Moving on.
Proof of stake is an idea that says: instead of miners proving that they did a bunch of work, which is basically unsustainable in the long term (I would venture to suggest the whole thing was unsustainable in the beginning, but that’s what happens when you get computer nerds to try to solve a puzzle: they throw power at it), let’s make it so that miners can only mine based on a percentage of the coins that they themselves hold. They have a Stake in the success of the currency. This means that even if they did get to 51%, they wouldn’t want to screw around with the currency because they would actually have 51% of the coins and they’d be hurting themselves quite a lot. It also means that relatively small miners can do some work if they have a small stake.
Bitcoin uses proof of work. Ethereum (another blockchain which I’ll come to later) is moving to proof of stake. There are innumerable blockchain cryptocurrencies out there[2] and some use either whilst some use hybrids of both. But at least now you know what it all means.
To get back to the point quickly: if someone wanted to go back and change a block, say by putting an additional 0 on the money that they were paid, a few things will happen:
- The hash of the block will be incorrect
- So they will have to re-mine the block (remember, it’s expensive!)
- But if they do that, it will invalidate the hash of the next block because the next block uses the previous block’s hash and, well, it’s different now).
- This would mean they’d have to re-mine that next block.
- And so on, until they get back to the top of the chain, which, because time does not stand still, has been moving forward anyway, meaning that they’d have to re-mine a whole bunch more blocks and still fall behind.
The further back the block, the more infeasible it becomes to change it. That’s why some people wait until transactions are a few blocks back before they finish the transaction. That is, if I paid you a million bitcoins for something in a transaction, you might well wait for ten or more blocks to be created on top of the one with that transaction in it before you, say, sent me the super yacht.
Why would you send it, you ask? Because you can’t at this point say that you weren’t paid: it’s easy to go back and prove it, because it’s on the chain. And I can’t get the yacht and grab the money back by changing the block the transaction is in because it would be far too expensive, I may as well let you keep the darn yacht.
If you‘re interested there’s really neat example of blockchains (and hashing) here, courtesy of Anders Brownworth. It shows a bunch to the stuff I’ve just been writing about quite nicely and there are even some videos. And unlike other blockchain demos it doesn’t require you to give it your email address so that it can spam you forever.
Now, blockchains are sometimes called trustless technologies. This doesn’t actually mean what you think it might mean. In fact, trust is very much a part of the picture. Did you spot why?
It’s like this. Blockchain technology allows for interactions and transactions in situations where there is either no trust or not enough trust. It does this by taking the thing that people are concerned about and replacing it with something that they are not. To be more precise, it allows people to trust the technology in the place of trusting the person. If you wanted to be more pedantic you might say that it allows people to trust a society that ratifies a certain transaction rather than having to trust the person they are transacting with.
This is actually very important. Things like this allow for collaboration and cooperation where trust is in short supply. And that helps the world go round.
System Trust
But here’s the thing: blockchains don’t do away with trust, they just move it someplace else. I’ve talked about system trust a couple of times in the book, and it’s a good time to look at it here because of how it applies to blockchains. It doesn’t just apply to blockchains though, as we’ll see.
System trust isn’t a new concept. In fact it was called ‘institution-based trust’ in a paper by McKnight, Cummings & Chervany (1998), itself referring back to Shapiro’s (1987) “The Social Control of Impersonal Trust”. What is interesting about the Shapiro paper is that it finds that the various social trustees that we put in place to help protect us against the need to trust are themselves trusted (naturally). This leads to problems because it’s rather paradoxical. The problem? We don’t get rid of the need to trust when we rely on other systems, we just shift it someplace else. Sound familiar?
Sure, it’s more complicated than that, so let’s explore it a little further. It’s like this: there are many many times every day when we engage with agents over whom we have no control – insurance companies, pharmacists, specialists, the government and so on. The reasons are many, but to quote Shapiro (page 630):
“unwitting principals, blinded by distance, organizational structure, secrecy, and lack of expertise, idly await the future dividends of symbolic promises made by faceless strangers.”
The only real control we might have is to simply not engage, and that’s rather problematic if you want to continue to exist in a complex society. The problem, you see, is that all of the little things we put in place to help us move around this complexity are founded on trust (they certainly hold up to a definition of putting oneself in the control of others) but the systems in place actually do little to help enforce the correct behaviour of the others involved. Shapiro calls them ‘Guardians of Trust”, and they can be seen as enforcing things like fiduciary trust (which you’ve seen before when we looked at Barber earlier).
