How LLM Technology Works
It is difficult to formulate a more concise description of how transformer-based LLMs like ChatGPT work, than that provided by Stephen Wolfram:
The basic concept of ChatGPT is at some level rather simple. Start from a huge sample of human-created text from the web, books, etc. Then train a neural net to generate text that’s “like this”. And in particular, make it able to start from a “prompt” and then continue with text that’s “like what it’s been trained with”. (Wolfram, 2023)
While the basic concept may be rather simple, the path to create a fully functioning GPT is anything but. Without going into too much detail, we endeavour to provide enough information for users to conceptualize what’s going on “behind the scenes.” We split the explanation into two parts:
- how the LLM is trained (think of this as how it learns everything it “knows”), and
- what happens when it “is run,” that is, when the end user prompts it with queries.
Training the LLM
Pre-Training: Building the Knowledge Foundation
Before LLMs like ChatGPT are able to process your input (prompts), they first need to be
- taught how to use language, and
- given as much contextual information about the “universe” as possible.
To fulfill both of these needs, they are fed massive text datasets encompassing books, articles, code, and online conversations. These datasets undergo a process of tokenization, mapping to embeddings, and are run through the transformer architecture. The algorithms and mathematics of these processes are beyond the scope of this simplified explanation, but this interactive visual explainer from the Financial Times does an excellent job of illustrating them. More technical resources are provided at the end of this section for those interested in pursuing this topic in more depth.
For closed-source models like GPT-3.5 and 4 (used in ChatGPT), the exact datasets and their weightings are proprietary.
However, open-source LLMs, like Meta’s Llama, publish which datasets they are using, and their weightings. We will have more to say about datasets and their quality in the section on Bias, but for now, the specifics of their source and contents are not germane to understanding the mechanics of how LLMs work. It is enough to know that, as an example, the Llama model was pre-trained on ~4.75 terabytes of text data scraped from various web and (digitized) print sources. This is equivalent to almost 400 million pages of text.
This data is run through the LLM in a cycle of unsupervised learning, cycling through the entire dataset multiple times, adjusting the model parameters on each pass, with performance periodically evaluated against a validation set to monitor progress and prevent overfitting. Training continues until the model’s performance ceases to improve significantly with additional passes.
Fine-tuning: Specialization and Refinement
The next stage of training involves human supervision, in a process known as Reinforcement Learning from Human Feedback (RLHF). This diagram gives one example of an RLHF process; the one used in OpenAI’s InstructGPT:
Figure 1
OpenAI’s RLHF Process
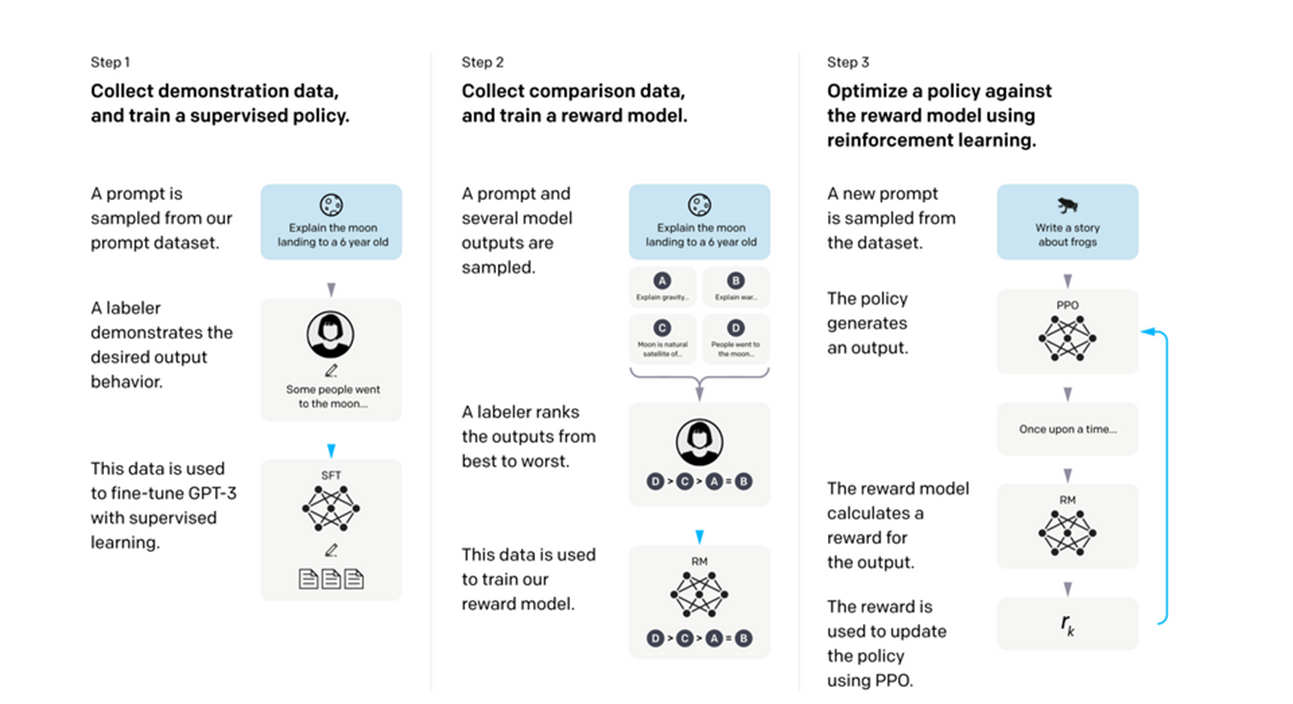
