Méthodes de travail avec les données de recherche
8 Nouvelles aventures en nettoyage des données: travailler avec des données dans Excel et R
Dr. Rong Luo et Berenica Vejvoda
Objectifs d’apprentissage
À la fin de ce chapitre, vous pourrez :
- Expliquer les procédures générales pour se préparer au nettoyage des données.
- Effectuer les tâches courantes de nettoyage des données à l’aide d’Excel.
- Importer des données et effectuer les tâches de base de nettoyage des données à l’aide du langage de programmation R.
Introduction
Le nettoyage des données est une partie essentielle du processus de recherche. Au cours du chapitre précédent, quelques tâches de bases courantes de nettoyage des données vous ont été présentées. Dans ce chapitre-ci, nous examinerons plus en profondeur l’exploration, la manipulation et le nettoyage des données en utilisant quelques outils de recherche flexibles et polyvalents. Dans certains cas, ces outils sont les mêmes qu’utilisent les chercheuses et chercheurs pour l’analyse de leurs données; il est donc utile que les personnes responsables de la curation et de la gestion des données les connaissent.
Les procédures générales pour se préparer au nettoyage des données
Si vous ne faites aucune préparation avant le processus de nettoyage des données, vous prenez le risque de rencontrer de graves problèmes, notamment la perte de vos données. Au cours de cette section, nous discuterons des étapes générales qui devraient être appliquées avant le processus de nettoyage des données.
Faire une copie de sauvegarde
Les pratiques de gestion des données de recherche (GDR) recommandent la création d’une sauvegarde sécurisée de vos données pour assurer que les données originales puissent toujours être restaurées en cas de modifications erronées survenues au cours du processus de nettoyage. Cette copie de sauvegarde des données originales ne devrait en aucun cas être modifiée. Vous devriez aussi tenir un registre / journal de tous les changements effectués. Vous seriez surpris d’apprendre combien de chercheuses et chercheurs créent des erreurs dans leurs données originales en tentant de les « améliorer ». Si une personne a besoin d’un accès aux données originales, vous devriez envoyer ou partager seulement une copie des données, sinon permettre l’accès aux données originales en lecture seule.
Comprendre les données
La première étape du nettoyage des données est de comprendre les données à nettoyer. Pour les comprendre, il faut commencer par faire une exploration de base des données (ou une analyse exploratoire des données) pour se faire une idée des problèmes qui pourraient exister à l’intérieur des données. Vérifiez les valeurs des données par rapport à leur définition dans le fichier de métadonnées ou la documentation pour déceler des valeurs impossibles ou qui sortent des limites (p. ex., un âge négatif ou de plus de 200 ans). Assurez-vous d’avoir des noms pratiques pour les colonnes de données et de bien les comprendre. Vérifiez les délimiteurs qui séparent les valeurs dans vos fichiers texte et assurez-vous que les valeurs de vos données n’intègrent pas le délimiteur lui-même. Si vos observations ne sont pas numérotées, vous devriez ajouter un numéro d’enregistrement unique aux observations individuelles dans votre jeu de données pour que vous puissiez plus facilement repérer les enregistrements problématiques en vous rapportant à leur numéro.
Planifier le processus de nettoyage
Le nettoyage des données doit être fait de façon systématique pour garantir que toutes les données soient nettoyées à l’aide des mêmes procédures. Ainsi, l’intégrité des données est assurée et les données peuvent être plus facilement traitées pendant l’analyse. Pour créer un plan de nettoyage d’un champ particulier dans un jeu de données, posez-vous les trois questions suivantes :
- Quelles sont les données que vous nettoyez?
- Comment allez-vous identifier un problème dans le jeu de données à nettoyer?
- Comment le champ devrait-il être nettoyé?
Choisir les bons outils
Une des étapes les plus importantes du nettoyage des données est de choisir le bon outil en fonction d’un objectif précis. Le chapitre précédent a présenté OpenRefine, un outil spécialisé et pratique pour le nettoyage des données. Ici, nous discuterons de deux outils logiciels puissants et polyvalents – Excel et R – et nous soulignerons quelques-unes des caractéristiques de nettoyage de chacun d’eux.
Les outils de nettoyage des données
L’outil de nettoyage des données que vous choisirez dépendra de différents facteurs, dont votre environnement informatique, votre expertise en matière de programmation et des exigences en lien avec la préparation de vos données. Il existe une grande variété de choix de logiciels et de méthodes pour le nettoyage et la transformation des données. Nous examinerons Excel et Google Sheets ainsi que le langage de programmation R.
