Contexte canadien pour la gestion des données de recherche
5 Partage et réutilisation des données de recherche au Canada : pratiques et politiques
Meghan Goodchild; Shahira Khair; Amber Leahey; Kaitlin Newson; et Lee Wilson
Objectifs d’apprentissage
À la fin de ce chapitre, vous pourrez :
- Comprendre les pratiques, les politiques et les services qui guident le partage et la réutilisation des données de recherche au Canada.
- Déterminer les éléments de l’infrastructure de recherche numérique canadienne, notamment les options de stockage comme les dépôts de données et les plateformes de préservation à long terme, ainsi que les services qui soutiennent l’accès à ces infrastructures et leur utilisation.
- À l’aide d’études de cas, définir les soutiens et obstacles au partage et à la réutilisation des données tout au long du cycle de vie des données de recherche, en plus des secteurs qui doivent être développés.
Introduction
Les chercheuses et chercheurs au Canada, toutes disciplines et tous domaines confondus, produisent des quantités de données encore jamais vues (Baker et al., 2019). Grâce aux progrès de la science ouverte et des politiques de données ouvertes des maisons d’édition, des organismes de financement de la recherche, des groupes disciplinaires et des établissements, les chercheuses et chercheurs réalisent de plus en plus la nécessité de gérer leurs données conformément aux politiques connexes en matière de dépôt et de partage de données. Ces politiques soutiennent des buts plus larges en ce qui a trait à la transparence, à la reproductibilité et à la réutilisation (Groupe de travail de l’Alliance en gestion des données de recherche [GT GDR de l’Alliance], 2020). (Consultez le chapitre 12, « Planification de la gestion des données pour les processus de travail en science ouverte, » pour obtenir un aperçu de la science ouverte et des données ouvertes).
Accélérer le progrès scientifique et éviter les collectes de données dispendieuses constituent des éléments importants en faveur du partage et de la réutilisation des données. Le partage des données permet également de reproduire les résultats de recherche, ce qui améliore l’intégrité des résultats publiés et le degré de confiance à leur égard. Lorsqu’il est facile de découvrir des données de recherche et d’y accéder, cela accroît la visibilité et l’impact de la recherche. Qui plus est, le partage des données, des environnements de recherche et des outils favorise et améliore la collaboration, ce qui se traduit par une plus grande interopérabilité et des économies en recherche.
Dans le but d’optimiser les avantages du partage et de la réutilisation des données, les résultats des données de recherche doivent être guidés par les principes FAIR – Facile à trouver, Accessible, Interopérable, Réutilisable – abordés au chapitre 2 (Wilkinson et al., 2016). De plus, ils doivent être appuyés par une infrastructure et des services de soutien en recherche numérique selon les principes TRUST – Transparence, Responsabilité, Orientation vers l’utilisateur, Durabilité et Technologie (Transparency, Responsibility, User focus, Sustainability and Technology) (Lin et al., 2020). Par conséquent, le partage de données devient une partie intégrante de la recherche de haute qualité, ce qui exige la mise en pratique continue de la gestion des données de recherche (GDR). Des services de GDR émergent au Canada dans toutes les disciplines, dans les établissements ainsi qu’aux paliers régional et national afin d’appuyer les chercheuses et chercheurs en matière de partage et de réutilisation des données.
Dans le cadre de ce chapitre, vous apprendrez au sujet des politiques et des pratiques, de l’infrastructure de recherche numérique ainsi que des outils et des services permettant le partage et la réutilisation des données de recherche au Canada. Nous examinerons les éléments qui soutiennent le cycle de vie des données ainsi que les services relatifs à la curation et à la préservation des données. Enfin, nous aborderons des études de cas afin de mettre en évidence des pratiques de partage et de réutilisation des données et des défis disciplinaires.
Politiques et pratiques au Canada
Organismes de financement de la recherche
Les organismes de financement et les gouvernements de partout dans le monde ont reconnu la nécessité d’établir des politiques de GDR afin de soutenir l’accès aux données financées par des fonds publics. Les mandats des organismes de financement qui exigent le partage des données influencent le comportement des chercheuses et chercheurs ainsi que la demande pour une infrastructure et des services en GDR (GT GDR de l’Alliance, 2020). La Politique des trois organismes sur la GDR au Canada (2021) alimente une culture de changement pour le dépôt et le partage de données, car elle définit les exigences en vertu desquelles les chercheuses et chercheurs « sont tenus de déposer dans un dépôt numérique les données de recherche, les métadonnées et les codes qui appuient directement les conclusions de la recherche publiées dans des revues de même que les préimpressions découlant de la recherche financée par les organismes subventionnaires » (Gouvernement du Canada, 2021); la mise en oeuvre de cette mesure est à venir. Les titulaires de subventions doivent offrir un accès convenable aux données pour autant que les exigences éthiques, culturelles, juridiques et commerciales le permettent, conformément aux principes FAIR et aux normes propres à leurs disciplines. La souveraineté des données autochtones (abordée en détail au chapitre 3) reconnaît les droits inhérents des communautés autochtones de gouverner la collecte, la propriété et l’utilisation de leurs données, ce qui peut se traduire par des pratiques distinctes en ce qui a trait au partage de leurs données de recherche.
Politiques des organismes de financement
Locales et régionales
Les établissements de recherche canadiens peuvent définir leurs propres exigences pour la gestion et le partage des données en fonction de politiques internes qui régissent les pratiques de la recherche et la propriété intellectuelle. De plus, ils doivent publier une stratégie indiquant comment les pratiques de GDR seront prises en charge (Gouvernement du Canada, s.d.).
Nationales
- Politique des trois organismes sur la GDR (2021)
- Certaines demandes de subvention doivent comprendre un plan de gestion des données (mise en œuvre progressive depuis le printemps 2022).
- Les titulaires de subventions doivent verser dans un dépôt numérique les données de recherche, les métadonnées et les codes qui appuient directement les conclusions de la recherche publiées dans des revues, de même que les prépublications préimpressions découlant de la recherche financée par les organismes subventionnaires. Le dépôt doit être effectué au moment de la publication (mise en œuvre à venir).
- Bien que le partage de données ne soit pas exigé, les organismes subventionnaires s’attendent à ce que les chercheuses et chercheurs donnent un accès approprié aux données lorsque les exigences éthiques, culturelles, juridiques et commerciales le permettent et conformément aux principes FAIR ainsi qu’aux normes de leurs disciplines. Dans la mesure du possible, ces données, ces métadonnées et ces codes doivent être reliés à la publication à l’aide d’un identifiant unique pérenne (IUP).
- Déclaration de principes des trois organismes en GDR au Canada (2016)
- Les données doivent être collectées et stockées en utilisant des logiciels et des formats qui permettent leur stockage sûr ainsi que leur préservation et leur accès bien au-delà de la durée du projet.
- Politique des trois organismes sur le libre accès aux publications (2015)
- Les chercheuses et chercheurs dont les travaux sont financés par les Instituts de recherche en santé du Canada (IRSC) devraient déposer certains types de données (p. ex., bio-informatique) dans des bases de données publiques appropriées.
- Politique sur l’archivage des données de recherche (1990)
- Les données de recherche doivent être conservées et rendues disponibles dans les deux années qui suivent l’achèvement du projet (Conseil de recherche en sciences humaines, s.d.).
