Appendix 3: Chapter 10 Exercises
Introduction
The purpose of this exercise is to demonstrate the relationship between open data, electronic lab notebooks (ELN), and software containers in reproducible research. You will interact with code in a published ELN, which is hosted in GitHub and made interoperable by myBinder. Many of the fundamentals you learned in chapter 10 will be illustrated here.
This exercise has both an introductory and an advanced activity. In the introductory activity, you will explore the code on GitHub and examine a static version of an ELN. In the advanced activity, you will launch a software container in an interface called Binder. The container hosts an electronic lab notebook that queries an open dataset. You can interact with it online without altering the original copy. The online container allows you to run the code without installing any programs on your computer. The advanced activity requires a higher knowledge of coding, or simply the perseverance to keep trying. The software container doesn’t always load on the first try, and the code won’t work unless it is perfectly entered. This exercise is meant to show benefits and complexity of reproducible research. Don’t be afraid to Google terms that you don’t understand. Additionally, ChatGPT is really good at explaining code and how it functions.
At the very end of the exercise there is a reflection question. You can answer this question even if you haven’t done the advanced activity.
Part 1 (Introductory): Explore the Data and the Code Repository
The Programme for International Student Assessment (PISA) is an international initiative that measures the educational attainment of 15-year-old students. The openly available dataset is available to researchers for their own analyses. This activity uses an analysis of the PISA dataset conducted by Klajnerok (2021), which was published to GitHub using a Jupyter Notebook.
The repository was forked into a new GitHub repository so we could use it for this activity: https://github.com/mediagestalt/PISA. In GitHub, a fork is a copy of a dataset that retains a link to the original creators (“Fork a repo,” n.d.). In the following image, you can see the fork symbol and a link to the dataset that precedes this one. These linkages are important as they show the provenance of the dataset.
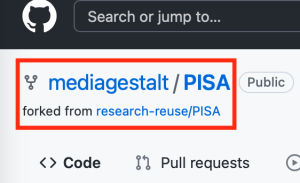
QUESTION 1: What is the name of the repository from which this code originated?
Answer: The original creator of the code is https://github.com/mklajnerok/PISA. For this project, the code and data were reused by https://github.com/research-reuse/PISA and placed into a software container called Binder. This assignment is a fork of https://github.com/research-reuse/PISA, and adapted for this textbook. The original dataset was published by PISA.
You can navigate GitHub as you would any nested file directory. In the image that follows, you will see a screenshot of GitHub. The filenames are in the left column, the middle column shows the comment that was left to describe the last changes to the file, and the right column shows the last time the file was edited. You can also see the last person that contributed to the code repository at the top left of the table and the versioning information at the top right of the table, shown in the following image as “83 commits.”
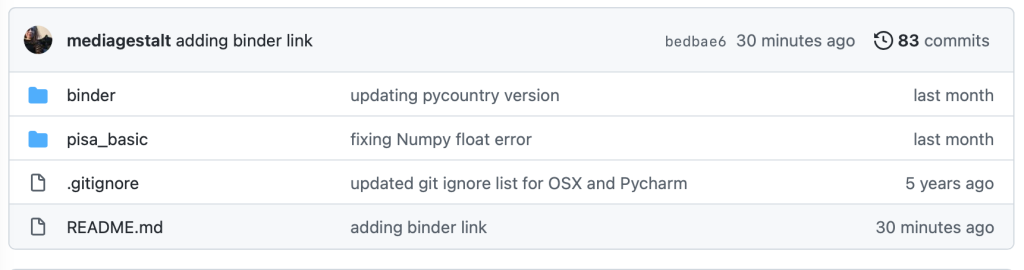
GitHub Folders
For the next question, find the following files in the repository. You will find the files in different folders, so don’t be afraid to look around.
requirements.txtpisa_project_part1.ipynb
Click on the title of a file to view it. Then, scroll down to view the content of each file. You are looking for a list of dependencies, which are the software packages required to run the code in the notebook. In the pisa_project_part1.ipynb file, you will find the list under the heading “Extracting PISA dataset,” as shown in the following image.