Microsoft Excel/Google Sheets
Excel et Google Sheets sont d’excellents outils de nettoyage des données et contiennent une variété de fonctionnalités et de caractéristiques intégrées pour automatiser le nettoyage de vos données. Excel est largement disponible en programme de bureau tant pour Windows et MacOs alors que Google Sheets est disponible en ligne. Ils se ressemblent et sont faciles à apprendre, utiliser et comprendre. Ils peuvent tous deux importer et exporter le format très courant de fichier de données CSV et autres formats courants de tableur. Lors de l’exportation, vérifiez que les noms des colonnes de données exportées sont utilisables puisque certains progiciels statistiques peuvent avoir de la difficulté à traiter les noms de colonnes qui contiennent des espaces ou des caractères spéciaux. Les techniques courantes de nettoyage des données utilisées dans Excel et Google Sheets pour l’édition et la manipulation sont résumées dans le tableau ci-dessous.
| Fonction | Description |
| = CONCATENER (ou CONCAT dépendamment de votre version Excel) | Permet de joindre plusieurs colonnes. |
| = SUPPRESPACE | Supprime tous les espaces d’une chaîne de texte, à l’exception des espaces simples entre les mots. |
| = GAUCHE | Renvoie le ou les premier(s) caractère(s) d’une chaîne de texte en fonction du nombre de caractères que vous spécifiez. |
| = DROITE | Renvoie le ou les dernier(s) caractère(s) d’une chaîne de texte en fonction du nombre de caractères que vous spécifiez. |
| = STXT | Renvoie un nombre donné de caractères d’une chaîne de texte, à partir d’une position que vous spécifiez, en fonction du nombre de caractères que vous spécifiez. |
| = MINUSCULE | Convertit toutes les lettres d’une chaîne de texte en lettres minuscules. |
| = MAJUSCULE | Convertit toutes les lettres d’une chaîne de texte en lettres majuscules. |
| = NOMPROPRE | Convertit une chaîne de texte à un format de nom propre pour que la première lettre de chaque mot soit en majuscule et les lettres qui suivent en minuscules. |
| = VALEURNOMBRE | Convertit une chaîne de texte en nombre. |
| = TEXTE | Convertit un nombre au format texte. |
| = SUBSTITUE | Remplace un texte précis dans une chaîne de texte. |
| = REMPLACER | Remplace une partie d’une chaîne de texte, selon la position et le nombre de caractères précisés, avec une chaîne de texte différente. |
| = EPURAGE | Supprime tous les caractères non imprimables d’une chaîne de texte. |
| = DATE | Renvoie le nombre qui représente la date dans le code date-heure de Microsoft Excel. |
| = ARRONDI | Arrondi le nombre d’une cellule précise à un nombre spécifié de chiffres. |
| = TROUVE | Renvoie la position initiale d’une chaîne de texte dans une autre chaîne de texte. TROUVE est sensible à la casse. |
| = CHERCHE | Renvoie le numéro de la position initiale d’un caractère spécifique ou d’une chaîne de texte dans une autre chaîne de texte, en lisant de gauche à droite (non sensible à la casse). |
Pour comprendre certaines de ces fonctions, nous examinerons une variété d’erreurs courantes qui surviennent lors de l’importation des données incluant des sauts de lignes à la mauvaise place, des espaces de trop ou aucun espace entre les mots, des majuscules à la mauvaise place ou toutes les lettres en majuscules/minuscules, des valeurs de données mal formatées et des caractères non imprimables.

La figure 1 illustre des combinaisons de CONCATENER ET SUPPRESPACE imbriquées de différentes manières pour trouver la meilleure configuration de sortie selon la façon dont vous voulez que le texte apparaisse[1]. Il s’agit d’un exemple sur la façon de générer une simple ligne de texte à partir du contenu de trois rangées en imbriquant deux fonctions Excel. CONCATENER rassemble les trois cellules en une seule, mais elle n’agit pas sur les espaces supplémentaires que vous voyez dans le texte. SUPPRESPACE supprime tous les espaces à l’exception d’un seul espace entre les mots, mais la fonction ne peut pas ajouter d’autres espaces nécessaires. Nous avons donc besoin d’ajouter des guillemets pour permettre à Excel d’ajouter les espaces nécessaires entre les mots.

Les fonctions GAUCHE, DROITE et STXT de la figure 2 montrent de quelle façon des données peuvent être traitées selon l’endroit dans la chaîne où se trouve le texte ou les numéros à extraire.
Les rangées 11 et 12 illustrent la façon d’utiliser la fonction STXT pour extraire des numéros à l’intérieur d’une chaîne de texte. La fonction STXT utilise trois arguments : une référence à la chaîne avec laquelle vous travaillez, la position du premier caractère à extraire et le nombre de caractères à extraire. Alors STXT(A11,4,3) regarde d’abord le contenu de la cellule A11 et trouve la chaîne « BUS256XD », ensuite elle renvoie les 3 caractères en partant du quatrième caractère : 256. Les données du C11 et C12 sont le résultat de la fonction STXT dans les rangées 11 et 12.
