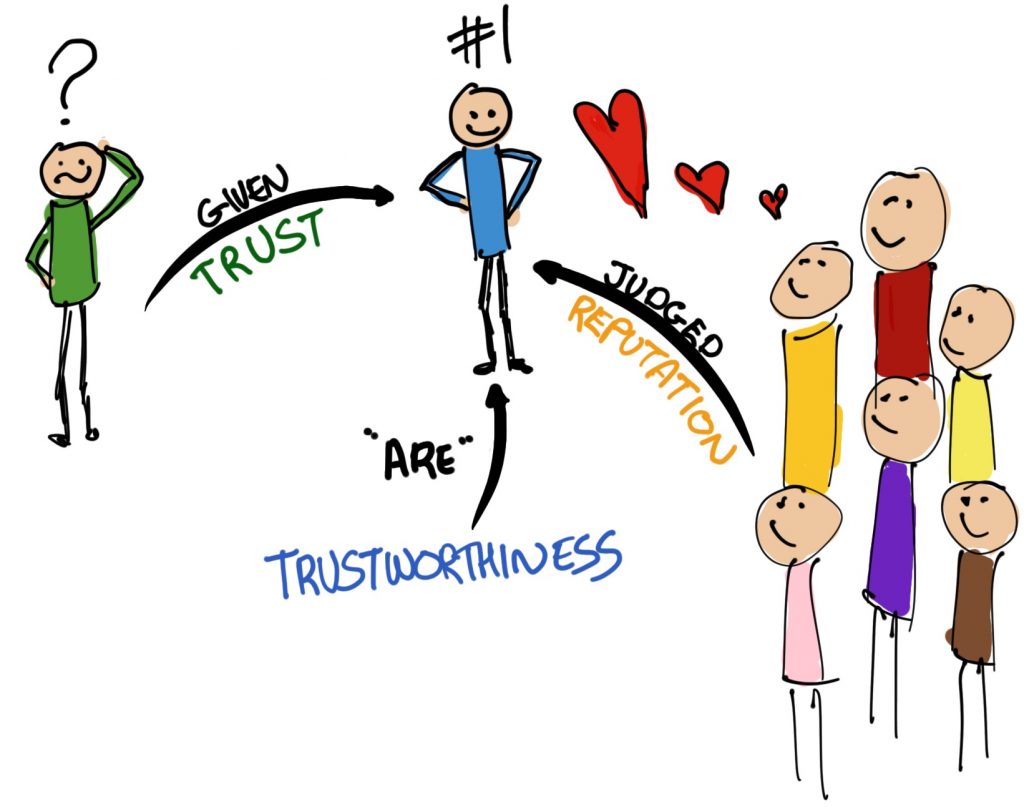
How Popular Are You?

Does being placed #1 mean you’re popular?
In this chapter we’re going to look at recommendation and reputation. There are similarities, but there are also fundamental differences between the two. In a nutshell, recommender (recommendation) systems tell you you will like something (or someone perhaps) based on some set of measures. Reputation systems, on the other hand, essentially tell you who or what is popular based on, you guessed it, some set of measures.
If you head to someplace like Wikipedia or even did a search for Recommender Systems (on DuckDuckGo of course), you might find that the definition goes something like this: the system looks at new stuff and tries to predict how you will rate it based on some set of measures. I’ve never been a fan of this definition because it implies that the systems are passive, that they just sit there and say to themselves, “Oh, Steve would rate this one 4 out of 5” and there we are. They don’t. Recommendation systems are not passive. Quite the opposite in fact. Sometimes they are also quite insidious, guiding you toward things that the system predicts you’ll like based on what it already knows about you.
Consider that for a moment. If I happen to like comedies featuring, say, Mike Myers, a recommender system might push me towards Austin Powers (I like Austin Powers), or even a comedy with some other SNL comedian starring in it, or perhaps a movie like Shrek. All pretty innocuous. What if I one day ‘like’ a page that has something to do with election fraud, or one that has to do with Antifa, or whatever? The system may well quite happily lead me down the rabbit hole that ends in the situation we saw on January 6th, 2021 in the USA (if I keep coming back to that, it’s because it is important). It’s a rabbit hole because you don’t even know you’re going down it and then it’s too late. This is not to say that recommender systems don’t have positive effects, but it does mean that they are power tools.
What has a power tool got to do with anything, you ask? Let me digress a little to an example I use in class occasionally. Imagine you wanted to put a hole in a concrete wall. You could do it with a screwdriver (I’ve tried, the result isn’t that great but it’s a hole and you end up with a useless screwdriver afterwards (needs must)). You could do it with a hand-powered drill type thing. Takes a while. Or you could use a power drill, maybe with a hammer-type action. Much better hole, much quicker.
What if you wanted to take a tree down. Why? Because it’s dead of course, or because you are coppicing. You can use an axe. You could use a saw of some kind (there are plenty of different kinds) and build those arm muscles. Or you could use a chainsaw (like in Figure 6.2).

