Chapitre 7 – L’informatisation des entreprises
Introduction
Ce chapitre explore l’impact sur les organisations de la révolution des technologies de l’information. Le chapitre examine quelques-unes des nombreuses promesses que renferme cet important développement, mais aussi les menaces qui requièrent peut-être de meilleurs équilibres entre l’éthique et la loi. L’informatique fait partie de la vie des organisations depuis déjà plusieurs décennies. Ses applications dans la gestion furent évidentes dès les premiers moments, alors que la terminologie même de l’informatique en vint à emprunter du monde des organisations (celui de « programme » et de « fonction » par exemple). Simplement dit, l’ordinateur et l’organisation se ressemblent beaucoup. Ce chapitre est donc l’occasion d’explorer les nombreuses façons dont ils se ressemblent, et cela dans le but d’en venir à voir comment l’informatique présente de nouvelles opportunités et de nouveaux défis pour le gestionnaire. À la base, le gestionnaire serait nouvellement préoccupé, et dans une mesure toujours plus croissante, par la collecte et la saisie des données. La production d’information à partir de ces données a pour but d’appuyer la décision, mais elle passe par des étapes à chaque année plus complexe (présentant d’ailleurs un besoin toujours croissant en logiciels spécialisés). Or, si en effet la culture est un produit de la prise de décision, il faut admettre que l’informatisation des sociétés, par quoi on désigne la manière dont les organisations vont absorber et exister dans des systèmes aux couches informationnelles augmentées est aussi un phénomène culturel. L’informatisation des sociétés marquera invariablement les pratiques des personnes en organisation puisque les tâches quotidiennes vont être tournées toujours plus vers les données, mais aussi parce qu’à la longue ces pratiques transforment les pratiques et les croyances. Notamment, les tâches répétées autour des données font rapidement croire que la donnée est neutre, ce qui normalise des cultures où le lien entre donnée et réalité est perdu.
Informatisation
La gestion des entreprises a fait un saut important dans les années 1960 avec l’introduction des mainframe computers par IBM. Toujours en rare usage aujourd’hui, le mainframe (notamment par sa taille) était l’acquisition symbolique et effective d’une capacité d’action à informatisation augmentée. Les premières organisations à s’en doter furent donc les premières à se doter d’une capacité computationnelle aujourd’hui quasi universellement répandue. Bien sûr, rares étaient à cette époque les organisations qui pouvaient se prévaloir d’un tel appui à leur prise de décision, mais la célèbre loi de Moore annoncée dans les années 1970 était de nature à inspirer la venue prochaine des capacités informatiques dans les organisations. En effet, à partir des années 1980, la matérialisation des technologies informatiques atteint le commun des gestionnaires. Le PC fait son entrée d’une manière à rapidement accélérer la production, mais aussi faciliter l’entreposage des données et documents. C’est alors que des tâches autrefois manuelles et reléguées à des particulières (en l’occurrence) comme la dactylographie, disparurent, et les capacités de dactylographie furent alors intégrées aux compétences attendues (et souvent très implicites) des gestionnaires dans les organisations. La capacité d’interagir avec ce qui est non plus simplement technologie de l’information, mais aussi technologie de communication, explique toutefois certainement l’exigence de compétence avec des logiciels particuliers. D’où bien sûr l’obligation, dans le cadre d’un processus d’apprentissage, de maitriser ces logiciels. La formation spécifique pour taper des rapports est aujourd’hui reléguée à des compétences implicites à la faveur de compétences spécialisée. Curieusement d’ailleurs, l’importance de maitriser le clavier serait aujourd’hui remise en question par la prédiction automatisée. Même la place de la maitrise du clavier est en évolution constante au sein des compétences technologiques attendues chez les gestionnaires.
