Solutionnaire
Chapitre 7, Le nettoyage de données dans le processus de gestion des données de recherche

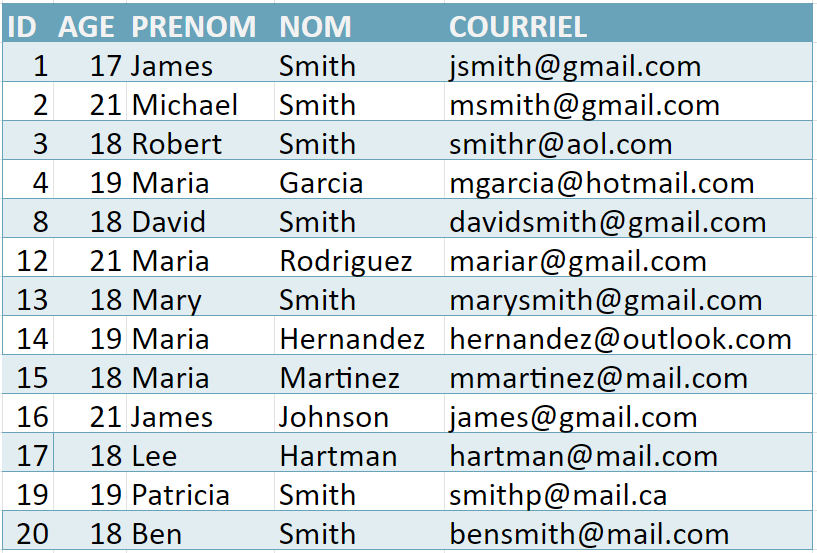
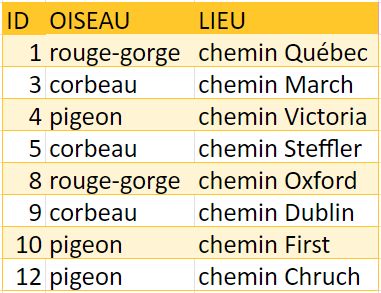
Chapitre 8, Nouvelles aventures en nettoyage des données
Réponse à la question 1 :
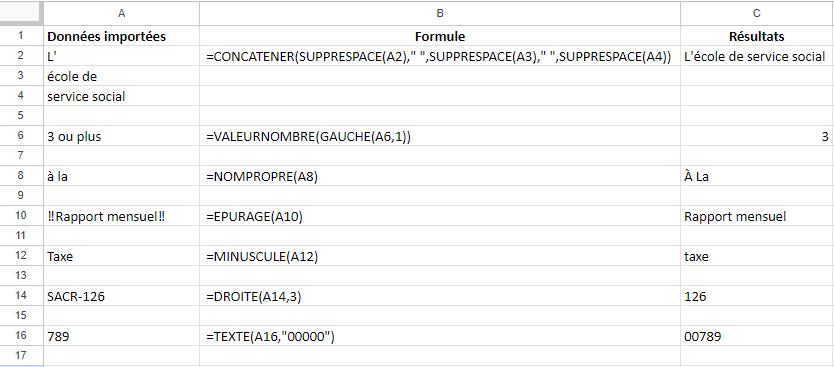
Réponse à la question 2 :
Selon la boîte à moustache, il existe une valeur aberrante. Nous remplaçons cette valeur par « NA ». Nous calculons ensuite la moyenne en éliminant tous les « NA ».
> boxplot(mydata_csv$Largeur)
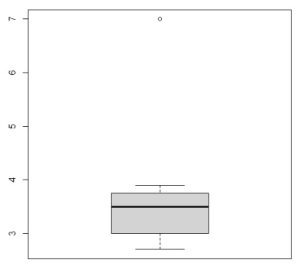
> summary(mydata_csv$Largeur)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
2.700 3.000 3.500 3.814 3.750 7.000 1
> mydata_csv$Largeur[mydata_csv$Largeur==7] = NA
> mean(mydata_csv$Largeur, na.rm = T)
[1] 3.283333
Chapitre 13, Les données sensibles: des considérations pratiques et théoriques
Réponse à la question 1 :
Énoncé de politique des trois conseils : Éthique de la recherche avec des êtres humains – EPTC 2
Réponse à la question 2 :
Les identifiants directs sont les suivants:
- nom entier ou partiel ou initiales;
- dates précises d’événements personnels tels que la naissance, la graduation, l’admission à l’hôpital (seul le mois ou l’année peut être acceptable);
- adresse complète ou partielle (de grandes zones géographiques, telles que des villes, appartiennent à la catégorie d’identifiants indirects et doivent être révisées);
- code postal complet ou partiel (les trois premiers chiffres peuvent être acceptables);
- numéros de téléphone ou de télécopieur;
- adresse courriel;
- identifiants ou noms d’utilisateurs Web ou de médias sociaux tels que le pseudonyme Twitter;
- numéros de protocole Internet ou IP; renseignements précis relatifs au navigateur Web ou au système d’exploitation (ces informations peuvent être recueillies par certains types d’outils de sondage ou de formulaires Web);
- identifiants de véhicule tels que la plaque d’immatriculation;
- identifiants liés à des dispositifs médicaux ou autres;
- tout autre numéro d’identification unique lié directement ou indirectement à un individu tel que le numéro d’assurance sociale, numéro d’étudiant ou numéro d’identification d’un animal de compagnie;
- photos d’individus ou de leur domicile ou emplacement; des enregistrements vidéos les montrant; des images médicales;
- enregistrements audio de personnes (Han et al., 2020);
- données biométriques;
- tout attribut personnel unique ou reconnaissable (p. ex., maire de Kapuskasing ou gagnant du prix Nobel).
