Méthodes de travail avec les données de recherche
7 Le nettoyage de données dans le processus de gestion des données de recherche
Lucia Costanzo
Objectifs d’apprentissage
À la fin de ce chapitre, vous pourrez :
- Expliquer pourquoi il est important de nettoyer vos données.
- Vous rappeler les tâches courantes de nettoyage des données.
- Mettre en œuvre les tâches courantes de nettoyage des données en utilisant OpenRefine.
Qu’est-ce que le nettoyage des données?
Vous avez peut-être entendu parler de la règle du 80/20? La plupart des chercheuses et chercheurs consacrent 80% de leur temps à la recherche, au nettoyage et à la réorganisation de grandes quantités de données et seulement 20% de leur temps à analyser ces données.
En entamant un projet de recherche, vous utiliserez soit des données primaires générées à partir de vos propres expériences, soit des données secondaires issues des expériences d’une autre équipe de recherche. Une fois les données obtenues pour répondre à votre ou vos question(s) de recherche, vous aurez besoin de temps pour les examiner et les comprendre. Les données peuvent se retrouver dans des formats difficiles à analyser. Au cours de l’étape du nettoyage des données, vous utiliserez des pratiques de gestion des données de recherche (GDR). Le processus de nettoyage des données peut être long et fastidieux, mais il est essentiel pour assurer la précision et la qualité de votre recherche.
Le nettoyage des données peut sembler évident, mais c’est une étape où plusieurs chercheuses et chercheurs éprouvent des difficultés. George Fuechsel, un programmeur et instructeur de la compagnie IBM a été le premier à utiliser l’expression « garbage in, garbage out » (déchet qui entre, déchet qui sort) (Lidwell et al., 2010) pour rappeler à ses étudiantes et étudiants que l’ordinateur ne traite que ce qu’on lui donne – peu importe que l’information soit bonne ou mauvaise. Le même principe s’applique aux chercheuses et chercheurs; peu importe la qualité de vos méthodes, l’analyse ne dépend que de la qualité des données. Autrement dit, les résultats et conclusions d’une étude seront aussi fiables que les données utilisées.
L’utilisation de données nettoyées vous permet de ne pas perdre de temps en analyses inutiles.
Six actions principales de nettoyage et de préparation
Le nettoyage et la préparation des données peuvent se résumer à six actions principales : découvrir, structurer, nettoyer, enrichir, valider et publier. Elles sont menées tout au long du projet de recherche afin de maintenir l’organisation des données. Examinons chacune des actions de plus près.
1. Découvrir les données
Cette étape importante consiste à découvrir ce que les données peuvent révéler. Elle est désignée comme l’analyse exploratoire des données (AED). Le concept de l’AED a été développé dans les années 70 par le mathématicien américain John Tukey. D’après un mémoire, « Tukey a souvent comparé l’AED à un travail de détective. Le rôle de l’analyste de données est d’écouter les données de toutes les manières possibles jusqu’à ce qu’une histoire plausible se dégage des données[1] » [traduction] (Behrens, 1997). L’AED est une approche employée pour mieux comprendre les données par le biais de méthodes quantitatives et graphiques.
Les méthodes quantitatives synthétisent les caractéristiques des variables en utilisant des mesures de tendance centrale, dont le mode, la médiane et la moyenne arithmétique qui est la plus courante d’entre elles. Les mesures de dispersion indiquent à quelle distance du centre il est vraisemblable de retrouver des points de données. La variance, l’écart-type, l’étendue et l’écart interquartile constituent tous des mesures de dispersion. D’un point de vue quantitatif, la distribution peut être évaluée en utilisant une mesure d’asymétrie. Des histogrammes, des boîtes à moustaches et parfois aussi des diagrammes à tiges et à feuilles sont utilisés pour visualiser rapidement chacune des variables en fonction de la tendance centrale, de la dispersion, de la modalité, de l’étendue et des observations aberrantes.
L’examen des données par le biais de techniques d’AED permet d’identifier des tendances sous-jacentes et des anomalies, aide à établir des hypothèses et vérifie des suppositions liées à l’analyse. Examinons maintenant l’action de structurer les données.
2. Structurer les données
En fonction de la ou des question(s) de recherche, vous pourrez avoir à organiser les données de différentes façons pour différents types d’analyses. Prenons comme exemple les données par mesures répétées – quand chaque unité expérimentale ou sujet est mesuré à plusieurs moments ou dans différentes conditions.
