Types de données de recherche
13 Les données sensibles: des considérations pratiques et théoriques
Dr. Alisa Beth Rod et Kristi Thompson
Objectifs d’apprentissage
À la fin de ce chapitre, vous pourrez :
- Définir les termes suivants: dépersonnalisation, renseignements identificatoires, données sensibles, évaluation statistique des risques de divulgation.
- Reconnaître que l’établissement de niveaux de risque pour des données sensibles (p. ex., faible, moyen, élevé, très élevé) dépend du contexte de recherche.
- Comprendre les politiques et les règlements canadiens en matière d’éthique relatifs aux données de recherche.
Évaluation préliminaire
Introduction
Que sont les données sensibles? La Boîte à outils pour les données sensibles – destinée aux chercheurs (Groupe d’experts sur les données sensibles du réseau Portage, 2020a) définit les données sensibles comme des « informations qui doivent être protégées contre l’accès non autorisé ou la divulgation » et donne plusieurs exemples. Toutefois, cette définition des données sensibles soulève la question suivante : pourquoi ces informations doivent-elles être protégées? L’examen des exemples peut nous aider à y voir plus clair, car ils incluent des éléments tels que des renseignements personnels sur la santé et d’autres types de renseignements d’ordre confidentiel, certains renseignements géographiques (p. ex., des localisations d’espèces en péril) ou des données protégées en vertu de politiques institutionnelles. La caractéristique commune à tous ces exemples est la notion du risque, celui associé aux personnes dont la confidentialité est compromise, aux espèces en péril qui seraient perturbées ou chassées, aux politiques qui seraient enfreintes. Autrement dit, les données sensibles s’appliquent aux données qui ne peuvent être partagées sans risquer de trahir la confiance ou de nuire à une personne, une entité ou une communauté.
Dans ce chapitre, nous discuterons du travail avec les données sensibles dans le cadre des politiques fédérales et provinciales canadiennes. (Les données autochtones ont des implications en matière d’éthique et de propriété et elles sont abordées dans un autre chapitre.) Nous terminerons en donnant un aperçu des options pour la préservation sécuritaire, le partage et l’archivage approprié des données sensibles.
Les données de la recherche avec des êtres humains
Au Canada, tant au fédéral, au provincial que dans les institutions, une variété de cadres juridiques, stratégiques et réglementaires régissent les données sensibles qui impliquent des êtres humains. Dans la plupart des cas, ces exigences réglementaires ont été conçues pour assurer la confidentialité et un degré élevé de protection de la vie privée. Ainsi, le cadre réglementaire associé aux données sensibles relève de la catégorie des données impliquant des êtres humains.
Les politiques sur la vie privée au Canada
Ce n’est pas toujours facile de savoir laquelle des lois sur la protection de la vie privée s’applique à chacune des situations. Les principaux règlements sur la protection de la vie privée en lien avec les données de recherche se retrouvent généralement au niveau des juridictions provinciales et territoriales puisque les universités ne relèvent pas du champ d’application des deux principales lois fédérales sur la protection de la vie privée (Commissariat à la protection de la vie privée au Canada, s.d.). Toutefois, certaines informations sensibles, comme les dossiers médicaux, peuvent être recueillies par des chercheuses et chercheurs universitaires en partenariat avec des organismes privés et publics; celles-ci relèvent alors de la juridiction fédérale de la Loi sur la protection des renseignements personnels, qui s’applique aux organismes gouvernementaux, ou de la Loi sur la protection des renseignements personnels et les documents électroniques (LPRPDE), qui s’applique aux entités commerciales du secteur privé. Le gouvernement canadien a développé un outil pratique pour aider à déterminer laquelle des législations s’applique aux différents scénarios impliquant des informations sensibles.
Au niveau national, l’énoncé de politique des trois organismes subventionnaires sur la conduite éthique de la recherche avec des êtres humains (Énoncé de politique des trois conseils : Éthique de la recherche avec des êtres humains – EPTC 2) établit les paramètres liés à la vie privée, la justice, le respect et la préoccupation pour le bien-être des participantes et des participants. L’EPTC 2 supervise aussi la gouvernance des comités d’éthique de la recherche (CÉR), qui sont responsables d’évaluer les projets de recherche qui dépendent d’êtres humains. Contrairement aux États-Unis, où une loi fédérale régit les renseignements médicaux (HIPPA), la gestion des dossiers médicaux ou des données cliniques au Canada est régie au niveau provincial et territorial. Toutes les provinces et tous les territoires disposent d’au moins une loi sur la protection de la vie privée qui s’applique à la recherche.
Traditionnellement, les systèmes judiciaires au Canada et ailleurs en Occident garantissent le droit des individus (et par extension, des sociétés) à la vie privée, à la propriété de leurs renseignements et à la protection contre les préjudices directs en contexte de recherche. Toutefois, les données ont le potentiel de nuire à certains groupes ou certaines communautés – par exemple, pour stigmatiser des groupes racisés ou des minorités sexuelles et de genre (voir Ross et al., 2018.) De tels préjudices sont trop peu abordés dans les politiques et législations canadiennes actuelles. Les principes de propriété, contrôle, accès et possession (PCAP®) constituent un modèle alternatif. Il s’agit d’un protocole de recherche établi pour protéger les intérêts des Premières Nations piloté par le Centre de gouvernance de l’information des Premières Nations. Ces principes « s’appliquent aux Premières Nations spécifiquement, et non à tous les Autochtones » (Centre de gouvernance de l’information des Premières Nations, s.d.) et leur utilisation n’est pas destinée à d’autres contextes. Même si ces principes cherchent d’abord à privilégier les intérêts d’une communauté, ils peuvent aussi s’appliquer de façon plus générale à des recherches auprès de communautés marginalisées. Pour en savoir plus sur les modèles autochtones de recherche éthique, consultez le chapitre « Souveraineté des données autochtones. »
De nombreuses provinces mettent à jour leurs lois sur la protection de la vie privée, ce qui aura un impact sur la gestion des données de recherche impliquant des êtres humains. Par exemple, la loi 25 (aussi appelée Loi modernisant des dispositions législatives en matière de protection des renseignements personnels) a été adoptée au Québec pour solidifier les exigences en matière de consentement, de surveillance et de conformité. La loi 25 s’inspire du Règlement général sur la protection des données (RGPD) de l’Union européenne, largement considéré comme étant la plus complète des législations sur la protection de la vie privée au monde. Les impacts potentiels de la loi 25 comprennent l’obligation du consentement pour chacune des utilisations secondaires des données de recherche, l’introduction du droit à l’effacement ou du « droit à l’oubli » (Wolford, 2018) et l’obligation de faire une évaluation formelle des impacts sur la vie privée avant tout transfert de données d’une personne à l’extérieur du Québec (Commissariat à la protection de la vie privée du Canada, 2020). Nous aborderons le consentement plus en détail dans la section intitulée « Le langage du consentement et l’EPTC 2 ». Cette modification légale s’explique par le fait que les chercheuses et chercheurs pouvaient demander un consentement général pour l’utilisation des renseignements des personnes participantes (p. ex., l’échantillon d’un patient participant à un essai clinique pouvait être utilisé pour d’autres études sans avoir à fournir de détails sur ces études particulières). Maintenant, la loi 25 ne permet plus de consentement général pour les études. Elle exige que les responsables des recherches obtiennent le consentement à chaque fois que l’échantillon est utilisé à de nouvelles fins. Bien que la loi 25 soit propre au Québec, elle représente un modèle en matière de réforme de loi sur la protection de la vie privée et pourrait donc avoir d’importantes conséquences pour les données de recherche impliquant des êtres humains.