Dès les années 1990, l’univers des gestionnaires a été encore une fois transformé, cette fois par l’émergence de l’Internet. L’informatique à ce point permettait l’existence au sein des organisations de réseaux informatiques restreints. Or, ces réseaux existaient selon des protocoles de communication qui leur étaient uniques et donc déjà difficilement interopérables. La connexion à ces réseaux exigeait des interfaces logiciels spécialisées (‘interface propriétaire’) ou être soumise à des requêtes adaptées à leurs exigences (ce à quoi s’est spécialisé une première génération de ‘hackers’). L’idée de servir (par des ‘serveur’) sous format texte et médiatique des requêtes d’information provenant de n’importe où souffrait de plus des infrastructures limitées (mais tout de même accessibles, les réseaux téléphoniques ayant d’abord servi avant de laisser leur place aux câbles optiques). La standardisation des protocoles de requête autour du format HTTP a engendré un mouvement d’organisation autour de la gestion des espaces virtuels nouvellement ouverts. Quelques organismes de type tiers secteurs ont émergé pour se porter garant de l’organisation de cet espace, mais les années 90 ont vu émerger de nombreuses entreprises technologiques dédiées à soutenir l’expansion de ce nouveau domaine qui prend alors le nom de technologie de l’information et des communications (TIC). On peut penser à Oracle, ou Sun Microsystems (la seconde fut absorbée par le premier en 2010), mais aussi aux nombreuses entreprises qui ont émergé pour soutenir les applications des TIC (design web, transaction commerciale, etc.). Et bien sûr, les années 1990 sont la décennie de la popularisation d’un phénomène de communication aujourd’hui synonyme de la vie en organisation : le « courriel » (email). À vrai dire, le courriel précède la décennie des années 1990. Il émerge selon différents protocoles de communication d’abord développés dans les réseaux plus restreints d’organisations spécifiques. Précédés par les ‘messages boards’, trois des protocoles développés indépendamment ont été retenus (SMTP, POP, et IMAP) pour l’extension universelle de l’accès au courriel. Pour le bien ou le pire, le courriel est aujourd’hui une composante indispensable de la vie du gestionnaire.
Au tournant du 21e siècle, le Canada, par le biais de ses entreprises, s’est embarqué dans un ambitieux programme de développement des infrastructures nécessaires pour augmenter la circulation sans cesse croissante des requêtes web. Cette expansion infrastructurelle est arrivée tout juste à temps pour accommoder l’émergence des médias sociaux comme nouvelle dimension de l’informatisation des sociétés. Le potentiel commercial des informations sur les utilisateurs repose sur le besoin de collecter ainsi que la disponibilité de ces infrastructures de transmission. Tout aussi nécessaires sont les centres de données pour héberger ces informations. C’est ainsi que le tournant du 21e siècle fut aussi marqué par le dépassement des capacités décentralisées d’héberger les données. Les grands de l’informatique se dotent de leurs propres data centers mais il se développe aussi l’industrie du cloud computing pour toutes ces entreprises dont la technologie n’est pas le cœur de la proposition de valeur, mais qui désire tout de même prendre part à l’informatisation des sociétés. Ces entreprises trouvent tout aussi bien de nouveaux outils dans les médias sociaux, sous la forme de transactions avec les sociétés mères (Facebook a fait fortune par la vente de ces informations et la mise à l’accès de ses utilisateurs), mais aussi comme simple participant dans ces réseaux. De fait, la présence dans les médias sociaux est aujourd’hui une nécessité et toute organisation qui n’y a pas sa présence semble déjà moins sérieuse étant donné l’effort minimal (et le coût souvent gratuit) derrière son utilisation.
Les jalons dans l’histoire des TIC ont presque toujours été accompagnés de discours perturbateurs, évoquant la fin de certains modèles économiques traditionnels, comme si chaque nouveauté annonçait la révolution complète du marché. À chaque étape de ces évolutions, un discours souvent apocalyptique accompagnait ces innovations, marquant chaque nouvelle révolution technologique comme la « fin du monde » du marché tel qu’on le connaissait. Il est tout à fait vrai que l’innovation transforme la nature du commerce. Les nombreuses innovations de gestion des bases de données et des transactions commerciales que nécessite le commerce électronique ont très sérieusement affecté les opérations des marchés. L’introduction effrénée des nombreuses nouvelles applications logicielles et matériels (‘Internet of things’) se poursuit à ce jour, mais il est aussi vrai que le domaine des TIC a connu des standardisations importantes sur le plan des attentes de présentation et des services qui permettent de souscrire à ces attentes (pensons à Wix, qui place aujourd’hui la conceptualisation de site web élégant à la portée de toutes). Ainsi, comme c’est presque toujours le cas dans les technologies disruptives, les discours apocalyptiques seraient à mitiger. Il y a certainement transformations dans les fonctions et opérations des entreprises qui affectent l’emploi. Mais il y a aussi des moments de stabilisation et même parfois de démocratisation des contrôles (supervision algorithmique, accès aux capacités, gouvernance des données, etc.). Ces changements ont été perçus comme des ruptures majeures, mais en réalité, ils ont différemment affecté les organisations.