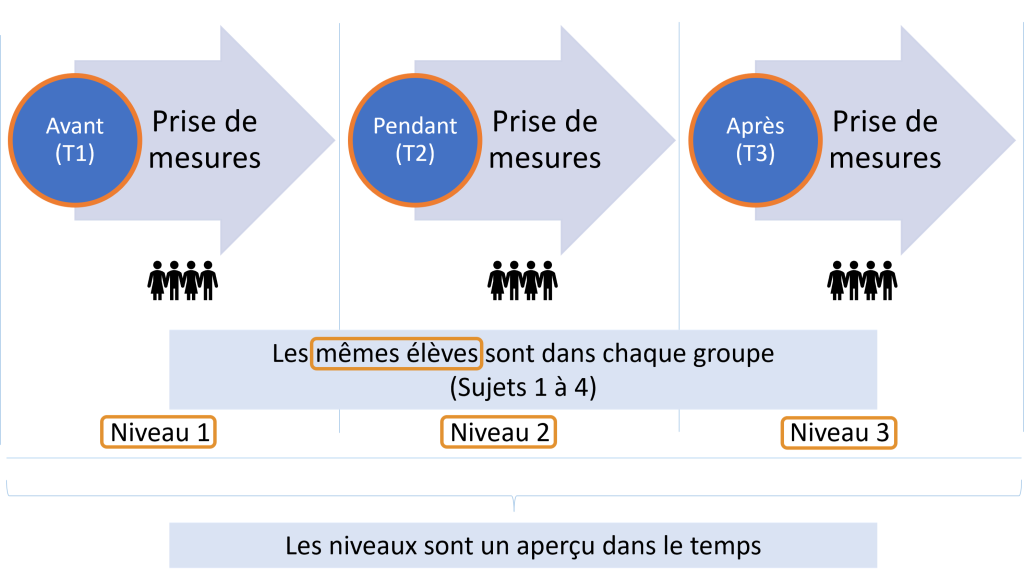
Imaginons, pour la figure 1, que des chercheuses étudient les effets d’un programme de petits-déjeuners auprès d’élèves de 6e année et qu’elles veulent recueillir des résultats de tests à trois moments différents, dont avant (T1), pendant (T2) et après (T3) la tenue du programme matinal. À noter que chaque groupe est constitué des mêmes élèves et que chaque élève est mesuré aux différents moments. Chaque mesure au cours de l’étude est un aperçu dans le temps. Il y a deux façons de structurer des données de mesures répétées : les formats longs et larges.
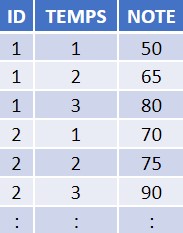
Le tableau 1 illustre des données structurées en format long avec chaque élève de l’étude représenté par trois rangées de données, une pour chacun des moments dans le temps où des résultats ont été recueillis. Dans la première rangée, Élève 1 au Temps 1 (avant le programme de petits-déjeuners) a eu un résultat de 50 pour le test. Dans la deuxième rangée, Élève 1 au Temps 2 (à mi-chemin du programme de petits-déjeuners) a eu un résultat plus élevé, de 65. Et dans la troisième rangée, Élève 1 au Temps 3 (après le programme) a obtenu un résultat de 80.
Le format large, tel qu’illustré par le tableau 2, utilise une seule rangée pour chacune des observations ou des personnes participantes, et chaque mesure ou résultat se trouve dans sa colonne distincte.
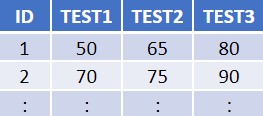
Dans le format large, l’ensemble des résultats des tests d’un seul élève se trouve dans la même rangée, et chaque résultat de test individuel de l’élève est dans sa propre colonne. En consultant la première rangée, Élève 1 a obtenu un résultat de 50 sur le test avant le programme de petits-déjeuners, il a ensuite obtenu 65 à mi-chemin du programme et 80 après le programme.
Bref, un format long de données utilise plusieurs rangées pour chaque observation ou personne participante, tandis que le format large de données utilise une rangée par observation. La façon de structurer vos données (format long ou large) sera déterminée par le modèle ou l’analyse statistique choisie. Il est possible que vous ayez à structurer vos données dans les deux formats pour réaliser vos objectifs d’analyse.
Structurer les données est une activité fondamentale de nettoyage et de préparation des données; l’étape vise à réorganiser les données en vue d’une analyse statistique particulière. Les données peuvent contenir des irrégularités ou des anomalies, ce qui peut avoir un impact sur la fiabilité des modèles de la chercheuse ou du chercheur. Examinons de plus près le nettoyage des données pour que votre analyse puisse fournir des résultats plus précis.
3. Le nettoyage des données
Le nettoyage des données est essentiel pour assurer la qualité de votre analyse. Les neuf conseils suivants abordent, à l’aide d’exemples pratiques, une série de problèmes couramment rencontrés lors du nettoyage des données.
Conseil no 1: la vérification de l’orthographe
 Le repérage de fautes de frappe ou de variations orthographiques est l’une des tâches les plus importantes dans le nettoyage des données. Vous pouvez utiliser un logiciel de vérification orthographique pour identifier et corriger les erreurs d’orthographe ou de saisie des données.
Le repérage de fautes de frappe ou de variations orthographiques est l’une des tâches les plus importantes dans le nettoyage des données. Vous pouvez utiliser un logiciel de vérification orthographique pour identifier et corriger les erreurs d’orthographe ou de saisie des données.
