First Principles in Research Data Management
1 The Basics: An Introduction to Research Data Management
An Introduction to Research Data Management
Kristi Thompson
Learning Outcomes
By the end of this chapter you should be able to:
- Define the terms research data, Research Data Management, and Data Management Plan.
- Describe the three elements of the 2021 Tri-Agency Research Data Management Policy.
- Understand the link between Research Data Management and research replicability.
- List some common elements of a Data Management Plan and explain their importance.
Introduction
In 2021, Canada’s three federal research funding agencies, the Canadian Institutes of Health Research (CIHR), the Natural Sciences and Engineering Research Council (NSERC), and the Social Sciences and Humanities Research Council (SSHRC), released the Tri-Agency Research Data Management Policy. The policy’s stated goal is to ensure that “research data collected through the use of public funds should be responsibly and securely managed and be, where ethical, legal and commercial obligations allow, available for reuse by others” (Government of Canada, 2021). Funding agencies in many other countries have released similar policies.
This chapter will discuss some of the fundamental questions of Research Data Management (RDM) in Canada: Where is the push towards formal RDM coming from? What is research data, in terms of this policy and in general? What are the requirements of good data management?
Canada’s Three Federal Research Funding Agencies
The Natural Sciences and Engineering Research Council of Canada (NSERC), the Social Sciences and Humanities Research Council of Canada (SSHRC), and the Canadian Institutes of Health Research (CIHR), are Canada’s three federal research funding agencies. They are sometimes collectively referred to as the Tri-Council or the Tri-agency; throughout this text they will often be collectively referred to as the agencies. As the source of a large share of Canada’s research money, they are able to set policies that significantly influence how research is conducted in Canada. In addition to the Tri-Agency Research Data Management Policy, they are responsible for the Policy Statement on Ethical Conduct for Research Involving Humans (TCPS 2), the Open Access Policy on Publications, and others. Their policies are not laws. However, in addition to deciding whether or not to award funding to individual researchers, the agencies can each bar entire institutions from administering research funds, which would make every researcher at that institution ineligible to apply for funds. This gives the agencies a huge amount of power to shape how research is done in Canada.
What Are Research Data?
To understand RDM requirements, you have to understand the definition of research data. The term research data combines two key concepts: research and data. Research might be described as a systematic process of investigation, a way of finding out about things. Research transforms information into knowledge and is a part of how we discover the world. Data can be an important part of that knowledge discovery. Data are one type of information or evidence that serve as input to research. But not all information in a research project is data.
Canada’s Tri-Agency FAQ (2021) states that “What is considered relevant research data is often highly contextual, and determining what counts as such should be guided by disciplinary norms” (Government of Canada, 2021b). In short, context is important; you can’t really define research data without looking at how it’s being generated and used. The FAQ section “How are research materials related to research data?” delves into this: “Research materials serve as the object of an investigation, whether scientific, scholarly, literary or artistic, and are used to create research data. Research materials are transformed into data through method or practice.”
That transformation is a key part of separating general information from research data. Data are the results of taking raw information from any source (e.g., informants/survey respondents, archival or bibliographic data, social media, scientific instruments, document text) and collecting or assembling that information into a structured form to serve as an input for further research. Because of the work that goes into structuring, annotating, and organizing research data, they can also be considered a research output, along with books, articles, and other items created by researchers. Research data are a vital source of information that may not be captured in any other source. If they are published or shared, they can be referred to by other researchers and cited just like any other research output.
For example, a researcher may use a set of research articles as input for their research. If the researcher is simply reading those articles and referring to their contents through citations to support other ideas, the articles are serving as research material, but not research data. However, if the researcher takes the same set of articles, imports them into a piece of software, and reviews and annotates them in a structured way to come to some sort of formal conclusion on the group of articles as a whole, then those articles form a dataset and are considered research data.