Les fonctions GAUCHE et DROITE ne nécessitent que deux arguments : la chaîne et le point de départ. Ces fonctions renvoient ensuite le reste de la chaîne, en partant soit de la gauche ou de la droite. C13 et C14 illustrent des portions de cellules extraites de A13 et A14 en utilisant les fonctions DROITE et GAUCHE.
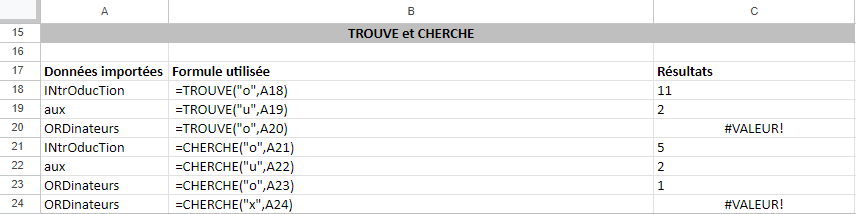
La figure 3 illustre la différence entre les fonctions TROUVE et CHERCHE. Dans Excel, TROUVE est utilisé pour renvoyer la position d’un caractère ou d’une sous-chaîne spécifique à l’intérieur d’une chaîne de texte; la fonction respecte la casse. La fonction CHERCHE revoie également la position d’un caractère ou d’une sous-chaîne à l’intérieur d’une chaîne de texte. Contrairement à TROUVE, la fonction CHERCHE ne respecte pas la casse. Les deux fonctions renvoient le message d’erreur #VALEUR! si le caractère ou la sous-chaîne spécifique n’apparaît pas dans le texte.

La figure 4 démontre de quelle façon les fonctions MAJUSCULE, MINUSCULE et NOMPROPRE sont utilisées pour ajuster les données. La fonction MAJUSCULE modifie tout le texte en lettres majuscules. La fonction MINUSCULE modifie tout le texte en minuscule. Et la fonction NOMPROPRE modifie la première lettre de chaque mot en majuscule avec toutes les autres en minuscules, ce qui est utile avec des noms propres.

Excel fait l’alignement des chaînes de caractères d’une colonne en fonction de la façon dont elles sont stockées : le texte (y compris des numéros stockés en tant que texte) est aligné à gauche tandis que les numéros sont alignés à droite. Dans la figure 5, la fonction VALEURNOMBRE convertit le texte qui apparaît dans un format reconnu (tel que des formats de numéro, de date ou d’heure) en une valeur numérique. Si un texte ne se retrouve pas dans l’un de ces formats, VALEURNOMBRE renvoie le message d’erreur #VALEUR!. La fonction TEXTE permet de modifier l’affichage d’un nombre en appliquant des codes de format, ce qui est utile dans les situations où vous souhaitez afficher des nombres dans un format plus lisible. Par contre, Excel considère désormais le numéro comme du texte, de sorte que l’exécution de calculs sur ces données risque de ne pas fonctionner ou de donner des résultats inattendus. Il est préférable de conserver la valeur originale dans une cellule, puis d’utiliser la fonction TEXTE pour créer une copie formatée du numéro dans une autre cellule.

La figure 6 illustre la façon dont la fonction SUBSTITUE remplace une ou plusieurs chaînes de texte avec une autre chaîne. Cette fonction est utile si vous voulez substituer une ancienne version de texte d’une chaîne avec une nouvelle version. Toutefois, elle ne respecte pas la casse. Par exemple, dans la cellule A41, la fonction ne remplacera pas « t » pour « T » dans « Taxe ». La fonction SUBSTITUE est différente de REMPLACER; vous utilisez SUBSTITUE pour remplacer des caractères spécifiques, peu importe où ils se trouvent dans la chaîne de texte, tandis que vous utilisez REMPLACER pour remplacer tout caractère qui se trouve dans une position particulière d’une chaîne de texte.