L’informatisation des sociétés, cette transmutation de la substance des organisations en quelque chose qui est partiellement sous format digital, invite à quelques points spécifiques pour l’observation. L’informatisation est quelque chose qui se place dans les pratiques des personnes associées à l’organisation, dans ce que les travaux web et l’utilisation des logiciels spécialisés sont une composante de leur quotidien. Il l’est bien sûr à divers degrés, mais du moment qu’il l’est, le gestionnaire est confronté aux choix qui entourent la sélection et les applications de ces outils informatiques. Par exemple, la sélection du logiciel Microsoft BI est peut être assez simple, mais la structuration des représentations des données n’est pas décidée à l’avance, y compris le choix d’IA à employer dans ce processus de sélection. La validation du contenu par le gestionnaire ne consiste plus de simplement savoir si ce dernier s’impose ou non à une des étapes de la production d’information décisionnelle. Il est plutôt question pour le gestionnaire de règlementer le niveau d’autonomisation des tâches. D’une manière, il s’agit là de quelque chose dont le gestionnaire a toujours été responsable, c’est-à-dire que la tâche du gestionnaire serait toujours d’atteindre une automatisation des opérations au sein du groupe restreint qui forme l’organisation. À l’égard de toutes les étapes du processus de formulation des informations pertinentes à la prise de donnée, il est possible d’imaginer un moyen que le gestionnaire s’interpose dans le processus par rapport aux IA aujourd’hui hautement compétentes à bien des égards : dans la cueillette des données, dans l’analyse ou l’interprétation, enfin dans la formulation d’information et la prise de décision, chacune des étapes interpelle à sa façon le gestionnaire à s’imposer plus ou moins par rapport aux formes d’autonomisation. Et en cela, le gestionnaire ne fait que poursuivre son rôle historique défini déjà au 19e siècle.
Pour le gestionnaire donc, il devient essentiel de comprendre ce qu’un ordinateur peut et ne peut pas accomplir. Cette connaissance de base est indispensable afin de gérer l’équilibre désiré. Plus fondamentalement, il est nécessaire pour lui ou elle de formuler l’équilibre désiré. On ne pourra par exemple pas savoir quelle est l’importance de sélectionner soi-même ses modèles d’analyse si on ne sait pas comment leur variété peut donner des résultats de nature différente (et non pas simplement différent, mais différemment rendu). La formation des intelligences doit devenir une aptitude de plus en plus partagée, si en effet les optimisations promises sont à s’avérer. Ces intelligences sont là pour assister le gestionnaire, mais leur présence même doit être un acte de choix, et si ce n’est pas seulement par celui-ci, il semble donc que le gestionnaire devra toujours, à la genèse des choses, prendre la décision d’organiser.
Données et prise de décision
Une donnée est une constante ou une variable produite par une observation. Les constantes sont fascinantes, mais leur présence semble limitée à la biosphère (la constante Pi, ou le nombre d’or en sont des exemples). Dans les organisations, et plus généralement dans le monde social, les données sont typiquement variables. Mais elles sont aussi très nombreuses, car leur observation peut porter sur une grande variété des phénomènes. La prise de données n’a pas toujours été populaire, les résistances aux recensements ne sont pas chose nouvelle, la prise de donnée a toutefois connu un regain de préoccupation avec l’expansion dans les organisations. Certains ont pu vouloir l’éviter, mais elle fait désormais partie intégrante de notre monde. Il est incontournable pour le gestionnaire de réfléchir aux types de données dont il dispose et d’identifier celles qui lui semblent les plus pertinentes. La pertinence tient généralement à la possibilité de tirer de la donnée une information pouvant appuyer la prise de décision, mais il est aussi nécessaire de pouvoir évaluer la pertinence relative d’une donnée, soit de déterminer entre deux informations laquelle est la plus nécessaire. Car il n’y a pas toujours la chance de tout faire. Les capacités d’analyse et même d’interprétation des données ont beaucoup bénéficié des TIC, mais certaines formes de cueillette n’ont pas amélioré depuis leur émergence et demeurent laborieuses. Tout gestionnaire soucieux des coûts saura que des études de clientèles qui nécessitent des entretiens directs nécessitent l’emploi de personnes pour l’effectuer. Ainsi donc, il serait important de pouvoir argumenter son utilité avant de lancer un couteux processus d’entretien direct.