Les quasi-identifiants peuvent comprendre l’un des éléments suivants :
- âge (peut être un identifiant direct dans le cas de personnes très âgées);
- identité de genre;
- revenu;
- emploi ou secteur d’activité;
- variables géographiques;
- variables ethniques ou d’immigration;
- appartenances à des organismes ou utilisation de services particuliers.
Il existe de nombreux autres exemples !
Réponse à la question 3 :
La combinaison de la latitude et de la longitude ou les informations sur la proximité du site industriel le plus proche sont des variables de localisation qui peuvent indiquer avec précision où se trouve une espèce menacée et peuvent être considérées comme des données sensibles.
Chapitre 14, La gestion des données de recherche qualitatives
Réponse à la question 1 :
- Peuvent mener à la réidentification des personnes participantes;
- Difficiles à dépersonnaliser; plus souvent sous forme textuelle ou audio;
- Recueillies par des êtres humains;
- Dépendent du contexte;
- Souvent recueillies auprès de communautés marginalisées ou d’individus vulnérables;
- Souvent issues de questions de recherche hautement sensibles;
- Sont moins souvent archivées, partagées ou réutilisées.
Réponse à la question 2 :
- Histoires orales;
- Journaux personnels de participantes ou participants;
- Photos;
- Vidéos;
- Documents;
- Artéfacts;
- Réponses ouvertes aux questions de sondage.
Réponse à la question 3 :
Faire le suivi des activités et de la prise de décisions pendant toute la durée du projet, précisant ce qui s’est passé, à quel moment et pourquoi.
Réponse à la question 4 :
- Capture;
- Traitement;
- Sécurité et sauvegarde des données;
- Transfert pour la transcription;
- Transfert vers d’autres membres de l’équipe;
- Traduction.
Réponse à la question 5 :
- Enregistrement original;
- Transcription originale;
- Transcription vérifiée;
- Transcription anonymisée;
- Transcription modifiée;
- Transcription codée.
Réponse à la question 6 :
La coproduction vise à réunir les compétences complémentaires des chercheuses et chercheurs en recherche qualitative et des bibliothécaires/archivistes/spécialistes des données afin d’établir et de mettre de l’avant des normes de gestion de données qualitatives.
Chapitre 17, Gestion des données de recherche et mouvement de la science ouverte : positions et enjeux
Réponse à la question 1 :
Tout d’abord, les deux définitions caractérisent toutes deux la science ouverte par l’importance de la collaboration dans la conduite de la recherche. La libre mise à disposition des résultats de la recherche est aussi une caractéristique commune bien que la définition de Foster Open Science mette beaucoup plus l’accent sur le libre accès traditionnel et est en ce sens plus réductrice. La définition de Vicente-Saez et Martinez-Fuente parle davantage d’accès et de partage que de libre accès comme tel, le partage pouvant être soumis à des restrictions légales ou éthique. Cette définition est donc davantage formellement circonscrite par les principes FAIR que celle de Foster Open Science. Les principes de transparence sont également moins développés dans la définition de Foster Open Science. On y mentionne seulement des conditions favorisant la réutilisation sans être explicites sur ces conditions et on ne fait aucune allusion à l’assurance qualité et l’audit qui sont facilités par des principes de transparence.
Réponse à la question 2 :
La réponse peut varier selon les point de vue et les expertises qui ouvriraient sur de nombreux exemples non listés dans ce chapitre. Par contre, l’école pragmatique façonne plus d’un domaine de la science ouverte (tableau 1.2) : ouverture des protocoles de recherche, réseaux sociaux académiques et autres plateformes de collaboration, comme les cahiers de laboratoires ouvert, et finalement ouverture du processus de révision par les pairs.
Réponse à la question 3 :
Faux. Les éditeurs commerciaux ont consolidé leur place en rendant dominant le modèle d’affaires du libre accès basé sur les frais de traitement d’articles et on ne peut pas exclure que l’acquisition d’infrastructure en lien avec les données de la recherche ne soit pas dans leur ligne de mire. Elsevier offre déjà son répertoire de données, Mendeley Data. Le blogue Scholarly Kitchen aborde assez régulièrement les acquisitions et fusions dans le domaine de l’édition dans le domaine de la santé. Consultez cet exemple : Elsevier to Acquire Interfolio.
Réponse à la question 4 :
Parce que les données de recherche produites sont souvent dépendantes de leur contexte de production. Il devient alors problématique de penser la reproductibilité au regard de contextes qui sont souvent uniques. La reproductibilité de la recherche qualitative doit donc être envisagée à la lumière de diverses postures épistémologiques appelant elles-mêmes leurs propres méthodologies et balises d’analyse.
Réponse à la question 5 :
Le domaine des Critical Data Studies.