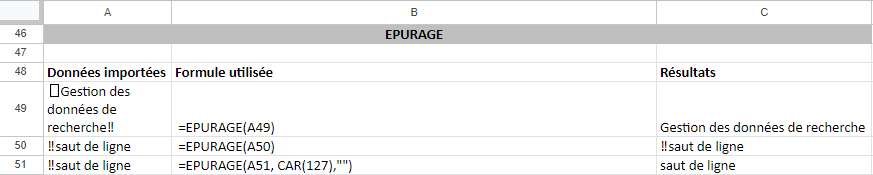
La fonction EPURAGE illustrée dans la figure 7 élimine du texte les caractères non imprimables tels que les retours chariot (↩) ou d’autres caractères de contrôle représentés par les 32 premiers codes ASCII 7 bits. Les données importées d’une variété de sources peuvent comporter des caractères non imprimables et la fonction EPURAGE aide à les éliminer d’une chaîne de texte. Dans Excel, un caractère non imprimable peut s’afficher comme un symbole de case (☐). À noter que la fonction EPURAGE ne peut pas éliminer tous les caractères non imprimables (p. ex., le caractère d’effacement). Vous pouvez préciser un caractère ASCII en utilisant la fonction CAR de Excel et le numéro du code ASCII. Par exemple, CAR(127) correspond au code d’effacement. Pour éliminer un caractère non imprimable, vous pouvez simplement remplacer le caractère non imprimable à éliminer avec des guillemets vides (“”).
Dans l’exercice ci-dessous, le caractère non imprimable CAR (19) dans la rangée 10 s’affiche comme « !! ».
Exercice 1
Utiliser les fonctions de Excel/Google Sheets pour générer les résultats de nettoyage dans la colonne B à partir des données importées de la colonne A.
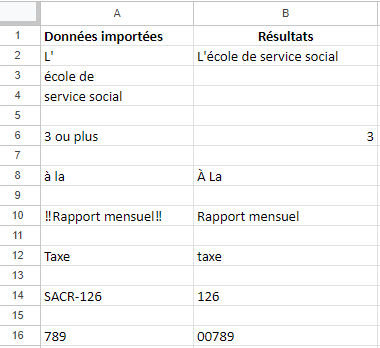
Voir le solutionnaire pour les réponses.
Le langage de programmation R
Bien que les tableurs comme Excel et Google Sheets fournissent des fonctions courantes qui peuvent faciliter le nettoyage des données, leur utilisation peut s’avérer difficile pour des jeux de données volumineux. De plus, si Excel et Google Sheets ne disposent pas déjà d’une fonction intégrée particulière, il faudra beaucoup de temps de programmation pour la construire. C’est ici que le programme R peut aider. R est l’un des progiciels statistiques les plus connus et accessibles pour le nettoyage des données. R est un langage de programmation entièrement fonctionnel ayant des fonctionnalités qui permettent de travailler avec des données et des statistiques. Il n’est pas nécessaire de maîtriser la programmation pour utiliser certaines de ses fonctions de base.
Les deux composantes les plus importantes du langage R sont les objets qui stockent les données et les fonctions qui manipulent les données. R utilise également une panoplie d’opérateurs comme +, -, *, / et <- pour effectuer des tâches simples.
Pour créer un objet R, choisissez un nom et utilisez ensuite le symbole plus-petit-que suivi du signe moins pour y sauvegarder des données. Cette combinaison ressemble à la tête d’une flèche : <-. Par exemple, vous pouvez sauvegarder la donnée « 1 » dans un objet « a ». À chaque fois que R rencontre l’objet « a », il sera remplacé par la donnée « 1 » sauvegardée à l’intérieur, tel qu’illustré ici :
> a <- 1
R est doté de nombreuses fonctions que vous pouvez utiliser pour effectuer des tâches élaborées. Par exemple, vous pouvez arrondir un numéro avec la fonction round. L’utilisation d’une fonction est assez simple. Vous n’avez qu’à écrire le nom de la fonction accompagné de la donnée, mise entre parenthèses, sur laquelle vous voulez que la fonction opère.
> round (3.1415)
[1] 3
Les extensions (ou packages) R sont des collections de fonctions écrites par des programmeurs R. Pour que les extensions puissent bien fonctionner, vous pourriez avoir à en installer d’autres d’avance. En les installant, il est plus simple dès le départ de configurer « dependencies = TRUE ».
> install.packages("package name", dependencies = TRUE)
Commençons par télécharger et installer les logiciels nécessaires. R est disponible pour Windows, MacOS et Linux.
1. Installer R et RStudio
R peut être téléchargé ici : https://cran.rstudio.com/.
- Pour les utilisateurs Windows, https://cran.rstudio.com/bin/windows/base/;
- Pour les utilisateurs Mac, https://cran.rstudio.com/bin/macosx/;
- Pour les utilisateurs Linux, https://cran.r-project.org/bin/linux/.
Base-R est simplement un outil de ligne de commande : vous inscrivez des commandes à l’invite et voyez les résultats affichés à l’écran. RStudio, quant à lui, est un environnement de développement intégré, un ensemble d’outils dont un éditeur de script, une invite de commande, une fenêtre de résultats ainsi qu’un menu de commandes pour les fonctions R les plus couramment utilisées. Travailler en R, veut généralement dire utiliser R par le biais de RStudio. À noter qu’avant d’utiliser RStudio, vous devez d’abord installer R.