Research data can be secondary data, meaning that the researcher did not collect or assemble the material themself. In this case, the structuring or refining to serve as input may have been done by another researcher. Or the data may come pre-structured if it’s administrative data (say, extracted from an admissions database). But something that is a structured collection of information that is being refined into research through analysis is still considered research data.
Data Structure
A common structural format for data, used in spreadsheets and statistical files, is the rectangle, in which data are organized into rows and columns. Each row will contain one case, which is a single unit of the thing being studied (e.g., one person in a survey, or a fruit fly in an experiment). Each column will be used to store one variable or characteristic of each case, such as the age of each person (or fruit fly!) in the study.
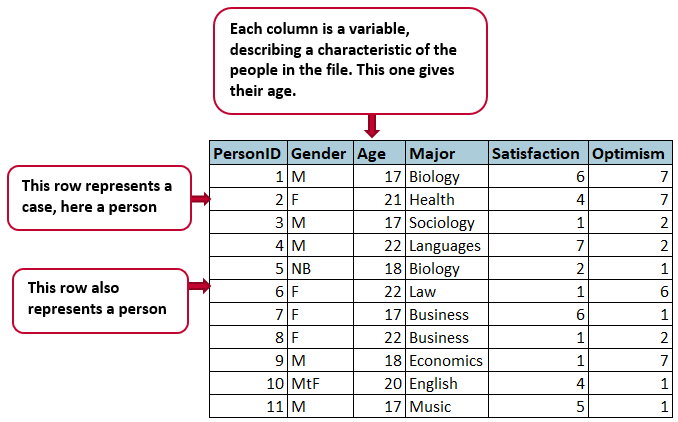
While we’re talking about data structure, here are some simple rules for organizing rectangular, spreadsheet-style data to make it easier to manage:
- Organize the data as a single rectangle, with subjects/cases as rows and variables/features as columns; add a single row as a header at the top, with brief, descriptive names for what is in each column.
- Put just one thing in a cell and do not merge cells. Every cell should have one piece of information that corresponds to one row and one column (one case and one variable).
- Create a data dictionary — a separate document explaining what is in your rows and columns.
- Do not include calculations or functions in the original data files.
- Do not use font colour or highlighting as data.
The figure above shows what data structured this way will look like. Data in this simple format can be read by and used in any spreadsheet program or statistical package.
What Is Research Data Management?
Research data management is a general term that describes what researchers do to structure, organize, and maintain data before, during, and after doing research. In this sense, anyone who collects or uses data for the purpose of doing research is doing research data management. Creating a data file and deciding where to save it, renaming a data file, or moving it are all research data management activities. Research Data Management (RDM), spelled with capitals, is an emerging discipline that is concerned with researching and developing ways to manage research data more effectively. The idea behind data management is to use a set of techniques to structure, organize, and document the information that is serving as input to research and to do so in a way that will allow others to understand and reproduce your research and make use of the data that went into your research.
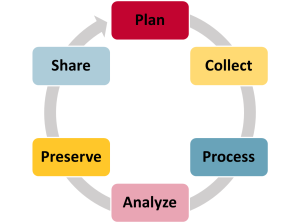
The research data lifecycle is often used to illustrate the cyclical nature of research. Researchers start by planning their research. They then collect, process, and clean data to get them into shape for analysis and analyze them to form conclusions about their research. Finally, they take steps to preserve the data for the long term and make them available for others to use and study. In practice, the cycle is more complex, with many steps happening at the same time. For example, preservation of the original data needs to start as soon as the data has been collected to avoid any possibility of loss, and researchers will often process, analyze, and reprocess their data as they work with them. This is a very data-centric view of research, as the research cycle will include many other steps, from applying for funding to writing up and publishing results.
Reproducibility, Replicability, Traceability
Reproducibility, replicability, and traceability are three related but distinct concepts that are important to understanding the importance of good RDM. For research to be reproducible, it must be possible for researchers who were not part of the original research team to repeat the research using the same data, methods, and code, and to get the same results. In practice this means data, code, and thorough documentation need to be available to external researchers.