Risques et préjudices
La divulgation de renseignements personnels est un risque qui peut survenir lorsqu’il est possible d’isoler des individus dans un jeu de données et d’associer leurs renseignements à des sources externes, ce qui, avec un effort raisonnable, permet d’identifier les personnes. L’ampleur des préjudices causés à des participantes et participants de recherche dépend de la population et du sujet des données. Généralement, les risques plus élevés sont faciles à identifier et à définir (p. ex., si des renseignements sur la santé d’un individu étaient rendus publics). Les enfants sont considérés comme une population vulnérable puisqu’ils ne peuvent donner eux-mêmes leur consentement. Les recherches impliquant des enfants représentent donc un niveau élevé de risque puisque la divulgation de leurs renseignements peut causer de graves préjudices. Des sujets jugés tabous par la société peuvent aussi comporter des risques de préjudices importants pour les gens qui participent à des recherches. Ce qui constitue un sujet tabou peut varier d’une culture ou d’une situation à l’autre. Les éléments suivants peuvent néanmoins être considérés comme extrêmement sensibles, ce qui augmente le risque de préjudices potentiel qu’une participante ou un participant de recherche pourrait subir si ses renseignements sont divulgués :
- usage de drogues ou d’alcool (y compris la cigarette);
- pratiques sexuelles / MTS;
- questions familiales privées;
- violence conjugale / familiale;
- perte ou décès dans la famille;
- statut de victime;
- comportements criminels / délinquants;
- questions et problèmes de santé physique / mentale.
Les populations vulnérables, telles que les communautés suivantes, sont plus susceptibles d’être affectées par une divulgation de renseignements, et ce indépendamment du sujet de recherche :
- les communautés autochtones;
- les communautés racisées;
- les groupes à faibles revenus;
- les enfants/adolescents;
- les opprimés politiques.
Les recherches impliquant des êtres humains issus de populations vulnérables et/ou abordant des sujets sensibles peuvent nécessiter l’ajout de mesures de protection supplémentaires en matière de stockage et de sécurité des données. Certaines données peuvent être partagées sans se préoccuper du risque de divulgation, comme dans le cas de personnes qui participent à une recherche et consentent au partage de leurs renseignements identificatoires (p. ex., des partages d’histoires orales lors d’entrevues) ou dans le cas de renseignements recueillis de sources publiques sans attentes particulières liées à la vie privée (p. ex., une liste des membres d’un conseil d’administration). Autrement, les données doivent être évaluées pour déterminer leur risque de divulgation et elles ne pourront être partagées que si elles tombent en deçà d’un seuil de risque acceptable. Des mesures courantes de curation et de statistiques permettent d’évaluer quantitativement les risques et ainsi de réduire le potentiel de divulgation de données confidentielles. Les premières étapes comprennent l’analyse du caractère unique des données de chaque personne à l’intérieur d’un jeu de données plus large.
Les identificateurs
Plusieurs personnes peuvent consentir à ce que leurs renseignements soient utilisés à des fins de recherche sans vouloir que leur identité soit divulguée. Les données de recherche peuvent comporter des identifiants directs, tels que les coordonnées des personnes participantes, leur numéro d’étudiant ou autre type de renseignements identificatoires. Les données de recherche sans identifiants directs sont quand même susceptibles de porter atteinte à la confidentialité en raison des identifiants indirects ou quasi-identifiants – des détails personnels qui, utilisés en combinaison avec d’autres, peuvent mener à l’identification d’une personne. Ces données peuvent inclure des sondages ou des entrevues avec des personnes participantes qui ont consenti à fournir des renseignements à des fins de recherche. Les données des personnes participantes peuvent également comprendre des renseignements issus de dossiers médicaux, de déclarations d’impôts, des médias sociaux ou de toute autre source de renseignements de nature personnelle.
Les identifiants directs
Les identifiants directs mettent immédiatement les participantes et participants d’une recherche à risque d’être réidentifiés. On parle d’éléments tels que le nom, le numéro de téléphone, mais aussi d’autres détails moins évidents. Par exemple, la loi américaine Health Insurance Portability and Accountability Act (HIPAA) considère toute zone géographique de moins de 20 000 personnes comme un identifiant direct. Des dates précises liées à des événements personnels, telles que les dates de naissance, sont également considérées comme identificatoires.
Le HIPAA a établi une liste de 18 identifiants personnels tandis qu’un ensemble de lignes directrices du British Medical Journal contient une liste de 14 identifiants directs et 14 indirects basés sur des lignes directrices internationales. À partir de ces sources et d’autres, nous avons compilé une liste d’identifiants directs pour la recherche canadienne. Ils devraient toujours être éliminés des données avant de rendre celles-ci publiques, à moins que les participantes et les participants de recherche n’aient autorisé le partage de leur identité (à quelques exceptions près).
- nom entier ou partiel ou initiales
- dates précises d’événements personnels tels que la naissance, la graduation, l’admission à l’hôpital (seul le mois ou l’année peut être acceptable)
- adresse complète ou partielle (de grandes zones géographiques, telles que des villes, appartiennent à la catégorie d’identifiants indirects et doivent être révisées)
- code postal complet ou partiel (les trois premiers chiffres peuvent être acceptables)
- numéros de téléphone ou de télécopieur
- adresse courriel
- identifiants ou noms d’utilisateurs Web ou de médias sociaux tels que le pseudonyme Twitter
- numéros de protocole Internet ou IP; renseignements précis relatifs au navigateur Web ou au système d’exploitation (ces informations peuvent être recueillies par certains types d’outils de sondage ou de formulaires Web)
- identifiants de véhicule tels que la plaque d’immatriculation
- identifiants liés à des dispositifs médicaux ou autres
- tout autre numéro d’identification unique lié directement ou indirectement à un individu tel que le numéro d’assurance sociale, numéro d’étudiant ou numéro d’identification d’un animal de compagnie
- photos d’individus ou de leur domicile ou emplacement; des enregistrements vidéos les montrant; des images médicales
- enregistrements audio de personnes (Han et al., 2020)
- données biométriques
- tout attribut personnel unique ou reconnaissable (p. ex., maire de Kapuskasing ou gagnant du prix Nobel)
De plus, tous les fichiers numériques partagés, tels que des photos ou documents, doivent être vérifiés au cas où des renseignements comme un nom ou un emplacement y seraient intégrés (voir Henne et al., 2014.)
Les identifiants indirects
Les risques de violation de la confidentialité posés par les identifiants directs sont évidents – si vous détenez l’adresse ou le numéro d’assurance sociale d’une personne, sa vie privée peut être compromise. Mais quels sont les identifiants indirects et pourquoi sont-ils problématiques? Les identifiants indirects (aussi désignés comme quasi-identifiants) se rapportent à des attributs qui ne peuvent pas en soi identifier une personne, mais qui, combinés, peuvent révéler l’identité de quelqu’un. Une variable a le potentiel d’être un identifiant (direct ou indirect) seulement si elle peut être liée à des renseignements d’autres sources pour identifier une personne.
Il est impossible de dresser une liste complète des quasi-identifiants, mais on devrait toujours tenir compte des éléments suivants:
- âge (peut être un identifiant direct dans le cas de personnes très âgées);
- identité de genre;
- revenu;
- emploi ou secteur d’activité;
- variables géographiques;
- variables ethniques ou d’immigration;
- appartenances à des organismes ou utilisation de services particuliers.
Ces variables doivent être considérées en relation avec tout renseignement contextuel d’un jeu de données – par exemple, la documentation d’un sondage ou d’une recherche publiée peut indiquer de façon claire que les personnes qui ont participé à la recherche habitent un endroit particulier ou pratiquent un métier particulier.
Les autres variables d’un jeu de données constituent des renseignements non identificatoires (peu susceptibles d’être reconnus comme provenant d’individus spécifiques ou qui n’apparaissent pas dans des bases de données externes). Celles-ci peuvent comprendre des opinions, des notes sur l’échelle de Likert, des mesures temporaires (telles que le rythme cardiaque au repos) et autres. Ces renseignements ne font pas partie de l’évaluation de la confidentialité, mais doivent quand même être pris en compte dans l’évaluation globale des risques. Une des questions en lien avec les variables non identificatoires se rapporte au niveau de sensibilité des données; un jeu de données qui contient des renseignements confidentiels sur la santé ou un sondage qui pose des questions de nature délicate sur des comportements antérieurs doit être traité avec plus de soins qu’un jeu de données qui évalue des produits.