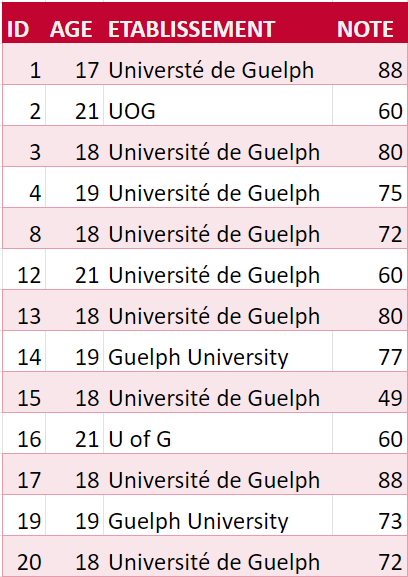
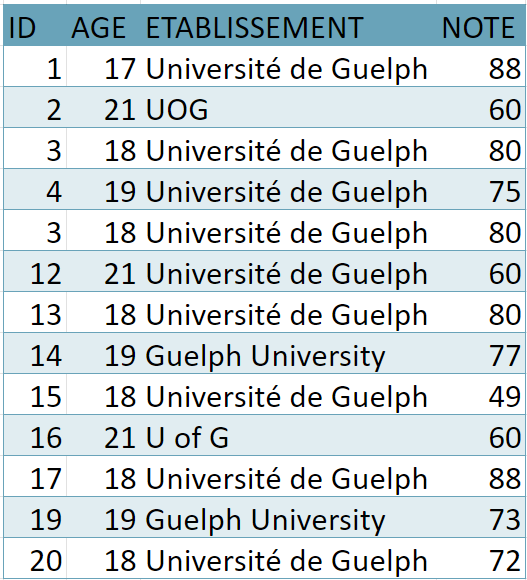
Ces logiciels de vérification peuvent aussi être utilisés pour uniformiser les noms propres. Si, par exemple, un jeu de données contient des entrées pour « Université de Guelph » et « UOG » et « U of G » et « Guelph University » (tableau 3), chaque variation orthographique sera considérée comme un établissement différent. L’orthographe choisie importe peu; l’important, c’est qu’elle soit uniforme à travers le jeu de données.
Exercice du conseil no 1 : la vérification orthographique
Parcourez le tableau 3 et uniformisez le nom dans la colonne ETABLISSEMENT à « Université de Guelph ».
Voir le solutionnaire pour les réponses. Les fichiers de données pour les exercices de ce chapitre sont disponibles (en anglais uniquement) dans le dépôt Borealis.
Conseil no 2: les doublons
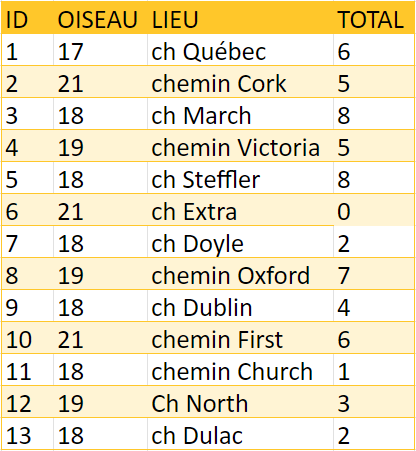
 Parfois, les données sont entrées ou générées manuellement en utilisant des méthodes qui peuvent entraîner des dédoublements de rangées. Vérifiez les rangées pour déterminer si certaines données sont en double et doivent être supprimées. Si chaque rangée comporte un numéro d’identification, celui-ci devrait être unique à chacune des observations. Dans cet exemple, deux observations ont le 3 comme numéro d’identification (tableau 4). Puisqu’elles ont toutes les deux des valeurs identiques, une des rangées devrait être supprimée.
Parfois, les données sont entrées ou générées manuellement en utilisant des méthodes qui peuvent entraîner des dédoublements de rangées. Vérifiez les rangées pour déterminer si certaines données sont en double et doivent être supprimées. Si chaque rangée comporte un numéro d’identification, celui-ci devrait être unique à chacune des observations. Dans cet exemple, deux observations ont le 3 comme numéro d’identification (tableau 4). Puisqu’elles ont toutes les deux des valeurs identiques, une des rangées devrait être supprimée.
Exercice du conseil no 2: les doublons
Parcourez le tableau 4 et supprimez les entrées en double.
Indice : Si vous utilisez Excel, cherchez et utilisez la fonction « Valeurs en double ».
Voir le solutionnaire pour les réponses.
Conseil no 3: trouver et remplacer
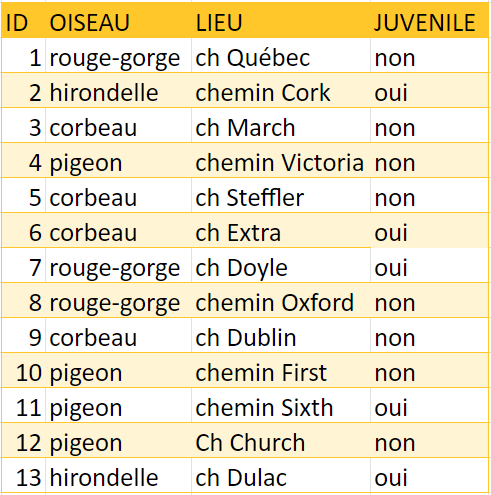
 Avec certains remplacements bien choisis, il est possible d’obtenir des données relativement propres et de les organiser dans une forme intéressante en cherchant des tendances ou des répétitions dans un fichier. Cet exemple illustre le nombre d’observations d’oiseaux dans la ville de Guelph. En consultant la colonne LIEU, les abréviations « ch » et « Ch » sont remplacées par le mot complet « chemin » (tableau 5). Cette opération s’effectue à l’aide de la fonction trouver et remplacer.
