Droit d’auteur
Le droit d’auteur protège les expressions originales d’un contenu qui sont fixées sur un support tangible (physique ou numérique) – il est à noter qu’il existe certaines différences entre les divers régimes nationaux de droit d’auteur et que dans la plupart des cas la loi s’applique dans l’espace national où l’expression est créée. Nous vous recommandons de faire un suivi auprès de la bibliothèque ou du bureau du droit d’auteur de votre établissement pour toute question précise au sujet des licences.
Les données pourraient être protégées par le droit d’auteur si un jugement ou une compétence était appliqué au choix des données à inclure ou à leur disposition (les données brutes ne sont pas de la propriété intellectuelle, mais des faits du domaine public). Des facteurs externes à votre équipe de recherche ou à projet peuvent déterminer si les données sont protégées par le droit d’auteur et à qui elles appartiennent. Il est conseillé de consigner les données et la propriété des droits d’auteur dès les premières étapes d’un projet.
Une licence est une permission accordée par la ou le titulaire du droit d’auteur permettant à une autre personne d’utiliser son œuvre à certaines fins et sous certaines conditions. Le droit d’auteur reste la propriété de sa ou son titulaire. Les licences ouvertes sont utilisées par les titulaires de droits d’auteur pour préciser les droits qu’ils souhaitent conserver, tout en communiquant les types d’utilisation que d’autres personnes peuvent faire de leur travail, sans avoir à demander la permission chaque fois.
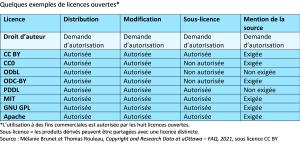
Le tableau ci-dessus montre, du point de vue d’une chercheuse ou d’un chercheur qui souhaite réutiliser du contenu dont elle ou il n’est pas propriétaire, comment le droit d’auteur se compare aux licences ouvertes populaires pour le partage de données, de logiciels ou de codes. Vous pouvez utiliser différentes licences pour la recherche publiée, la rédaction, les données et les sorties de code de votre recherche. Il est à noter que, comme les mécanismes particuliers de réutilisation du code et des données diffèrent de la façon dont les « œuvres créatives » (y compris la rédaction universitaire) sont réutilisées ou republiées, on recommande souvent d’utiliser des licences ouvertes propres au code et aux données, plutôt que d’utiliser la même licence Creative Commons que vous pouvez utiliser pour les produits créatifs du projet (Creative Commons).
Lorsque vous planifiez vos propres produits de publication, vous devez faire des distinctions entre la licence ouverte et celle qui restreint l’utilisation. Par exemple, vous voulez probablement conserver le droit d’auteur sur vos articles de recherche, et vous assurer de respecter les accords de droit d’auteur et de licence avec des personnes dont vous partagez le contenu intellectuel ou créatif dans le cadre d’activités de mobilisation du savoir. Toutefois, vous voudrez peut-être accorder une licence de données ouvertes sur l’exportation de métadonnées.
Les documents et les données de recherche sont toujours envisagés du point de vue de la chercheuse ou du chercheur. Si vous travaillez dans le domaine de la recherche-création et que vos produits sont des expressions artistiques ou culturelles qui ont une valeur en dehors du milieu universitaire, vous pourriez tenir compte du fait que vos « données de recherche », tel qu’elles sont produites, diffusées, citées et réutilisées dans une économie universitaire, constituent néanmoins des travaux créatifs qui vous appartiennent. Vos données devraient peutêtre demeurer protégées par un droit d’auteur et ne pas être partagées par le biais de plateformes de publication de données. Ou encore, vous pourriez considérer vos créations artistiques comme des documents de recherche potentiels pour de futurs chercheuses, chercheurs et artistes. Il pourrait être avantageux pour vous et la communauté de recherche de prendre le temps d’apprendre comment utiliser sciemment les licences ouvertes et les dépôts de données comme des systèmes d’autoédition et d’autoarchivage parallèles qui vous permettent de partager votre expression artistique selon vos conditions.