Much quicker, much cleaner cut, and so on. How about if you wanted to go visit a friend in the town down the road? There’s Shanks’ pony, of course. It works but takes a while. You could (if you are lucky like what I am) ride a horse or you could resort to the power tool that is your motorcycle. Much faster, a different kind of fun, possibly even cleaner (mine’s a Zero).
What about if you wanted to know what was happening in your little world? You could run around town asking people you knew. You could even email people you think like the same kinds of politics as you, or people you think know you well enough to tell you stuff you know would be worthwhile to you. Or you could use Facebook. Or Twitter. Or Parler. Okay, maybe not Parler, we live in hope.
What happens if your hand slips when you are using a drill? I’ve had a hole in my leg once. No, really. Don’t want that again. Could be worse. What if your attention slips as you are rounding a corner on that bike, or if someone else’s does in the car coming round the corner the opposite direction? What if you get distracted by your 5 year old running towards you when you are using that chainsaw? What if you aren’t thinking enough when you look at your Facebook (or whatever) feed? The results can be damaging, if not disastrous.
Tools like recommender systems are power tools for your imagination, power tools for your mind. As with any power tool, use them right and you will get what you want more cleanly and more accurately and almost certainly much faster than if you didn’t use them; use them wrong, or use the wrong one, or simply drift in the wrong direction some day when you weren’t paying attention, and you will find yourself in a metaphorical corner with no real happy way out.
You have a brain. Use it.

The old adage goes, just because you can do something does not mean that you should. We can make marvels, algorithms and tools that will perfectly predict what you will want to see or do or read next, or lead you down that rabbit hole faster than you can say, “election”. There is a way to do one without doing the other, but we (and the people who use us as products) seem to have become rather lazy. Treat the things that come to you from these systems with a healthy respect. It will benefit you in the long run.
Back to the original programme.
It’s entirely possible for a recommender system to use some form of reputation as a means to determine what to recommend – after all, it kind of makes sense that recommending something or someone popular is probably a safe bet.
However, if you take a step back and think for a minute you’ll also see that it makes sense to recommend something based on the fact that you will like it. That’s not necessarily popular, but it can be similar. Similarity is interesting because it works in pretty much two ways:
- Similarities with something you like; and
- Similarities with something you are.
On the other hand, reputation systems deal with popularity in a few different ways. Ultimately popularity depends on who is looking and who is asking the question. For instance, the popularity of a person may be based on the music they make, or the pictures they draw. It may depend on the specific kind of work that they do, or the ethic they have toward it. For a node in a network, popularity might be measured in speed of throughput, uptime, things like that.
Before we go more deeply into what all of that means, let’s address one question: are these Trust Systems? After all, that’s what this book is about. The short answer is, no, they’re not. They don’t calculate trustworthiness, trust, anything like that. They don’t reason about trust or trustworthiness (although a reputation system may revolve around perceived trustworthiness – that is, trustworthiness can be a popularity measure – and recommendation may be based on trustworthiness in a specific context). So, what they are then is ways of helping trust reasoning to actually happen. They give information to the trust reasoner. For instance, if I was trying to figure out which of two different airlines to fly with, I might look online for a system which rates airlines to help me (like Yelp or Travel Advisor, or something like that). These systems provide reputation measures and/or recommendations to help me make the ‘right’ choice. Why ‘right’? This isn’t actually a normative thing. Because it’s all contextual, yes? I might be concerned about the comfort of the seats whilst someone else might worry more about the on-board food (this is really not something to get excited about, but you see the point). The systems we use in this context provide us with information to help us make our decision. You might say ‘choosing an airline is not a trust decision’ and you’d be right. Giving them your money for a flight 8 months into the future might be. Ask people who bought tickets at the start of 2020 for travel in, say, June. Refunds are, well, not so easy to get. Coupons in return for money. Is this legit or a scam?I digress. Moving on.
Figure 6.4: Fancy that.
Actually, the previous discussion brings up that trust empowerment versus trust enforcement thing I talked about a little in the Can We See It? chapter. It’s like this: recommender systems could be seen as Trust Enforcement tools: they kind of tell you what to pick. That’s a fairly strict reading of what they do, but in some instances they might not even tell you why they are recommending the thing they are. Much of the time these calculations are secret – after all, they are the basic means by which a company makes money – good recommendations mean you will keep coming back for more (at which point they can do things like track you, advertise based on your likes, which are based on your searches, and so on).
If that wasn’t enough of a clue, think about PageRank.