Avec certains remplacements bien choisis, il est possible d’obtenir des données relativement propres et de les organiser dans une forme intéressante en cherchant des tendances ou des répétitions dans un fichier. Cet exemple illustre le nombre d’observations d’oiseaux dans la ville de Guelph. En consultant la colonne LIEU, les abréviations « ch » et « Ch » sont remplacées par le mot complet « chemin » (tableau 5). Cette opération s’effectue à l’aide de la fonction trouver et remplacer.
Exercice du conseil no 3: trouver et remplacer
Parcourez le tableau 5. Trouvez et remplacez tous les « ch » et « Ch » avec « chemin » dans la colonne LIEU.
INDICE: Faites attention en utilisant la fonction trouver et remplacer. Dans l’exemple ci-dessous, il y a des instances où les lettres « ch » ou « Ch » NE ne se rapportent PAS au mot chemin (p. ex., « Church » ou « March »); ces données seront donc remplacées par erreur. Ce type de modification peut être évité en insérant un espace avant la chaîne que vous cherchez (donc, « (espace)ch »). Expérimentez aussi la fonction de respect de la casse (majuscules ou minuscules) si elle est disponible. Conservez toujours une copie de vos données originales en cas de problèmes.
Voir le solutionnaire pour les réponses.
Conseil no 4: majuscules et minuscules
 Le texte peut être tout en lettres minuscules, tout en majuscules ou seulement avoir une majuscule au début de chaque mot. Le texte peut être converti tout en minuscules, comme pour les adresses courriel; tout en majuscules, comme pour les abréviations de provinces, et dans les deux casses, comme pour les noms propres. Dans l’exemple de ce tableau, l’utilisation des majuscules et minuscules n’est pas uniforme. Parfois, les noms et courriels sont inscrits en majuscules, parfois en minuscules et parfois dans un format pour les noms propres (tableau 6).
Le texte peut être tout en lettres minuscules, tout en majuscules ou seulement avoir une majuscule au début de chaque mot. Le texte peut être converti tout en minuscules, comme pour les adresses courriel; tout en majuscules, comme pour les abréviations de provinces, et dans les deux casses, comme pour les noms propres. Dans l’exemple de ce tableau, l’utilisation des majuscules et minuscules n’est pas uniforme. Parfois, les noms et courriels sont inscrits en majuscules, parfois en minuscules et parfois dans un format pour les noms propres (tableau 6).
Exercice du conseil no 4: majuscules et minuscules
Dans la colonne NOM du tableau 6, modifiez le texte en remplaçant la première lettre du prénom et du nom avec une majuscule. Convertissez ensuite le texte dans la colonne COURRIEL à des lettres minuscules.
INDICE: Si vous utilisez Excel, cherchez les fonctions MAJUSCULE, MINUSCULE et NOMPROPRE.

Voir le solutionnaire pour les réponses.
Conseil no 5: espaces et caractères qui ne s’impriment pas
 Les espaces et les caractères qui ne s’impriment pas peuvent avoir des résultats imprévus quand vous effectuez des fonctions de tri, de filtrage ou de recherche. Les espaces en début ou en fin de mot, de multiples espaces intercalés ou les caractères qui ne s’impriment pas sont tous invisibles. Ils peuvent se faufiler lorsque vous importez des données à partir de pages Web, de documents Word ou PDF.
Les espaces et les caractères qui ne s’impriment pas peuvent avoir des résultats imprévus quand vous effectuez des fonctions de tri, de filtrage ou de recherche. Les espaces en début ou en fin de mot, de multiples espaces intercalés ou les caractères qui ne s’impriment pas sont tous invisibles. Ils peuvent se faufiler lorsque vous importez des données à partir de pages Web, de documents Word ou PDF.
Conseil no 6: chiffres et signes
Il y a deux éléments à surveiller :
- les données peuvent comprendre du texte
- le signe négatif peut ne pas être standardisé
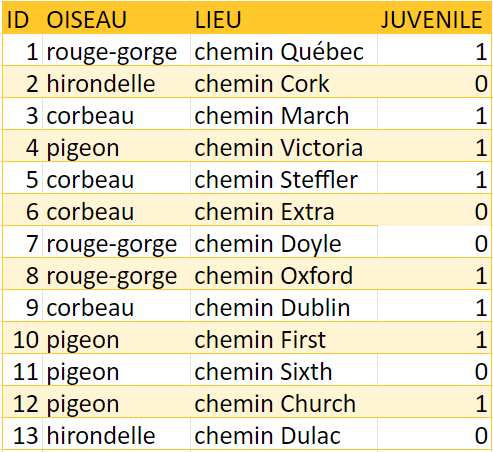
 Vous pourriez obtenir un jeu de données qui comporte des variables définies comme des chaînes de caractères (elles peuvent inclure des chiffres, des lettres ou des symboles). Les fonctions numériques, comme les additions et les soustractions, ne peuvent pas être utilisées avec les variables en chaîne. Pour pouvoir effectuer une analyse quantitative des données, vous devez donc convertir les valeurs d’un format en chaîne à des valeurs numériques. Le tableau des observations d’oiseaux (tableau 7) comporte une colonne indiquant s’il s’agit d’un oiseau juvénile. Pour une analyse quantitative des données, vous devrez convertir toutes les valeurs en chaîne « non » à la valeur numérique 0 ainsi que les valeurs en chaîne « oui » à la valeur numérique 1. Laissez telle quelle la colonne originale JUVENILE en guise de référence et créez une nouvelle colonne avec les valeurs numériques. La colonne originale ne sert qu’à vérifier la transformation de la nouvelle colonne et pourra ensuite être supprimée lorsque la transformation sera jugée complète et exacte. Dans cet exemple, la nouvelle colonne JUVENILE_NUM contient les valeurs numériques qui correspondent aux valeurs en chaîne de la colonne JUVENILE (l’exercice du conseil no 6 illustre cet exemple).