Internationales
Plusieurs organismes publics de financement de la recherche dans d’autres pays qui soutiennent les chercheuses et chercheurs du Canada exigent que les jeux de données qui sous-tendent leurs publications de recherche soient publiés. C’est le cas notamment des organisations suivantes :
- Organismes de financement aux É.-U., comme les National Institutes of Health (NIH) et la National Science Foundation (NSF)
- UK Research and Innovation funders
- European Commission Horizon 2020
Plusieurs sources privées de financement de la recherche ont leurs propres attentes en matière de partage de données (p. ex., Wellcome Trust, Bill & Melinda Gates Foundation).
Autres politiques et pratiques
Des maisons d’édition ont également encouragé l’adoption de pratiques en GDR. Lorsqu’une déclaration sur la disponibilité des données est exigée, il est beaucoup plus probable que les données de recherche soient partagées en ligne. Lorsque les politiques sont moins rigoureuses, comme le fait de recommander l’archivage de données, les taux d’archivage n’augmentent que légèrement comparativement au fait de ne pas disposer d’une telle politique (Vines et al., 2013). Le partage et la disponibilité des données varient selon la discipline. Par exemple, les domaines de la biologie, des sciences de la Terre, des sciences médicales et des sciences physiques présentent un taux supérieur de partage de données (Stuart et al., 2018); toutefois, les données sont moins faciles d’accès dans des documents en lien avec l’énergie et la catalyse, la psychologie, l’optique et l’optoélectronique et la foresterie (Tedersoo et al., 2021).
Au cours des 20 dernières années, le partage des données s’est amélioré (Tedersoo et al., 2021), mais les études démontrent que les résultats ne sont pas toujours entièrement reproductibles à partir des données partagées en raison d’une documentation et de métadonnées inadéquates (Rieseberg et al., 2021). Des efforts importants ont été déployés pour atténuer ce phénomène. Par exemple, le Journal of Molecular Ecology encourage les autrices et auteurs à utiliser la base de données en libre accès GEOME pour créer des liens permanents entre les données génétiques et les métadonnées géographiques et écologiques afin que les données versées respectent les principes FAIR (Rieseberg et al., 2021). La Public Library of Science (2022) a annoncé le lancement d’un projet pilote de « données accessibles » où certains articles mettront en évidence les liens vers des jeux de données dans des dépôts spécifiques dans le but d’accroître le partage et la découverte de données de recherche et de souligner l’avantage des modèles de science ouverte. L’American Journal of Political Science, en partenariat avec le Odum Institute for Research in Social Science, fournit des services de curation et de vérification de données pour faire en sorte que les jeux de données reproduisent les résultats des articles correspondants (Jacoby et al., 2017). Par conséquent, les politiques, à elles seules, ne suffisent pas; le recours à des solutions propres aux disciplines est requis pour que les données partagées soient accessibles et réutilisables.
Infrastructure, outils et services
Une gamme d’infrastructures est nécessaire pour soutenir la production, le partage et la réutilisation des données tout au long de leur cycle de vie. Ainsi, elles travaillent de concert afin que les données adhèrent aux principes FAIR au-delà de la durée du projet de recherche.
Il existe trois types de stockage de données de recherche : actif, dépôt et archive. La figure 1 définit le stockage actif au cours de la phase de recherche, le stockage dans un dépôt pour la phase d’accès et de publication et le stockage de type archive pour la phase de préservation, laquelle nécessite un traitement supplémentaire afin de soutenir l’accessibilité à long terme.
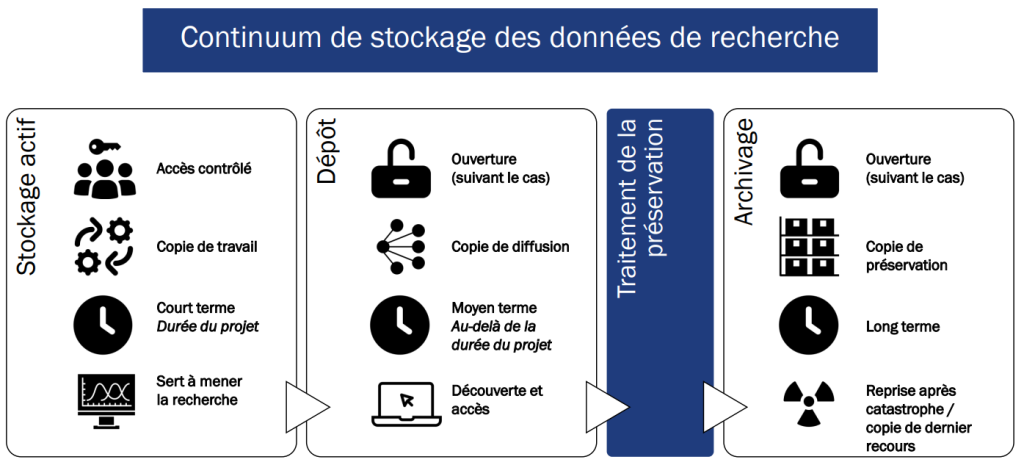
Le tableau 1 donne des détails sur le stockage actif, de type dépôt ou sous forme d’archive et donne des exemples de ce qui est utilisé au Canada. Le tableau 2 aborde les diverses infrastructures de recherche qui aident au partage, à la réutilisation et à l’accès.
| Type | Attributs | Exemples |
|
Stockage actif
|
|
|
|
Stockage de type dépôt
|
|
|
|
Stockage de type archive
|
|
|
| Type | Attributs | Exemples |
|
Dépôts multidisciplinaires
|
|
|
|
Dépôts et infrastructures disciplinaires
|
|
|
|
Outils et services de préservation
|
|
|
|
Outils et services de reproduction des données de recherche et de logiciels
|
|
|
|
Services de découverte de données
|
|
|
|
Interopérabilité et normes
|
|
|
Dépôts de données canadiens
Les dépôts de données sont essentiels à l’infrastructure de recherche au Canada. De tels outils nationaux et institutionnels sont mis sur pied pour aider les communautés de recherche à déposer, partager et préserver à long terme leurs données afin d’offrir des services de GDR ouverts, équitables et connectés. Ce faisant, nous évitons les intérêts commerciaux croissants et réduisons la dépendance aux solutions personnalisées comme des sites Web de projet de recherche qui exigent souvent une maintenance et des ressources à long terme. Grâce au financement fédéral, provincial et institutionnel, les dépôts canadiens sont mis à la disposition des chercheuses et chercheurs sans frais supplémentaires et peuvent offrir une plus longue durée de vie que le projet de recherche. Le tableau 3 donne un aperçu des types de dépôts de données au Canada dont plusieurs peuvent être découverts via les registres internationaux comme le Registry of Research Data Repositories (re3data), FAIRSharing et OpenDOAR.
| Type | Attributs | Exemples |
|
Dépôts multidisciplinaires
|
|
|
|
Dépôts disciplinaires
|
|
|
|
Dépôts gouvernementaux
|
|
|
|
Bases de connaissances
|
|
|
|
Dépôts de données universitaires
|
|
|
Services de soutien
Pour produire des jeux de données au potentiel de réutilisation élevé, les chercheuses et chercheurs doivent adopter de bonnes pratiques de curation alors que les données sont nettoyées, documentées, interreliées, stockées puis partagées. Plusieurs services sont à leur disposition pour élaborer ces pratiques de GDR (voir le tableau 4).