That’s right. PageRank is essentially an algorithm that works out which page to recommend to you based on the search you are doing and the popularity of the pages out there on the web. There’s a paper from a while ago describing it, but the real trick is that Google tweaks the model all the time (they use many different algorithms) to beat people who try to game it (we’ll talk about attacks and such later). In a nutshell, PageRank calculates the reputation (I know I said recommendation, bear with me) of the pages on the web in terms of popularity, like this: each page’s popularity is a function of the number of pages that link to it and the popularity of the pages that link to it. If that sounds a little tautological, don’t worry. Think of it like this: if I’m a person who everyone thinks is really awesome and important, clearly other people will want to, you know, be my friend. Ask Kevin Bacon (we will get back to him). If lots of important people are my friends, clearly this is a sign that I am even more important than you previously thought.
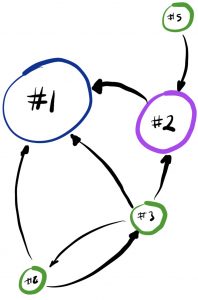
More popular means more visited, more linked, more trusted? In web page terms, these friends are links. Google’s home page is hugely popular – it’s certain that there are a huge number of pages that link to it. These can be individual pages or sites, right up to sites like Facebook or Instagram or whatever (doesn’t matter – the thing is that there will be some hugely popular sites that point at Google). It doesn’t link to that many itself (at all) though. But that doesn’t matter either because its popularity is high because of who links to it. If the Google page pointed toward another page, it would be quite important simply as a result of that link. But if the Google page was the only page that linked to it, then that page wouldn’t be as important as the Google page because it’s about the number as well as the importance of the links.
Alright, so in this particular example, we were looking at Google recommending pages to you. The list of results it gives you is a rank of the pages from most to least important based on the search you do. The top ones are the recommendations. Not that many people go to the second and third pages or beyond of search results. Why would you? Google has you covered (I use DuckDuckGo, for full disclosure). But that recommendation is based on the importance of pages, which ultimately maps to a sort of reputation. Pages don’t link to other pages at random, right? They link because the page they are linking to has something relevant to say about the thing they are linking for (talking about). However, as in all things, this might be a negative thing. Imagine if all those pages pointing to the Google homepage were actually saying, “this one sucks”. Absent some form of intelligence you may well get the same important result. This begs a question: is a hugely unpopular page/person/whatever important or not?
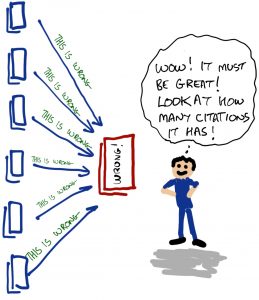
Here Steve assumes that if a website has multiple citations, it must be a great resource. Having many of something does not mean it must be good, or right. It is better to have one, but accurate.
There are a lot of philosophical questions wrapped up in all that which you can feel free to explore in your own time. It is the case that there are different kinds of recommender/reputation systems that look at this all quite differently, as you will see.
Is there mathematics involved in the Google model? Sure, like pretty much any reputation or recommendation system. I’m not going to go into it here. Remember the start of the trust model chapter? Mathematics? Yeah. Seriously though, much of the work revolves around things called eigenvectors and eigenvalues. One day I may explain those here.
Phew, that’s the 800-pound gorilla dealt with. I’m sure it’ll pop back into the scene someplace though. Watch this space.
The discussion did bring one important thing up though: reputation and recommender systems sometimes go hand in hand. That is to say, recommender systems sometimes use some form of reputation in the way they figure out what to recommend. Bear that in mind as we move forward. In the meantime let’s go right back to where we started this chapter: the two systems: recommender and reputation. For the sake of simplicity, let’s have a look at recommender systems first. When we verge into reputation territory, I’ll let you know.
So, recommender systems can be broadly split into a couple of different types. We have recommendations based on content-based filtering and recommendations based on collaborative filtering. This is not quite the way some people look at it, but trust me on this one.
All filtering works like this: the system ‘knows’ things about what you like (we’ll get to that) and when something new pops up it looks at that thing to see if it matches the stuff you like. Bear with me, we’ll get to the matching stuff too. If it does then you will get that thing recommended to you. Simple.
There are two key things here. The first is that the system knows something about what you like, and the second is the way it matches those likings with the content of something new. Let’s explore them in turn and we’ll get back to the content/collaborative distinction.
The content-based filtering does matching by looking at something you tell the system, either explicitly or implicitly, as we will see, and then figures out if the content of the thing matches. This can work through a couple of different relationships. The first is pretty simple – it’s based on the relationship that you have with the kind of thing that is being recommended. Imagine for instance that you love Dungeons and Dragons, like my son Owain does. Knowing this means that if a new D&D book or game or movie or whatever comes along, he may well get matched with it. Think of it like your favourite aunt who knows you like cats and so gets you a pair of cat slippers for Christmas.