QUESTION 2: Compare the dependencies listed in requirements.txt with those listed in the pisa_project_part1.ipynb notebook. What is different?
Answer: The requirements.txt file includes the version numbers of the dependencies; the notebook file simply lists the names. Versioning information for dependencies is very important because unknown changes to dependencies may prevent the code from working properly, or at all. This is a scenario where updating to the newest version of a program is not always preferred. Curating code for reuse is essentially freezing the code ‘in time,’ so that it runs exactly as it did when it was created.
The file names and directories show the importance of relative file paths. In the Git directory, find the location of the following .csv files and match them to where they are named in the notebook file.
- pisa_math_2003_2015.csv
- pisa_read_2000_2015.csv
- pisa_science_2006_2015.csv. Hint: the files are listed in the second code cell below the dependencies.
Part 2 (Advanced): Run and Alter the Code
It is time to explore the software container. Since the original researcher wrote the code in a Jupyter Notebook (a commonly-used ELN), it is possible to ‘containerize’ the code and the data so that it can be run by other users.
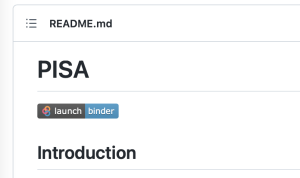
Return to the main page of the GitHub repository, also known as the README file. Then, click on the launch binder button, shown in the following image.
Depending on your computer and your internet speed, the software container may take several minutes to load. If it takes too long, just close the page and try launching again from the GitHub Binder link. You can see the Binder loading screen in the following image.

When the notebook loads, scroll down and explore the page. The live notebook looks exactly like the notebook file you viewed in the GitHub repository.
As you examine the notebook, you will see narrative text interspersed with blocks of code inside defined cells. There is additional commentary inside the code cells. This is what literate programming looks like.
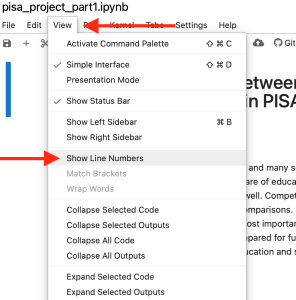
To make the next part of the activity easier, turn on the line numbers in the file. This will show a number on each line of the code block, making it easier to identify specific lines of code. The location of this command is shown in the next image. You won’t see an immediate change to the page, as this is just a setting change.
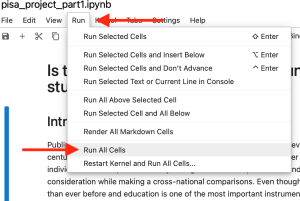
Now it is time to run the code. To start, you must run all of the code cells. The location of this command is shown in the following image. As you scroll down the page, you will begin to see new content below some of the code blocks. These are the results of the analysis for which the code was written. There may be text, tables, or visualizations.
You will also see a number in square brackets in the left margin beside each block of code. Start at the beginning of the page and read down until you reach cell number 6. Don’t worry if you don’t understand the code. Pay more attention to the textual descriptions, and the comments inside the cells. You can identify a comment because it will be preceded by a [#] or [“””] symbol. Read the narrative descriptions until you reach cell #6. It is shown in the following image.