L’évaluation des besoins de l’infrastructure de recherche numérique réalisée en 2021 par l’Alliance de recherche numérique du Canada (l’Alliance) a découvert que les chercheuses et chercheurs ont des niveaux variables d’accès et de sensibilisation au support offert par rapport aux processus de travail de recherche au palier local, provincial et national; l’accès le plus grand se trouve au palier local (Pérez-Jvostov et al., 2021).
- Soutiens internes : le premier point de soutien pour plusieurs chercheuses et chercheurs se trouve dans leurs propres groupes de recherche. Par exemple, plusieurs ont recours à des gestionnaires de données pour soutenir les membres de l’équipe avec la gestion et la publication des données. Habituellement, les chercheuses et chercheurs découvrent et sélectionnent les outils et services sur recommandation de leurs pairs (Pérez-Jvostov et al., 2021).
- Établissements d’enseignement supérieur : ils offrent des services et un soutien formels par le biais des bureaux de la recherche, des bibliothèques universitaires et des services de calcul informatique (Pérez-Jvostov et al., 2021). L’exigence des trois organismes subventionnaires de disposer de stratégies de GDR aidera à unir le soutien à l’échelle du campus.
- Modèles de soutien partagé : ils peuvent améliorer l’efficacité, l’accès et l’équité tout en répondant aux demandes des chercheuses et chercheurs. Ils sont souvent coordonnés par un consortium régional ou national. L’étude de cas 1 illustre une communauté de pratique formant un réseau de soutien pour les gestionnaires d’un dépôt institutionnel.
- Services et soutiens par discipline : ils répondent aux besoins de communautés de recherche précises et sont souvent promus à l’échelle nationale et internationale par le biais d’organismes de recherche et de maisons d’édition. Ils sont essentiels pour l’adoption de pratiques et d’outils normalisés dans les disciplines connexes, car ils sont adaptés à des processus de travail de recherche particuliers.
| Catégorie | Services |
|
Planification de la gestion des données (PGD)
|
L’Alliance soutient l’infrastructure et supervise l’élaboration de l’Assistant PGD, un outil de gestion des données en ligne. Les bibliothèques et bureaux de la recherche universitaires collaborent pour soutenir les chercheuses et chercheurs locaux à développer des PGD conformément à la politique de GDR des trois organismes.
|
|
Découverte et accès aux données
|
Les bibliothèques universitaires soutiennent la découverte et l’accès aux données par le biais de services de référence et d’abonnement à des bases de données. Certains de ces services sont partagés entre les établissements (p. ex., Odesi, dépôt Dataverse Abacus). Des organisations nationales et provinciales permettent l’accès aux données et l’utilisation d’informations démographiques à des fins de recherche. En raison du caractère sensible de ces données, le soutien exige souvent la signature d’un accord avec le fournisseur de service (p. ex., RCCDR et centres de données StatCan, ICES, Population Data BC). L’Alliance soutient un service de découverte national, Lunaris, pour accroître l’exposition aux dépôts de données et aux jeux de données canadiens. Les travaux exploratoires appuient l’accès aux jeux de données partagés sur les infrastructures de calcul de haute performance (p. ex., jeux de données en bio-informatique).
|
|
Calcul et stockage
|
Les services de calcul informatique locaux et les TI offrent du soutien aux chercheuses et chercheurs en gestion des données pour le calcul ainsi que de l’infrastructure de stockage pour les données pendant la phase active de la recherche. L’Alliance et sa Fédération nationale de partenaires accordent une importance au fait d’accroître la prise en charge de la gestion des données pour le stockage actif. Les chercheuses et chercheurs peuvent obtenir du soutien par le biais du soutien technique national de l’Alliance.
|
|
Curation et publication des données
|
Une gamme de flux de travail et de guides ont été développés pour aider les personnes responsables de la curation des données, notamment :
Pour appuyer la publication en libre accès, certaines bibliothèques universitaires offrent un service de curation aux chercheuses et chercheurs qui déposent des données et d’autres objets de recherche dans des dépôts institutionnels ou d’autres systèmes de gestion d’actifs numériques. Borealis offre des services locaux par le biais d’un modèle de soutien distribué; l’infrastructure est hébergée de manière centralisée, mais l’aide pour la curation est offerte localement aux chercheuses et chercheurs selon les capacités et l’offre de service des établissements (consultez l’étude de cas 1 ci-dessous). L’Alliance offre du soutien à la curation aux chercheuses et chercheurs qui utilisent le DFDR, un dépôt accessible à l’échelle nationale. Elle aide également les chercheuses et chercheurs à créer et à déployer des portails de recherche sur des infrastructures de calcul informatique de pointe. D’autres dépôts agissent comme des ressources de confiance pour gérer les données de recherche et offrir des services qui soutiennent leurs plateformes (p. ex., Centre canadien des données astronomiques, Ocean Networks Canada, Polar Data Catalogue). Des maisons d’édition commerciales, notamment Springer Nature and Elsevier, offrent des services de soutien à la curation et la publication de jeux de données. D’autres disposent de partenariats avec des dépôts tiers afin d’aider les autrices et auteurs à publier des jeux de données qui soutiennent leurs publications (p. ex., le partenariat entre Wiley et Dryad).
|
|
Formation
|
Les chercheuses et chercheurs bénéficient d’une formation auprès de services élaborés au sein des communautés et des établissements dans leur discipline (Pérez-Jvostov et al., 2021). Ces services sont souvent dirigés par des pairs et des spécialistes en soutien qui agissent à titre de « responsables de l’intendance des données, » développant des activités pour promouvoir la sensibilisation, la compréhension, le perfectionnement et l’adoption d’outils de GDR, de pratiques exemplaires et de ressources. Les principaux événements au Canada comprennent :
|
|
Domaines de services émergents
|
Les services de soutien au partage et à la réutilisation des données sont mis sur pied en réaction aux besoins des chercheuses et chercheurs en matière de GDR. Les domaines de services émergents comprennent :
|
Étude de cas 1 : mettre sur pied un service et une communauté de dépôt de type Dataverse au Canada
Contexte
Le projet Dataverse est un logiciel ouvert de dépôt de données de recherche qui permet aux personnes utilisatrices de partager, de citer, d’explorer et d’analyser des données de recherche. Il est développé par l’Institute for Quantitative Social Science de l’Université Harvard avec des partenaires de partout dans le monde. Borealis, le dépôt Dataverse canadien, repose sur le logiciel Dataverse et a commencé en tant que dépôt de données de recherche régional pour l’Ontario Council of University Libraries. Au cours des 10 dernières années, il est devenu un service national, bilingue, qui compte plus de 60 établissements membres. L’infrastructure est hébergée par l’Université de Toronto; les fichiers de données sont stockés en toute sécurité sur le Ontario Library Research Cloud. Borealis offre une option de dépôt aux chercheuses et chercheurs qui ne disposent pas d’un dépôt disciplinaire et qui pourraient bénéficier d’une flexibilité dans les choix de partage des données (p. ex., d’un accès libre à restreint), d’outils d’exploration dans le navigateur ainsi que d’actions et de stockage propices à la préservation.