So who watches these watchers[3]? Who, in the final analysis, ensures that the “Guardians of Trust” are trustworthy? Well, naturally people put in place to watch them. Perhaps you can see the problem, since at this point it probably makes sense to put people in to make sure that those watchers are themselves trustworthy… As Shapiro says (page 649):
“One of the ironies of trust is that we frequently protect it and respond to its failures by bestowing even more trust.”
And that’s basically system trust. As problematic as it is, we put trust in the systems around us to ensure that the people around us that we can’t control behave properly when we are not in a position to know if they are. And so forth. It’s at this point where you might be asking “well, are there any other trustless technologies than blockchains?” This is a pretty good question.
Most importantly, there is actually something called zero trust in the realm of Enterprise solutions (not the space-ship). Let’s take a look.
Zero Trust

Before we start, the basic premise of zero trust is that your systems are already being attacked. I’ve often started talks about trust and security with the basic statement that if you have a system connected to the Internet, either your system is compromised now or it will be soon To put it another way, zero trust assumes that there is definitely an attacker in the system. This is not an unreasonable assumption. It also means that, regardless of whether you are “inside” your own “protected” system or not, you can’t assume that it is trustworthy. I first identified zero trust as a special thing in my PhD thesis back in 1994, but as a security practice, zero trust was advanced by a certain John Kindervag at Forrester. It is worth noting here that in general zero trust applies to things (computers and such) in a network, and people have coined the term “next generation access” to take this to people in a network, but for now we’ll mix them all up into the single term of zero trust.
So how does this all work?
Traditionally, security goes something like this: put up a bunch of firewall, use defence in depth, make sure that the perimeters of your systems are protected and “impenetrable”. As well, is people need to be off site and away from the network, use things like VPNs (Virtual Private Networks) to ensure that, although they are away, they are still ‘within the perimeter’. Much of this uses things like encryption, packet monitoring, access control tools, some AI perhaps to spot traffic that doesn’t seem ‘right’, and so one. In other words, a whole bunch of tools to ensure that your internal network is ‘secure.’ And then we call it ‘trustworthy.’ This sounds like a great thing until you realize a few different issues.
The first is that there are people in your network and, like it or not, people are special. They will write passwords down on Post-It Notes, they will forget to change the network their computer has access to when they are at home, they will be susceptible to things like phishing attacks and so on. People are often said to be the weakest link in a security chain. When you look at all the things that might go wrong because of them, you might think that this is a reasonable description. We’ll get back to that!
The second issue is that generally, if something gets ‘behind’ all your protections, the protections themselves don’t tell you. In other words, when they fail, they fail silently. The end result is that anyone or anything who is in the system with nefarious intent is pretty much in the clear unless you do some hard looking yourself. Some logs might help (and indeed do) but you need to look at them and see the issues.
And third? When something is inside, the permissions are quite open, especially if you have been relying on the perimeter to protect you. Christian Jensen, a colleague of mine from DTU in Denmark, likens this to a medieval castle. It has strong walls but the odd chink in the mortar that might just let a person inside if your sentries are not paying attention. Once inside, that person could dress like a soldier, or a peasant, or whatever, and get places you don’t want them to with impunity. Remember that Handsome Prince story? Well, when the Prince got into the tower he’d got through the defences and could do as he wished, basically. Those issues are evident when you look at things like foreign access to US infrastructure that has been reported recently here or the SolarWinds debacle. It’s not getting any better, because…
Fourth, you’re in an arms race. You put protections in, the bad folks try to break them, developing bigger and better tools to do so and selling them to the people who want to break in. And so on. The thing about arms races is that they never end. Meanwhile, the bad people only have to succeed once whilst the security folks have to succeed every single time there is an attack. Not great odds.
Finally, this: we are great at making tools that take away some of the issues that we associate with people: we have spam filters, phishing attack filters, firewalls, different kinds of authentication and so on (we’ll get back to the authentication thing. We’ll also talk more about attacks later in the book). The thing is, many of these tools spot and deal with attacks that would be obvious to the human anyway, and let through the things they can’t spot to allow the human to figure them out. Most organizations will train their people in security but hardly ever enough[4]. Thus, the person doesn’t see the attack because:
- They were never trained to see it; and anyway
- It’s hard to spot. Because if it wasn’t the automatic systems would have spotted it!
At which point this becomes a human fault (or as some smart security types say PBKAC – Problem Between Keyboard And Chair – truly helpful) which in fact it quite clearly is not. Regardless of the idea of Zero Trust, we can do much better by the people we are trying to serve, I would venture to suggest. Add all this up and we can see that ‘trustworthy’ it most certainly isn’t.