The great thing about this is actually that content is not as much an issue as our next kind of match. However, the system still needs to ‘know’ something about you and something specific about the thing it is recommending to you as a result. If Owain was more or less specific in his likes he might get recommendations only for new D&D adventures on D&D Beyond or recommendations that included stuff about Esper Genesis. The system needs to know what these things are about, and so there’s your content stuff. The relationship is between the person and the content of the product. To put it another way, the system makes a link between what Owain likes and all kinds of different things he might like as a result.
It gets more complex though when we start talking about things like the content of different kinds of things and building recommendations based on that. For instance, say Anika (Steve’s daughter) loves Harry Potter books, a good book recommender system might bring forward books in the fantasy genre, or the magic genre specifically, or schooled wizards and witches (it’s a thing). There’s little point in recommending Harry Potter books. She has those. You want to sell her other books she might like based on the ones she has already liked.

The filtering is solely based on similar past products/brands and linkings. Did I mention this was a selling thing? Oh yes, recommender systems are all over eCommerce.
The relationship in Anika’s example is pretty simple too – it’s between books she liked and similar books that she might like as a result. The products are similar, which they aren’t in Owain’s case. The filtering and recommendation is still based on the content – the recommendation is based on what the thing being recommended is about in some way.
Here’s a different one. My other son, Layne, is very much into his fish. He also likes Marvel movies and TV shows. And The Tick. He’s quite fond of chess too. If he was to be online looking for something fun to buy or watch, a recommender system based on collaborative filtering would basically try to find someone else (Person X) in the system who likes fish, chess, Marvel and The Tick and also something else, like a new movie that has just come out and they watched last night. Because they liked that something else and they also like the other things Maybe likes, well, there’s a fair chance Layne will like that something else too, right? Right.
In fact, it doesn’t matter what the content of that something else actually is to the system at all. All that matters is the similarity between Layne and Person X. This is pretty neat because (as with the first example with Owain) all kinds of different things can be recommended, from games to socks, but also because they can be recommended not just because they are D&D related, but might come completely out of completely left field and recommend something Layne had never thought of: a Marvel movie about fish socks, for instance.
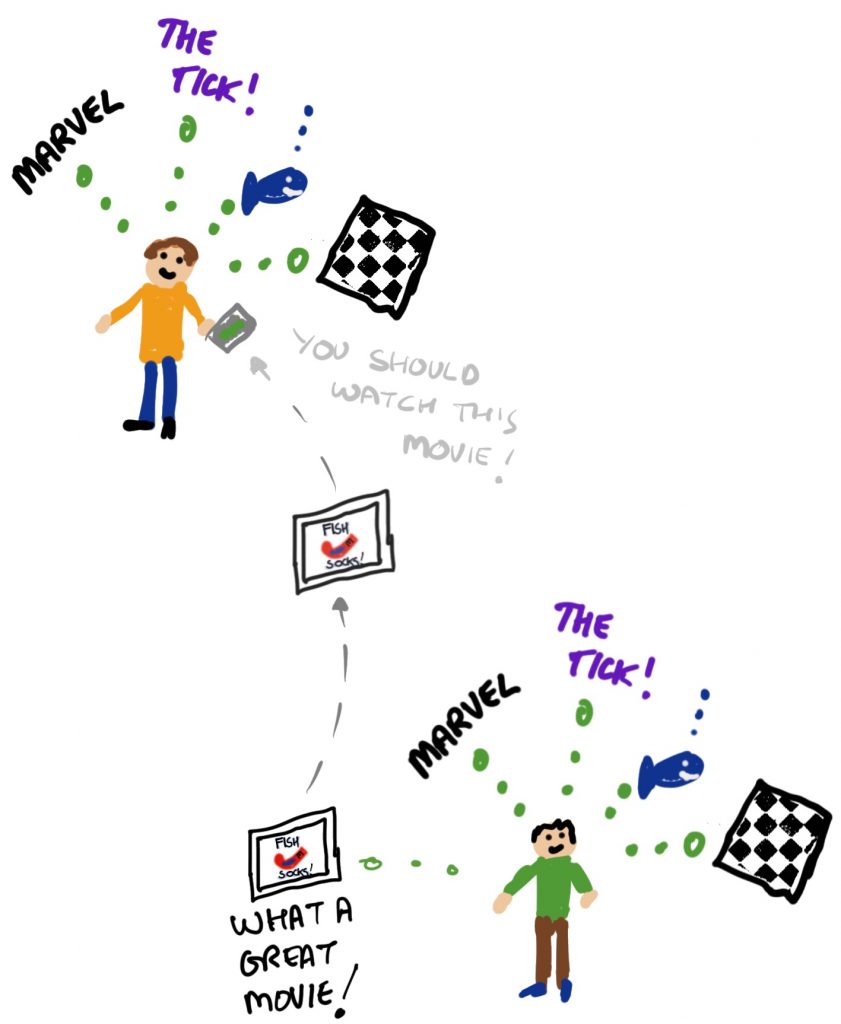
In the first example, with Owain, the system needed to know something about Owain (the user) to be able to recommend something new (which had to do with a specific thing). In the second example (with Anika) the system needed to know something about Anika’s preferences, the topic (the genre) as well as the content of the things it was recommending. In the third example (with Layne) the system needed to know a bunch about Layne – and not just that he was or was not interested in D&D or Harry Potter books (although perhaps the Marvel Fish Sock Movie is a bit of a stretch). By now you will probably have realized something about recommender systems. They need data! If they don’t have it, they can’t do anything. The more the data, the better the recommendations.

Technology knows how to get around with knowing more about you! All it wants is data.
Think about Netflix for a second. What differentiates them? What does the company do? Stream videos to you? Not really – they use Amazon’s Web Services for that, and anyway, anybody really could do that with enough money (as Amazon Prime TV, Disney Plus and a host of other services show).
No, what Netflix does is recommend movies and TV shows to you based on what it knows about you. The better it knows you, the better the recommendations get (just don’t let your Gran watch her stuff with your profile!). The longer you stay with them, the harder it is to leave (I mean, it’s a pain having rubbish shows recommended to you as the next system learns stuff about you).
Just saying. These services need data.
How do they get it? Ratings? Well, that would be a fine thing. I mean, who really rates stuff anyway? Not that many people actually. Netflix can use a bunch of analytics to determine if you watch a movie or TV show to the end, if you binge watch a show, and so on, which is almost as good as ratings because if you watch it, that kind of means you enjoyed it (or were too tired to change the movie). So Netflix gets that stuff there. It also gets it if you rate the movies you watch. Noticed how easy it is to rate them? That’s because they would really like you to do it. Some services ask questions when you sign up. Amazon Prime almost certainly uses the purchases you made from Amazon itself to help guide its recommendations. There’s a lot of rich data there.
Other places also make it really easy to give ratings: click on stars, for instance. In the case of social media sites, you may ‘like’ stuff or you may follow someone (and the system knows what they like, and so on). All of these things are things that you do. They are explicit ratings.
But hey, let’s be honest, none of us are really that excited about clicking on a bunch of stars when we have the thing we wanted. There’s a reason why well-designed bank auto-tellers give you your card back before they give you the money. How, then, to get the data from more implicit means – things you do that are associated with the data but don’t require you to do extra work (or thinking)? Remember that Netflix thing? Watching a movie is a ‘like’ that costs you, well, the time to enjoy a movie. Clicking on links to get places, or ads when shown on a web site, or purchasing things are all of them rich sources of data for the recommender systems. Because you don’t explicitly go out of your way to rate them, these are implicit ratings. They’re still pretty good though: after all, spending a couple of hours of your time watching a movie is a commitment of sorts. There’s also a reason why we say ‘pay’ attention. It’s valuable. Buying something, actually spending your money instead of just your time, is also valuable: you put your money where your likes are.