Les lois des Premières Nations, des Métis et des Inuits sur la propriété intellectuelle, y compris l’expression culturelle et le savoir traditionnel, peuvent différer des lois nationales et internationales sur le droit d’auteur et la propriété intellectuelle. Il convient de noter, par exemple, que la Loi canadienne sur le droit d’auteur accorde le droit d’auteur pour les histoires, les chansons, la poésie, etc., à la première personne qui les enregistre, c’est-à-dire les capte dans des enregistrements imprimés ou audio. Cela a fait en sorte que des histoires ou des chansons traditionnelles deviennent « la propriété » des chercheuses et chercheurs, plutôt que des peuples autochtones qui les ont créées. Cette loi ne respecte pas les traditions orales de nombreux peuples autochtones du Canada. Lorsque vous travaillez avec des données qui appartiennent à des Autochtones, il est essentiel de vous informer des lois autochtones et de leurs répercussions sur votre travail. Chaque contexte d’engagement sera différent et orienté par des protocoles propres aux collectivités des Premières Nations, des Inuits et des Métis.
 Voici des normes communes établies dans le cadre du partenariat de SpokenWeb qui permettent le partage de données entre les parties du partenariat et éventuellement au public:
Voici des normes communes établies dans le cadre du partenariat de SpokenWeb qui permettent le partage de données entre les parties du partenariat et éventuellement au public:
- un protocole d’éthique commun avec consentement éclairé qui permet le partage de données au public;
- une exemption commune de numérisation pour les artéfacts audio historiques.
La chercheuse principale ou le chercheur principal (CP) du site central (Jason Camlot) établit une norme que les autres CP du site partenaire suivent. Un formulaire de protocole d’éthique pour les entrevues orales sur l’histoire a été soumis par l’Université Concordia. Une fois ce formulaire de protocole accepté par le comité d’éthique de la recherche avec des personnes participantes de l’Université Concordia, il pourrait être modifié pour répondre aux exigences des comités d’éthique de la recherche (CER) du site du partenariat et soumis pour examen accéléré.
Cela signifie que les restrictions en matière de protection des renseignements personnels et de confidentialité concernant l’utilisation et le partage de ces entrevues sont normalisées dans l’ensemble du partenariat. Ces restrictions sont établies en fonction des choix faits par les personnes interrogées sur le formulaire de consentement. Ces entrevues sont des « données » dotées d’attributs particuliers régissant le partage. Les principes de ces protocoles d’éthique pour les entrevues orales sur l’histoire sont également respectés lors des événements publics tenus par le partenariat SpokenWeb. Par exemple, les personnes participant au symposium remplissent un formulaire d’autorisation et de renonciation pour les enregistrements et les publications à venir découlant de leurs séances.
➔Modèle de flux de données : Collecte de données
Questions de la chercheuse ou du chercheur :
Si je travaille avec un cadre de lutte contre l’oppression ou des méthodologies décolonisatrices, devrais-je utiliser une base de données ou un système descriptif existants ou en inventer de nouveau ? Quelles sont les normes existantes ? Quelles sont la main-d’œuvre, les ressources, les relations nécessaires pour l’adapter ? Mon processus d’adaptation ou l’idée de nouveaux modes de description font-ils partie de mes données ? Dois-je consigner cela et, le cas échéant, quelles parties du processus ?
? ? ? ! *
Questions sur le modèle de flux de données qui contribuent à votre réflexion sur ces éléments complexes :
- Pouvez-vous énumérer vos types de données ? Quels fichiers auront besoin de métadonnées ?
- Avez-vous des protocoles de propriété collective ?
Commencez par réfléchir à tous les formats et types de données que vous allez recueillir et créer dans le cadre de votre projet de recherche. Réfléchissez également à leur lieu d’entreposage et à leur utilisation dans le cadre du projet. Assurez-vous de les organiser et de faire preuve de cohérence dans vos processus de collecte et dans vos normes descriptives. Créez un inventaire de vos types de données et des formats de fichier dans lesquels elles sont stockées. Cette étape vous aidera également à déterminer les éléments qui sont inclus ou non dans la portée de votre travail en matière de traitement, de préservation et de partage.