Un ensemble d’enregistrements qui comporte les mêmes valeurs de quasi-identifiants s’appelle une classe d’équivalence. Une classe d’équivalence de 1 se rapporte à une personne dont les attributs sont uniques dans le jeu de données. Cette personne risque donc d’être identifiée et elle est désignée comme étant unique à l’échantillon. Si une étude contient un échantillon complet d’une population quelconque (p. ex., tous les employés d’un endroit particulier), cette personne est aussi unique à la population en fonction de ces attributs (son identité peut donc être évidente pour les gens qui connaissent la population). Parallèlement, les membres d’une classe d’équivalence plus importante – avec 10, 20 ou 50 membres – sont indissociables les uns des autres et ne peuvent donc pas être identifiés en fonction de leurs quasi-identifiants; ils ne sont donc pas considérés comme étant à risque d’être identifiés.
Vous connaissez maintenant les quasi-identifiants et comprenez de quelle façon ils peuvent être utilisés pour identifier les personnes qui participent à des sondages. Alors, que faites-vous avec? Vous pouvez tout simplement les retirer de vos données comme vous le feriez pour les identifiants directs. Par contre, ce procédé pourrait avoir de sérieux impacts sur la capacité des autres membres de la communauté de recherche à utiliser ce jeu de données. Vous devriez plutôt évaluer les quasi-identifiants pour en déterminer le niveau de risque.
Comme première étape, une curatrice ou un curateur des données peut isoler les variables et les étudier dans le contexte d’autres informations sur les données. Les variables quasi-identifiantes qui contiennent des groupes avec un petit nombre de personnes répondantes (p. ex., une variable sur la religion avec trois réponses de « Bouddhisme ») peuvent représenter un risque élevé. Des valeurs peu courantes (p. ex., plus de six enfants) peuvent aussi comporter un risque élevé. Ces valeurs peuvent être évaluées en effectuant un calcul de fréquence sur les données. Toutefois, la grosseur des groupes identifiables tant dans l’enquête que dans la population en général doit être prise en compte. Il n’y a peut-être qu’une seule personne de Winnipeg dans votre sondage téléphonique à composition aléatoire, mais si l’enquête ne cherche pas à cibler davantage, la personne ne risque pas d’être identifiée.
Une approche pratique et sensée à la dépersonnalisation des données est de décrire une personne en n’utilisant que les valeurs des variables démographiques dans un jeu de données :
« Je pense à une personne mariée de sexe féminin, vivant en Ontario, détentrice d’un diplôme universitaire qui est âgée de 40 à 55 ans. »
Cette personne ne semble pas être à risque à moins que l’information contextuelle fournisse des indices supplémentaires – par exemple, s’il s’agit d’une enquête sur les gens qui exercent la profession d’arbitre de hockey.
Des valeurs à combinaison inhabituelle ou atypique pour les variables peuvent être problématiques. L’âge, le niveau d’éducation ou l’état civil ne sont pas forcément identifiants, mais que se passe-t-il si, par exemple, une personne dans le jeu de données est dans le groupe d’âge de moins de 17 ans et qu’elle indique être divorcée ou diplômée universitaire? Cette personne peut alors être identifiée et représente un exemple de valeur extrême cachée qui n’apparaît pas en examinant la fréquence de toutes les variables d’un jeu de données. Plus il y a d’identifiants indirects dans les données, plus il y a de chances de combinaisons atypiques cachées et plus elles sont difficiles à déceler. Le besoin d’une méthode formelle d’évaluation des quasi-identifiants et de quantification de leur niveau de risque s’impose. Ce processus s’appelle l’évaluation statistique des risques de divulgation.
L’évaluation statistique des risques de divulgation
Il existe différentes techniques pour évaluer et limiter les risques de réidentification, mais la plus connue d’entre elles est la k-anonymisation. Il s’agit d’une approche permettant de démontrer mathématiquement qu’un jeu de données a été anonymisé. Elle a d’abord été avancée en 1998 par des informaticiens (Samarati et Sweeney) et constitue depuis lors la base de tous les efforts formels d’anonymisation des données. L’approche part du principe que ce ne devrait pas être possible d’isoler moins de « k » cas individuels dans votre jeu de données et ce, pour toutes les combinaisons possibles de variables identificatoires – « k » correspond au numéro établi par la chercheuse ou le chercheur; dans la pratique, il correspond généralement à cinq.
Imaginons un sondage sur le personnel d’une usine d’outils et de matrices avec trois variables démographiques : le groupe d’âge, le genre et le groupe ethnique. Prenons, par exemple, une personne dans le jeu de données qui n’est pas une minorité visible et qui est de sexe masculin entre 25 et 30 ans. Pour que les données soient k-anonymes avec k=5, au moins quatre autres personnes dans le jeu de données doivent avoir le même ensemble d’attributs. Cela doit également être vrai pour tous les autres individus dans le jeu de données; chaque personne doit avoir au moins quatre jumeaux de données.
Dans la figure 1, les cas 1, 6 et 13 représentent une classe d’équivalence où k=3. Chaque cas de cette classe d’équivalence a deux jumeaux de données. Même si un pirate informatique savait qu’une personne ciblée se trouvait dans le jeu de données et qu’il pouvait faire correspondre ses attributs aux données, il ne pourrait identifier cette personne parmi les trois cas. Le cas 14 quant à lui, n’a aucun jumeau de données – il est unique à l’échantillon.
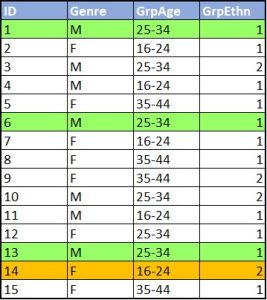
Pour réussir la k-anonymisation où la valeur de « k » d’un jeu de données correspond à cinq, vous pouvez utiliser des techniques de réduction des données, dont la réduction globale des données et la suppression locale. La réduction globale des données implique de modifier certaines variables de tout un jeu de données, tel que de regrouper certaines réponses en catégories (p. ex., regrouper l’âge en tranches de 10 ans). La suppression locale se rapporte à l’élimination de réponses ou de cas individuels (p. ex., supprimer la réponse sur l’état civil de la personne participante de moins de 17 ans plutôt que de regrouper les variables sur l’état civil et l’âge qui sont autrement inoffensives).
La k-anonymisation est facile à vérifier en utilisant des logiciels standards de statistiques, même si la plupart de ces progiciels n’ont pas de fonctionnalités intégrées pour faire ces vérifications. La ressource Directives sur la dépersonnalisation des données de l’Alliance de recherche numérique du Canada (L’Alliance) fournit du code pour faire les vérifications dans R et Stata.
La k-anonymisation a pour but de garantir l’anonymisation des données, c’est-à-dire que chaque enregistrement des données anonymisées ne pourra être distingué de « k » moins un autre enregistrement d’un même jeu de données. Toutefois, les personnes qui participent à une recherche ne sont généralement pas informées qu’il sera impossible de savoir quelle ligne d’un fichier de données correspond à leurs renseignements personnels. On leur dit plutôt que leurs réponses resteront confidentielles. Même si les enregistrements d’une personne ne sont pas uniques aux données, la possibilité de trouver quand même des renseignements personnels les concernant n’est pas exclue.
Quelques années après la publication sur la k-anonymisation comme solution à l’enjeu de la vie privée, des chercheurs ont remarqué une potentielle lacune importante : l’attaque par homogénéité. Lorsque tous les membres d’une classe d’équivalence (un jeu de jumeaux de données) partagent les mêmes valeurs d’attributs sensibles, des pirates informatiques pourraient déduire les attributs des personnes qui ont répondu à un sondage sans les identifier. Reprenons comme exemple l’échantillon de l’enquête sur le personnel d’une usine. La figure 2 illustre les variables démographiques accompagnées d’une question sensible, si les travailleuses et travailleurs sont pour ou contre la mise en place d’un syndicat. Les cas 1, 6 et 13 forment toujours une classe d’équivalence de k=3. Alors même si vous connaissez les personnes qui correspondent à ces attributs, vous ne pouvez savoir quelle personne correspond à quel cas. Par contre, ces trois personnes ont donné la même réponse à la question sur le syndicat. Vous connaissez donc la réponse de toutes ces personnes. Il y a donc une atteinte à la confidentialité.