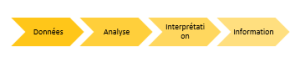
Les transformations technologiques actuelles influencent la prise de décision, tant au niveau stratégique qu’opérationnel. Elles redéfinissent la manière dont les entreprises structurent leurs processus et leurs flux d’information. Simplement dit, les données, par un processus d’analyse (soumission à des récupérations aux choix structurées) et d’interprétation (lecture et contextualisation de la signification du résultat), donne lieu à des informations (évaluation ou composante décisionnelle). L’intersection de l’informatique et du commerce fait remarquer que la qualité d’une information repose sur le respect de l’intégrité de ce processus de transformation. Les données ne sont jamais que des observations de la réalité, mais alors leur mauvais traitement construira un pauvre portrait de la réalité. Lorsque des informations issues de données mal gérées sont introduites dans la décision, la performance de l’organisation peut en souffrir. Un aspect fondamental du rôle du gestionnaire à l’ère de l’informatique est donc les choix et la préparation des données pour l’analyse. Tout ce qui peut influencer ou limiter notre comportement, et en particulier affecter la prise de décision, peut être d’une manière ou d’une autre quantifié. Il est désormais assez évident ce que l’on peut accomplir avec l’informatique, mais encore fait-il que le gestionnaire en fasse un apprentissage. Cela comprend la nuance importe qui veut que tout ce qui peut être réduit à un état de donnée peut faire l’objet d’une analyse informatisée, mais ce n’est pas tout qui peut être réduit à l’état de données. Par exemple, on peut analyser les données de ventes ou les statistiques économiques. En utilisant des sources comme Statistique Canada, on peut examiner l’activité économique dans différents secteurs et sur une base géographique. Cela nous permettrait d’identifier les besoins économiques spécifiques dans différentes régions du Canada, et ainsi diriger nos efforts entrepreneuriaux vers les secteurs qui nécessitent davantage de développement. Mais ce n’est pas tout qui est pertinent pour comprendre le besoin entrepreneurial qui peut être quantifié. L’insertion communautaire de l’entrepreneur ne fera pas l’objet de donnée chez Statistique Canada, mais relèvera spécifiquement de ce gestionnaire.
Il existe une grande liberté d’accès à des ressources éducatives, notamment avec une immense quantité de livres disponibles dans les bibliothèques pour que le gestionnaire puisse s’instruire. Non seulement ces ressources sont-elles utiles pour nouveaux arrivants, mais comme il se trouve que l’informatique est un domaine à complexité quasi infinie, le besoin de référence persiste. Il y a des évolutions constantes (de nouvelles ‘librairies’ dans le langage informatique, par exemple) et donc même ce que le gestionnaire programmeur connait déjà pourrait être rapidement oublié dans le marasme de tout ce qu’il y a à connaitre. Pour le gestionnaire hors secteur, il n’est peut-être pas nécessaire d’apprendre à coder selon un langage particulier (ça ne fait jamais tort), mais une familiarité avec des fonctionnalités de logicielles avancées ou d’interfaces web sont de plus en plus appréciée. La disponibilité de ces outils d’autoformation ne doit pas minimiser ce que peut représenter une formation formelle dans les sciences de l’informatique, mais elles peuvent permettre à des gestionnaires amateurs d’en arriver à une meilleure compréhension des possibilités, dilemmes et défis que pose l’informatisation des sociétés. Les outils de la formation sont partout , mais il faut tout de même être en mesure de comprendre le problème.
Il est important de se réjouir de ces avancées informatiques, mais cela met également en lumière la persistance des précautions analytiques à prendre et qui sont déjà bien connus en statistique. D’abord, dans toute interprétation, le gestionnaire doit se garder de ne pas transférer des résultats statistiques d’un groupe d’individus pour faire des généralisations sur des comportements individuels. Ce n’est pas parce qu’une personne appartient à un certain groupe que l’on peut affirmer qu’elle se comportera de manière prévisible, tel que supposer qu’un jeune homme est dangereux au volant simplement à cause de stéréotypes de conducteur liés à son groupe. Inversement, on ne peut pas non plus extrapoler le comportement d’un individu pour tirer des conclusions sur un groupe. Dire que tous les jeunes hommes conduisent mal parce qu’on en a vu un conduire mal est une grave erreur de méthodologie. Chaque individu et chaque groupe est unique et ne doit pas être jugé uniquement sur des stéréotypes.