Anyway, zero trust does away with these assumptions. The real assumption that it makes is that there is an imposter inside your network. It could be a piece of hardware with spyware on it, or an Internet of Things device with poor security (that would be most of them then). It could be a BYOD (Bring Your Own Device) tool like someone’s iPhone or Android device which you can’t examine to see if it is compromised or not. It could be a bad actor (human). Many of these things could happen and more, if you have been looking at the things I wrote just now. And of course, spotting them is hard.
So what to do?
Trust nothing until you have to, and even then assign least privileges. This means, figure out who is asking to be able to do something and whether or not they say they are who they say they are (identity), then figure out if they are allowed to access the thing (asset) they are asking for (access). If they are, ensure that this is all they get to do (monitor) and that the person who owns the asset knows what is going on (report).
It’s not entirely new – least privilege and ‘need to know’ and so on have been around for a very long time. What is new is the acknowledgement that the systems we think are trustworthy actually are not, and that everything inside your own network has to be treated the same as everything outside it – with zero trust – until has proved it is who it says it is, and that it has access to the things it asks for.
That authentication thing? You can use MFA — Multi-Factor Authentication — to ensure that identity is what it is claimed to be. MFA is about asking the person or thing who wants access to prove that they are who they say they are in different ways — a password, a PIN, a swipe card, biometrics and so on all mixed up into a set of things needed for that proof. Often you hear “something you have” (like a swipe card), “something you know” (like a PIN or a password) and “something you are” (like a fingerprint or iris scan). There are many many different ways to combine these, and the more you have, the more secure the identity proof is (in theory).
You can combine these in zero trustwith things like periodic re-challenging — that means asking the thing or person to go through that proof again. Or you could monitor what is happening and react to things that are not or should not be allowed based on the access privileges assigned to that person or thing. Basically, you create a model of everything in the network, assign privileges to these things but only when asked for and monitor to make sure those privileges are being adhered to. In addition you could monitor to ensure that, even when they are being adhered to, the person or thing doing them is the same person or thing that was granted the privileges in an ongoing way.
Phew.
Interestingly, this page says “Put Your Trust in Zero Trust” which basically says everything you need to know about if there is no trust present or not (remember that System Trust thing?).
One more thing: the way this works works is pretty much exactly how we have been saying trust works in this little book. This is a significant departure from regular information security, which talks in terms of being able to “trust” something that is supposedly secure. Which would mean that there’s “no risk, we’ve got you covered.” As you may recall, the whole point of thinking about trust is because it tries to get things to work when there are no such guarantees. In other words, that nobody can bet trusted until you’ve thought about what you are trusting them for. Which means doing things like determining the trustworthiness of people or things in a given context, continually monitoring if needed, putting safeguards in place and so on. If this doesn’t sound familiar in the case of Zero Trust and Next Generation Access it’s because you haven’t really been paying attention…
As it happens, back in 2012 I happened to be giving an invited talk at the Information Security for South Africa conference (ISSA) in which I basically said things like “your systems are already compromised, or if not will be soon. The thing that will work is trust,” before heading into a description of how which looked remarkably like zero trust[5]. Whilst I wasn’t booed out of the room, I was told by a professor in the audience that (more or less) I had just told him that basically the things he had been doing for his entire career were wrong. This may be true, but I don’t think he meant it as a compliment. Such is life.
If you’re interested, a good overview of zero trust is here. It may not change your life, but it will show you how being suspicious and using trust properly can actually help security (honestly, it took a while for people to realize that…).
Is it trustless? It is, in the same way that blockchains are trustless. There is of course trust, but at the same time it is trust that has been transferred to the system or managed in a way that ensures that it is placed extremely carefully (and not for great lengths of time). It’s probably as close as you’re going to get to a trustless system because, at the end of the day, trust is always somewhere. If it wasn’t, nobody could actually do their jobs, secure or not.
It’s an old observation that the only really secure system is one that isn’t connected to anything else and has all its ports glued shut so that nobody can plug anything in. It’s also a pretty useless system in the final analysis because a lot of the power of the technology we use comes from things like network effects – being connected is a huge boost to potential.
When you’re in that kind of place, somewhere or other you’re going to have to trust someone who needs access to a file, or something that needs to forward a packet. You can put in place things like zero trust, and indeed probably should, but in the final analysis if you want something useful to happen, well, you know where to look.
- Sure you can see the difference! ↵
- Seriously. For a while there it was like - turn around and there's a new one! ↵
- Yes, the old Qui custodiet ipsos custodies issue! ↵
- Regardless of the fact that people are in fact the last line of defence in a secure system. ↵
- Yet another example of me being far too early with an idea! ↵