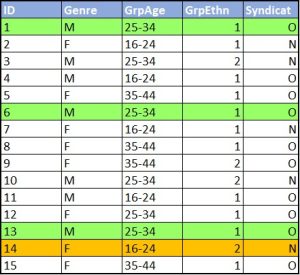
Des techniques qui affinent la k-anonymisation, telles que la k-anonymisation p-sensible et la l-diversité (Domingo-Ferrer et Torra, 2008) ont été élaborées pour aborder la question de la divulgation des attributs. Toutefois, leur mise en œuvre est difficile et tend à dégrader la valeur de recherche du jeu de données. Examinons une des variantes les plus simples.
La l-diversité est appliquée à un jeu de données quand chaque groupe d’enregistrements qui partage une même série d’attributs démographiques comporte au moins « l » valeurs différentes pour chacune des variables confidentielles. Dans notre exemple, chacun des groupes de jumeaux de données devrait comporter les deux réponses, oui et non, à la question sur le syndicat; deux représente donc la valeur maximale possible de « l » pour cette question. La valeur établie de « l » doit s’appliquer pour toute réponse confidentielle dans le jeu de données. Imaginez maintenant un sondage typique avec une douzaine de questions – la l-diversité doit être considérée pour chaque réponse dans chaque classe d’équivalence. Autrement dit, l’application des techniques comme la l-diversité n’est pratique que pour les jeux de données avec peu de variables.
La plus grande menace d’une attaque par homogénéité survient lorsqu’un jeu de données représente l’échantillon d’une population entière. Imaginez que le jeu de données du sondage à l’usine n’implique que 25% de la population. Cela signifie qu’il y a possiblement d’autres personnes qui ne font pas partie du jeu de données et qui possèdent les mêmes quasi-identifiants que les cas 1, 6, et 13; leur position sur l’établissement d’un syndicat est inconnue. En ignorant quelles personnes font partie du jeu de données, impossible de connaître leur opinion, et ce, même si elles appartiennent à la même classe d’équivalence. Cette supposition ne peut être faite que si le jeu de données représente un petit échantillon d’une population plus large et que si le principe de la k-anonymisation a été appliqué. Inversement, si le jeu de données représente l’échantillon d’une population entière ou d’une proportion importante de celle-ci, il doit être traité avec beaucoup de précautions – il est presque impossible de garantir la dépersonnalisation d’un tel jeu de données.
Les identifiants cachés
En évaluant le risque, il faut tenir compte de l’ampleur du jeu de données (nombre de personnes participantes et nombre de variables). Dans le cas de jeux de données plus importants, les pirates informatiques peuvent utiliser des approches d’apprentissage automatique. Les cotes et classements personnels ne sont pas considérés comme des éléments identifiants. Malgré cela, Zhang et al. (2012) ont fait la description d’un cas où un système d’apprentissage artificiel a été entraîné à traiter une importante collection de profils qui incluaient des classements de films; le système a pu déduire avec une certaine fiabilité quels comptes étaient liés à de multiples personnes utilisatrices. Il est facile d’imaginer d’autres attaques avec des approches semblables – par exemple, faire la comparaison de critiques de livres publiées sur des sites comme Goodreads à des réponses de sondage incluant des classements de livres utilisés dans les thérapies axées sur les traumatismes.Thompson et Sullivan (2020) ont démontré une autre approche où des variables inattendues étaient susceptibles de réidentifier des personnes ayant répondu à un sondage par le biais d’une attaque utilisant des renseignements géographiques. Elles ont démontré qu’une variable indiquant la distance de la grande ville la plus proche pouvait être combinée au renseignement sur le domicile d’une personne ayant répondu au sondage et habitant une réserve autochtone; cette combinaison permettait de localiser certaines personnes ayant répondu au sondage. Le procédé est difficile à faire à la main, mais très facile à l’ordinateur.
Ces cas sont la preuve qu’il n’y aura jamais une seule mécanique simple pour encadrer la dépersonnalisation des jeux de données. Vous devrez toujours évaluer à quel point des sources externes de renseignements ou de données peuvent chevaucher les données de votre population de recherche et partager certains renseignements identiques. Il y a risque de réidentification quand des informations externes auxquelles des pirates informatiques ont accès peuvent être combinées à des informations d’un jeu de données archivé; chaque jeu de données doit être évalué de façon individuelle.
La dépersonnalisation des données qualitatives
Nous utilisons généralement des méthodes statistiques d’anonymisation de données sur des données structurées comme celles d’un tableur ou d’une feuille de calcul. Toutefois, les données qualitatives sont souvent stockées et analysées dans des formats non structurés (p. ex., des entrevues, des groupes de discussion ou transcriptions d’histoires orales en format texte, audio ou vidéo, des observations ethnographiques notées sur le terrain, etc.). L’anonymisation de données qualitatives non structurées demeure possible, de nombreux logiciels ou outils numériques existent pour faciliter ou automatiser certains des processus (pour un excellent aperçu, visionnez cette discussion entre spécialistes sur la dépersonnalisation des données qualitatives (en anglais uniquement) : https://youtu.be/MbKw3LR2rVo).
Il arrive parfois qu’un individu qui participe à une recherche s’identifie lui-même par inadvertance en répondant à des questions d’entrevue ou en discutant d’une expérience vécue. Prenons par exemple une étude où un bibliothécaire mène des entrevues avec des bibliothécaires d’autres universités; si une personne répond qu’elle travaille pour tel établissement (McGill) et occupe tel poste (spécialiste en gestion des données de recherche), ces renseignements utilisés en combinaison avec d’autres peuvent l’identifier. Le défi des données qualitatives repose sur le fait que les informations identificatoires ne se retrouvent pas dans des catégories prédéterminées (p. ex., l’âge, la religion, le genre) de sorte qu’il n’est pas possible de prédire la quantité de renseignements identificatoires contenus dans un jeu de données avant la collecte et l’analyse de celui-ci.
La chercheuse ou le chercheur peut supprimer les informations identificatoires – une approche similaire à celles utilisées avec les données structurées – cependant, les informations contextuelles sont souvent essentielles aux recherches qualitatives. Par conséquent, la chercheuse ou le chercheur pourra attribuer des codes pour remplacer les catégories d’informations identificatoires. Le Finnish Social Science Data Archive (FSD) recommande l’utilisation de crochets dans les transcriptions pour indiquer les éléments qui ont été dépersonnalisés afin d’éviter la ponctuation couramment utilisée (Finnish Social Science Data Archive, 2020). Par exemple, une chercheuse peut remplacer un nom d’individu par [Participant1], ou un endroit précis comme Pohénégamook (un petit village au Québec) par [village]. Si le contexte géographique est important, le code peut alors être modifié pour représenter un endroit en général plutôt qu’un village précis tel que [région du Bas-Saint-Laurent].
Lorsque vous dépersonnalisez des informations qualitatives ou rassemblez des informations plus détaillées en catégories, il est important de documenter les décisions et les catégories dans un guide de codification qui accompagnera le jeu de données. Par exemple, la chercheuse peut décider d’éliminer le nom des villages dont la population est inférieure à 1000 habitants. La documentation doit détailler les motifs et les définitions afin de permettre la réutilisation potentielle du jeu de données.
Les transcriptions d’entrevues devraient être anonymisées même si la chercheuse ou le chercheur n’envisage pas de publier ses données. Ainsi, le risque de préjudices est réduit en cas de fuite. L’anonymisation devrait être irréversible; en anonymisant, la chercheuse ou le chercheur doit tenir compte à la fois du préjudice potentiel pour les personnes participantes si des informations identificatoires étaient rendues publiques et de sa capacité à analyser les données sans perdre de nuances. Si l’objectif d’une recherche est d’analyser un sujet sensible, les données ne devraient peut-être pas être dépersonnalisées, elles auront donc besoin de mesures supplémentaires de protection.