Les éléments clés permettant de comprendre comment les organisations évoluent sous l’informatisation contestent les fondements de ce mouvement (développement d’un environnement organisationnel propice au changement), les choix dans la gestion des données et les options de quantification. Ces préoccupations exigent de faire réfléchir à l’impact de ces transformations sur la prise de décision en entreprise. Pour aborder l’informatisation dans le contexte des affaires, il est essentiel de comprendre que ce n’est pas simplement une question d’avoir un technicien des informations parmi les membres du personnel. Il s’agit plutôt d’une réflexion plus profonde sur la manière dont une entreprise peut quantifier et transformer toutes ses activités en informations exploitables. L’informatisation ne se limite pas à la gestion des données, mais inclut également l’exploration des aspects complexes associés, notamment la gestion de la vie privée et le respect des individus dans un environnement numérisé.
Le forage des données
Le forage de données, ou data mining en anglais, permets d’analyser de grandes quantités de données pour en extraire des informations utiles. Le forage des données consiste à mobiliser ces formules pour l’extraction d’information implicite, inédite et utile, à partir de l’analyse de grandes quantités de données diversifiées. Appliqué à la gestion, le but du forage des données est d’extraire des informations pertinentes à la résolution de défis administratifs, commerciaux et organisationnels. Le forage des données à des racines dans les mathématiques. Une part importante des modèles d’analyse trouvent leur ascendance dans une application à une base de données de formules de statistique. C’est le cas des modèles de régression ainsi que des modèles d’arbre de distribution. Certains modèles viennent d’ailleurs dans les mathématiques, notamment les modèles neuronaux. La modélisation a d’abord pour résultat de proposer des algorithmes, soit des séries de règlements illustratifs des observations possibles dans les tendances de variables entre les cas. La modélisation propose aussi de prévoir des résultats d’observation selon ces mêmes algorithmes, mais pour un nouvel échantillon dont une ou plusieurs valeurs sont manquantes, duquel il nous faut regrouper un nouveau cas, ou encore prévoir la conformité à des associations possibles. Par exemple, en proposant une valeur manquante, le data mining répond à des types de problèmes de tendances futures dans les choix des acteurs.
Trois familles de modèles se sont avérées particulièrement utiles pour la résolution des problèmes décisionnels. Chacun parvient à dire quelque chose au sujet d’un nouveau cas qui se présente pour ajout dans la base de données. On retrouve d’abord les modèles supervisés, ceux qui visent à produire une variable manquante (selon l’exemple du paragraphe précédent). Parmi ceux-ci figure la grande variété des adaptations de la statistique. Les modèles supervisés sont utiles pour effectuer des prédictions d’un choix parmi d’autres options possibles que ferait un cas nouvellement ajouté à la base de données. Notamment, le choix d’acheter ou d’autrement prendre part à l’offre de l’organisation. Selon les caractéristiques des acheteurs passés, un modèle supervisé est en mesure de prédire si une nouvelle personne, étant donné ses caractéristiques, deviendra elle aussi un acheteur. Les modèles d’association identifient des relations dans les composantes d’un cas. Hormis que les modèle d’association fonctionnent typiquement à partir de donnée booléenne (une option 0 ou 1), la nuance d’avec les modèles supervisée est que ces relations ne sont pas nécessairement dans un sens de causalité, simplement de présence parallèle. Ces modèles peuvent servir à comprendre quelle sont les associations entre la présence commune d’item, par exemple un étalage de magasin. Si l’étalage dans une épicerie ne semble pas regrouper des aliments d’un même type, il faudrait soupçonner qu’il regroupe des aliments dont la présence commune est retrouvée dans les reçus des clients. Enfin, les modèles de segmentation (regroupement), vont chercher à classer les cas au sein de groupes aux caractéristiques communes. Usant de données quantitatives (ou converties ainsi), ces modèles tentent de produire des partages entre les cas d’une base donnée. L’étanchéité des groupes est une mesure à observer pour la validation du modèle et le nombre de groupe peut lui aussi faire l’objet d’une manipulation (le gestionnaire peut ‘forcer’ ses cas au sein de 3, 4 ou X groupes) ou d’une détermination par l’application du modèle. La segmentation ayant été effectuée, il est alors possible de placer un nouveau client (nouveau cas) dans une catégorie qui aura été construite à partir d’observation des caractéristiques de clients antérieurs. Les applications sont pertinentes au marketing comme elles peuvent l’être pour la gestion des ressources humaines. Chacune des familles de modèle est à déployer selon la nature du problème que rencontre le gestionnaire, mais à lui bien sûr de la reconnaitre.