For research to be replicable, researchers who were not part of the original research team need to be able to repeat the original research study on newly collected or different data and get the same or similar results. For this to be possible, the original researchers’ methods need to have been documented and published, but the original data do not need to be available.
For research to be traceable, researchers who were not part of the original research need to be able to reproduce the analysis dataset from the original, as collected or acquired datasets. If data are traceable, everyone can be confident that no undocumented changes happened to the dataset. External researchers should also understand why every change made to the data happened, who made it, and what the decision process was. Research data are evidence — if you’ve ever watched CSI, this is like the chain of custody that ensures evidence in a criminal case hasn’t been contaminated.
Remember those data structure tips from earlier in the chapter? Simple, standardized, widely understood formats and structures are good for reproducibility, replicability, and traceability.
Mandating specific standards for how data should be managed isn’t meant to put arbitrary constraints on how people do research. The standards help to preserve research integrity by having researchers handle their data in ways that can be followed and understood and, therefore, reproduced and replicated. Research findings that cannot be repeated or reproduced are not credible. Mandated RDM also includes the goal of increased data sharing, not just so research can be reproduced directly, but so data can be reused for other projects, allowing for the creation of more research at a lower cost. The 2021 Tri-Agency Research Data Management Policy includes three requirements intended to help Canada move towards this goal.
Replicability Crisis
The replicability crisis is an ongoing issue in the physical and social sciences that calls the credibility of these sciences into question. Starting around 2010, psychologists began to repeat earlier studies in an effort to reproduce their findings and found they were unable to consistently do so. In one major effort to replicate 28 studies, close to half could not be replicated, and 32% showed effects opposite to that which had been originally reported (Klein et al., 2018). This means that people who rely on this research have been teaching, carrying out further research, and changing practices based on results that may be incorrect. Similar issues have since been reported in other fields, such as biology, medicine, and economics. The original studies may have included bad data, incorrect analysis methods, or atypical samples, among many possible reasons for the discrepancies. If the original data aren’t available and traceable, it’s hard to tell.
Tri-Agency Policy: The Three Requirements
The three requirements laid out in the Tri-Agency Research Data Management Policy (Government of Canada, 2021) are:
-
- Institutional Strategies. Institutions (generally post-secondary institutions and hospitals) that are eligible to administer Tri-Agency funding are required to develop formal RDM strategies, post them on their websites, and submit them to the agencies by a deadline. These strategies need to explain how the institution intends to support its researchers in doing better RDM and in coping with the next two requirements. Strategies submitted to the agencies are linked on their Institutional Strategies page.
- Data Management Plans. The agencies will start requiring that researchers submit plans explaining how they intend to manage their data, at least for some funding opportunities. These plans will be considered when the agencies decide how to award grants.
- Deposit. When grant recipients publish any articles or other outputs arising from research supported by the agencies, they will be required to deposit the data and code that support that research output into a digital repository. This is a fairly narrow requirement. A researcher may collect dozens of variables but write a paper that only makes direct use of a small subset of them. This subset is what they need to deposit. Also note that depositing is not the same as sharing. Data that is confidential or otherwise shouldn’t be shared needs to be deposited in a secure private location.
Data Management Plans (DMPs)
A Data Management Plan (DMP) is a formal description of what a researcher plans to do with their data from collection to eventual disposal or deletion. DMPs have existed in some form or other since the 1960s (Smale et al., 2020), but adoption has been slow and, in many disciplines, it is still not widespread. Internationally, DMPs have become a frequent requirement of funding agencies, including in the United Kingdom and in the United States. Tools and templates have been developed to help researchers write plans that meet funding agency requirements. The main tool used in Canada is called DMP Assistant. It is a web-based tool that asks users a series of questions about their data and research plans, with contextual help and guidance on how to answer those questions.