Le langage de consentement et l’ETPC 2
Lors de la curation de données d’êtres humains, vous devez être au courant des mesures de protection offertes aux personnes participantes et sous quelles conditions les comités d’éthique de la recherche (CÉR) ont autorisé la recherche. Au Canada, c’est la politique de l’EPTC 2 qui établit les lignes directrices éthiques pour les recherches avec des êtres humains. Dans la plupart des établissements, le CÉR examinera le langage de consentement plus que toute autre composante de la demande afin d’assurer la confidentialité et la protection de la vie privée des personnes participantes, en plus de s’assurer que celles-ci aient été bien informées de la portée et de la nature de leur participation dans la recherche. En vertu des lignes directrices de l’EPTC 2, les formulaires de consentement devraient comprendre les informations suivantes :
- la participation est volontaire;
- les personnes participantes peuvent se retirer de la recherche et ce, même si elle est en cours;
- un énoncé en langage clair (p. ex., sans jargon) qui décrit l’étude de façon sommaire et qui énumère les risques et bénéfices potentiels pour les personnes participantes – cette information est particulièrement importante pour les études qui impliquent des populations vulnérables, des sujets jugés tabous, de la coercition (p. ex., des incitations) et/ou de la duperie quand les personnes participantes ne connaissent pas le but véritable de la recherche;
- dans l’éventualité où les données seraient accessibles à d’autres chercheuses ou chercheurs ou au public, sous quelles conditions, est-ce qu’elles seront stockées dans des dépôts particuliers*, sous quels formats et avec quels renseignements (p. ex., si les données peuvent comporter des identifiants directs ou indirects).
*Les CÉR peuvent exiger que les chercheuses et chercheurs identifient le dépôt où seront stockées ou publiées les données sur des personnes participantes. Par exemple, un CÉR peut exiger que les données soient uniquement stockées ou publiées dans des dépôts dont les serveurs sont au Canada ou dont l’accès est contrôlé (p. ex., la possibilité de limiter l’accès à certaines personnes particulières).
Les formulaires de consentement devraient préciser les détails entourant le dépôt ou la publication éventuelle de données sur des êtres humains; quelques chercheuses ou chercheurs peuvent avoir l’intention ou l’obligation (p. ex., par les organismes subventionnaires ou les politiques d’un périodique) de rendre leurs données accessibles à la suite de la publication d’une recherche connexe. Autrement, si une chercheuse ou un chercheur est tenu ou choisit de partager ses données, le consentement des personnes participantes devra possiblement à nouveau être demandé par le biais d’un formulaire de consentement amendé, ce qui peut s’avérer difficile, voire impossible, si tous les identifiants directs ont été anonymisés de façon permanente.
Certaines ressources fournissent des modèles ou des exemples de langage pour les formulaires de consentement et les demandes de CÉR en lien avec le stockage et le partage de données d’êtres humains. L’Alliance de recherche numérique du Canada (l’Alliance) a publié une Boîte à outils pour les données sensibles – destinée aux chercheurs (Groupe d’experts sur les données sensibles du réseau Portage, 2020b) dans laquelle vous pouvez puiser pour rédiger vos formulaires de consentement et bien expliquer les éléments suivants aux personnes participantes : la différence entre l’anonymat et la confidentialité; les obstacles au retrait de l’étude; les paramètres de l’utilisation future des données y compris les processus de supervision (p. ex., l’établissement d’ententes de réutilisation des données ou l’obligation pour les prochains projets de recherche d’obtenir l’autorisation d’un CÉR avant de pouvoir accéder aux données); si les données peuvent être utilisées à d’autres fins que celles du sujet de recherche original et si les données sont ouvertes au public soit entièrement ou en partie. Vous trouverez ci-dessous un texte passe-partout (adapté à partir de plusieurs sources) que vous pouvez modifier et utiliser dans des formulaires de consentement advenant que vos données soient susceptibles d’être partagées. La Boîte à outils pour les données sensibles – destinée aux chercheurs (Groupe d’experts sur les données sensibles du réseau Portage, 2020b) contient des exemples supplémentaires pour d’autres types de cas :
Les organismes subventionnaires et les maisons d’édition demandent souvent aux chercheuses et chercheurs de rendre leurs données de recherche accessibles une fois leur étude terminée. L’accès aux données permet à la communauté de recherche de reproduire les conclusions scientifiques et encourage l’exploration des jeux de données existants. Afin d’assurer la confidentialité et l’anonymat, toute donnée partagée sera dépouillée des renseignements pouvant identifier une personne participante.
Pour plus de ressources et des exemples de langage pour les formulaires de consentement, veuillez vous référer aux guides très complets fournis (en anglais uniquement) par le Inter-university Consortium for Political and Social Research (ICPSR) et le Finnish Social Science Data Archive.
Le Qualitative Data Repository (QDR) basé à l’Université Syracuse à New York propose un guide pour le consentement éclairé (en anglais uniquement) en lien avec les études qualitatives, notamment pour des entrevues et des histoires orales où les identifiants directs sont conservés dans la publication du jeu de données (Qualitative Data Repository, s.d.-b). Le QDR propose aussi des modèles (en anglais uniquement) pour la publication de documents d’archives et pour l’obtention du consentement pour la diffusion de données dépersonnalisées ou identificatoires (Qualitative Data Repository, s.d.-a). L’exemple suivant provient du QDR pour le dépôt d’informations potentiellement identificatoires :
Les données générées à partir de l’information que vous avez fournie dans le cadre de notre échange pourront être partagées avec la communauté de recherche (généralement sous forme numérique via Internet) afin de faire progresser les connaissances scientifiques. En raison de la nature des informations, une dépersonnalisation complète des données peut s’avérer impossible. Conséquemment, d’autres mesures seront appliquées avant le partage. Je prévois déposer les données dans le DÉPÔT X, ou dans un dépôt similaire dans le domaine des sciences sociales. Vos données NE SERONT ACCESSIBLES QUE SOUS LES CONDITIONS SUIVANTES. Malgré ces mesures, il n’est pas possible de prédire comment les personnes qui accèdent aux données les utiliseront[1] [traduction].
Le Data Curation Network fournit un guide complet pour la curation des données d’êtres humains (en anglais uniquement), y compris pour la révision du langage de consentement. Le guide d’introduction sur la curation des données avec des êtres humains offre du soutien aux responsables de la curation et des dépôts de données sur les bonnes questions à poser en lien avec, notamment, le processus de consentement, le langage de consentement et les lacunes potentielles entre le jeu de données et le langage de consentement.
Autres catégories de données sensibles
Les données d’êtres humains sont souvent considérées sur un pied d’égalité avec les données sensibles. Toutefois, d’autres catégories de données sensibles qui n’impliquent pas des êtres humains sont tout aussi importantes. Dans le cas de chercheuses et chercheurs qui travaillent en collaboration avec des partenaires d’industrie pour développer des technologies et des inventions, les données peuvent être considérées comme relevant du « secret commercial » et doivent alors être protégées conformément aux obligations contractuelles (Gouvernement du Canada, 2019). La poursuite du profit comme principal objectif d’une recherche est, en théorie, contraire aux vocations universitaires. Par contre, ce type de partenariat permet un plus large accès à des ressources et des infrastructures que celles qui sont disponibles par l’entremise de sources de financement universitaires ou publiques. Par exemple, les vaccins de la COVID-19 ont été développés beaucoup plus rapidement en raison des partenariats entre la communauté de recherche universitaire et les compagnies pharmaceutiques privées.
Voici d’autres catégories de données sensibles :
- la propriété intellectuelle;
- les données à double usage;
- les données assujetties à un contrôle des importations/exportations;
- les données sous licence tierce;
- la localisation d’espèces en péril.
Des préoccupations en matière de propriété intellectuelle peuvent survenir lorsque des données sont associées à des demandes de brevet en instance, à des recherches brevetées ou à d’autres informations protégées par le droit d’auteur. Les gens qui détiennent les droits sur les données peuvent décider d’accorder l’accès et permettre leur réutilisation. Si la propriété intellectuelle est liée à une source potentielle de revenus, le partage et l’accès aux données sont peu courants. Voici quelques considérations importantes en matière de propriété intellectuelle : qui est propriétaire des données, quelles sont les conditions d’utilisation (ou la licence) des données ainsi que toute autre condition liée à l’utilisation ou la réutilisation des données. Le chapitre 12 « Planification de la gestion des données pour les processus de travail en science ouverte » aborde plus en détail les considérations en matière de propriété intellectuelle.
