Bias
Datasets
The most obvious form of bias found in tools based on LLMs is data bias. Because LLMs are trained on enormous amounts of text data scraped from the Internet, they absorb the biases present in the data sources. This data can reflect societal prejudices, stereotypes, and imbalances, but can also potentially include toxic ideas and hate speech. Even a company that strives to control for overt hate speech and obvious bias in its output is still beholden to its data sources; we will discuss some mitigation strategies these companies employ later in this section.
It is helpful to know what these enormous training data sets are, in order to understand where bias might enter the system. Jill Walker Rettberg provides a comprehensive analysis of what little information OpenAI has made public about the data sources for its GPT tools, but essentially, there are five main named sources of data, each consisting of billions of pieces of data (or “tokens”), but not all of these tokens are equally valued. The table below is from the paper that introduced GTP-3 in 2020 (Brown et al., 2020).
| Dataset | Quantity (tokens) | Weight in Training Mix |
| Common Crawl (filtered) | 410 billion | 60% |
| WebText2 | 19 billion | 22% |
| Books1 | 12 billion | 8% |
| Books2 | 55 billion | 8% |
| Wikipedia | 3 billion | 3% |
We will look at what these data sets are, but first, notice the quantity of tokens (material) versus the “weight in training mix”: Books1 and Books2 each account for 8% weight in the training mix, even though Books2 contains almost 4 times as many tokens as Books1. As outlined in the table below, not all tokens are created equal. So, what are these sources, and how might they contribute to bias?
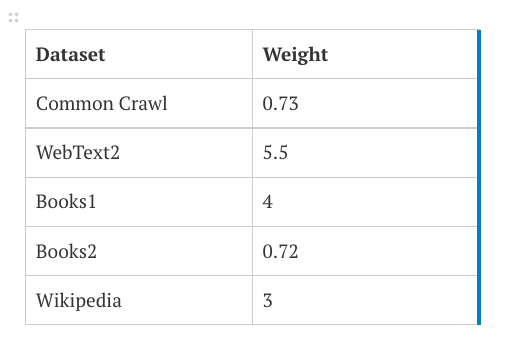
The Common Crawl (filtered) contains millions of scraped web pages, which, while pulling from pages in some 40 different languages, contains predominantly English sites, the majority of which (51.3%) are hosted in the United States (Dodge et al., 2021).
Because these pages on the open web may not be of the highest quality (even once they are “cleaned,” which we’ll discuss more in the section on erasure of marginalized groups), their weighting is lower than most of the other sources. WebText2 is the second set of data, potentially chosen to counterbalance the low-quality of the Common Crawl, containing “web pages which have been curated/filtered by humans… all outbound links from Reddit, a social media platform, which received at least 3 karma. This can be thought of as a heuristic indicator for whether other users found the link interesting, educational, or just funny” (Radford et al., 2019, p. 3). This data set (curated by thousands of Reddit users) has the highest weighting, at 5.5 (as compared to the Common Crawl’s 0.73).
The next data sets are Books1 and Books2. OpenAI’s description of these sets is quite vague: “two internet-based books corpora” (Brown et al., 2020). Rettberg surmises that the company’s vagueness may stem from the copyright status of the works in question (i.e., that OpenAI broke copyright laws in using this material), and suspects that one of the corpora is Project Gutenberg (books in the public domain). One may also be BookCorpus, which “consists of 11038 books that were self-published on Smashwords and are available for free” (Rettberg, 2022). This data set is potentially of poor quality, due to, among other things, it containing
- thousands of duplicated works;
- hundreds of works by the same author (which diminishes breadth); and
- over-representation of certain genres (romance novels) and of Christianity as compared to other religions (Bandy & Vincent, 2021).
It is interesting to note that Books1 is weighted more than 5.5 times as heavily as Books2; perhaps Books1 is Project Gutenberg, containing
- great works of English and European literature, including all of Shakespeare’s oeuvre, a large body of po
 etry, and children’s literature;
etry, and children’s literature; - historical texts such as the Declaration of Independence;
- reference books such as dictionaries and encyclopedias;
- works by renowned scientists, mathematicians, and philosophers; and
- the Bible and the Quran, in different translations.
At first blush, it is easy to see that certain corpora would contain data that, if it doesn’t demonstrate outright bias, at the very least would have certain specific characteristics (e.g., novels and plays from previous centuries and historical documents might have outdated gender norms and ethnic stereotypes; religious texts may have doctrinal imperatives; self-published romance novels could have almost anything at all…). To combat this, OpenAI undertook fine-tuning using Reinforcement Learning from Human Feedback to train the model to recognize desired responses. There are many challenges with RLHF, but it is a necessary step for optimization of various aspects of the model, not the least of which is minimizing toxic speech and bias.
Despite the popular belief that “tools aren’t biased” or “algorithms aren’t racist” or “software isn’t sexist,” the people who built or fine-tuned the tools undoubtedly have some unconscious bias, as all humans do, and the data the tools are drawing from definitely contain bias. One of the most common forms of bias is surrounding gender.
Media Attributions
- Dataset table