DMPs are intended to help researchers manage data across all phases of the research data lifecycle, from collection to sharing. They are often described as “living documents” that should be updated as needed while researchers work with their data. They can include a variety of different elements (Williams et al. (2017) identified 43 topics that may be required as elements of DMPs), and which elements may be required or useful can vary by discipline or by type of data. The elements of a DMP are intended to prompt researchers to consider how they will handle their data and what resources they will need before they start their research. The Tri-Agency Policy asks the researcher to submit a plan that addresses the following:
- how data will be collected, documented, formatted, protected, and preserved
- how existing datasets will be used and what new data will be created over the course of the research project
- whether and how data will be shared
- where data will be deposited.
Research funders, in Canada and internationally, want researchers to use DMPs to demonstrate that their data will be collected, stored, and preserved in a way that facilitates transparency, data sharing and reuse, and reproducibility of results. Researchers who do this will be given an edge when applying for funding to collect or use data. DMPs are also intended to have benefits for researchers, helping them think through and work with their data more effectively. In effect, DMP requirements are a form of social engineering, intended to nudge researchers into doing better research.
These benefits are largely unproven. In theory, carefully considering all the elements that DMPs incorporate should lead to better research, but theory sometimes collides with practice. “Indeed, an extensive literature review suggests there is very limited published systematic evidence that DMP use has any tangible benefit for researchers, institutions or funding bodies” (Smale et al., 2020). Given that DMPs are meant to enhance the research enterprise, it is unfortunate that relatively little thought seems to have been put into researching whether they actually achieve that goal or how they could be modified to do a better job.
We’ll look quickly at some of the topics often covered in a DMP.
Data Collection
Researchers need to list the types of data they will be collecting or acquiring and what file formats the data will be saved in. From the start, researchers should consider formats that will allow for data preservation, sharing and reuse; good formats are ones that can be used in widely available software packages. Open formats are even better: they have published standards so that anyone with the training can write the software to read them. Open formats are future-proof.
Thinking about file naming conventions before starting data collection can be surprisingly important. Researchers who don’t establish a system ahead of time are liable to end up with an assortment of files with names like “data.csv”, “data2.csv”, “finaldata.csv”, “fixeddata.csv” and so on. An example of a system for naming and tracking different versions of a data collection might be “shortdescriptivename-changemade-date.ext”. Including the change and date in the file name acts as a rudimentary form of version control, which will be discussed in more detail in chapter 10, “Supporting Reproducible Research with Active Data Curation.” Version control should also include further systems to help enhance the traceability of the data, such as noting information about every change made to the data on a master documentation file or making all changes to the data using code that is updated and saved after each change.
Documentation and Metadata
Documentation is essential to both preservation and traceability. If a file is preserved as a sequence of 0s and 1s on disk, but no one knows what those numbers represent, then the file hasn’t really been preserved. Documentation needs to include elements like a master study document noting where the data came from and how they were collected, giving columns in spreadsheets easily understood names, and recording detailed information about changes made to the data files.
Documentation can also include giving files and folders human-readable names and coming up with a sensible structure of folders and subfolders. One common form of additional documentation is the README file, which is simply a file included in each folder that lists the files present in that folder, describes the contents of each file, and explains any relationships between the files (e.g., if there are code files that were used to generate data files).
For many types of data, including health and survey files, codebooks are also important. Codebooks describe the structure and contents of data files according to some schema. For example, a survey codebook will list all the questions asked in a survey (which will be coded as variables), describe different possible response options, explain how the survey sample was chosen, and explain any additional variables created by researchers. Ideally, you should have sufficient documentation on your deposited data that someone who is knowledgeable in your field would be able to:
- understand and follow the steps you took to collect your data in the first place and the decisions you made along the way
- take your original data file and reproduce the changes you made to it to get your data into their final form
- run the analyses that produced your final publishable results.