Téléchargez et installez RStudio Desktop qui est gratuit et disponible pour Windows, Mac et plusieurs versions de Linux ici : https://posit.co/download/rstudio-desktop.
2. Se familiariser avec RStudio
Avant d’importer des données, familiarisez-vous avec RStudio.
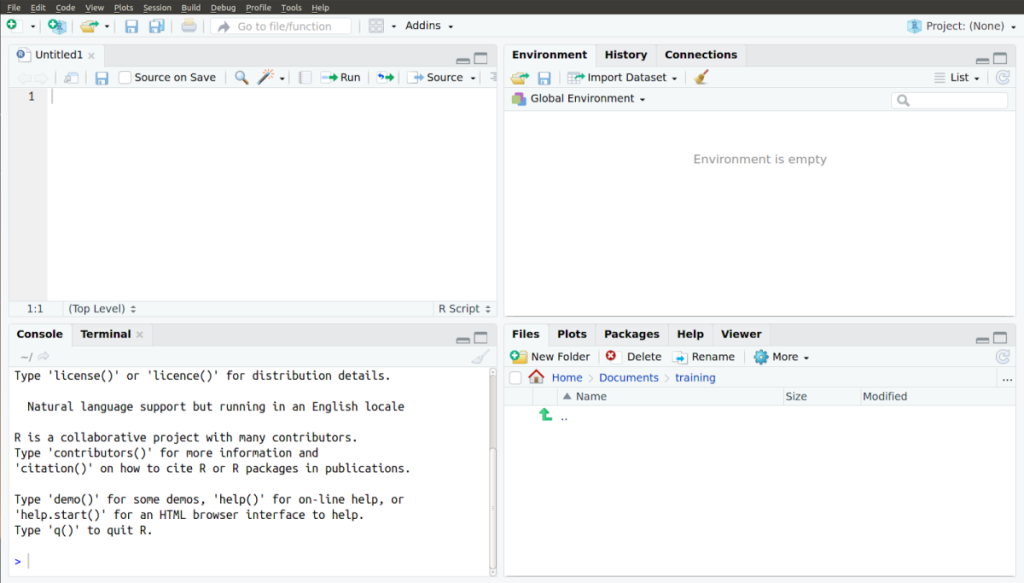
RStudio a quatre zones (voir figure 8) :
| Section | Objectif |
| Supérieure gauche | Cette section montre le texte en cours d’édition. Un texte R est un ensemble de commandes R et de commentaires. Ils sont généralement utilisés pour faire le suivi des commandes à exécuter et pour fournir des notes, par le biais de commentaires, qui expliquent le pourquoi des commandes. |
| Supérieure droite | L’onglet Environment énumère toutes les variables et les fonctions qui ont été définies et utilisées dans une session. |
| L’onglet History énumère toutes les commandes inscrites dans la console R (dans la zone supérieure gauche de RStudio) | |
| L’onglet Connections peut aider à se connecter à des bases de données externes pour accéder à des données qui ne se retrouvent pas sur votre ordinateur. | |
| Inférieure gauche | L’onglet Console affiche une invite de commande qui vous permet d’utiliser R de façon interactive, comme vous le feriez sans RStudio. |
| L’onglet Terminal ouvre une interface système pour effectuer des fonctions plus avancées, telles que l’accès à un système distant. | |
| Inférieure droite | L’onglet Files vous permet de faire le suivi, d’ouvrir et de sauvegarder les fichiers associés à votre projet R. |
| L’onglet Plots illustre les graphiques en cours de tracé. | |
| L’onglet Packages permet de charger et d’installer des extensions qui ajoutent des fonctions R supplémentaires. | |
| L’onglet Help fournit des informations utiles sur certaines fonctions. | |
| L’onglet Viewer peut être utilisé pour afficher du contenu Web local et interagir avec lui. |
Vous pouvez exploiter l’invite de commande en inscrivant des commandes R dans la console, tout comme vous le feriez si vous travailliez sans RStudio. Vous pouvez ensuite voir les résultats affichés sous les onglets History et Environment. Une sauvegarde de votre travail n’est pas faite de façon automatique lorsque vous fermez R. Pour sauvegarder, vous pouvez copier et coller le contenu de votre console dans un fichier texte.