What are the downsides? Well, the real one for the recommender systems that do the person to person matching (Layne and his socks, remember?) is that you need a bunch of people with their interests to join in before you can give really good recommendations. That’s what’s known as a cold-start problem. It’s something which trust systems other than recommender systems suffer from too, which we will get to shortly. It’s also something that the other two schemes don’t suffer from. In Anika’s case all the system needs to know is her preferences and the (already available) books and genres around. Likewise with Owain’s D&D, he could be the only person in the system and still get good recommendations about all kinds of D&D products. There’s also the problem of sparsity, which is where there just aren’t enough people to ensure granularity (people who like the same stuff), which other recommendation systems don’t suffer from.
But there’s something else, too. Okay, so recommender systems are an interesting topic and, as I said at the start of the chapter, can help in trust-based decisions (all data is good for a trust-reasoner, right?). What I didn’t talk much about is privacy. It’s important, so I will now. There are obvious issues with personal privacy here. It’s possibly okay that companies like Netflix have your data – after all, you gave it to them – but if companies start to sell it in order to make money, this is problematic. It’s entirely possible that according to the contracts you have with the organizations this is quite legal. This does not make it moral.

These magical recommendations are nothing but a breach of your personal information, data, and SECURITY.
How do all these recommendations actually happen though? How are the matches actually made? There’s a fair amount of interesting mathematics in this kind of thing. What the systems are trying to do is to find how similar the person’s interests are to the aspects of the specific item being compared. For various reasons this isn’t the place to get into mathematics but there are some really nice explanations (and pictures) here: https://builtin.com/data-science/recommender-systems.
Reputation (management) systems are a special breed. The basic premise of these systems is that one’s reputation can be calculated. Indeed, everyone’s reputation can be calculated. There are obvious questions around that, and let’s start with the first one to get it out of the way. Can it actually be done? The most obvious answer is “yes” and there are plenty of different examples that you bump into in many walks of life. For example, your credit rating (if you have one, and if you haven’t you will) is a measure of your reputation in the context of paying the bills. It’s a big deal too, and it’s big money. After all, banks use credit agencies every time you want to do something like open an account, or borrow money, or get a credit card. At least in Canada, mobile phone service providers use it when you want to get a contract with them. Private lenders use it. When I needed to get secret clearance for a prior job, the process of figuring out if I was ‘trustworthy’ enough to get the clearance used it (that was interesting! I mean, the rating was a little off for various reasons!). As you might expect there are quite a few credit rating agencies around. Some even go as far as rating countries (after all, it simply wouldn’t lend money to a country that had a poor credit rating).
What other examples are there, you ask? I’ve already talked about PageRank, which is kind of a reputation system used to rank recommendations for web searches. There are also quite a few ‘trust’ companies out there that use a whole host of data, from likes and follows to that credit rating, to determine if you are trustworthy (enough for a new job, or to lend to, or to be my friend…). Full disclosure: I once did some work for one of them.
Collaborative filtering systems for recommendations, which I talked about above, are all about people giving ‘likes’ and so on to things so that similar things can be recommended to them. Like the PageRank thing, they’re not far removed from reputation systems: reputation is how many ‘likes’ something has (literally in the case of a lot of social media, which we will discuss in a bit).
More prosaically, perhaps, Amazon uses a reputation system for its marketplace sellers (go take a look). eBay also uses one for sellers and buyers. In fact, a whole bunch of such sites do – it supposedly removes some of the risk involved when transacting with people you don’t know.
There’s the thing, right there: reputation systems are good in situations where you don’t know someone. They give you additional information that you can base a decision on (see Figure 6.13).

Think back once more to our trust enforcement vs. trust empowerment discussion. Where are reputation systems? Used properly, and made sufficiently transparent, they can be empowerment tools. Far too often they are leveraged into enforcement tools, as you will see.
They are used to make sure that the person on the other side of the line is not, to coin a phrase, a dog. Because on the Internet, nobody knows if you’re a dog.
A slightly more complex answer to the question “do they work?” can be arrived at if you start thinking about the past few chapters that you have hopefully enjoyed. In many cases I’ve done quite a lot of hammering home the point that trust is subjective – you can have all kinds of views around it, calculate it in lots of ways, apply it in many places according to your own needs, but the point is that it is a decision you make. This is just as important a point when we consider reputation systems. What is important when it comes to someone’s reputation? Quite simply, it’s up to you. I, for instance, quite like dogs. The systems may have their own views, which we’ll come to shortly, but yours may differ. So how do you reconcile these differences? We’ll talk about that too.
So the more complex answer is “it depends”. It depends on who is asking, who is calculating, what they are calculating for and how the answer is used, because when you start looking at if people pay their bills on time and determining if they are good gardeners, or good security risks, there are obvious problems with the result you’re going to get.
Just like trust.
Now we’ve got that out of the way, let’s explore a few of them quickly. Why quickly? Because there’s some juicy problems to discuss, that’s why!
Firstly it is important to know that reputation systems are actually pretty simple. Their purpose (the dog thing) is to help people build ‘trust’ where there isn’t any, by listening to what society thinks about the trustworthiness of a specific other person in a specific context. If you’ve been paying attention at all, you’ll know that there are quite a few problems with that sentence.
To do this, they count stuff. That’s pretty much it. They can count follows, or likes, or links to, or number of days past due for however many bills, or court convictions (and what for), or they can count stars or some other form of feedback from people who others transact with. But that’s what they do: they count stuff.
And then they put all that stuff into some algorithm or other in order to come out with an answer that says “yep, you can trust this person” (naturally in context, how could you assume otherwise? Yes, that was sarcasm).
There are indeed many examples, and some of them I’ve talked about just now. Here are some more… Reddit uses a form of reputation called ‘karma’. Good karma opens up all kinds of possibilities and different abilities. How to get karma? By posting stuff and having it upvoted (liked) and not downvoted (which loses karma). You can be funny, or sad, or poetic or a painter or whatever, just be upvoted. Slashdot uses karma too, in a slightly different way, but good karma still gets you better abilities (and a greater likelihood of things you write about being seen). As an aside, just because you have good karma on these sites does not mean you are a source of the truth. Unfortunately it is often seen that way, with obvious problems. Various sites, such as Advogato (an open-source community social network which pretty much no longer exists, although a bunch of data from it does) used trust metrics based on peer reviews (in fact, Advogato was set up as a way of testing a specific trust metric for its attack-proof-ness by Ralph Levien. Attack proof trust metrics are sort of like a holy grail for social networks, by the way. Can it be done? Levien thought so). The thing is though, we still keep coming back to that old question: what for? What question are we actually asking when we are asking “how much is that person trusted”?
I could go on. There are many. Aside from eBay in eCommerce there are sites like Epinions. Fancy figuring out if the prof you’re about to get is any good? ratemyprofessors.com may have some answers for you. For travel, you might think about asking TripAdvisor. Medical problems? ratemds.com or medicalproblems.com. Truly the world is your oyster (just ask Yelp). Speaking of profs (which we were) we can go even further because there are naturally ratings for things like how popular their research is. Based on citations this time, there is Google’’s own i10 index, which counts the number of articles with more than ten citations. The h-index (invented by the physicist J. E. Hirsch) is something pretty much all profs think about if they do research, it goes like this: a h-index of n means that the researcher has written n papers with at least n citations. As you might imagine, a high h-index not only means you write a lot but that what you write gets cited by others (which is good) or yourself (not quite so good – I mean, self-promotion and all that, right?). See a problem with this? I do (see Figure 6.15). I mean, if you’re just starting out, when people really look at this stuff and care, what is your h-index going to be? If you only published one paper the maximum it could be is, well, one.