In the first phase of RHLF, a set of sample inputs (e.g., questions a user might ask a chatbot) and exemplar outputs (e.g., replies that would be considered excellent) are created. The LLM is then iteratively trained, adjusting parameters in each iteration, to get closer and closer to the exemplar outputs when presented with the chosen inputs. It is also possible in this stage to specialize the model, using prompts and exemplars that will skew the LLM’s reaction function to a specific field of knowledge, or style of response.
The next phase involves the LLM again being presented with the same sample input several times, with the outputs each numbered. This time, no exemplar is given; instead, a group of trained human raters are given the different answers and asked to rank them in order of preference (against a set of criteria, often helpfulness, truthfulness, and harmlessness). These rankings are then used to train a separate reward model. This reward model is essentially a mathematically encoded representation of human preference (or, at least, of the humans who did the rating— more on this later).
In the final phase, the LLM is again prompted with queries, the outputs of which are then scored by the reward model. The process repeats, and the LLM’s parameters are adjusted iteratively to maximize the score, at a scale and speed not possible using human raters.
User-facing Operation: When the User Asks a Question
Now that we have a familiarity with how LLMs are created and trained, we can discuss what is happening when we use them. When we interact with an LLM like ChatGPT, the same general process of tokenization, mapping to embeddings, and running through the transformer architecture is applied to our prompts as it was to the larger dataset during training. As part of creating effective inputs (prompt engineering), we may give ChatGPT exemplars or model the type of output we would like to see from it (e.g., “write formally, in complete sentences,” “provide the information in a table,” etc.). Some LLMs may perform a limited version of the reinforcement learning described in step 3 of the RLHF section above, by generating multiple responses to our queries, grading them (internally) against a reward model, and discarding all but the top scoring responses. Given that this is a relatively computationally expensive design choice, we might expect to see it only where an LLM would otherwise underperform.
Further Reading
For more detailed explanations on various aspects of the creation, training, fine-tuning and use of LLMs, we refer readers, especially those with a background in neuroscience, math, or linguistics to Stephen Wolfram’s excellent print and online book on the topic, What is ChatGPT Doing… and Why Does it Work?.
Readers with a more software engineering background (particularly of the architect or analyst variety) may appreciate Andrej Karpathy’s talk “Intro to Large Language Models,” in which he uses concrete examples (such as deploying a local install of [pre-trained] Llama 2) as jumping off points to address the topics discussed here, as well as offering many practical considerations for training and running LLMs as live applications:
Finally, readers with a software engineering background (particularly of the developer variety) may enjoy another Karpathy talk, in which he walks through writing and pre-training a custom GPT at the code level:
In the next section, we will cover some the ways in which LLMs are not working , and explain how keeping them front of mind can help us avoid many of their limitations.