Par exemple, vous pouvez ouvrir RStudio et inscrire la commande suivante dans la console (le texte qui suit l’invite « > ») :
print("Bonjour")
R renvoie la sortie suivante :
[1] "Bonjour"
En plus de pouvoir travailler de façon interactive en inscrivant des commandes à l’invite, vous pouvez également créer des scripts R en utilisant l’éditeur de RStudio qui apparaît dans la zone supérieure droite. Les scripts sont des fichiers texte qui contiennent une séquence de commandes R pouvant être exécutées de façon consécutive. Vous pouvez sélectionner vos commandes dans les scripts et les exécuter une à la fois ou toutes ensembles. L’écriture et la sauvegarde de vos commandes pour le nettoyage des données dans des scripts vous permettent de mieux faire le suivi de votre travail. Aussi, vous pouvez plus facilement réexécuter le code plus tard et sur de nouveaux jeux de données. Utiliser cette méthode pour faire le suivi de votre travail est une bonne pratique de GDR.
Pour ouvrir un nouveau script, sélectionnez-le à partir de l’icône supérieure gauche :
![]()
Avant d’importer votre jeu de données, vous devriez changer votre répertoire de travail pour le faire correspondre à l’emplacement de votre jeu de données. À partir de RStudio, utilisez le menu pour modifier votre répertoire de travail pour celui où vous avez sauvegardé l’échantillon de votre fichier de données. Dans le menu Session, sélectionnez > Set Working Directory > Choose Directory.
Vous pouvez également utiliser la fonction R setwd(), qui signifie set working directory ou « définir le répertoire de travail », dans la fenêtre de la console (ou de l’éditeur de script). Les barres obliques (/), plutôt que les barres obliques inverses, doivent être utilisées dans le chemin d’accès. Si vous avez sauvegardé les données dans « C:\data », il vous faudra alors entrer la commande ainsi :
setwd("C:/data")
3. Importer des données
Vous pouvez importer des données de différents formats en utilisant R. Les fichiers CSV sont couramment utilisés pour les données numériques. Les CSV ressemblent beaucoup aux fichiers Excel typiques, mais ce sont des fichiers texte avec des colonnes séparées par des virgules. Dans Excel, vous pouvez exporter ce type de données en utilisant « Enregistrer sous » ; il s’agit d’un format de préservation courant en gestion des données et il peut être lu par de nombreux programmes.
Dans les prochains exemples, nous utiliserons un échantillon de jeu de données – sample.csv – que vous trouverez sur Borealis. Veuillez télécharger et sauvegarder le jeu de données dans un nouveau dossier sur votre ordinateur. Les fichiers SPSS et Excel nécessaires pour ces exemples sont également disponibles dans Borealis.
Pour charger le fichier CSV, créez d’abord un nouveau script dans l’éditeur de script. Inscrivez la commande suivante dans le script afin d’utiliser la commande R intégrée read.csv. Exécutez ensuite le script.
mydata_csv<-read.csv("sample.csv")
Le délimiteur par défaut de la fonction read.csv() est une virgule, mais si vous avez besoin de lire un fichier qui utilise d’autres types de délimiteurs, vous pouvez le faire en fournissant l’argument sep à la fonction (p. ex., ajouter « sep = ‘;’ » pour les fichiers qui utilisent le point-virgule comme séparateur).
> mydata_csv<-read.csv(“sample.csv”, sep=’;’)
Veuillez noter que « mydata_csv » dans la commande ci-dessus fait référence à l’objet (le data frame ou tableau de données) qui sera créé lorsque la fonction read.csv importera le fichier sample.csv. Imaginez le tableau de données mydata_csv comme étant le contenant utilisé par R pour conserver les données du fichier CSV.
Les commandes R suivent un certain modèle. Examinons celui-ci. Dans la commande ci-dessus – « mydata_csv<-read.csv(“sample.csv”, sep=’;’) » – read.csv est une fonction qui lit dans un fichier CSV et qui comporte deux paramètres. Le premier – « sample.csv » – indique à read.csv lequel des fichiers il doit lire, tandis que le second – « sep=’;’ » – lui indique que les données du fichier sont séparées par des points-virgules. Après que read.csv ait fait l’analyse du fichier, l’opérateur d’assignation – « <- » – affecte les données à mydata_csv, un objet (tableau de données) créé pour contenir les données. Vous pouvez maintenant utiliser et manipuler les données dans le tableau de données.