Analyse
Bien que Borealis soit hébergé de manière centrale, les bibliothèques et les établissements universitaires gèrent leurs collections; ils appuient ainsi leurs chercheuses et chercheurs dans le dépôt et le partage de jeux de données. Puisque la capacité locale varie selon les établissements et les régions (Goddard et al., 2018), il est essentiel de cultiver une communauté de pratique pour renforcer les capacités de chaque établissement et pour développer de façon collaborative les ressources et le matériel de formation nécessaires pour soutenir les chercheuses et chercheurs. En plus des efforts déployés pour mettre sur pied l’infrastructure technique, l’équipe de Borealis a travaillé avec le Groupe d’experts Dataverse Nord de l’Alliance sur des initiatives de développement de la communauté telles que la création de ressources bilingues, de documents de sensibilisation et de formation à l’intention des gestionnaires et des personnes utilisatrices, la tenue de rencontres communautaires mensuelles et le maintien d’une liste de diffusion pour partager librement les connaissances, l’expertise et les besoins des chercheuses et chercheurs (Goodchild et Huck, 2022).
Discussion
Pour que Borealis existe, il est essentiel de créer des espaces et du soutien pour la communauté. La rétroaction aide à définir les priorités en matière d’élaboration technique et de service; la participation de la communauté à la préparation de guides pour l’utilisation et l’administration de Borealis et d’autres projets fait en sorte que les ressources répondent aux besoins de la communauté de recherche. Le but global de la communauté (c’est-à-dire, favoriser le partage et la réutilisation des données de recherche) est en harmonie avec les efforts nationaux pour consolider l’infrastructure de recherche numérique et la communauté de GDR au Canada (GT GDR de l’Alliance, 2020).
Éléments à prendre en considération pour le partage de données
Le partage de données exige de la planification. Dès le début du projet, dans le cadre du plan de gestion des données, les chercheuses et chercheurs doivent réfléchir aux logiciels et aux outils nécessaires pour créer ou collecter, analyser et documenter les données; au stockage approprié et aux procédures de sauvegarde; à la manière dont les données seront déposées et, si possible, partagées; la manière dont les données seront gérées pour assurer la conformité aux exigences éthiques et légales.
Les différences disciplinaires, notamment l’attitude et la culture, peuvent exercer une influence sur le partage et la réutilisation des données. Certains domaines de recherche disposent de traditions à cet égard et peuvent avoir adopté des normes ainsi que des outils pour soutenir ce travail. C’est particulièrement le cas des sciences humaines où les résultats ne correspondent pas toujours aux définitions traditionnelles des données de recherche; les chercheuses et chercheurs peuvent alors penser à utiliser des approches différentes pour favoriser le partage. Des services et des outils sont souvent mis sur pied afin de répondre à des besoins particuliers à une discipline et il peut s’avérer difficile de les adopter ou de les réorienter dans d’autres disciplines ou contextes. Bien que les outils et services généraux peuvent être utiles, ils n’ont souvent pas le contexte disciplinaire nécessaire pour permettre leur réutilisation et leur adoption. Parmi les éléments disciplinaires à prendre en considération, mentionnons :
- Les formats de fichier (libre vs propriétaire, outils et logiciels standards au sein de la discipline);
- Les normes de métadonnées utilisées pour la documentation et la découverte de jeux de données;
- Le stockage de données actives, les outils de transfert de données et les dépôts de données pour soutenir les besoins disciplinaires (p. ex., données massives, données sensibles);
- Le choix de dépôt en fonction des caractéristiques et de la communauté qui va l’utiliser;
- La disponibilité de la curation des données :
- Examen de la qualité des données;
- Documentation des données aux fins de réutilisation;
- Transformation des données (p. ex., nettoyage, anonymisation, dépersonnalisation);
- Les modalités d’accès et les licences de réutilisation;
- Les outils d’exploration et de visualisation des données;
- Les avantages de partager divers types de données.
Les études de cas suivantes examinent des projets de recherche ou des considérations d’ordre disciplinaire dans les domaines des humanités numériques (étude de cas 2), des sciences de la santé (étude de cas 3) et des sciences naturelles (étude de cas 4). Elles mettent en évidence les enjeux auxquels sont confrontés les chercheuses et chercheurs et mettent de l’avant des solutions ainsi que les leçons apprises.
Étude de cas 2 : humanités numériques
Contexte
La bibliothèque de l’Université Queen’s a organisé l’exposition virtuelle de la collection Diniacopoulos (en anglais uniquement), le point culminant d’un projet de recherche qui présente des films en réalité virtuelle et des modèles 3D à l’échelle d’artéfacts archéologiques grecs et égyptiens de la collection de la faculté d’études classiques. L’exposition virtuelle a été construite sur WordPress et utilise le logiciel Object2VR pour créer une expérience interactive qui permet d’examiner et de faire tourner les objets en réalité virtuelle 3D dans le navigateur.
Analyse
L’équipe de recherche voulait partager et préserver les données du projet pour une utilisation future, car le domaine de la réalité virtuelle ne cesse d’évoluer. Les visionneuses en ligne et les systèmes de gestion de contenu exigent un entretien continu de logiciels et d’outils dont la durée de vie est inconnue, ce qui met en lumière des éléments à prendre en considération au chapitre de la durabilité et de l’accès à long terme. Parmi les défis rencontrés, mentionnons le choix du dépôt, étant donné la taille du jeu de données (60 Go), l’important nombre de fichiers (plus de 6500) et la complexité de la structure de dossiers, sans compter que ce domaine dispose de peu d’options et de pratiques exemplaires. Qui plus est, il était essentiel d’inclure la documentation et les métadonnées disciplinaires pour faire en sorte que les données puissent être réutilisées et comprises hors de leur contexte d’origine.
Discussion
L’équipe de recherche a déposé le jeu de données dans la collection Dataverse de Queen’s (Jones et al., 2017), qui fait partie de Borealis, afin de bénéficier du soutien de la bibliothèque de l’Université Queen’s et de caractéristiques comme des champs de métadonnées exhaustifs et la capacité d’attribuer un identificateur d’objets numériques (DOI) qui pourrait être lié à l’exposition virtuelle. L’équipe de Borealis a pris en charge le dépôt de gros dossiers d’archives compressés de type ZIP pour chaque artéfact. Le débat se poursuit au sujet de la compréhension des données de recherche en sciences humaines. Il faut continuer à étudier la question par le biais de statistiques d’utilisation et de citations des jeux de données pour déterminer s’il existe des défis à la réutilisation de ces données contextuelles et si des outils et des plateformes améliorés pourraient mieux gérer, partager et conserver ces types de projets en humanité numériques.
Étude de cas 3 : partage de données sensibles
Contexte
Les données sensibles font référence aux données qui peuvent causer préjudice si rendues publiques. Habituellement, il s’agit de données recueillies à propos d’êtres humains et peuvent comprendre de l’information sensible, confidentielle ou personnelle en lien, entre autres, avec la santé, l’ethnicité, les opinions politiques ou l’emplacement géographique d’une personne. Les données de recherche qui impliquent des êtres humains doivent être gérées conformément aux lignes directrices du comité d’éthique de la recherche (CÉR) et en recevoir l’approbation. Plusieurs établissements fournissent des normes de sécurité et des lignes directrices en matière de protection pour gérer les données sensibles et confidentielles.