The documentation section of a DMP should also include information explaining how the researchers will make sure they keep track of and record every change made to the data file. If there will be many people working with the data, it’s especially important to have a system.
Code Files
Statistical programs, such as SPSS, Stata, and R, and general-purpose programming languages, such as Python, let you modify and analyze data by typing commands into a code file and then running them. Some programs, like SPSS, will also let you generate the commands using menu options. If any changes made to your data are done using code files, you will always be able to go back and figure out exactly how every change to your data happened.
Storage and Backup
Researchers can explain where they will be storing their data and how secure it will be in the storage and backup section. Storing only one copy of the data — on a personal hard drive that could fail or a USB stick that could be stepped on — is surprisingly common (Cheung et al., 2022). It’s also a bad idea, as many have discovered. A system that ensures data are regularly backed up is a good idea. The 3-2-1 backup rule is a widely used standard: there should be three copies of each file, the copies should be on two different media, and one copy should be off-site. If data is stored somewhere with an automated backup system (such as a departmental server or a cloud service) then that reduces the need for additional copies since a copy will be in the backup system.
Preservation and Sharing
Research transparency and the preservation and sharing of research data are key goals of RDM, so it is essential to address them in a DMP. The gold standard for data sharing is posting a complete, well-documented dataset in an online archive, where it can be downloaded by anyone, with an open or Creative Commons license that explicitly allows it to be reused. Some licenses include the stipulation that data that are used in further research should be properly cited (though, even if that is not stipulated, it is good practice and professional courtesy to do so).
If data will be shared, the most important step is identifying an appropriate repository. There are many appropriate data repositories available. Many institutions (universities, colleges, hospitals, etc.) have institutional data repositories with features that ingest data to preservation formats. These institutions commit that the data will be preserved and backed up. Individual journals also host archives to make data relating to the papers they publish available. There are also disciplinary repositories that host particular types of data, such as genomic data or geospatial data.
However, open sharing in a repository is not always advisable, and for some kinds of data (such as medical data) sharing may be highly unethical. Confidentiality, commitments made to research subjects, Indigenous data sovereignty, data ownership, and intellectual property concerns can all be reasons why openly sharing a particular dataset is not an option. In cases like this, researchers may need to find alternative sharing methods. One possible alternative would be to share documentation about the data in a repository and invite potential users to contact the research team for access. Sometimes parts of a data collection can be shared while other parts are considered too sensitive. The potential users may need to commit to following certain ethical standards, or other conditions may be applied. In these cases, the data will need to be preserved in some other way, in a secure archive or on a private network. See chapter 13, “Sensitive Data,” for more information.
The preservation and sharing section of a DMP needs to be explicit about how data will be preserved for the long term. It also needs to explain provisions for data sharing, including where it will be deposited, what parts of the data will be shared, and what access conditions there will be, if any. If data can’t be shared openly, the DMP needs to explain why not.
Conclusion
Research Data Management is a general term for the work researchers do as they organize and maintain data during and after their research. It is also a growing field of practice that engages librarians, data professionals, and researchers with the question of how to best manage data to include research transparency, data preservation, and data sharing so it can be criticized, studied, and used by other researchers and research consumers. Ultimately, RDM is about doing better research.
Reflective Questions
-
- Pick a field of study and describe some examples of research data that might be used by researchers in that field. What might be some particular challenges of managing this data?
- Read the Tri-Agency Research Data Management Policy. What does it tell you about how the funding agencies view RDM?
- Find your (or a local) institution’s RDM strategy. What does it tell you about how the institution views RDM?
- Visit DMP Assistant or use the template in Appendix 1 and create a DMP for an imaginary research project.
Key Takeaways
- Research Data Management (RDM) is an umbrella term for the activities undertaken by researchers while they work with data. As a field of study, RDM asks you to engage with fundamental questions about the best way to perform research.
- Canada’s three federal research funding agencies have a policy on Research Data Management that is intended to encourage researchers to make their research more transparent and to preserve and share their data.