Dans R, <- est l’opérateur d’assignation le plus courant . Vous pouvez également utiliser le signe égal =. Pour plus d’informations, utilisez la commande d’aide :
> ?read.csv
Pour lire un fichier Excel, commencez par télécharger et installer l’extension readxl. Dans la console R, utilisez la commande suivante:
> install.packages("readxl")
Veuillez noter que certaines extensions peuvent dépendre d’extensions connexes afin de bien fonctionner. En utilisant des extensions existantes, les personnes qui font de la programmation peuvent économiser du temps dans la création de nouvelles fonctionnalités avec des fonctions qui ont déjà été mises en œuvre. Toutefois, il peut être difficile de savoir si une extension nécessite une autre extension pour bien fonctionner. Conséquemment, il est recommandé d’installer des extensions en ajoutant un énoncé des dépendances (« TRUE » indique à R que les dépendances devraient être incluses). En réglant le paramètre des dépendances à « TRUE », R va télécharger et installer toutes les extensions nécessaires à l’extension qui sera installée.
> install.packages(“readxl”, dependencies = TRUE)
Une fois le téléchargement et l’installation de l’extension terminés, utilisez la fonction library() pour charger l’extension readxl.
> library(readxl)
Notez que contrairement à la fonction install.package, il n’est pas nécessaire de mettre le nom de l’extension entre guillemets pour la fonction library.
Vous pouvez maintenant charger le fichier Excel avec la fonction read_excel() :
> mydata_excel <- read_excel("sample.xlsx")
Pour plus d’informations, utilisez la commande d’aide ?read_excel.
Les fichiers SAV du logiciel SPSS (Statistical Package for the Social Sciences) peuvent être lus avec R en utilisant l’extension haven qui ajoute des fonctions supplémentaires permettant d’importer des données d’autres outils statistiques.
Installez haven en utilisant la commande suivante :
> install.packages("haven", dependencies = TRUE)
Une fois le téléchargement et l’installation de l’extension terminés, utilisez la fonction library() pour charger l’extension :
> library(haven)
Vous pouvez maintenant charger le fichier SPSS avec la fonction read_sav() :
> mydata_spss <- read_sav("sample.sav")
Vous pouvez aussi importer des fichiers SAS et Stata. Pour plus d’informations, utilisez les commandes d’aide ?haven ou ?read_sav, ou visitez https://haven.tidyverse.org/.
Les données peuvent aussi être téléchargées directement d’Internet en utilisant les mêmes fonctions que celles énumérées plus haut (à l’exception des fichiers Excel). Vous n’avez qu’à utiliser une adresse Web plutôt que le chemin d’accès.
> mydata_web <- read.csv(url("http://quelque.part.net/donnees/echantillon.csv"))
Maintenant que les données ont été chargées dans R, vous pouvez commencer à effectuer des opérations et des analyses pour les vérifier et y déceler des problèmes potentiels.
4. Vérifier les données
R est un outil beaucoup plus flexible que Excel pour le travail avec des données. Nous allons aborder les fonctions R de base pour la vérification d’un jeu de données.
Assumons que le fichier texte suivant, stocké sous le nom sample.csv, est composé de huit rangées et de cinq colonnes.
1,4.1,3.5,setosa,A 2,14.9,3,set0sa,B 3,5,3.6,setosa,C 4,NA,3.9,setosa,A 5,5.8,2.7,virginica,A 6,7.1,3,virginica,B 7,6.3,NA,virginica,C 8,8,7,virginica,C
Prenons maintenant la commande suivante pour l’importation des données. Puisque le jeu de données ne contient pas d’en-tête (c’est-à-dire, la première rangée ne fait pas la liste des noms de colonnes), vous devez préciser « header=FALSE ». Si vous voulez définir manuellement le nom des colonnes, vous ajoutez l’argument col.names. Dans la commande ci-dessous, nous demandons à read.csv de définir le nom des colonnes à ID, Longueur, Largeur, Espece et Site (à noter que les accents sont éliminés des mots en français afin d’éviter l’ajout de caractères qui risquent d’être mal interprétés lors des manipulations). En utilisant colClasses, vous pouvez préciser le type de données (nombres, caractères, etc.) que vous vous attendez à retrouver dans les colonnes de données. Dans cet exemple, nous avons précisé à read.csv que la première colonne ainsi que les deux dernières (variables catégoriques) doivent être traitées comme des données de type facteur (factor) tandis que les deux colonnes du milieu comme des données numériques (numeric).
Inscrivez la commande suivante dans votre script et exécutez-la :
> mydata_csv <- read.csv("sample.csv", header = F, col.names = c("ID","Longueur", "Largeur", "Espece", "Site"), colClasses=c("factor","numeric","numeric","factor", "factor"))
Les données ont maintenant été chargées dans mydata_csv. Pour afficher les données chargées, exécutez la ligne suivante :
> mydata_csv
R fera un renvoi des données à partir du fichier qu’il a lu.