Everyone, experienced or interns, all deserve a fair chance. Having a larger h-index does not mean success, does it?
To address this problem, Johannes Koelman introduced the Einstein index. You see, Einstein published stuff but the ones he published in his early career were groundbreaking. They are so massively cited that they’re probably off the scale. Trouble is, if that scale is the h-index, Einstein as a ‘starting’ scientist sits at, well, 3. Koelman’s Einstein index counts the citations of the scientists’ top three cited articles (not books) and adds them up. High Einstein index means, well, good things. Koelman talks more about indices here and it’s worth a read. Notably it talks a bit about the problems behind these indices, and the reasons they won’t go away even if we wanted them to.

Why did I focus on academic indices for reputation? Because I am one. Talk about what you know, eh?
There’s actually another one which is quite close to the h-index, called the E number (for cycling – there’s also one for astrophysics, which isn’t this one), after Sir Arthur Eddington, who was something of a rockstar astrophysicist at the start of the 20th century, and who played a large part in popularizing science, which is a noble endeavour. He was also quite the avid cyclist. The E number for cycling is a number E such that the cyclist has ridden at least E miles on at least E occasions (days). So, to get an E number for cycling of, say 80, you’d have to cycle 80 miles or more in at least 80 days (fortunately they don’t need to be consecutive, which would make things quite challenging!). Apparently Eddington’s own E number for cycling was 84, which is pretty good and better than I will ever manage.
There’s another reason for telling you this stuff. Both the h-index and the E number for cycling have a couple of things in common. The first is that it takes a lot of time to get to a large number. Unless you pump out loads of highly cited articles every year, your h-index will only grow by a maximum of the number of articles you do write (and only then if people actually cite them – which is dependent on them being any good!). So early career researchers are likely to have a low one. The same applies to the E number for cycling – not only does it take time to build it up (you have to cycle for at least a certain number of days to get a number that large, it takes effort, since you have to cycle that number of miles in each of those days. If you’re just starting out, you’re not going to have much on an E number – my own is around 10, and I don’t like cycling that much so it’ll probably stay there.

Why is Sir Arthur thinking of the number 82 while riding a bike?
This is important because it’s a behaviour reputation systems exhibit. The longer you are in the system, the more your reputation can grow (or not, depending on the kind of person you are in that context!). For instance, if you are new to borrowing money, the advice is to get a small credit card (small as in low limit, which is all you’re likely to get anyway with no history), use it and pay it off each month. After a time, you build up a history of being a good payer, and so it goes, you have a credit history which is good. It takes time.
On the other hand, it can also be skewed strongly in the wrong direction too. Imagine a site which allows you to rate your farrier, for instance. We’ll call it ratemyfarrier.com (if there is a site like this when you are reading, remember I said it first). Like pretty much all these ‘rate my’ sites, the farrier is put in the system by a happy (or angry) customer to rate them if they are not already there. If it’s been around for a while, there will likely be a bunch of older farriers on it, with a history of being kind to horse’s feet, or of being quite mean and expensive. You get the idea. Now if I was a new farrier (are you kidding me – that’s hard work and skilled too!) And went to a farm and did an amazing job, this would happen: the farm owner would go to rate farrier, login and search for me.