Au Canada, la recherche financée par les trois organismes fédéraux de financement de la recherche (les organismes subventionnaires) qui implique des êtres humains est encadrée par l’Énoncé de politique des trois conseils : Éthique de la recherche avec des êtres humains (EPTC 2) (Groupe en éthique de la recherche, 2022). Les chercheuses et chercheurs doivent se conformer à la politique, laquelle aborde les enjeux de consentement, de la vie privée et de l’équité en lien avec divers types de recherche humaine, notamment les essais cliniques, la recherche génétique et celle impliquant les Premières Nations, les Inuits et les Métis. La recherche portant sur les peuples autochtones peut ne pas être sujette aux lignes directrices de l’EPTC 2, selon les circonstances et les modalités convenues ou qui régissent les données considérées sous le contrôle des personnes participantes ou des groupes communautaires (consultez le chapitre 3, « Souveraineté des données autochtones » ; consultez les principes de PCAP® pour un modèle de gestion des données au sujet des Premières Nations). La manipulation et l’utilisation de données sensibles peuvent être régies par d’autres cadres légaux et éthiques du programme de recherche (p. ex., IRSC, CRSH) ou de l’établissement, ou au palier provincial (p. ex., Loi sur l’accès à l’information et la protection de la vie privée) ou fédéral (p. ex., Loi sur la protection des renseignements personnels et les documents électroniques).
En 2021, les trois conseils ont émis des lignes directrices à l’intention des chercheuses et chercheurs intitulées Lignes directrices pour verser des données existantes dans des dépôts publics (Groupe en éthique de la recherche, s.d.). Le document indique que les chercheuses et chercheurs peuvent déposer et partager des données dans un dépôt si les personnes participantes ont consenti à cet effet ou si un CÉR a donné son approbation. Les chercheuses et chercheurs doivent être conformes à l’EPTC 2 avant le dépôt et le partage des données et obtenir l’approbation du CÉR avant de faire la collecte ou la réutilisation de la recherche qui implique des êtres humains.
Analyse
L’infrastructure et les services de soutien pour le stockage, le dépôt et le partage de données sensibles demeurent une lacune importante au Canada. La complexité entourant les données sensibles exige un croisement entre plusieurs services et unités administratives d’un établissement, notamment les lignes directrices du CÉR, les contrats et services juridiques, les pratiques en matière de GDR ainsi que l’infrastructure et les processus de travail pour gérer les données sensibles tout au long de leur cycle de vie.
Dans le cadre de la recherche en sciences de la santé, plusieurs options sont offertes pour publier ou partager des données; les éléments à prendre en considération varient. La dépersonnalisation ou l’anonymisation des jeux de données comprend la suppression de données identifiables d’un jeu de données. Toutefois, certains d’entre eux ne peuvent pas être dépersonnalisés sans compromettre l’utilité des données. Ils peuvent être partagés par des portails à accès restreint grâce à des ententes de partage/transfert de données. Cette approche présente certains inconvénients: les frais administratifs généraux et le besoin potentiel d’avoir un portail fait sur mesure.
Discussion/conclusions
Des efforts sont continuellement déployés pour améliorer les outils, l’infrastructure, les processus de travail et les ressources en ce qui a trait à la gestion et au partage de données sensibles. Des logiciels sécuritaires et faciles d’utilisation, comme Research Electronic Data Capture (REDCap), sont de plus en plus populaires en tant qu’outils pour la saisie de données en recherche clinique et pour la création de bases de données et de projets conformes aux lignes directrices légales (Patridge et Bardyn, 2018). Le projet de dépôt de données sensibles de l’Alliance a mené à la création d’un outil de cryptage à divulgation nulle de connaissance pour faciliter le dépôt sécuritaire et l’accès contrôlé aux données sensibles au sein de la plateforme DFDR. Pour la prochaine phase du projet, l’équipe de GDR de l’Alliance dirige la participation collaborative entre établissements afin d’élaborer un cadre politique ayant pour but de préciser et de simplifier le flux de travail pour le dépôt et le partage de données sensibles. Le Groupe d’experts en données sensibles de l’Alliance a publié des documents visant à encadrer les pratiques de GDR dans le contexte de l’éthique de la recherche, notamment la boîte à outils pour les données sensibles.
- Partie 1 : Glossaire terminologique sur l’utilisation des données sensibles à des fins de recherche
- Partie 2 : Matrice de risque lié aux données de recherche avec des êtres humains
- Partie 3 : Langage en matière de gestion des données de recherche pour le consentement éclairé
Les chercheuses et chercheurs ont besoin d’un leadership permanent pour trouver des solutions nationales afin de garantir un accès équitable au soutien, aux outils et à l’infrastructure pour la gestion et le partage des données sensibles.
Étude de cas 4 : soutenir les grands producteurs de données au Canada – SuperDARN et le Dépôt fédéré de données de recherche (DFDR)
Contexte
Le Super Dual Auroral Radar Network (SuperDARN) est un réseau composé de 36 radars scientifiques déployés partout dans le monde par des universités et des laboratoires gouvernementaux de 10 pays. SuperDARN Canada (dont le siège social se trouve à l’Université de la Saskatchewan) exploite cinq radars au Canada, lesquels produisent des données précieuses que les chercheuses et chercheurs peuvent utiliser pour comprendre la météorologie de l’espace, la radiocommunication et la physique dans la haute atmosphère terrestre. Toutefois, en raison des saisies de qualité supérieure et des taux de collecte rapides des radars, SuperDARN génère des données à très grande échelle; leur stockage de manière sécuritaire, consultable et accessible constitue un défi. En 2018, SuperDARN Canada a commencé à rencontrer l’équipe du DFDR.
Analyse
La taille, l’échelle et la portée des données, en plus de la complexité du cadre organisationnel de SuperDARN en tant que partenaire de recherche international, présentaient de nombreux défis. La collecte de données de SuperDARN a commencé en 1993; elles existent sous forme brute et traitée. SuperDARN Canada et le DFDR ont réfléchi au format de données qu’il conviendrait le mieux de publier (environ 80 To de données brutes ou environ 10 To de données traitées par version algorithmique) et, parmi les données traitées, quelle génération d’algorithme choisir : l’algorithme le plus ancien, largement utilisé, ou le plus récent. La création de versions des jeux de données pour mettre à jour l’algorithme obsolète signifiait doubler la taille de la collection.
Les données sont collectées au fil du temps, des régions et des instruments par des installations de radars qui fonctionnent dans les deux hémisphères. Par conséquent, les équipes devaient prendre en considération la manière de subdiviser les données en unités publiables les mieux adaptées à la découverte, à la réutilisation, au suivi de l’utilisation et à la création de rapports. Les équipes devaient également réfléchir à la taille des jeux de données et au nombre de fichiers, sans oublier les limites relatives au navigateur Web. Bien que les fichiers soient petits, les jeux de données pouvaient atteindre plusieurs téraoctets en fonction de la manière dont les données étaient organisées.
Puisque les données brutes et traitées étaient offertes uniquement sous forme de fichiers binaires, l’équipe de curation du DFDR ne pouvait pas réaliser de vérification de la qualité. La complexité des données signifiait aussi que sans documentation exhaustive, les jeux de données ne seraient utiles qu’à un nombre restreint de personnes qui participent à la recherche.
Discussion/conclusions
Format
L’équipe a décidé de publier les données sous forme brute depuis 1993.