| Catégories | Approches et modèles | Applications | Adaptations algorithmiques |
| Supervision (Classification) | Régression, arbre décisionnel, Réseaux de neurones, SVM | • Susceptibilité à devenir client
• Identification des attentes et intérêts des clients |
Règlements logiques ou algébriques permettant de séparer les exemples en plusieurs classes connues, selon les valeurs des champs, ou selon leur corrélation. |
| Segmentation (clustering) | Moyenne-K, (k-means), mixtures de gaussiennes (EM) | • Segmentation des marchés en groupes de clients aux caractéristiques similaires. | Regroupement des exemples (cas) selon leurs caractéristiques communes |
| Association | Panier d’achat, RBM, Séquence Apriori, OneR, ZeroR, Eclat, FP-growth | • Suggestion des achats
• Prédiction temporelle des ventes • Détection de la fraude |
Ensembles d’items dont les caractéristiques sont parallèles ou récurrentes sur le plan temporel |
L’utilisation de ces modèles doit donc permettre d’analyser des données et de prendre des décisions plus éclairées. L’apprentissage automatique repose sur l’identification de régularités dans les données pour prendre des décisions. Ce principe s’applique à de nombreux autres domaines : dans le commerce, il peut servir à recommander des produits aux consommateurs en fonction de leurs habitudes d’achat ; en médecine, il peut aider à détecter des maladies à partir d’images médicales ; dans l’industrie, il peut optimiser la maintenance des machines en prévoyant les pannes avant qu’elles ne surviennent. Par exemple, si le gestionnaire cherche à améliorer les performances de vente de son entreprise, mais qu’il ne sait pas précisément quel sera le chiffre d’affaires de la semaine prochaine, un algorithme d’apprentissage automatique peut analyser les données passées (ventes précédentes, tendances du marché, saisonnalité, etc.) et fournir une prévision des ventes futures. Prenons le cas d’un organisme prêteur qui souhaite évaluer la capacité d’un individu à rembourser un prêt. En analysant des facteurs tels que le niveau d’éducation, le salaire, l’historique de crédit, le statut de propriétaire ou locataire et d’autres éléments socio-économiques, un algorithme peut établir un score de risque. Ce score soutient ensuite l’institution financière dans sa décision d’accorder le prêt ou non (le degré d’influence permise du modèle est précisément cette dimension d’automatisation que le gestionnaire doit préciser). L’objectif ici est donc d’établir des règles sous forme d’algorithmes permettant de prédire une valeur manquante et donc l’utilisation d’un modèle supervisé est avisée. À partir de ces règles, les gestionnaires tenteront d’extraire des informations. La production des modèles, comme la production des données avant elle, est soucieuse d’intégrer dans sa démarche autant de données que possible. Plus les bases de données utilisées pour l’entraînement sont vastes et diversifiées, plus les modèles deviennent précis et nuancés. Règle générale, pour obtenir un modèle fiable, il faut au moins 10 000 cas pour l’entraînement du modèle, avec le tiers servant à la validation. Avec un volume de données insuffisant, le modèle risque d’être biaisé ou de manquer de précision. Une base de données restreinte limite la capacité du modèle à produire des prédictions robustes et représentatives.
Comme champ de recherche, la modélisation vise à comprendre comment les choix dans la formation des modèles peut être elle-même sujette à des projections. L’enchainement dans la formation des algorithmes a été théorisé il y a plusieurs décennies, mais ce n’est que récemment que le soutien informatique a pu être rassemblé. Ainsi, ce que l’on nomme l’intelligence artificielle peut être conceptualisé comme un algorithme dont l’exécution première crée la possibilité d’une autocontinuité dans la capture et le raffinement des bases de données au soutien de sa modélisation. L’apprentissage automatique et l’intelligence artificielle sont donc des concepts reliés, mais distincts. L’apprentissage automatique désigne le processus de modélisation de données de manière à procurer des projections de rendements futurs. L’intelligence artificielle consiste à enchainer ces processus de modélisation dans une suite pouvant alors rendre compte d’un processus de génération des circonstances de questionnement. Simplement dit, l’apprentissage automatique est mené par le modèle, mais l’intelligence artificielle est la possibilité d’automatise la sélection dans la modélisation, y compris les variables et cas qui seront utilisés pour la constituer. La modélisation est une étape du processus de transformation des données en informations, l’informatisation est la prise en main du processus, c’est-à-dire la capacité de mener un processus de questionnement avec une intervention limitée de la part du gestionnaire.