Au moment d’organiser vos données et vos fichiers, choisissez des conventions de nommage et amorcez votre réflexion sur la façon de structurer les dossiers et les fichiers. Les conventions de nommage (c.-à-d. utiliser une méthode cohérente et descriptive pour nommer vos fichiers) sont cruciales pour pouvoir trouver facilement les fichiers pertinents et faciliter le contrôle des versions. Cela peut sembler fastidieux au départ, mais en suivant de simples directives, vous éviterez la frustration d’avoir à ouvrir une série de fichiers différents pour tenter de trouver le bon document ou la bonne version. Pour structurer vos fichiers, utilisez des dossiers (qui respectent également une convention de nommage!), soyez précis au sujet du contenu à verser dans chacun de ceux-ci et organisez-les hiérarchiquement (du sujet plus vaste au plus restreint, p. ex., Administration> Communications > Courriels > Courriels de Felicity). Si les données sont remises ou fournies à une communauté des Premières Nations, métisse ou inuite, cette structure doit également être construite d’une manière qui reflète les besoins et priorités de cette communauté, être accessible et correspondre aux capacités de cette communauté.
Planifiez votre collecte de données en tenant compte de la contribution que les données nouvellement recueillies peuvent apporter ou non aux ressources de données existantes. Que cette contribution se produise en même temps que votre collecte de données ou plus tard dans le projet, ce plan de regroupement de vos données dans un système existant aura une incidence sur la façon dont vous recueillez et enregistrerez vos données.
Les pratiques exemplaires de gestion des données établissent une distinction entre :
- les données administratives (contrats d’adjointes et adjoints de recherche (AR), dossiers de gestion de projet, budgets, etc.) et les données de recherche;
- les documents de recherche et les données de recherche;
- les plateformes, logiciels, codes et autres ressources élaborés pour partager ou visualiser vos recherches;
- le contenu des données et le format du fichier dans lequel les données sont stockées (par exemple, il est possible de stocker des textes dans des tableurs ou des bases de données en plus de stocker des textes dans des documents Word).
Les détails techniques sur la façon dont vous planifierez et exécuterez votre collecte de données pour votre projet de recherche particulier dépassent la portée du présent Manuel. Il vous incombera de définir et de trouver les ressources nécessaires pour satisfaire vos exigences techniques particulières. Cela dit, lorsque vous avez défini votre plan de collecte de données, votre structure de fichier et vos conventions de nommage, il est temps d’ajouter du contexte à vos données pour vous assurer que d’autres personnes les comprennent. C’est là que les métadonnées sont utiles.
Les métadonnées sont les données qui fournissent de l’information sur les données. Les métadonnées s’avèrent la meilleure façon de décrire vos données et de pointer vers les sources originales; à ce stade, il est bon de commencer à penser aux métadonnées qui seront nécessaires pour vos fichiers de projet.
Vous vous rappelez la distinction faite entre les documents de recherche et les données de recherche dans la première section? Dans ce cas, les descriptions de l’enregistrement et de nombreuses données de recherche du partenariat de SpokenWeb sont en fait des métadonnées.
Les responsables de SpokenWeb ont commencé par chercher et adopter des schémas de métadonnées existants pour les descriptions des collections littéraires et des fichiers audio. Cela a permis de gagner du temps et de faire en sorte que les données produites puissent être importées dans d’autres systèmes existants, comme les catalogues de bibliothèque et Wikidata. Cela signifiait également que les chercheuses et chercheurs pouvaient importer ou emprunter des métadonnées de systèmes existants. Or, les équipes de SpokenWeb ont constaté que ces schémas avaient des limites; elles ont donc ajouté les compétences techniques et la main-d’œuvre nécessaires à leur méthodologie de projet afin de concevoir des conventions personnalisées de métadonnées et de catalogage pour les artéfacts audio analogiques. Tous les artéfacts audio sont décrits dans un système d’ingestion des métadonnées affectueusement baptisé SWALLOW – faisant allusion à la poésie romantique et au fait « d’avaler » ou d’ingérer des données – ce qui signifie que toutes les personnes collaborant au partenariat peuvent faire des recherches dans les collections audio des autres. De plus, les adjointes et adjoints de recherche de SpokenWeb ont tous une formation en saisie de métadonnées et ils constituent l’essentiel de la main-d’œuvre déployée pour apporter cette contribution au projet universitaire.