Not finding me they would enter my name, a date, probably, and a rating (“5/5 – Steve was really kind and gentle with the horses and helped a lot with advice on a pony who has foundered.”). I got 5/5 stars! I am the best farrier on the site! Because, let’s be honest, even the best farrier will have someone who doesn’t like them, right?
Does that seem fair? Does it seem fair that a potentially really good researcher with few but amazing publications has a lower h-index than a mediocre one who strategically placed a few poorly written papers in highly cited journals and piggybacked off them, perhaps even with lots of self-citation?
OF COURSE IT’S NOT FAIR! (Sorry for shouting).
I can’t do much about the h-index thing (I quite like the Einstein index idea though, and if you combine metrics like this you find some good evidence for quality as well). And my career as a farrier is pretty much over now anyway.
So how to manage this stuff? One obvious way you may have already spotted is to use time as a mitigator, or perhaps number of ratings. If the person looking at rate farrier gets to see the number of people who have ranked each farrier they will get much more context. The site could even show them the number of good and bad reviews they got as well as the average stars. Which is exactly the kind of thing you see on eBay for instance. People can leave positive, neutral or negative reviews, and the rating of the seller goes up by 1, stays the same, or goes down by one depending on which of these is left. The result is shown as a percentage (the percentage is the number of positive versus negative reviews, so if a seller has a 90% rating, they will have had 90% positive reviews). You can dig further and see comments, things like that. Amazon’s marketplace is similar. There is also information about the length of time people have been using the site.
Uber has a reputation system too. You take a ride, and then you can rate the ride with up to 5 stars. If you rate with less than 5, you get asked why. Drivers can rate riders too. Riders can see the ratings of drivers around and choose one they want based on that. The rating shown is an average of the last 500 ratings. This means that it’s pretty volatile until you get a couple of hundred drives under your belt, should you choose to be an Uber driver. It’s your call, that’s all I’m saying. Things out of your control (traffic jams and so on) are not counted.
Here’s a thought: Why is it that we are seeking such perfection? It’s not like every student I ever had gets 100% in every course they took. Why not? Because we’re all learning. Every day. We all make mistakes. A very good rating to me is around 4 out of 5 stars (80%, it’s in the ‘A’ range, right? That’s pretty good, right?). So why does Uber imply it isn’t? Why do we all as users of technologies like this insist that the only thing that’s good enough is 5 out of 5? How does life work that way? The system results in a couple of potential things happening:
- Either everyone gets (and gives) 5 stars, or
- Everyone is a failure.

Josh in Figure 6.19 is sad. Does success mean 5/5? This actually brings up another problem with trust and reputation representations: mine is not yours. My 4 stars may be equivalent to your 3 stars. My 0.5 trust may be equivalent to your 0.7 trust. My “Pretty good” may be equivalent to your “Wow! Amazing!” It’s subjective, right? Bear this in mind.
The creators of such systems would suggest that the crowd is wise enough to be able to even out the rough and the smooth. But if everyone is either 5 stars or a failure, where exactly is the smooth? More to the point, if everyone is either 5 stars or a failure, how am I supposed to choose which 5 star driver is best for me? When reputation systems have insufficient granularity they are practically useless.
No, I don’t have the answer. I’m just the one who asks the questions.

Is reputation always correct? Always deserved?
There’s a saying, which may or may not have originated from Voltaire: don’t let the perfect be the enemy of the good. Although many people would rather it didn’t, I believe it applies here. Reputation systems are at such a pass that it’s almost impossible to tell what they really mean because, well, you’re a 5 star or you’re not.
I’m not. How exactly does that make me a failure?
Reputation systems abound, and they’re not going away. In fact they show every sign of becoming more prevalent. There’s a lot to tease out here, and it takes a long time (so if anything this particular chapter will never be finished to perfection (sic))! In the interests of your sanity and mine, let’s move to a couple of salient examples, one fictional and the other sadly not.
The fictional one is whuffie. In Cory Doctorow’s ‘Down and Out in the Magic Kingdom’ whuffie is basically the reputation capital in the Bitchun society that everyone gets to see (on their Heads up Displays) at will. Do something good for someone, they’ll give you some whuffie, want a nice room for the night? It’ll cost you some whuffie. If your whuffie gets low enough, even elevators don’t stop for you (ask Julius). whuffie is described as a measure of esteemed respect. What it is is reputation. The book (which you should read, it’s even free online in lots of different versions, some of which are amazingly creative) describes how it is earned, lost, regained and so on throughout the existence of the characters (who never die anyway). As you might expect, it’s dystopian but disguised as ‘good’.
This brings us to dystopian disguised as ‘good for society’. In China, you may have heard, there is a social credit system. What is this? Well, it’s not (totally) Douglas’ idea of social credit, that’s for sure. Not sure what that means? Look at http://socialcredit.com.au.
The Social Credit System in China is still in development as of the time of writing, which means that there are many questions about how it works and how it might not. There are also different kinds of representation in the system itself (like numerical values for credit or black/whitelisting for credit). It basically works like this: do things that are socially acceptable or correct — like donate blood or volunteer — and you get credit. Do things that people don’t like — like playing loud music, jaywalking, bribery and so on — and you lose credit . How is it enforced? By citizen participation (oh, those crowds again, we’ll get back to crowds, don’t worry), facial recognition systems (and we know how perfect those are, right?), a whole lot of AI. Things like that. There’s also evidence that you can buy credit, but of course, that would be wrong, so it never happens (yes, that was sarcasm too).
And so we reach the point of all that: control.
The Social Credit System in China is a control mechanism. It’s possible to see it as a form of reputation, and the behaviour is not far from whuffie: if you have bad credit you will be blacklisted, and you won’t be allowed to travel (already happened), or stand for politics, or get your children into universities. To become un-blacklisted? Do good things for society.
You get the idea.
Doesn’t it sound wonderful? Sure. Until you start asking questions like ‘who gets to decide what is good and what isn’t?’ Is posting on a social network that isn’t Chinese good or not? What about reading a certain kind of book? How about running for political office?
Like many things which seem interesting, promising, and plausible in first light, there are huge issues here.
What could possibly go wrong? Blackmail, coercion, corruption, mistaken identity. The list is quite long.
And just in case you think it couldn’t happen here, wherever here is, consider: a good (financial) credit score gets you a long way. Moreover, see those reputation scores you’re building on all those nice sites you use? Who controls them? Who decides what is ‘good’?