Il va de même que les organisations d’aujourd’hui peuvent aussi prendre avantage de l’intelligence artificielle, certaine de manière plus agressive ou avancée que d’autres. Cela ne signifie pas que tout est utile ou nécessaire pour chaque entreprise, mais les gestionnaires contemporains sont actuellement en train de découvrir précisément ce que l’intelligence artificielle peut accomplir pour eux. Il est intéressant de constater comment ces technologies sont intégrées de manière créative dans divers domaines. Par exemple, on peut imaginer un avenir où les postes de travail seront assistés par des intelligences artificielles capables d’analyser précisément et de manière autonome, ajustant automatiquement les opérations commerciales, mais sous la supervision d’un gestionnaire qui verra à la conformité des principes éthiques et légaux en vigueur. Cela reflète les conditions actuelles des technologies dans le monde des affaires. Encore et toujours, le gestionnaire doit définir ce que ces technologies signifient et comment les exploiter au mieux. La question aux lèvres de tous les gestionnaires est actuellement : est-ce que les intelligences artificielles peuvent redéfinir l’avenir de votre entreprise ?
Culture informationnelle
L’informatisation est l’une des plus grandes transformations culturelles de l’histoire de l’humanité. Elle a fondamentalement altéré la nature des rapports qui unissent la multitude, pour le bien ou pour le pire. En ce qui concerne les organisations, l’introduction de cette grande variété des nouvelles tâches, logiciels et bases de données a transformé le travail au quotidien. Le gestionnaire feuillette de moins en moins de documents en papier pour finalement, aujourd’hui, préférer d’encadrer ses activités par des logiciels. Il en va de même pour les employés, qui seront eux aussi encadrés (par les gestionnaires) dans leurs traitements des informations. Ces transformations plutôt anodines n’ont pas toujours de quoi à trop sévèrement altérer l’équilibre de l’éthique d’une organisation. Mais toute l’informatisation n’est pas aussi neutre. Dans la poursuite de l’informatisation, la capture de données interdites ou même la poursuite de questions non éthiques à partir de données autrement neutres introduisent dans la gestion de l’informatisation des dimensions d’éthique qui interpellent le gestionnaire. Le choix de capturer ou non des informations sensibles, ou le refus d’une question trop invasive représente des types d’incidents qui correspondent à ce genre de problème, qui n’est peut-être pas aussi nouveau qu’on voudrait le penser. L’informatisation encourage la capture des observations au sein de l’organisation elle-même ainsi qu’en dehors, et des deux côtés est-il possible de repérer des décisions sur l’utilisation des données qui soient problématiques.
Les problèmes éthiques dans la décision informatisée sont largement orientés par les prises et l’utilisation de l’information. Par exemple, partout aujourd’hui des caméras capturent nos moindres gestes, mais en fin de compte c’est l’utilisation de cette information qui peut être problématique. Elle peut être traitée avec des normes d’anonymat selon le précepte de ne pas enfreindre à la dignité de la personne. Mais elle peut tout aussi bien servir pour y enfreindre. Par exemple, les gouvernements cherchent à obtenir des informations bancaires pour des raisons variées. Aux États-Unis, ainsi que dans d’autres nations comme la Chine et la France, des demandes sont livrées aux grandes banques pour accéder à ces données financières. Cette pratique soulève des questions sur l’utilisation de ces données, qui peut aller du contrôle de la fraude (une activité légitime) au contrôle des personnes (une activité dont la légitimité est en question dans le monde démocratique). Tout tourne donc ici autour de l’utilisation des données, ce qui comprend leur traitement pour la réalisation de métadonnées. Il y a des utilisations des données qui sont correctes et acceptables sur le plan de l’éthique (ou de la loi), et d’autres qui ne le sont pas. Par exemple, est-il éthique qu’une personne conduisant une voiture rouge paie des primes d’assurance plus élevées parce qu’une pluralité des accidents de la route implique des voitures rouges? Est-ce qu’on peut imposer à tous les jeunes hommes qu’ils paient des assurances plus élevées parce que les modèles indiquent que ce groupe est plus de risques ? Ces questions soulignent la nécessité d’examiner la manière dont les données sont utilisées, dans ce cas dans le domaine de l’assurance. La gouvernance des normes institutionnelles liées aux TIC peut sembler complexe, mais elle n’est pas impossible. Et comme elle soulève des questions importantes sur la vie privée, il semble crucial de questionner quels sont les normes applicables aux informations recueillies à notre égard. Le gestionnaire retrouve ici une dimension où faire preuve d’éthique, car c’est souvent à lui de voir à l’application des normes. Il doit en cela compléter ce qui est quand même une responsabilité de voir à la collecte et l’utilisation éthiques des données.