Utilisez des métadonnées pour décrire vos données par type, utilisation, titre, source, etc. pour différents publics; cela constitue également un moyen de faire le suivi des licences et des conditions de consentement. Les métadonnées doivent être lisibles par machine pour les recherches informatiques, mais aussi descriptives pour les humains (c.-à-d. d’autres membres d’équipes de recherche, collaboratrices et collaborateurs, etc.) pour leur permettre de trouver les données de manière efficace. Les métadonnées peuvent également servir à décrire vos méthodes. La méthodologie de votre projet est également constituée de données et de renseignements nécessaires pour que les collaboratrices et collaborateurs, les partenaires et les chercheuses et chercheurs futurs puissent citer, utiliser ou réutiliser votre projet.
Certaines communautés de recherche dans les disciplines ont déjà établi des schémas de métadonnées (bon nombre se trouvent dans le Metadata Standards Catalog [en anglais seulement]). C’est une bonne pratique de commencer par là. En utilisant un schéma existant, vous pouvez mettre l’accent sur sa modification ou l’élargissement de sa portée selon vos besoins, vos valeurs et vos questions. Vous contribuez également au potentiel de données de la collectivité dans son ensemble, et cette pratique s’inscrit dans les principes FAIR de recherche, d’accessibilité, d’interopérabilité et de réutilisabilité. Les catalogues de schémas de métadonnées peuvent vous être utiles. Vous pouvez également consulter votre bibliothécaire et d’autres spécialistes des métadonnées institutionnelles.
À tout le moins, créez un fichier README (lisezmoi) qui explique vos choix pour cette description des métadonnées. Il devrait aussi décrire les structures de fichier pour faciliter la compréhension de la collection ou des décisions et observations, afin que votre collection soit réutilisable. Chaque type de données ou fichier peut avoir plusieurs types de métadonnées différents :
- Administration (chaînes de commandes, journaux, manifestes)
- Technique (propriétés, caractéristiques du fichier)
- Description (résumés, annotations, contexte, termes clés)
- Préservation (état et qualité du dossier, par exemple)
- Accent sur le consentement et la permission
Vous pouvez envisager la rédaction des métadonnées de différentes façons. Par exemple, si vous avez les compétences ou les connaissances techniques, vous pouvez adapter ou créer un système de catalogage pour ces métadonnées qui permettra l’importation et l’exportation de données sophistiquées, l’établissement de liens vers des sources et la recherche qui va au-delà d’une feuille de calcul. Plus simplement, vous pouvez aussi traiter les métadonnées comme si vous écriviez un texte. Les métadonnées peuvent être considérées comme une narration encodée qui raconte l’histoire de vos données. Les métadonnées peuvent servir de niveau de description qui guide l’interprétation de votre projet. L’ajout de métadonnées peut être aussi simple ou complexe que vous le souhaitez; l’important est de décrire vos données afin que les autres puissent collaborer plus efficacement avec vous, réutiliser vos données ou répéter votre méthode. Si vous constatez que le répertoire créé précédemment ne convient pas à votre travail, vous pouvez chercher des façons d’ajouter des champs pour le corriger ou pour tenir compte d’une réalité qui n’a pas été prise en compte auparavant. Quoi qu’il en soit, il est toujours préférable d’essayer de réutiliser que de repartir de zéro.
Des responsables du partenariat avec SpokenWeb ont discuté avec la critique littéraire crie-métisse Deanna Reder des méthodes et protocoles de recherche autochtones pour les universitaires en littérature. Mme Reder et les membres de l’équipe de The People and the Text (TPatT) (en anglais seulement) s’appuient sur les principes PCAP® des Premières Nations : propriété, contrôle, accès, possession (en santé, les quatre principes de recherches sont le respect, la réciprocité, la pertinence et la responsabilité) et les protocoles propres à la nation ou à la tribu. TPatT s’inspire des travaux de chercheuses/chercheurs et de créatrices/créateurs autochtones comme Skawennati, Jason Lewis, Elizabeth LaPensee et Maize Longboat, et bénéficie du soutien et de l’infrastructure du Collaboratoire scientifique des écrits du Canada (CSEC). 