- Data Management Plans (DMPs) are documents prepared by researchers to describe how they intend to manage their data. They cover many aspects of working with data, including data collection, documentation, storage, sharing, and preservation.
Reference List
Cheung, M., Cooper, A., Dearborn, D., Hill, E., Johnson, E., Mitchell, M., & Thompson, K. (2022). Practices before policy: Research data management behaviours in Canada. Partnership: The Canadian Journal of Library and Information Practice and Research, 17(1), 1-80. https://doi.org/10.21083/partnership.v17i1.6779
Government of Canada. (2021a). Tri-Agency research data management policy. https://www.science.gc.ca/eic/site/063.nsf/eng/h_97610.html
Government of Canada. (2021b). Tri-Agency research data management policy – Frequently asked questions. https://science.gc.ca/site/science/en/interagency-research-funding/policies-and-guidelines/research-data-management/tri-agency-research-data-management-policy-frequently-asked-questions#1b
Klein, R. A., Vianello, M., Hasselman, F., Adams, B. G., Adams Jr., R. B., Alper, S., Aveyard, M., Axt J. R., Babalola, M. T., Bahník, Š., Batra, R., Berkics, M., Bernstein, M. J., Berry D. R., Bialobrzeska, O., Binan E. D., Bocian, K., Brandt, M. J., Busching, R., … Nosek, B. A. (2018). Many Labs 2: Investigating variation in replicability across samples and settings. Advances in Methods and Practices in Psychological Science, 1(4), 443-490. https://doi.org/10.1177/2515245918810225
Smale, N. A., Unsworth, K., Denyer, G., Magatova, E., & Barr, D. (2020). A review of the history, advocacy and efficacy of data management plans. International Journal of Digital Curation, 15(1), 1-29. https://doi.org/10.2218/ijdc.v15i1.525
Williams, M., Bagwell, J., & Zozus, M. N. (2017). Data management plans: The missing perspective. Journal of Biomedical Informatics, 71, 130-142. https://doi.org/10.1016/j.jbi.2017.05.004
a policy applying to data collected with research funding from one of Canada's three federal funding agencies. The policy is intended to encourage better research by requiring researchers to create data management plans and preserve their data.
the Natural Sciences and Engineering Research Council of Canada (NSERC), the Social Sciences and Humanities Research Council of Canada (SSHRC), and the Canadian Institutes of Health Research (CIHR) (the agencies) are Canada’s three federal research funding agencies and the source of a large share of the government money available to fund research in Canada.
Tri-Council Policy Statement: Ethical Conduct for Research Involving Humans. The primary harmonized framework that accounts for Canadian-wide laws and broader ethical paradigms applicable to the rights of human participants in research
sources of information or evidence that have been compiled to serve as input to research.
data collected as a part of the process of administering something. Administrative data is used to track people, purchases, registrations, prices, etc.
a term that describes all the activities that researchers perform to structure, organize, and maintain research data before, during, and after the research process.
the cycle in which data is collected, processed, analyzed, preserved, and then shared so other researchers can start the cycle anew.
reproducible research is research that can be repeated by researchers who were not part of the original research team using the original data and getting the same results.
replicable research is research which can be repeated by other researchers on new or different data, getting the same or similar results as the original researchers.
traceable research is research where external researchers can understand and repeat every change made to the raw data to get it into final shape for analysis.
a formal description of what a researcher plans to do with their data from collection to eventual disposal or deletion.
a web-based tool which asks users a series of questions about their data and research plans, with contextual help and guidance on how to answer those questions.
a system for automatically tracking every change to a document or file, allowing users to revert to all previously saved versions without needing to continually save copies under different file names.
a plain text file that includes detailed information about datasets or code files. These files help users understand what is required to use and interpret the files, which means they are unique to each individual project. Cornell University has a detailed guide to writing README files that includes downloadable templates (Research Data Management Service Group, n.d.).