Vous pourriez obtenir un jeu de données qui comporte des variables définies comme des chaînes de caractères (elles peuvent inclure des chiffres, des lettres ou des symboles). Les fonctions numériques, comme les additions et les soustractions, ne peuvent pas être utilisées avec les variables en chaîne. Pour pouvoir effectuer une analyse quantitative des données, vous devez donc convertir les valeurs d’un format en chaîne à des valeurs numériques. Le tableau des observations d’oiseaux (tableau 7) comporte une colonne indiquant s’il s’agit d’un oiseau juvénile. Pour une analyse quantitative des données, vous devrez convertir toutes les valeurs en chaîne « non » à la valeur numérique 0 ainsi que les valeurs en chaîne « oui » à la valeur numérique 1. Laissez telle quelle la colonne originale JUVENILE en guise de référence et créez une nouvelle colonne avec les valeurs numériques. La colonne originale ne sert qu’à vérifier la transformation de la nouvelle colonne et pourra ensuite être supprimée lorsque la transformation sera jugée complète et exacte. Dans cet exemple, la nouvelle colonne JUVENILE_NUM contient les valeurs numériques qui correspondent aux valeurs en chaîne de la colonne JUVENILE (l’exercice du conseil no 6 illustre cet exemple).
Les chiffres peuvent être formatés de différentes façons, surtout pour les données financières. Par exemple, les valeurs négatives peuvent être représentées avec un trait d’union, placées à l’intérieur de parenthèses ou même surlignées en rouge. Ces valeurs négatives ne pourront pas toutes être lues par un ordinateur, notamment quand il s’agit de couleur. En nettoyant les données, choisissez et appliquez une approche claire et uniforme pour le formatage de toutes les valeurs négatives. Le signe négatif est le choix le plus courant.
Exercice du conseil no 6: chiffres et signes
Créez une nouvelle colonne intitulée JUVENILE_NUM dans le tableau 7. Inscrivez une valeur de 0 dans cette nouvelle colonne quand « non » apparaît dans la colonne JUVENILE. Inscrivez une valeur de 1 dans cette même colonne quand « oui » apparaît dans la colonne JUVENILE.
Voir le solutionnaire pour les réponses.
Conseil no 7: date et heure
 Il y a de nombreuses façons de formater les dates d’un jeu de données. Elles sont parfois formatées en chaîne. Mais si les données de dates sont nécessaires à des fins d’analyse, le type de champ devrait être changé de « chaîne » à « date » pour que les dates puissent être reconnues dans l’outil d’analyse choisi. Pour les valeurs liées à l’heure, vous devrez choisir une convention et l’appliquer uniformément à travers le jeu de données. Par exemple, vous pouvez choisir d’utiliser l’horloge de 12 ou de 24 heures pour préciser l’heure dans votre jeu de données. Peu importe ce que vous choisissez, vous devez veiller à ce que l’application se fasse uniformément. Vous pouvez aussi avoir à modifier un format pour vous assurer que tous les formats de date et d’heure sont uniformes.
Il y a de nombreuses façons de formater les dates d’un jeu de données. Elles sont parfois formatées en chaîne. Mais si les données de dates sont nécessaires à des fins d’analyse, le type de champ devrait être changé de « chaîne » à « date » pour que les dates puissent être reconnues dans l’outil d’analyse choisi. Pour les valeurs liées à l’heure, vous devrez choisir une convention et l’appliquer uniformément à travers le jeu de données. Par exemple, vous pouvez choisir d’utiliser l’horloge de 12 ou de 24 heures pour préciser l’heure dans votre jeu de données. Peu importe ce que vous choisissez, vous devez veiller à ce que l’application se fasse uniformément. Vous pouvez aussi avoir à modifier un format pour vous assurer que tous les formats de date et d’heure sont uniformes.