Les données à double usage se rapportent aux données développées à des fins civiles qui peuvent également être utilisées pour des applications militaires. Par exemple, la technologie de reconnaissance faciale peut avoir été développée pour des applications de téléphones intelligents, mais les jeux de données sous-jacents peuvent être utilisés pour former des modèles d’apprentissage automatique afin de suivre des dissidents politiques ou de déployer des drones armés. Un autre exemple de données sensibles à double usage comprend des informations techniques sur des infrastructures essentielles. Le Canada a mis en place une réglementation et des procédures d’évaluation pour déterminer si la recherche est à double usage et quelles sont les mesures de protection à appliquer selon le niveau de risque.
Les données assujetties au contrôle des importations/exportations (marchandises contrôlées) sont liées aux données à double usage dans la mesure où elles ont des incidences sur les applications et renseignements militaires pouvant traverser les frontières canadiennes (Gouvernement du Canada, s.d.). Dans la définition des marchandises contrôlées sont incluses les armes en provenance des États-Unis. Ces règlements sont en place pour empêcher la participation des chercheuses et chercheurs, qu’elle soit intentionnelle ou non, dans le trafic d’armes ou de technologies de l’armement.
Les tiers se rapportent aux entités autres que la personne responsable de la recherche et son établissement. L’utilisation des données par un tiers nécessite une licence de l’entité propriétaire des données. Par exemple, les démographes peuvent acheter des jeux de données de Statistiques Canada à condition que les données soient utilisées ou partagées que par des chercheuses ou chercheurs du même établissement. Des ententes sur l’utilisation des données précisent plusieurs choses : qui peut accéder aux données, à quelle(s) fin(s), quand, où les données seront stockées, si une partie des données peut être déposée et si les données doivent être détruites ou préservées à la fin de l’étude. Dans la plupart des cas, ces ententes interdisent aux chercheuses et chercheurs le dépôt ou la publication des jeux de données sous-jacents utilisés pour leur recherche.
Les informations sur la localisation des espèces menacées sont considérées comme une catégorie de données sensibles en raison de leur possible utilisation malveillante qui pourrait nuire à ces espèces. Prenons l’exemple du projet d’un chercheur qui place des étiquettes numériques de géolocalisation sur des rhinocéros pour étudier leurs déplacements. Des braconniers qui accèdent à ces données pourraient les utiliser pour localiser et chasser les rhinocéros qui constituent une espèce en péril.
L’identification des personnes participantes n’est pas nécessairement une préoccupation aussi importante lorsque les chercheuses et chercheurs travaillent avec ces autres catégories de données sensibles mais les responsables de la recherche auront à se soucier davantage des mesures de protection et de cybersécurité, des responsabilités légales et de la conformité. La gestion des données de recherche (GDR) pour ce type de données implique d’autres éléments comme des accès chiffrés ou protégés par mot de passe (p. ex., l’authentification multifactorielle, la transmission sécurisée de données via un réseau privé virtuel (VPN)), des procédés sécurisés de stockage et de sauvegarde, l’interdiction d’utiliser des appareils personnels pour interagir avec les données et des vérifications robustes de sécurité pour l’identification potentielle de fuites.
La préservation et le partage de données sensibles
Certains dépôts de données numériques acceptent les données sensibles, notamment le Inter-university Consortium for Political and Social Research (ICPSR), le Qualitative Data Repository (QDR), et le Finnish Social Science Data Archive. Toutefois, aucun dépôt canadien ne les accepte.
L’Alliance travaille actuellement sur un projet pilote pluriannuel visant à établir un partenariat avec des universités canadiennes dans le but de soutenir la mise en œuvre d’une infrastructure qui permettrait de contrôler l’accès à des données sensibles. La technologie doit se conformer aux politiques et lois institutionnelles, provinciales et fédérales et doit dépendre d’une infrastructure située au Canada. Le projet a débouché sur un outil intégrant le cryptage à divulgation nulle de connaissance afin que les jeux de données sensibles puissent être transférés d’un environnement de dépôt sécurisé vers les chercheuses ou chercheurs ou vice versa. La divulgation nulle de connaissance signifie que les gens qui administrent un système ne possèdent pas la clé pour déchiffrer les fichiers dans leur système. Les clés de déchiffrement des données sont stockées sur une plateforme indépendante. La chercheuse ou le chercheur qui souhaite accéder à un jeu de données sensibles doit télécharger les données chiffrées du dépôt de données pour ensuite recevoir le mot de passe de la plateforme de gestion de la clé.
Plusieurs dépôts de données d’établissements universitaires canadiens ont accès à une instance de Dataverse, et plusieurs utilisent Borealis, une instance de Dataverse gérée par Scholar’s Portal. Les conditions d’utilisation de Borealis ne permettent pas le dépôt de données sensibles. Toutefois, le consortium responsable du développement et de la maintenance de Borealis a choisi de s’en remettre aux CÉR pour déterminer si un jeu de données est de nature sensible. La sensibilité n’est pas un concept binaire – une donnée peut être plus ou moins sensible – le processus pour déterminer le niveau de sensibilité des données peut exiger des calculs complexes. Les dépôts de données peuvent accepter les jeux de données anonymisées d’êtres humains sans nécessairement les définir comme étant de nature sensible.
Pour préserver et partager des données sensibles, une chercheuse ou un chercheur peut parfois garder ses données localement tout en publiant une documentation et des métadonnées dans la collection Dataverse de son établissement pour que d’autres chercheuses et chercheurs puissent y découvrir les renseignements et les procédures pour accéder aux données. Les bibliothèques peuvent soutenir ce type d’initiative en créant des espaces sûrs et isolés du réseau pour assurer une préservation et une sauvegarde sécurisée, particulièrement dans le cas de données stockées à long terme. La bibliothèque doit alors travailler de concert avec la personne qui dépose des données pour assurer la mise en place de protocoles d’accès appropriés. Dans l’encadré ci-dessous, vous trouverez un exemple de langage pour le formulaire de dépôt :
Formulaire de dépôt : Conditions pour le dépôt, le stockage, le partage et la réutilisation
La personne qui dépose accorde à la bibliothèque le droit de stockage et de gestion sécuritaire des données y compris pour la transformation, le déplacement vers d’autres plateformes et la création de copies de sauvegarde pour assurer la préservation.
- indéfiniment ou jusqu’à leur retrait
- jusqu’à la date suivante, après laquelle les données seront supprimées
Est-ce qu’un enregistrement de ce jeu de données peut être partagé dans <archive locale> afin qu’il puisse être découvert? Si oui, veuillez fournir toute restriction en lien avec le partage de la documentation.
Veuillez préciser comment et sous quelles conditions les données peuvent être partagées avec la communauté de recherche extérieure à l’équipe originale. À noter que votre formulaire de consentement original doit, selon le cas, permettre cette réutilisation.
- Les données ne peuvent être partagées qu’avec la permission explicite de la ou des personne(s) suivante(s) (p. ex., le déposant, les membres de l’équipe de recherche originale, le comité de révision des données, etc.).
- Veuillez indiquer les personnes et fournir leurs coordonnées.
- Les données peuvent être partagées conformément à certaines conditions (p. ex., l’autorisation d’un comité d’éthique en recherche, l’établissement d’un plan de gestion sécuritaire des données qui fait état des mesures prévues pour assurer la sécurité des données lors de leur réutilisation, la signature d’un document avec des conditions).
Veuillez préciser les restrictions éthiques en matière de réutilisation. Selon le cas, joignez à votre dépôt de données une copie du formulaire original de consentement.
Conclusion
En évaluant les risques et les préjudices potentiels, les chercheuses et chercheurs doivent tenir compte d’une foule d’éléments : les politiques, lois et règlements au niveau institutionnel, provincial, fédéral; les exigences des organismes subventionnaires, les normes disciplinaires ainsi que les obligations contractuelles. Les préjudices peuvent atteindre plusieurs parties concernées, y compris les personnes participantes, les établissements, la chercheuse ou le chercheur, la communauté, le pays et toutes autres entités associées.