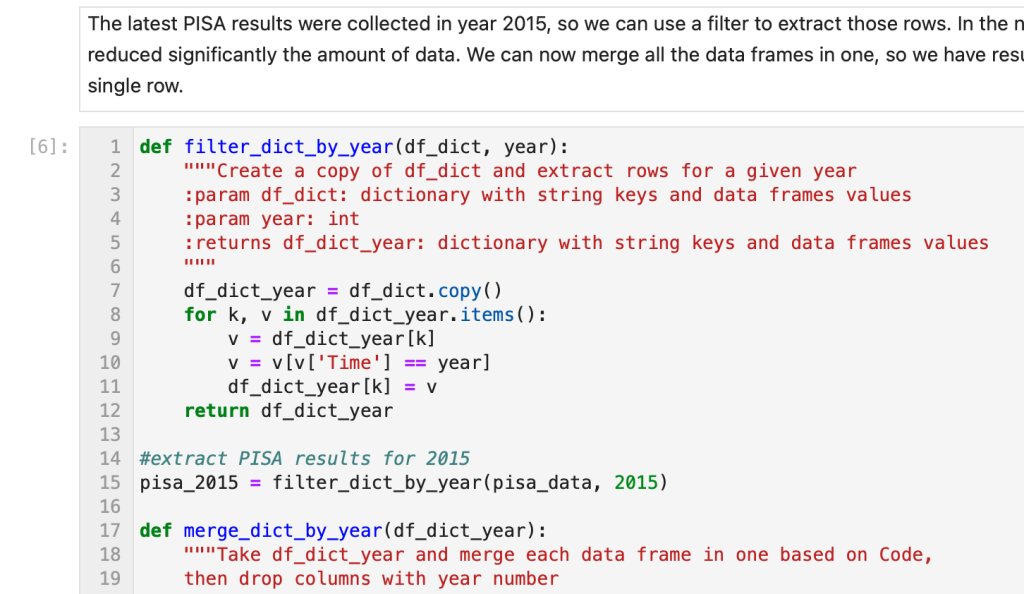
QUESTION 3: What does the comment on line 14 of cell 6 say?
Answer: #extract PISA results for 2015. Hint: If you didn’t find it, use the ‘Find’ feature in your browser to search for the phrase. Then, you’ll see the line and cell number.
The PISA dataset in this project has data going back to 2000. We can load more data by altering the code. For the next part of this activity, you will need to add new code to the ELN and re-run the code block. To get the additional lines of code, go to this code snippet (called a Gist) in GitHub. It is an edited version of cell 6 in the notebook.
Line 14 in the Gist and line 14 in code block 6 in the notebook are the same. The ‘#’ before the text means that the line is a comment, not live code. Line 15 is where the code starts. In this Gist, there are extra lines of code below line 15 that don’t appear in the notebook. Copy the code from lines 16 and 17 and paste them in the notebook. Make sure the notebook matches lines 14-17 in the Gist.
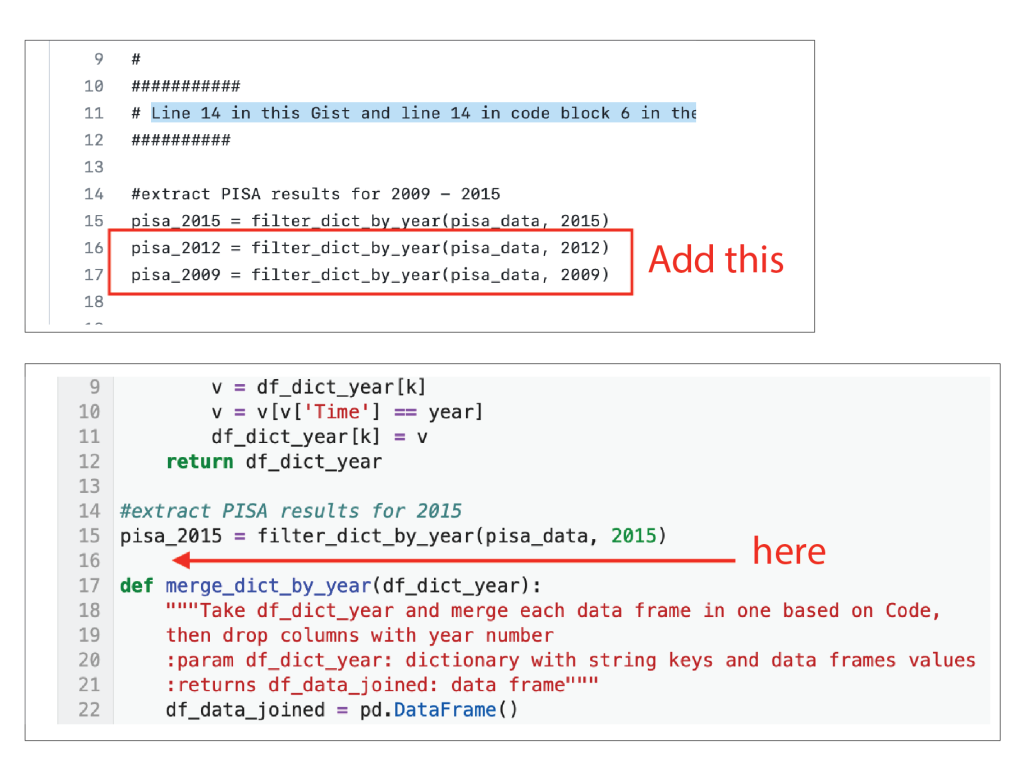
This code is calling on the PISA dataset. Before you added the extra lines, the data from PISA was from 2015 only. Adding the two extra lines of code imports additional years of data from PISA (2012 and 2009). If you want to experiment more, you can add additional lines with different years. Just be sure to follow the format exactly as you see it.