Conseil no 8: fusionner et fractionner les colonnes
 Après un examen approfondi d’un nouveau jeu de données, il est possible de soit (1) fusionner deux colonnes ou plus en une seule ou (2) de fractionner une colonne en deux ou plus. Conservez les colonnes originales qui ont été utilisées pour fusionner ou fractionner les colonnes. Utilisez ensuite les colonnes originales pour vérifier la transformation de la nouvelle colonne et supprimez l’originale lorsque la transformation est confirmée comme étant exacte. Par exemple, vous pouvez vouloir fractionner une colonne qui contient le nom complet en deux colonnes; une pour le prénom et l’autre, le nom de famille (tableau 8). Ou vous pouvez vouloir fractionner la colonne qui comporte l’adresse en colonnes distinctes pour la rue, la ville, la région et le code postal. L’inverse peut aussi s’appliquer; vous pouvez vouloir fusionner les colonnes du prénom et du nom de famille en une seule ou combiner les colonnes pour l’adresse.
Après un examen approfondi d’un nouveau jeu de données, il est possible de soit (1) fusionner deux colonnes ou plus en une seule ou (2) de fractionner une colonne en deux ou plus. Conservez les colonnes originales qui ont été utilisées pour fusionner ou fractionner les colonnes. Utilisez ensuite les colonnes originales pour vérifier la transformation de la nouvelle colonne et supprimez l’originale lorsque la transformation est confirmée comme étant exacte. Par exemple, vous pouvez vouloir fractionner une colonne qui contient le nom complet en deux colonnes; une pour le prénom et l’autre, le nom de famille (tableau 8). Ou vous pouvez vouloir fractionner la colonne qui comporte l’adresse en colonnes distinctes pour la rue, la ville, la région et le code postal. L’inverse peut aussi s’appliquer; vous pouvez vouloir fusionner les colonnes du prénom et du nom de famille en une seule ou combiner les colonnes pour l’adresse.
Exercice du conseil no 8: fusionner et fractionner les colonnes
Dans le tableau 8, fractionnez la colonne du NOM en deux; une pour le prénom et l’autre, pour le nom de famille.
CONSEIL : Avec Excel, cherchez les fonctions pour combiner le texte de plusieurs cellules en une seule et pour fractionner le texte en différentes colonnes.

Voir le solutionnaire pour les réponses.
Conseil no 9: données d’un sous-ensemble
 Certains fichiers de données peuvent parfois contenir des informations qui ne sont pas nécessaires à l’analyse; vous pourriez donc vouloir créer un nouveau fichier qui comporte uniquement les variables ou les observations qui vous intéressent. Vous aurez donc à faire une élimination sélective des colonnes ou des rangées superflues. Dans cet exemple, le chercheur a retiré la colonne JUVENILE (tableau 9). Vous pouvez également avoir besoin d’analyser uniquement certaines observations dans le fichier, ce qui vous permet de supprimer certaines rangées du jeu de données. Dans ce tableau, toutes les observations en lien avec les hirondelles seront éliminées. L’avantage de ce type de nettoyage, c’est qu’il limite la grosseur du fichier de données, permettant ainsi aux logiciels de fonctionner plus efficacement.
Certains fichiers de données peuvent parfois contenir des informations qui ne sont pas nécessaires à l’analyse; vous pourriez donc vouloir créer un nouveau fichier qui comporte uniquement les variables ou les observations qui vous intéressent. Vous aurez donc à faire une élimination sélective des colonnes ou des rangées superflues. Dans cet exemple, le chercheur a retiré la colonne JUVENILE (tableau 9). Vous pouvez également avoir besoin d’analyser uniquement certaines observations dans le fichier, ce qui vous permet de supprimer certaines rangées du jeu de données. Dans ce tableau, toutes les observations en lien avec les hirondelles seront éliminées. L’avantage de ce type de nettoyage, c’est qu’il limite la grosseur du fichier de données, permettant ainsi aux logiciels de fonctionner plus efficacement.
Exercice du conseil no 9: données d’un sous-ensemble
Créez un sous-ensemble de données dans le tableau 9 pour inclure uniquement les observations de juvéniles (JUVENILE =1).
CONSEIL: Comme toujours, il est important de conserver une copie de vos données originales.
Voir le solutionnaire pour les réponses.
Le nettoyage des données est une action importante qui mise sur l’élimination d’incohérences et d’erreurs qui peuvent avoir un impact sur la précision des modèles. Le processus de nettoyage des données donne aussi l’occasion d’examiner les données de plus près afin de déterminer si des modifications sont nécessaires, si les données doivent être codées différemment ou s’il y a lieu d’ajouter des données supplémentaires.
4. Enrichir les données
Un jeu de données peut parfois contenir des informations manquantes, ce qui nuit à la capacité de bien répondre à la question de recherche. Vous pourrez donc avoir à chercher d’autres jeux de données pour les fusionner à vos données. Il peut s’agir d’ajouter des données géographiques, telles qu’un code postal ou des coordonnées de longitude et de latitude, ou de données démographiques, telles que le revenu, l’état civil, l’éducation, l’âge ou le nombre d’enfants. L’enrichissement des données permet d’obtenir des réponses plus complètes à vos questions de recherche.
Il est également important de vérifier la qualité et l’uniformité des données dans le jeu de données. Examinons maintenant la validation des données pour que vos modèles puissent fournir des résultats plus précis.