Voilà pourquoi plusieurs établissements mettent en place de façon formelle un classement pour les données sensibles avec une échelle de niveaux de risques (p. ex., très élevé, élevé, modéré et faible). Les établissements doivent tenir compte de différents facteurs locaux et de la gouvernance dans l’évaluation des risques, ce qui entraîne parfois quelques difficultés. Par exemple, le classement des données de recherche dans plusieurs établissements se fait selon les mêmes balises que les données administratives ou d’entreprise, complexifiant l’application des différents niveaux de risques dans certains contextes – notamment à l’Université de la Colombie-Britannique (2021) où toutes les informations électroniques sont classées uniformément avec seulement une référence générale aux données de recherche. D’autres universités ont établi des lignes directrices qui comprennent des exemples précis en lien avec la recherche comme l’Université de Calgary (2015) qui inclut les recherches « avec des êtres humains identifiables » comme un exemple de situations comportant des risques très élevés. L’Université Harvard (2020) a mis en place un système consacré à l’identification des niveaux de risques et de préjudices dans les données de recherche. Les données comportant des risques mortels pour le sujet appartiennent à la catégorie de risques la plus élevée. Cette catégorie est définie ainsi : « toute donnée sensible qui est susceptible d’entraîner de graves préjudices pour le sujet ou toute donnée comportant des exigences contractuelles en matière de mesures de sécurité exceptionnelles[2] » [traduction].
Les bibliothèques fournissent les outils, l’information et la formation nécessaires aux gens qui font de la recherche pour qu’ils puissent préserver et partager leurs données de façon éthique et responsable. Mais c’est aux personnes responsables de la recherche qu’il incombe de faire preuve de diligence raisonnable en lien avec les risques.
Questions de réflexion
- Quelle est la principale politique canadienne en matière d’éthique à propos de la recherche qui utilise des données d’êtres humains?
- Énumérez trois identifiants directs et trois quasi-identifiants dans les données d’êtres humains.
- Une étudiante de cycle supérieur mène une étude sur le terrain au sujet d’une espèce de tortue menacée le long du fleuve Saint-Laurent. Sur une feuille de calcul stockée localement sur son ordinateur, elle fait le suivi des tortues et enregistre les informations suivantes à chaque observation : les latitudes et longitudes, la distance des sites industriels à proximité et le nombre de tortues observées. Dans quelle mesure la chercheuse travaille-t-elle avec des données sensibles?
Voir le solutionnaire pour les réponses.
Éléments clés à retenir
- La dépersonnalisation est le processus d’élimination dans un jeu de données de tout renseignement susceptible de porter atteinte à la vie privée des personnes qui participent à une recherche.
- Les données sensibles sont des données qui ne peuvent être partagées sans risquer de trahir la confiance ou de causer des préjudices à une personne, une entité ou une communauté.
- Les renseignements identificatoires sont des renseignements d’un jeu de données qui, soit seuls ou en combinaison avec d’autres, peuvent entraîner la divulgation de l’identité d’une personne.
- L’évaluation statistique des risques de divulgation est le processus d’évaluation mathématique des quasi-identifiants d’un jeu de données pour démontrer l’anonymisation des données.
- En évaluant le niveau de risque d’un jeu de données, vous devez tenir compte des éléments suivants : les détails à l’intérieur du jeu de données qui ont le potentiel de réidentifier un individu, soit individuellement, soit en combinaison avec d’autres; les renseignements extérieurs au jeu de données qui pourraient être jumelés aux données dans le jeu de données ou qui fournissent des informations supplémentaires sur la population de l’étude; le niveau de préjudices potentiels aux individus ou aux communautés en cas de diffusion des données.
- Les principales réglementations sur les données de recherche se trouvent au niveau provincial et territorial puisque les universités ne relèvent pas de la juridiction fédérale des lois sur la protection de la vie privée. La Loi sur la protection des renseignements personnels s’applique aux organismes gouvernementaux tandis que la Loi sur la protection des renseignements personnels et les documents électroniques (LPRPDE) s’applique aux entités commerciales du secteur privé. Les chercheuses et chercheurs qui travaillent avec ces organismes ou qui utilisent des données recueillies par eux (p. ex., les dossiers médicaux) doivent être au courant de ces réglementations. Les provinces et territoires canadiens comportent tous au moins une loi en lien avec la protection de la vie privée qui peut s’appliquer à la recherche; il est donc important de s’informer des lois de votre juridiction. Au niveau fédéral, l’Énoncé de politique des trois conseils sur l’éthique de la recherche avec des êtres humains (EPTC2) constitue le plus important cadre régissant la conduite de la recherche.
Lectures et ressources supplémentaires
Alder, S. (2023, 16 mai). What is Considered PHI Under HIPAA? The HIPAA Journal. https://www.hipaajournal.com/what-is-considered-phi-under-hipaa/
Groupe en éthique de la recherche. (2022). Énoncé de politique des trois conseils : Éthique de la recherche avec des êtres humains – EPTC 2 (2022). Gouvernement du Canada. https://ethics.gc.ca/fra/policy-politique_tcps2-eptc2_2022.html
Krafmiller, E. et Prasad, R. (2021, 16 juin). Dataverse and OpenDP [Présentation]. Dataverse Community Meeting 2021. https://youtu.be/q3irpQ4rOyU?t=250
Réseau Portage, Groupe de travail sur la COVID-19. (2020). Directives sur la dépersonnalisation des données (Version 2). Zenodo. https://zenodo.org/record/4452825#.Y-Wj7xOZPao
Sweeney, L. (2000). Simple demographics often identify people uniquely (Data Privacy Working Paper 3). Carnegie Mellon University. http://ggs685.pbworks.com/w/file/fetch/94376315/Latanya.pdf
Thorogood, A. (2018). Canada: will privacy rules continue to favour open science? Human Genetics, 137(8), 595–602. https://doi.org/10.1007/s00439-018-1905-0
Bibliographie
Centre de gouvernance de l’information des Premières Nations. (s.d.). FAQ sur les principes de PCAP®. https://fnigc.ca/fr/les-principes-de-pcap-des-premieres-nations/
Commissariat à la protection de la vie privée au Canada. (s.d.). Aperçu des lois sur la protection des renseignements personnels au Canada. https://www.priv.gc.ca/fr/sujets-lies-a-la-protection-de-la-vie-privee/lois-sur-la-protection-des-renseignements-personnels-au-canada/02_05_d_15/
Commissariat à la protection de la vie privée au Canada. (2020). Questions et réponses – projet de loi no 64. https://www.priv.gc.ca/fr/nouvelles-du-commissariat/nouvelles-et-annonces/2020/qa_20200924/
Domingo-Ferrer, J. et Torra, V. (2008). A critique of k-anonymity and some of its enhancements. Dans S. Jakoubi, S. Tjoa, et E. R. Weippl (dir.), ARES 2008: Third International Conference on Availability, Reliability and Security Proceedings, March 4-7, 2008. (pp. 990-993). IEEE Computer Society. https://doi.org/10.1109/ARES.2008.97
Finnish Social Science Data Archive. (2020). Anonymisation and personal data. https://www.fsd.tuni.fi/en/services/data-management-guidelines/anonymisation-and-identifiers/
Gouvernement du Canada. (s.d.). Quelles sont les marchandises contrôlées. https://www.tpsgc-pwgsc.gc.ca/pmc-cgp/quellessont-whatare-fra.html
Gouvernement du Canada. (2019). Lignes directrices sur la sécurité nationale pour les partenariats de recherche. https://science.gc.ca/site/science/fr/protegez-votre-recherche/lignes-directrices-outils-pour-mise-oeuvre-securite-recherche/lignes-directrices-securite-nationale-pour-partenariats-recherche
Groupe d’experts sur les données sensibles. (2020a). Boîte à outils pour les données sensibles — destiné aux chercheurs Partie 1: Glossaire terminologique sur l’utilisation des données sensibles à des fins de recherche. Zenodo. https://doi.org/10.5281/zenodo.4088986
Groupe d’experts sur les données sensibles. (2020b). Boîte à outils pour les données sensibles — destiné aux chercheurs Partie 3 : Langage en matière de gestion de données de recherche pour le consentement éclairé. Zenodo. https://doi.org/10.5281/zenodo.4107186
Han, Y., Li, S., Cao, Y., Ma, Q. et Yoshikawa, M. (2020). Voice-indistinguishability: Protecting voiceprint in privacy-preserving speech data release. 2020 IEEE International Conference on Multimedia and Expo (ICME), 1-6, https://doi.org/10.1109/ICME46284.2020.9102875
