Solutions
Chapter 7, Data Cleaning During the Research Data Management Process
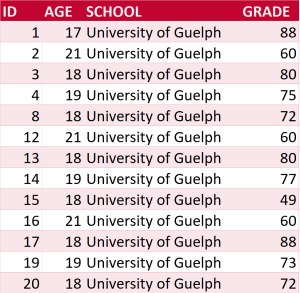




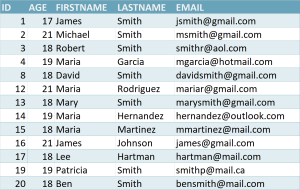
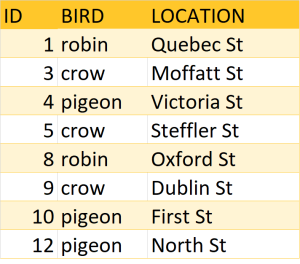
Chapter 8, Further Adventures in Data Cleaning
Exercise 1:

Exercise 2:
There is one outlier based on the boxplot. We replace this outlier by NA. Then calculate the mean by removing all NAs.
>boxplot(mydata_csv$Width)
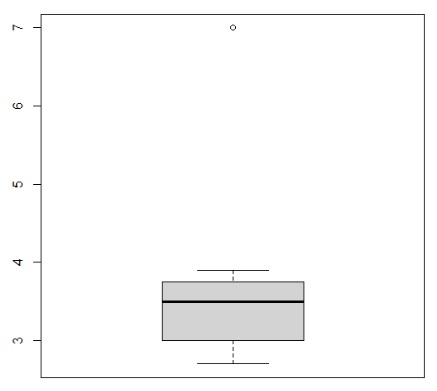
Exercise 2 boxplot
> summary(mydata_csv$Width) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's 2.700 3.000 3.500 3.814 3.750 7.000 1 > mydata_csv$Width[mydata_csv$Width==7] = NA > mean(mydata_csv$Width, na.rm = T) [1] 3.283333
The mean is 3.283333.
Chapter 13, Sensitive Data: Practical and Theoretical Considerations
Reflective Question 1:
Tri-Council Policy Statement: Ethical Conduct for Research Involving Humans – TCPS 2
Reflective Question 2:
Direct identifiers are any of the following:
- Full or partial names or initials
- Dates linked to individuals, such as birth, graduation, or hospitalization (year alone or month alone may be acceptable)
- Full or partial addresses (large units of geography, such as city, fall under indirect identifiers and need to be reviewed)
- Full or partial postal codes (the first three digits may be acceptable)
- Telephone or fax numbers
- Email addresses
- Web or social media identifiers or usernames, such as Twitter handles
- Web or Internet protocol numbers, precise browser and operating system information (these may be collected by some types of survey software or web forms)
- Vehicle identifiers, such as licence plates
- Identifiers linked to medical or other devices
- Any other identifying numbers directly or indirectly linked to individuals, such as social insurance numbers, student numbers, or pet ID numbers
- Photographs of individuals or their houses or locations, or video recordings containing these; medical images or scans
- Audio recordings of individuals (Han et al., 2020)
- Biometric data
- Any unique and recognizable characteristics of individuals (e.g., mayor of Kapuskasing or Nobel prize winner)
Quasi-identifiers may include any of the following:
- age (can be a direct identifier for the very elderly)
- gender identity
- income
- occupation or industry, job-related variables
- geographic variables
- ethnic and immigration variables
- membership in organizations or use of specific services
Many other examples exist!
Reflective Question 3:
Both location variables that may pinpoint the whereabouts of an endangered species could be considered sensitive data
Chapter 14, Managing Qualitative Research Data
Self-Assessment Question 1:
highly disclosive; can be difficult to de-identify; predominantly voice or text based; collected from humans; context dependent; often collected from marginalized communities or vulnerable individuals; often come from highly sensitive research topics; are less likely to be archived, shared, and reused
Self-Assessment Question 2
oral histories, participant diaries, photographs, video, documents, artifacts, open-ended survey responses
Self-Assessment Question 3
To document activity and decision making throughout the life of a study, helping detail what took place, when, and why
Self-Assessment Question 4
capturing; processing; securing or backing up; transferring for transcription; transferring to other team members; translating
Self-Assessment Question 5
original recording; original transcript; verified transcript; anonymized transcript; edited transcript; coded transcript
Self-Assessment Question 6
Co-production is intended to bring together the complementary expertise of qualitative researchers and librarians/archivists/data specialists to establish and advance standards for managing qualitative data.
Chapter 17, Research Data Management and the Open Science Movement
Reflective Question 1:
Both definitions mention the importance of research collaboration as an important aspect of open science. The free availability of research results is also a common feature, although the Foster Open Science definition places much greater emphasis on traditional open access and is in this sense more reductive. Vicente-Saez and Martinez-Fuente’s definition speaks more of access and sharing than of open access as such, since sharing may be subject to legal or ethical restrictions. This definition is therefore more in line with the FAIR principles than that of Foster Open Science. The principles of transparency are also less developed in the Foster Open Science definition. It only mentions conditions favoring reuse, without being explicit about these conditions, and makes no reference to quality assurance and auditing, which are facilitated by transparency principles.
Reflective Question 2:
Answers may vary according to someone’s point of view and expertise, and could include examples outside those listed in this chapter. However, Table 2 indicates that the pragmatic school of thought frequently shapes open science. Examples include open research protocols, academic social networks and other collaborative platforms, such as electronic lab notebooks, and finally open peer review.
Reflective Question 3:
False. Commercial publishers have consolidated their position by making article processing charges the predominant open access business model, and we cannot rule out that acquiring infrastructure linked to research data is not in their line of sight. Elsevier already offers its data repository, Mendeley Data. The Scholarly Kitchen blog regularly discusses acquisitions and mergers in the field of healthcare publishing. Take a look at this example: “Elsevier to Acquire Interfolio.”
Reflective Question 4:
For qualitative research, the production of research data is often dependent on the context in which it was produced. Thus it is problematic to think of reproducibility if research contexts are unique. Reproducibility in qualitative research must therefore be considered in light of various epistemological postures, which themselves call for their own methodologies and analytical guidelines.
Reflective Question 5:
The field of critical data studies.