5. Valider les données
La validation des données est essentielle pour assurer la propreté, l’exactitude et l’utilité des données. Rappelez-vous l’adage de Fuechsel: « garbage in, garbage out ». Si des données inexactes sont intégrées à une analyse statistique, les réponses qui en découlent seront elles aussi inexactes. Un logiciel n’est pas doté de raison et ne peut traiter que les données qu’il reçoit, qu’elles soient bonnes ou mauvaises. Bien que la validation des données soit fastidieuse, elle permet d’optimiser la capacité des données à répondre aux questions de recherche posées. Voici quelques vérifications couramment utilisées pour valider des données :
- Vérifier les types de données des colonnes et les données sous-jacentes pour s’assurer qu’ils sont bien ce qu’ils sont censés être. Par exemple, une variable de date peut avoir besoin d’être convertie d’un format en chaîne à un format de date. En cas de doute, mieux vaut convertir la valeur à un format en chaîne; elle pourra être modifiée plus tard, au besoin.
- Examiner l’étendue et l’exactitude des données en en passant en revue les principales fonctions d’agrégation telles que la somme, le décompte, le minimum, le maximum, la moyenne ou d’autres opérations connexes. Cette étape est particulièrement importante dans le contexte de l’analyse des données. Par exemple, Statistiques Canada peut attribuer des codes aux valeurs manquantes pour l’âge en utilisant des chiffres bien au-delà de l’échelle d’âge de la vie humaine (p. ex., en utilisant un chiffre comme 999). Si ces valeurs sont incluses par inadvertance dans l’analyse (en raison des « valeurs manquantes » qui n’ont pas été clairement identifiées), tout résultat lié à l’âge sera erroné. Faire le calcul et la révision de la moyenne, du minimum, du maximum, etc. aidera à identifier et à éviter de telles erreurs.
- S’assurer que les variables sont normalisées. Par exemple, en enregistrant les coordonnées de longitude et de latitude pour les emplacements en Amérique du Nord, vérifiez que les coordonnées de latitude soient positives et que celles de longitude soient négatives pour éviter de désigner par erreur des endroits de l’autre côté du globe.
La validation des données est importante pour assurer la qualité et l’uniformité. Une fois toutes les questions de recherche répondues, les bonnes pratiques prônent le partage des données nettoyées avec d’autres équipes de recherche, conformément aux ententes de confidentialité ou tout autre type de restrictions. Examinons maintenant l’étape de la publication des données, ce qui leur permet d’être partagées avec d’autres chercheuses et chercheurs.
6. Publier les données
Après tout l’effort déployé au nettoyage et à la validation des données, ainsi qu’à l’examen approfondi de votre question de recherche, une des meilleures pratiques en GDR est de rendre vos données disponibles à d’autres qui souhaitent les utiliser à leur tour. Cet objectif est incarné dans les principes FAIR, abordés ailleurs dans ce manuel; ces principes visent à rendre les données faciles à trouver, accessibles, interopérables et réutilisables. La publication des données permet de réaliser cet objectif.
Les logiciels propriétaires peuvent être utiles pour la collecte, la gestion et l’analyse des données, mais les données devraient être enregistrées dans des formats ouverts à l’étape de la publication. Généralement, des fichiers texte sont utilisés. Pour les tableurs et feuilles de calculs simples, le meilleur format pour la conversion des données est le CSV (comma separated values) tandis que le langage XML est mieux adapté aux structures de données plus complexes. Ainsi, les fichiers sont protégés contre l’obsolescence rapide des formats et un accès plus universel aux données est assuré pour d’autres équipes de recherche. Pour en savoir plus, consultez le chapitre 9, « Un aperçu du fascinant monde des formats de fichiers et des métadonnées. »
Si vos données impliquent des êtres humains ou des renseignements confidentiels, vous pourrez avoir à anonymiser ou à dépersonnaliser vos données (le sujet est abordé plus en détail dans le chapitre 13, « Les données sensibles » ). Gardez à l’esprit que la suppression des références explicites à des personnes ne garantit pas qu’elles ne pourront pas être identifiées. Si la divulgation non voulue de renseignements personnels est impossible, vous devrez peut-être publier un sous-ensemble des données qui, lui, sera sans danger pour les personnes participantes.
Pour que d’autres équipes de recherche puissent utiliser les données, ajoutez de la documentation et des métadonnées, incluant de la documentation au niveau du projet, des fichiers de données et des éléments de données. Un dictionnaire des données établit le nommage, la définition et les attributs des éléments d’un jeu de données; le sujet est discuté au chapitre 10. Vous devriez aussi documenter les scripts et les méthodes qui ont été développés pour l’analyse des données.