Adding just these lines isn’t enough. You’ll need to follow the same process for lines #31 and #40. This code and more instructions can also be found in the Gist. Note that the line numbers in the notebook will change when you add additional code.
Once you’ve added the extra parameters to the notebook, re-run cell 6 in the notebook by clicking in the cell and pressing shift + return. If there are any errors, check your code for typos and try again. You can also use the Run > Run Selected Cells menu command.
From here on, the cell numbers in the notebook will change depending on how many times you run the code within that cell.
Next, keep your cursor in the cell you just edited, and then insert a new cell for each of the additional years you’ve added.
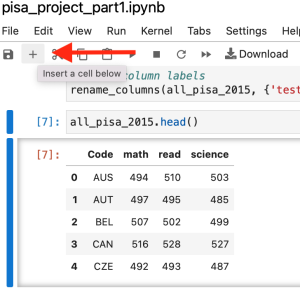
Type the additional variable names for the years you’ve added into the new cells and press shift + return to run each one.
For example: all_pisa_2012.head() all_pisa_2009.head()
If there are errors, check for typos and try again.
See how many other cells you can get to work! Both with the existing variables, and the new variables you’ve created.
If you make a mistake and break the code beyond repair, you can check the source file to copy and paste the original code. You can also reload the file completely with File > Reload Notebook from Disk in the notebook top menu.
Reflective Questions
- Based on what you’ve learned in chapter 10 and your exploration of the software container, what changes would you make to the structure of the file directory to improve the organization? Have the data and software been adequately documented? Work through the Reproducibility Framework (Khair, Sawchuk, and Zhang, 2019) to help with your assessment.
- Is the provenance of these data clear to you? Explain.
- What features of this dataset have enabled its reproducibility? What would you improve?
Reference List
Fork a repo. (n.d.). GitHub docs. https://docs.github.com/en/get-started/quickstart/fork-a-repo
Klajnerok, M. (2021). Is there a relationship between countries’ wealth or spending on schooling and its students’ performance in PISA? Medium. https://towardsdatascience.com/is-there-a-relationship-between-countries-wealth-or-spending-on-schooling-and-its-students-a9feb669be8c
Khair, S., Sawchuk, S., Zhang, Q. (2019). Reproducibility Framework. https://docs.google.com/document/d/1E0c5-DDVo2MMoF2rPOiH2brIZyC_3YZZrcgp0x6VCPs/edit
online tools built off the design and use of paper lab notebooks
in GitHub, a copy of a dataset that retains a link to the original creators.
a record of the source, history, and ownership of an artifact, though in this case the artifact is computational.
a plain text file that includes detailed information about datasets or code files. These files help users understand what is required to use and interpret the files, which means they are unique to each individual project. Cornell University has a detailed guide to writing README files that includes downloadable templates (Research Data Management Service Group, n.d.).
where code, commentary, and output display together in a linear fashion, much like a piece of literature.