Curation
L’équipe de curation du DFDR a collaboré avec SuperDARN Canada pour examiner les jeux de données et préparer des fichiers LISEZ-MOI qui saisissent les métadonnées descriptives et techniques pour que la communauté élargie de chercheuses et chercheurs puisse les utiliser. Des liens vers les publications et la documentation connexes ont été ajoutés et les jeux de données ont été reliés à un logiciel d’analyse et de visualisation créé par SuperDARN.
Leçons tirées
En plus des solutions abordées précédemment, ce projet a permis de tirer les leçons suivantes:
- La consultation sur les besoins en matière de publication des données peut prendre du temps et le processus est continu. Il s’est écoulé plusieurs années entre la première conversation et l’intégration des premiers jeux de données. Après la publication, le DFDR et SuperDARN Canada continuent de se rencontrer régulièrement.
- Il est important d’avoir une communication cohérente, surtout lorsque les décisions exigent des échéances plus longues. Il faut organiser des rencontres régulières, documenter les discussions et les décisions pour faire en sorte que les parties prenantes demeurent sur la même longueur d’onde et que les fils de discussion ne soient pas perdus.
- La durabilité et la planification sont essentielles. Dans le cadre de sa collaboration avec SuperDARN, le DFDR devait réfléchir aux besoins en matière de publication des données en lien avec la collecte ainsi que son engagement pour l’avenir.
L’avenir du partage de données au Canada
Plusieurs développements pourraient mieux soutenir les chercheuses et chercheurs du Canada pour tirer pleinement profit des avantages du partage de données. Quelques possibilités sont suggérées ci-après, notamment l’amélioration de l’accès et de l’inclusion, le renforcement des plateformes de recherche qui prennent en charge le cycle de vie des données, l’élaboration d’outils et de technologies pour automatiser les processus de travail de curation et l’amélioration de l’intégration et de l’interopérabilité entre les systèmes et les plateformes.
Accès et inclusion
Les obstacles systémiques à l’inclusion de l’ensemble des chercheuses et chercheurs de toutes les disciplines pour l’accès et l’utilisation des outils et des services de partage des données doivent être supprimés. Ceci permettrait de favoriser une adoption plus équitable des politiques et pratiques de partage de données. De nouvelles façons de concevoir le partage des données sont nécessaires pour transformer les infrastructures qui prennent en charge tous les types de données de recherche, à la fois en matière de formats et de normes, mais aussi en ce qui a trait aux modèles et processus de travail encore théoriques.
Au fur et à mesure que les processus de travail de partage de données évoluent, il faut veiller à créer des modèles d’édition équitables. Étant donné le coût élevé du stockage, particulièrement pour les gros jeux de données, nous devons équilibrer durabilité et équité.
Exemples
- Davantage d’options de personnalisation des dépôts de données; des outils et des normes flexibles;
- Des normes d’accessibilité Web dans les logiciels et plateformes;
- Des ententes d’accès libre entre établissements de recherche, maisons d’édition et dépôts.
Plateformes de cycle de vie de la recherche
Les processus de travail habituels pour téléverser ou télécharger des données d’un dépôt exigent le transfert de données entre les plateformes et entre les emplacements de stockage. Cette façon de procéder est inefficace et dispendieuse, voire impossible pour les gros ensembles de données en raison du coût, du temps nécessaire pour le transfert ou des limites de l’infrastructure. De plus, certains jeux de données dépendent de logiciels ou d’environnements informatiques spécialisés pour réaliser des analyses. Les plateformes de recherche et les grappes de stockage qui prennent en charge le cycle de vie complet des données, où il serait possible d’analyser les données, d’en faire la curation et où une version sûre serait partagée, sont nécessaires.
Exemples
- Des outils faciles à utiliser pour redistribuer les jeux de données entre plusieurs couches de stockage diverses (p. ex., déplacer des données depuis et vers un dépôt et un stockage actif);
- Des plateformes infonuagiques complètes permettant l’analyse, la curation et le partage de données.
Automatisation de la curation
Pour faire progresser la science ouverte, il ne suffit pas de rendre les données accessibles. Il faut temps et argent pour que les jeux de données soient conformes aux principes FAIR. Les nouveaux outils et les nouvelles technologies pourraient réduire cet investissement et soutenir les chercheuses, les chercheurs ainsi que les personnes responsables de la curation à produire des résultats de recherche de qualité supérieure.
Exemples
- Des algorithmes d’intelligence artificielle qui génèrent des métadonnées de qualité supérieure à partir des données;
- Des logiciels pour le couplage automatisé de données, à l’intérieur des jeux de données et entre eux;
- Des logiciels qui guident les chercheuses et chercheurs dans la documentation de leurs jeux de données, avec des normes et des taxonomies intégrées;
- Des logiciels qui vérifient la reproductibilité et la qualité des jeux de données.
Intégration et interopérabilité
Comme l’illustre la gamme de politiques, d’outils et de services qui soutiennent le partage des données de recherche, l’impulsion est grande pour faire progresser ces infrastructures. Toutefois, plusieurs sont offerts et développés en silos, reliés par trop peu d’éléments de logiciel médiateur ou de politiques-cadres. Alors que ces infrastructures sont mises sur pied, l’interopérabilité (p. ex., relier la politique à la plateforme, la plateforme au service, le service à la politique) et l’intégration aux processus de travail de recherche et d’édition se trouveront au cœur des activités visant à améliorer la facilité d’utilisation et l’adoption accrue de pratique de partage de données.
Exemples
- Des cadres politiques pour le partage de données au-delà des limites des juridictions;
- L’intégration des plans de gestion des données à l’infrastructure de recherche et de partage;
- La connexion des jeux de données dans un réseau plus vaste de résultats de recherche.
Conclusion
L’infrastructure, les outils et services canadiens qui soutiennent le partage de données de recherche sont importants, surtout à la lumière des politiques qui exigent un accès aux données financées par des fonds publics. Le domaine d’étude d’une chercheuse ou d’un chercheur et les préoccupations éthiques ont un impact sur la manière dont les données sont partagées et influencent l’élaboration de politiques et d’infrastructures qui pourraient faire progresser le partage de données au Canada.
Questions de réflexion
- Quels sont les défis en matière de partage de données de recherche?
- Quels sont les types de stockage de données? Donnez un exemple pour chacun d’eux.
- Que faut-il prendre en considération en matière de partage des données? Quel rôle jouent les différences relatives à la discipline à cet égard?
- Quels types de services de données (local, spécifique à un domaine ou national) pourraient être mis sur pied pour aborder les défis et obstacles mentionnés dans ce chapitre?
Éléments clés à retenir
- Les organismes de financement et les maisons d’édition peuvent définir des exigences qui favorisent le partage de données de recherche; toutefois, les politiques à elles seules ne suffisent pas à créer des résultats reproductibles. Des solutions techniques et particulières à la discipline sont nécessaires pour rendre les données accessibles et réutilisables.
- Les options de stockage, les infrastructures et les dépôts de données au Canada soutiennent la production, le partage et la réutilisation des données de recherche tout au long de leur cycle de vie. Le stockage de données de recherche peut être divisé en trois types : actif, de dépôt et archivistique. Les établissements de recherche canadiens offrent souvent des infrastructures de stockage à leurs chercheuses et chercheurs, bien que la disponibilité varie selon la capacité de l’établissement.