S’il ne parvient pas à exercer un jugement éthique concernant les informations fournies par les modèles algorithmiques, le gestionnaire risque précisément de rencontrer ces problèmes anciens de statistique où l’individu est jugé selon le groupe auquel il appartient. Et ces débats éthiques ne sont pas tous faciles à résoudre. Par exemple, si les données montrent que les clients qui achètent de la bière achètent également des cacahuètes, comment utiliser cette information ? Le gestionnaire doit-il placer ces deux produits côte à côte dans le magasin pour encourager les ventes, ou les éloigner l’un de l’autre pour influencer différemment le comportement des clients ? Est-il même éthique de promouvoir la vente de l’alcool, étant donné l’émergence d’un soupçon de propriété cancérigène? Ce type de décision nécessite une réflexion éthique sur la manière dont les données sont employées pour élaborer des stratégies commerciales.
L’informatisation dans les espaces de travail risque de fortifier des relations de pouvoir entre les divers acteurs de l’entreprise. Tous les humains ont en commun d’avoir à utiliser les toilettes à un moment donné. Cela fait partie de notre quotidien, tout comme notre présence dans un espace de travail. Lorsque le gestionnaire commence à considérer ces pauses comme une atteinte à la productivité, il évolue vers une culture dont l’informatisation fera en sorte d’exacerber les relations de pouvoir dans les lieux de travail. En recueillant des données à ce sujet, il est possible de créer une base de données qui pourraient être utilisées à mauvais escient. Comme nous l’avons observé au module 3, la prise de décision est étroitement liée à la culture des organisations. Avec l’informatisation viennent des transformations culturelles importantes puisqu’elle altère la prise de décision, ou du moins propose la possibilité de le faire. Il peut suivre ce qui peut être des pratiques et croyances arbitraires et peu réfléchies, menant à des décisions injustes et répressives. Il est aussi important de considérer ce que l’on risque de perdre dans ces transformations, notamment une partie de sa mémoire organisationnelle.
Conclusion
À l’ère actuelle, le gestionnaire en herbe ne doit plus voir sa formation comme une simple suite d’évaluation, mais plutôt comme une opportunité de stimuler son cerveau dans un monde où il est désormais en concurrence avec les intelligences artificielles. Le gestionnaire sera toujours nécessaire, mais la continuité de son utilité repose dans sa capacité à naviguer des choix informationnels (des choix au sujet des informations) de manière à rendre évident ce qui peut être automatisé et ce qui ne devrait pas l’être. Ces choix doivent bien sûr découler d’une prise de conscience évidente au sujet de la dimension d’éthique. Une tâche peut-elle être laissée à l’automatisation, où y a-t-il un trop grand risque de déroute non éthique de sorte que le gestionnaire doit assurer une supervision plus directe. Il est donc important d’apprendre non seulement l’aspect technique, mais aussi comment reconnaître les questions éthiques qui entourent l’utilisation des données. L’intelligence artificielle évoque des craintes légitimes pour le marché du travail. Ces perspectives sont largement inspirées de la dimension apprenante des TIC contemporaines. L’idée d’amélioration chez ces intelligences soulève la crainte d’être déplacé chez la gestion. Mais finalement, elle ne fait que remettre en question quelles sont les choses dont le gestionnaire doit s’occuper plus directement et qu’est-ce qu’il délègue. Le gestionnaire doit continuer à réfléchir sur la manière dont elle intègrera les TIC dans ses pratiques, les changements qu’elle apportera, et particulièrement la façon dont elle modifiera nos processus décisionnels. Et en cela, sa tâche n’est pas aussi nouvelle qu’on le penserait.
L’informatique est un monde complexe et trop peu d’espace a été laissé ici pour souligner l’importance de la formation. Ce que nous observons aujourd’hui pourrait être qualifié de démocratisation de l’intelligence artificielle. Il est désormais relativement accessible pour beaucoup de personnes d’utiliser des intelligences artificielles basées sur de vastes modèles de langage dont les accès ne sont pas gratuits, mais aussi assez abordables. Le gestionnaire peut raisonnablement apprendre des bases en programmation et créer ses propres intelligences artificielles, bien qu’il y ait une courbe d’apprentissage importante portant sur les logiciels spécialisés. Il de plus en plus important que les TIC soient au cœur de nos débats publics. Une distance entre la classe des législateurs et l’informatique n’est pas désirable, compte tenu de la complexité de l’informatique et les connaissances essentielles qu’il faut pour se prononcer sur le besoin des lois, par rapport à la liberté de l’éthique. En effet, combien de nos législateurs ont une formation en informatique?