Logiciel de nettoyage des données
OpenRefine (https://openrefine.org/ ) est un puissant outil de manipulation des données qui nettoie, réorganise et fait l’édition en lot des données qui manquent d’ordre ou de structure. Il fonctionne mieux avec des données en format tabulaire simple, notamment les feuilles de calcul dont les valeurs sont séparées par des virgules (CSV) ou des tabulations (TSV). OpenRefine est aussi simple à utiliser que Excel et dispose de puissantes fonctions de bases de données comme Microsoft Access. Il s’agit d’une application de bureau qui utilise un navigateur Web comme interface graphique. Tout traitement des données se fait localement à même votre ordinateur. En utilisant OpenRefine pour nettoyer et transformer les données, il est possible de filtrer par facette, regrouper, modifier des cellules, faire des concordances et utiliser des services Web plus approfondis pour convertir un jeu de données en format plus structuré. Ce logiciel ouvert est gratuit et le code source est librement accessible, de même que les modifications apportées par d’autres. Il y a d’autres outils de nettoyage des données disponibles, mais ils sont souvent coûteux. En plus, OpenRefine est largement utilisé dans le domaine de la GDR. Si vous choisissez d’autres logiciels de nettoyage des données, vérifiez toujours si vos données restent sur votre ordinateur ou si elles sont envoyées ailleurs pour être traitées.
Exercice: nettoyer et préparer les données pour l’analyse avec OpenRefine
Le tutoriel « Nettoyer ses données avec OpenRefine » vous permet de télécharger un jeu de données du Powerhouse Museum composé de métadonnées détaillées sur les objets de la collection dont le titre, la description, les catégories auxquelles les objets appartiennent, des informations sur la provenance et un lien permanent vers l’objet sur le site Web du musée. Vous effectuerez plusieurs tâches de nettoyage des données.
Conclusion
Nous avons examiné les six actions principales de nettoyage et de préparation des données, soit: découvrir, structurer, nettoyer, enrichir, valider et publier. En appliquant ces pratiques importantes en GDR, vos données seront plus complètes, documentées et accessibles, aussi bien à vous qu’à d’autres chercheuses et chercheurs. Vous répondrez aux exigences des publications savantes et/ou des organismes subventionnaires, vous rehausserez votre profil de chercheuse ou chercheur et vous répondrez aux attentes toujours croissantes de la communauté de recherche en matière de partage des données. Les pratiques de GDR, telles que le nettoyage des données, sont essentielles pour assurer des recherches précises et de grande qualité.
Éléments clés à retenir
- Le nettoyage des données est une tâche importante qui améliore l’exactitude et la qualité des données en amont de l’analyse des données.
- Les six tâches principales de nettoyage des données sont : découvrir, structurer, nettoyer, enrichir, valider et publier.
- OpenRefine est un puissant outil de manipulation des données qui nettoie, réorganise et fait l’édition en lot des données qui manquent d’ordre ou de structure.
Bibliographie
Behrens, J. T. (1997). Principles and procedures of exploratory data analysis. Psychological Methods, 2(2), 131.
Lidwell, W., Holden, K. et Butler, J. (2010). Universal principles of design, revised and updated: 125 ways to enhance usability, influence perception, increase appeal, make better design decisions, and teach through design. Rockport Publishers.
- "Tukey often likened EDA to detective work. The role of the data analyst is to listen to the data in as many ways as possible until a plausible ‘story’ of the data is apparent" ↵
Terme qui décrit toutes les activités que les chercheuses et chercheurs effectuent pour structurer, organiser et préserver les données de recherche avant, pendant et après le processus de recherche.
Processus qui vise à identifier et corriger les données altérées, inexactes ou non pertinentes. Cette étape fondamentale du traitement des données améliore la cohérence, la fiabilité et la valeur des données. (Talend, s.d.).
Processus utilisé pour explorer, analyser et synthétiser des jeux de données au moyen de méthodes quantitatives et graphiques. L'analyse exploratoire des données aide à faire ressortir des patrons et facilite la découverte d'irrégularités et d'incohérences dans un jeu de données.
FAIR est un acronyme qui signifie facile à trouver, accessible, interopérable et réutilisable. Les principes directeurs FAIR ont été élaborés en 2014 et visent à améliorer la réutilisation des données, tant par les machines que par les personnes.
Capacité des données ou des outils provenant de ressources non coopératives à travailler ou à communiquer entre eux avec un minimum d'effort et en utilisant un langage commun. L'interopérabilité exige que les données et les métadonnées utilisent des formats normalisés, accessibles et largement utilisés. Par exemple, lors de la sauvegarde de données tabulaires, il est recommandé d'utiliser un fichier CSV plutôt qu'un fichier propriétaire tel que XLSX (Excel). Un fichier CSV peut être ouvert et lu par davantage de logiciels qu'un fichier XLSX.
Fichier texte délimité qui utilise la virgule pour séparer les valeurs d’un enregistrement de données. Chaque ligne du fichier correspond à un enregistrement de données.
Éléments d’information utilisés pour décrire le contenu ou le contenant d’une ressource. Elles peuvent être structurées ou non.
Outil de manipulation de données à code source libre qui nettoie, remodèle et édite par lots les données désordonnées et non structurées.
Informations intégrées à des tableaux avec des rangées et des colonnes.
Fichier texte délimité qui utilise une tabulation pour séparer les valeurs. Chaque ligne du fichier correspond à un enregistrement de données.
Lorsque du code ou un logiciel est ouvert ou en source libre, les personnes qui l’utilisent sont autorisées à inspecter, utiliser, modifier, améliorer et redistribuer le code sous-jacent. Plusieurs programmeuses et programmeurs utilisent la licence MIT lors de la publication de leur code, ce qui implique que toutes les itérations ultérieures du logiciel incluent également la licence MIT.