- Des services de soutien existent pour les chercheuses et chercheurs du Canada qui élaborent des pratiques de GDR, qui publient des données ou qui planifient la réutilisation de données, y compris des services provenant de leurs propres groupes de recherche ou établissements d’enseignement supérieur et des services uniques pour répondre aux besoins de communautés de recherche en particulier.
- Les chercheuses et chercheurs devraient prendre en considération les différences disciplinaires et le contexte relatif au partage des données. Traditionnellement, certains domaines sont ouverts au partage et à la réutilisation des données. Si certaines disciplines ont adopté des normes et des outils pour soutenir ce travail, d’autres peuvent en avoir besoin pour aborder des sujets comme les métadonnées, la taille des fichiers, le type de fichier et les exigences relatives aux données sensibles.
- Le partage et la réutilisation des données sont soutenus par l’intégration et l’interopérabilité des systèmes et des plateformes, notamment celles qui prennent en charge le cycle de vie et les technologies qui facilitent les processus de travail liés à la curation des données.
Lectures et ressources supplémentaires
Barsky, E., Laliberté L. W., Leahey, A. et Trimble, L. (2017). Chapter 3. Collaborative Research Data Curation Services: A View from Canada. Dans L. R. Johnston (dir.), Curating research data, volume one: Practical strategies for your digital repository (p. 79-101). Association of College and Research Libraries. https://dx.doi.org/10.14288/1.0340778
Cheung, M., Cooper, A., Dearborn, D., Hill, E., Johnson, E., Mitchell, M. et Thompson, K. (2022). Practices before policy: Research data management behaviours in Canada. Partnership: The Canadian Journal of Library and Information Practice and Research, 17(1), 1–80. https://doi.org/10.21083/partnership.v17i1.6779
First Nations Information Governance Centre. (2014, 23 mai). Ownership, control, access and possession (OCAP™): The path to First Nations information governance. https://achh.ca/wp-content/uploads/2018/07/OCAP_FNIGC.pdf
Garnett, A., Leahey, A., Savard, D., Towell. B. et Wilson, L. (2017). Open metadata for research data discovery in Canada. Journal of Library Metadata, 17(3-4), 201-217. https://doi.org/10.1080/19386389.2018.1443698
Thompson, K. et Kellam, L. M. (2016). Introduction to databrarianship: The academic data librarian in theory and practice. Dans L. M. Kellam et K. Thompson (dir.), Databrarianship: The academic data librarian in theory and practice. Association of College and Research Libraries. https://scholar.uwindsor.ca/cgi/viewcontent.cgi?article=1047&context=leddylibrarypub
Rice, R. et Southall, J. (2016). The data librarian’s handbook. Facet Publishing.
Bibliographie
Baker, D., Bourne-Tyson, D., Gerlitz, L., Haigh, S., Khair, S., Leggott, M., Moon, J., Ridsdale, C., Tourangeau, R. et Whitehead, M. (2019). Research data management in Canada: A backgrounder. Zenodo. https://doi.org/10.5281/zenodo.3574685
Conseil de recherche en sciences humaines. (s.d.). Politique sur l’archivage des données de recherche. Gouvernement du Canada. https://www.sshrc-crsh.gc.ca/about-au_sujet/policies-politiques/statements-enonces/edata-donnees_electroniques-fra.aspx
Corcho, O., Eriksson, M., Kurowski, K, Ojsteršek, M., Choirat, C. van de Sanden, M. et Coppens, F. (2021). EOSC interoperability framework: Report from the EOSC executive board working groups FAIR and architecture. Publications Office of the European Union. https://data.europa.eu/doi/10.2777/620649
Goddard, L., Barsky, E., Cooper, A., Darnell, A., Davis, C., Doiron, J. et Taylor, S. (2018). Dataverse north working group: Year 1 recommendations. UBC Faculty Research and Publications. https://doi.org/10.14288/1.0386773
Goodchild, M. et Huck, J. (2022, 29 mars). Building a shared open research data repository community in Canada. Open Science Framework. https://osf.io/b9vyt
Gouvernement du Canada. (2021). Politique des trois organismes sur la gestion des données de recherche. https://science.gc.ca/site/science/fr/financement-interorganismes-recherche/politiques-lignes-directrices/gestion-donnees-recherche/politique-trois-organismes-gestion-donnees-recherche
Gouvernement du Canada. (s.d.). Stratégies institutionnelles de gestion des données de recherche publiées. https://science.gc.ca/site/science/fr/financement-interorganismes-recherche/politiques-lignes-directrices/gestion-donnees-recherche/strategies-institutionnelles-gestion-donnees-recherche-publiees
Groupe de travail sur la gestion des données de recherche de l’Alliance. (2020). État actuel de la gestion des données de recherche au Canada. Zenodo. https://zenodo.org/record/6647045
Groupe en éthique de la recherche. (s.d.). Lignes Directrices pour verser des données existantes dans des dépôts publics. Gouvernement du Canada. https://ethics.gc.ca/fra/depositing_depots.html
Groupe en éthique de la recherche. (2022). Énoncé de politique des trois conseils : Éthique de la recherche avec des êtres humains – EPTC 2 (2022). Gouvernement du Canada. https://ethics.gc.ca/fra/policy-politique_tcps2-eptc2_2022.html
Jacoby, W. G., Lafferty-Hess, S. et Christian, T-M. (2017). Should journals be responsible for reproducibility? Inside Higher Ed Blog. https://www.insidehighered.com/blogs/rethinking-research/should-journals-be-responsible-reproducibility
Jones, K., Bevan, G. et Monette, M. (2017). The Diniacopoulos ceramics display, Department of Classics – 2016 [Jeu de données].Borealis. https://doi.org/10.5683/SP/T7ZJAF
Lin, D., Crabtree, J., Dillo, I., Downs, R. R., Edmunds, R., Giaretta, D., De Giusti, M., L’Hours, H., Hugo, W., Jenkyns, R., Khodiyar, V., Martone, M. E., Mokrane, M., Navale, V., Petters, J., Sierman, B., Sokolova, D. V., Stockhause, M. et Westbrook, J. (2020) The TRUST Principles for digital repositories. Sci Data, 7, 144. https://doi.org/10.1038/s41597-020-0486-7
Patridge, E. F. et Bardyn, T. P. (2018). Research electronic data capture (REDCap). JMLA, 106(1), 142–144. https://doi.org/10.5195/jmla.2018.319
Pérez-Jvostov, F., Iron, K., Khair, S., Sahrakorpi, S. et Zhang, Q. (2021). Évaluation des besoins de la communauté de recherche: résumé des commentaires reçus. Alliance de recherche numérique du Canada. https://alliancecan.ca/sites/default/files/2022-04/EvaluationBesoins_Alliance_20220126.pdf
Public Library of Science. (2022, 29 mars). PLOS launches new feature to promote data sharing and access. The Official PLOS Blog. https://theplosblog.plos.org/2022/03/plos-launches-new-feature-to-promote-data-sharing-and-access/
Rieseberg, L., Warschefsky, E., O’Boyle, B., Taberlet, P., Ortiz-Barrientos, D., Kane, N. C. et Sibbett, B. (2021). Editorial 2021. Molecular Ecology, 30(1), 1-25. https://doi.org/10.1111/mec.15759
Stuart, D., Baynes, G., Hrynaszkiewicz, I., Allin, K., Penny, D., Lucraft, M. et Astell, M. (2018). Whitepaper: Practical challenges for researchers in data sharing. Figshare. https://doi.org/10.6084/m9.figshare.5975011
Tedersoo, L., Küngas, R., Oras, E., Köster, K., Eenmaa, H., Leijen, Ä., Pedaste, M., Raju, M., Astapova, A., Lukner, H., Kogermann, K. et Sepp, T. (2021). Data sharing practices and data availability upon request differ across scientific disciplines. Scientific data, 8, 192. https://doi.org/10.1038/s41597-021-00981-0
Vines, T. H., Andrew, R. L., Bock, D. G., Franklin, M. T., Gilbert, K. J., Kane, N. C., Moore, J-S., Moyers, B. T., Renaut, S., Rennison, D. J., Veen, T. et Yeaman, S. (2013), Mandated data archiving greatly improves access to research data. The FASEB Journal, 27(4), 1304-1308. https://doi.org/10.1096/fj.12-218164
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J-W., da Silva Santos, L. B., Bourne, P. E., Bouwman, J., Brookes, A. J., Clark, T., Crosas, M., Dillo, I., Dumon, O., Edmunds, S., Evelo, C. T., Finkers, R., Gonzalez-Beltran, A., … Mons, B. (2016). The FAIR guiding principles for scientific data management and stewardship. Scientific data, 3, 160018. https://doi.org/10.1038/sdata.2016.18
Capacité des données ou des outils provenant de ressources non coopératives à travailler ou à communiquer entre eux avec un minimum d'effort et en utilisant un langage commun. L'interopérabilité exige que les données et les métadonnées utilisent des formats normalisés, accessibles et largement utilisés. Par exemple, lors de la sauvegarde de données tabulaires, il est recommandé d'utiliser un fichier CSV plutôt qu'un fichier propriétaire tel que XLSX (Excel). Un fichier CSV peut être ouvert et lu par davantage de logiciels qu'un fichier XLSX.