In fact, the concept of social capital is closely linked to this. Social capital is basically the idea that positive connections with people around us mean that we are somehow happier, more trusting, less lonely and so on… Social capital, like reputation, can be used in situations where we are in trouble (ask for help) or need a little extra push (getting your child into that next best school) or a small recognition (like getting your coffee paid for by a co-worker every so often). You can gain social capital, and you can lose it. And if you lose it, then you don’t get the good things. It isn’t a specific number but the crowd you are part of calculates and implicitly shares it — by showing that you are accepted, by valuing your presence, things like that. It’s about shared values and making sure that you share them in order to move groups, society, companies, people who look like you, forward.
Does that sound at all familiar?
Political capital is a similar thing, you could see it as an extension of social capital.
It’s all reputation.
It has come to the attention of some thinkers (Like Rogers and Botsman, 2010) that all of this stuff hanging around is pretty useful. I mean, if you have a great reputation in one context, why is it that this isn’t used in other contexts? This has led to the idea of “Reputation Banks” where you can manage reputation capital to be able to use it in different contexts. Good reputation capital means you get to choose your passengers as an Uber driver, or get nice seats at restaurants, and so on.
How familiar does that sound? By the way, I think it’s an absolutely awful idea. So, why do I sound so down about all of this? Reputation systems, especially when pushed to the limits we see in China’s Social Credit System or even the concept of social capital, are a means to control the behaviour of others. This is where the whole nudge theory stuff comes from. That’s fine when we think of some of the behaviour that we don’t like. I’m sure I don’t need to tell you what that might be. And there’s one of the problems, because your opinion and mine will almost certainly differ. I might happen to think that certain behaviours are okay — perhaps I have a more profound insight into why they happen than you do. Whereas you just see them as a nuisance. In the superb “This is Water” David Foster Wallace talks about putting yourself aside for just a moment and trying to figure out why things are happening, or why people are behaving the way they are. Like trust, this stuff is very personal and subjective. It’s also information-driven in a way that we haven’t figured out properly yet. If someone is exhibiting a certain kind of (for the sake of simplicity, let’s call it ‘anti-social’) behaviour, why are they doing it? Do you know? I am sure I don’t. But the crowd believes that it does (I told you we’d get back there).
What is the crowd? Well, it’s usually not the people who are exhibiting behaviour that challenges it in some way (I’m sorry, that was a difficult sentence to parse). Let’s imagine it’s neurotypical, probably Caucasian, depending on where you are, almost certainly what you might call ‘middle to upper class’, possibly male-dominated. None of that has worked out particularly well for the planet so far, so why would we expect it to work out now in systems that expand its power exponentially?
It’s also stupid. Crowds are not ‘wise’. Their behaviour may be explainable by some statistical measures, but that doesn’t mean that what the crowd thinks is good for everyone actually is.
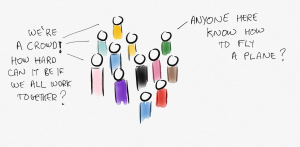
A crowd does not guarantee work done. It doesn’t mean that what anyone might think is good for us actually is.
To argue the point a little, consider the flying of a plane. If you put enough people together in a crowd who don’t know how to fly it, they’re not going to get any better at it (thanks to Jeremy Pitt for this example). You need an expert. Some problems are expert problems. Some problems (and their solutions) are domain-specific. I would venture to suggest that figuring out who is more skilled than anyone else, or which is the correct switch to flick on an airplane controls, are certainly both expert and domain-specific problems.
What if the behaviour you see in someone — for example a woman shouting at her son — is the result of a personal tragedy that she is dealing with that leaves her emotionally and physically exhausted (I got this example from This is Water)? None of this information fits into a Social Credit System. Even if a credit agency is supposed to let you put a note someplace to explain a discrepancy, that doesn’t change the score. If you have missed some payments because you had to pay for your child’s medication, the score doesn’t care. It’s a score. It makes people money, and it helps people who have money decide how to treat those who may not.
If you use a reputation system to decide whether to buy something from someone, then use it as a tool to help, not a tool to tell. A tool to inform, not to dictate. Or, in the language we’ve used up to now, a tool to empower, not to enforce. Enforcement goes two ways — it enforces behaviour the crowd sees as correct, and it enforces the ‘right’ choice (the choice that the system wants you to make).
Reputation systems are fine. They give you information that can help you make decisions. Just don’t use them to judge people or things. Or to believe one kind of thing over another. Or to choose friends or people to date. Use your head, that’s what it’s for.
As it happens, they are also open to quite a few different attacks, which is what we’ll talk about in the next chapter because the attacks on reputation systems are also amongst the attacks that can be made on trust.
As I said earlier, this chapter will never be finished, so the next time you read it (if there is one) it will likely be different.
But you’ve reached the end of it here, at this time.
In order then that the social contract may not be an empty formula, it tacitly includes the undertaking, which alone can give force to the rest, that whoever refuses to obey the general will shall be compelled to do so by the whole body. This means nothing less than that he will be forced to be free…
(Rousseau 1762, p. 18)