Henne, B., Koch, M. et Smith, M. (2014). On the awareness, control and privacy of shared photo metadata. Dans N. Christin et R. Safavi-Naini (dir.), Financial Cryptography and Data Security. FC 2014. Lecture Notes in Computer Science (pp. 77-88). Springer. https://doi.org/10.1007/978-3-662-45472-5_6
Qualitative Data Repository. (s.d.-a). Templates for researchers. https://qdr.syr.edu/guidance/templates#informed%20consent
Qualitative Data Repository. (s.d.-b). Informed consent. https://qdr.syr.edu/guidance/human-participants/informed-consent
Ross, M. W., Iguchi, M. Y. et Panicker, S. (2018). Ethical aspects of data sharing and research participant protections. American Psychologist, 73(2), 138-145. http://dx.doi.org/10.1037/amp0000240
Samarati, P. et Sweeney, L. (1998). Protecting privacy when disclosing information: k-anonymity and its enforcement through generalization and suppression (Technical Report SRI-CSL-98-04). Computer Science Laboratory, SRI International. https://epic.org/wp-content/uploads/privacy/reidentification/Samarati_Sweeney_paper.pdf
Thompson, K. et Sullivan, C. (2020). Mathematics, risk, and messy survey data. IASSIST Quarterly, 44(4), 1-13. https://doi.org/10.29173/iq979
Université Harvard. (2020, 22 avril). Data Security Levels – Research Data Examples. https://security.harvard.edu/data-security-levels-research-data-examples
Université de la Colombie-Britannique. (2021). Security classification of UBC electronic information. https://cio.ubc.ca/information-security-standards/U1
Université de Calgary. (2015, 1 janvier). Information Security Classification Standard. https://www.ucalgary.ca/legal-services/sites/default/files/teams/1/Standards-Legal-Information-Security-Classification-Standard.pdf
Wolford, B. (2018, 5 novembre). Everything you need to know about the ‘Right to be forgotten’. GDPR.EU. https://gdpr.eu/right-to-be-forgotten/
Zhang, A., Fawaz, N., Ioannidis, S. et Montanari, A. (2012). Guess who rated this movie: identifying users through subspace clustering. Proceedings of the Twenty-Eighth Conference on Uncertainty in Artificial Intelligence, 944-953. https://dl.acm.org/doi/10.5555/3020652.3020750
- "Data generated from the information you provide in our interaction may be shared with the research community (most likely in digital form via the Internet) to advance scholarly knowledge. Due to the nature of the information, full de-identification of those data might not be possible. As a result, other measures will be taken before sharing. I plan to deposit the data at REPOSITORY X, or at a similar social science domain repository. Your data will BE MADE AVAILABLE UNDER THE FOLLOWING ACCESS CONDITIONS. Despite my taking these measures it is not possible to predict how those who access the data will use them." ↵
- "sensitive data that could place the subject at severe risk of harm or data with contractual requirements for exceptional security measures." ↵
Données qui ne peuvent être partagées sans risque de trahir la confiance ou de nuire à une personne, une entité ou une communauté.
Sources d'informations ou de preuves qui ont été compilées pour servir de base à la recherche.
Le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG), le Conseil de recherches en sciences humaines du Canada (CRSH) et les Instituts de recherche en santé du Canada (IRSC) (les organismes subventionnaires) représentent les trois agences fédérales de financement de la recherche au Canada. Ils sont à la source d’une importante proportion des fonds de recherche au Canada.
Cadre principal harmonisé qui guide l’établissement des lois canadiennes et des paradigmes éthiques plus larges en lien avec le droit des êtres humains en recherche.
Acronyme qui signifie propriété, contrôle, accès et possession. Ces quatre principes gouvernent la manière dont les données et l’information relatives aux Premières Nations devraient être collectées, protégées, utilisées et partagées. Les principes PCAP® ont été créés pour combler une lacune dans les lois occidentales qui ne reconnaissent pas les droits des communautés et des peuples autochtones à contrôler leur information.
Droit qui permet à la personne concernée d’obtenir du responsable du traitement l’effacement, dans les meilleurs délais, de données à caractère personnel la concernant et le responsable du traitement a l’obligation d’effacer ces données à caractère personnel dans les meilleurs délais [traduction]. (GDPR.EU, 2018).
Renseignement recueilli par la chercheuse ou le chercheur qui permet d’identifier des participantes ou des participants à une recherche. Les noms, numéros de téléphone, numéros d’assurance sociale et numéros d’étudiant sont des exemples d’identifiants directs.
Tout renseignement dans un jeu de données qui, seul ou en combinaison avec d’autres renseignements, risque de permettre d’identifier une personne.
Attribut d’un individu qui n’est pas identifiant en soi mais qui, en combinaison avec d’autres renseignements, peut permettre d’identifier une personne. Un attribut ne peut être quasi-identifiant que si des pirates informatiques peuvent raisonnablement jumeler cet attribut à des informations de source externe.
Outil élaboré en additionnant ou en faisant la moyenne d'un certain nombre d'items de Likert liés entre eux. Un item de Likert est une question ou un énoncé dans un sondage où la personne interrogée doit exprimer son degré d'accord ou de désaccord.
Ensemble d’enregistrements qui comporte les mêmes valeurs d’identifiants indirects à l’intérieur d’un jeu de données.
Personne dont les renseignements en matière de quasi-identifiants ne correspondent à ceux d’aucune autre personne dans le jeu de données.
Personne dans une population qui peut être identifiée en raison d’une combinaison unique d’attributs démographiques.
Procédé par lequel tout renseignement qui pourrait compromettre la vie privée des participantes et participants à une recherche dans un jeu de données est retiré.
Approche permettant de démontrer mathématiquement qu’un jeu de données a été anonymisé. L’approche part du principe que ce ne devrait pas être possible d’isoler moins de « k » cas individuels dans un jeu de données et ce, pour toutes les combinaisons possibles de variables identificatoires – « k » correspond au numéro établi par la chercheuse ou le chercheur.
Dans un jeu de données ayant des identifiants indirects, enregistrement qui a la même valeur ou les mêmes attributs qu’un autre enregistrement. Par exemple, dans un jeu de données, deux hommes blancs entre 25-30 ans sont des jumeaux de données.
Processus utilisé lors de l'anonymisation d'un jeu de données. Le processus implique la suppression de réponses ou de cas individuels.
Modification de certaines variables dans l’ensemble d’un jeu de données, par exemple regrouper des réponses en catégories.
Moyen de porter atteinte à la confidentialité d’un groupe de participantes et de participants à une recherche quand toutes les personnes ayant le même ensemble d’attributs particuliers possèdent aussi un même attribut sensible.
Évaluation des risques à la vie privée fondée sur la k-anonymisation, mais plus contraignante.
Évaluation des risques à la vie privée fondée sur la k-anonymisation, mais plus contraignante. La l-diversité est appliquée à un jeu de données quand chaque groupe d’enregistrements qui partage une même série d’attributs démographiques comporte au moins « l » valeurs différentes pour chacune des variables confidentielles.
Données générées par des recherches qui examinent les aspects sociaux de la condition humaine en utilisant des méthodes descriptives plutôt que des mesures.
Fichier surtout utilisé par des sondeurs qui fournit des informations détaillées sur l'outil de sondage. Par exemple, on y retrouve les questions du sondage, les noms et définitions des variables utilisés pour coder les réponses du sondage, les valeurs acceptées pour chacune des variables, des statistiques sommaires pour chacune des questions, etc.
Terme qui décrit toutes les activités que les chercheuses et chercheurs effectuent pour structurer, organiser et préserver les données de recherche avant, pendant et après le processus de recherche.
Éléments d’information utilisés pour décrire le contenu ou le contenant d’une ressource. Elles peuvent être structurées ou non.
Données recueillies dans le cadre d’un travail de gestion administrative. Les données administratives peuvent être utilisées pour faire le suivi de personnes, d’achats, d’inscriptions, de prix, etc.