FAIR est un acronyme qui signifie facile à trouver, accessible, interopérable et réutilisable. Les principes directeurs FAIR ont été élaborés en 2014 et visent à améliorer la réutilisation des données, tant par les machines que par les personnes.
Terme qui décrit toutes les activités que les chercheuses et chercheurs effectuent pour structurer, organiser et préserver les données de recherche avant, pendant et après le processus de recherche.
Cycle au cours duquel les données sont recueillies, traitées, analysées, préservées et ensuite partagées avec d’autres chercheuses et chercheurs qui pourront recommencer le cycle.
Version préliminaire d’un article qui n’a pas encore passé le processus d’examen par les pairs, mais qui peut être partagé à des fins de rétroaction. Les prépublications (ou préimpressions) peuvent être considérées comme de la littérature grise.
Description formelle de tout le processus de la chercheuse ou du chercheur, de la collecte des données à leur analyse puis comment elles seront traitées à la fin du projet.
Sources d'informations ou de preuves qui ont été compilées pour servir de base à la recherche.
Éléments d’information utilisés pour décrire le contenu ou le contenant d’une ressource. Elles peuvent être structurées ou non.
Référence durable à un objet numérique qui fournit des informations sur cet objet indépendamment de ce qui lui arrive. Développé pour lutter contre des liens qui deviennent obsolètes (link rot), un identifiant pérenne peut être résolu pour fournir une représentation appropriée d'un objet, que celui-ci change d'emplacement en ligne ou qu'il soit mis hors ligne [traduction]. (CODATA Research Data Management Terminology, s.d.).
Disponibilité libre et immédiate d’informations sans limites d’utilisation dans l’environnement numérique.
Niveau de stockage qui prend en charge les données à l’étape active du projet de recherche, pendant que les données sont créées, modifiées et consultées fréquemment.
Niveau de stockage qui prend en charge le versement, le stockage, la découverte et l’accès approprié de copies sûres de documents numériques dans divers formats.
Niveau de stockage qui prend en charge une série d’activités gérées nécessaires pour soutenir la préservation à long terme des documents numériques.
Lors de l'ingestion des fichiers dans un système de préservation, processus qui consiste à convertir une copie des fichiers originaux dans un format non propriétaire, largement utilisé et respectueux de la préservation. La normalisation standardise les formats des objets numériques ingérés et permet aux archives d'éviter de gérer un grand nombre de formats. Cependant, la normalisation peut également modifier la taille et les propriétés des fichiers. [traduction]. (Scholars Portal, s.d.).
Méthode permettant de garantir l'intégrité d'un fichier et de vérifier qu'il n'a pas été altéré ou corrompu. Pendant les transferts de fichiers, une archive peut effectuer un contrôle d'intégrité pour s'assurer qu'un fichier transmis n'a pas été altéré en cours de route. Au sein de l'archive, le contrôle d’intégrité est utilisé pour s'assurer que les fichiers numériques n'ont pas été altérés ou corrompus. Il est le plus souvent réalisé en calculant des sommes de contrôles telles que MD5, SHA1 ou SHA256 pour un fichier et en les comparant à une valeur stockée. (Manuel de préservation numérique, s.d.).
Traitement qui consiste à regrouper des données et des informations sur les données dans un ensemble logique qui sera utilisé dans un processus de préservation numérique.
Bien que son rôle puisse varier, la personne responsable de l'intendance des données dans un contexte de recherche est chargée de veiller à ce que les données soient traitées de manière systématique et uniforme.
Série d'activités gérées nécessaires pour garantir un accès continu aux objets numériques aussi longtemps que nécessaire.
Domaine de recherche qui s'intéresse à l'application d'outils et de méthodes informatiques aux disciplines traditionnelles des sciences humaines telles que la littérature, l'histoire et la philosophie.
Nom pour une entité dans un réseau numérique; il ne s’agit pas d’une localisation. Le nom fournit un système pour l’identification pérenne et exploitable ainsi que pour l’échange interopérable d’informations gérées sur des réseaux numériques. Un DOI est un type d’identifiant pérenne émis par la Fondation internationale DOI. Cet identifiant permanent est associé à un objet numérique, ce qui permet à l’objet d’être fidèlement cité en référence, et ce, même si sa localisation et ses métadonnées sont modifiées au fil du temps [traduction]. (CODATA Research Data Management Terminology, s.d.).
Le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG), le Conseil de recherches en sciences humaines du Canada (CRSH) et les Instituts de recherche en santé du Canada (IRSC) (les organismes subventionnaires) représentent les trois agences fédérales de financement de la recherche au Canada. Ils sont à la source d’une importante proportion des fonds de recherche au Canada.
Cadre principal harmonisé qui guide l’établissement des lois canadiennes et des paradigmes éthiques plus larges en lien avec le droit des êtres humains en recherche.
Permet de garder une trace des modifications apportées à un fichier, aussi petites soient-elles. Également connue sous le nom de contrôle de version, cette opération s'effectue généralement à l'aide d'un système de contrôle de version automatisé tel que GitHub. De nombreux services de stockage de fichiers tels que Dropbox, OneDrive et Google Drive, conservent des versions historiques d'un fichier chaque fois qu'il est enregistré. Il est possible d'accéder à ces versions en consultant l'historique du fichier.
Document qui fournit des renseignements à propos d’un fichier ou d’un jeu de données. Il permet d’assurer la pérennité de l’interprétation correcte des données par toutes les personnes qui les consulteront.
Processus consistant à relier des systèmes ou des outils différents, souvent disparates, en une infrastructure cohérente.