ID Longueur Largeur Espece Site
1 1 4.1 3.5 setosa A 2 2 14.9 3.0 set0sa B 3 3 5.0 3.6 setosa C 4 4 NA 3.9 setosa A 5 5 5.8 2.7 virginica A 6 6 7.1 3.0 virginica B 7 7 6.3 NA virginica C 8 8 8.0 7.0 virginica C
Les sorties ci-dessus illustrent cinq colonnes de données. La première colonne, qui spécifie le numéro de la rangée, est créée de façon automatique par R lorsque les données sont chargées. La première rangée affiche le nom des colonnes que nous avons précisées.
Une des premières commandes à exécuter après le chargement du jeu de données est la commande dim, qui imprime les dimensions des données chargées par rangée et colonne. Cette commande vous permet de vérifier que toutes les entrées ont été lues correctement par R. Dans ce cas-ci, l’échantillon du jeu de données devrait comporter huit entrées avec cinq colonnes. Exécutons dim pour vérifier que toutes les données sont chargées.
> dim(mydata_csv)
Une fois la commande ci-dessus exécutée, R produira ce qui suit :
[1] 8 5
Cette sortie nous indique qu’il y a huit rangées et cinq colonnes dans les données chargées, ce qui correspond à nos attentes. Toutes les données ont donc été chargées.
Vous pouvez aussi exécuter la commande summary, qui vous donne des informations de base sur chacune des colonnes du jeu de données. Cette commande renvoie les valeurs maximales et minimales, les quartiles supérieurs et inférieurs (le quartile inférieur correspond à la valeur en dessous de laquelle se retrouvent 25% des données d’un jeu de données, tandis que le quartile supérieur correspond à la valeur au-dessus de laquelle se retrouvent 75% des données du jeu de données) ainsi que la médiane pour les colonnes de données numériques et la fréquence pour les colonnes de données catégoriques (le nombre de fois que chaque valeur apparaît dans une colonne).
> summary(mydata_csv)
ID Longueur Largeur Espece Site 1 :1 Min. : 4.100 Min. :2.700 set0sa :1 A:3 2 :1 1st Qu.: 5.400 1st Qu.:3.000 setosa :3 B:2 3 :1 Median : 6.300 Median :3.500 virginica:4 C:3 4 :1 Mean : 7.314 Mean :3.814 5 :1 3rd Qu.: 7.550 3rd Qu.:3.750 6 :1 Max. :14.900 Max. :7.000 (Other):2 NA's :1 NA's :1
Nous obtenons un résultat de cinq colonnes. Puisque nous avons demandé à R de lire les colonnes Longueur et Largeur comme des données numériques, il a calculé et affiché les informations sommaires en lien avec ces nombres dans leur colonne respective, notamment le minimum, le maximum, la moyenne et les quartiles. L’information sur chacune des colonnes est affichée dans les rangées sous le nom de la colonne. Par exemple, dans la colonne Longueur, la valeur minimale est de 4,1 et la valeur maximale, de 14,9. 1st Qu. affiche le quartile inférieur qui est de 5,4 et 3rd Qu. affiche le quartile supérieur, qui est de 7,55.
La rangée qui affiche « NA » nous indique s’il y a des valeurs manquantes. Dans R, les valeurs manquantes sont représentées par le symbole NA (not available). Le sommaire demandé fait apparaître deux valeurs manquantes : une dans la colonne Longueur et l’autre dans Largeur.
Dans la colonne Espece, où les données sont lues comme des données catégoriques (ou facteur), chacune des rangées affiche la fréquence à laquelle chacune des valeurs apparaît dans la colonne. Le sommaire montre trois instances de setosa, quatre de virginica et une de set0sa.
Il est possible ici d’identifier des erreurs d’enregistrement. Une des espèces de fleurs a été saisie de façon erronée; set0sa plutôt que setosa. Ce type d’erreur de frappe est très fréquent lors de l’enregistrement des données, mais il est souvent difficile à repérer, car le zéro et la lettre « o » se ressemblent beaucoup dans la plupart des polices.
R utilise une fonction de base – is.na – pour vérifier et énumérer les valeurs de données qui pourraient être manquantes. Cette fonction renvoie une valeur de vrai et faux pour chaque valeur d’un jeu de données. Si la valeur est manquante, la fonction is.na renvoie la valeur TRUE. Autrement, il renvoie la valeur FALSE.
> is.na(mydata_csv$Longueur)
[1] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
À noter que le signe de dollar ($) est utilisé pour préciser les colonnes. Dans ce cas-ci, nous voulons vérifier si la colonne Longueur dans le jeu de données CSV contient des valeurs manquantes. Le sommaire indique qu’une des valeurs est manquante; la fonction renvoie donc l’énoncé TRUE pour cette entrée de la colonne.
Les valeurs aberrantes sont des points de données qui diffèrent de façon importante des autres points du jeu de données; elles peuvent entraîner des problèmes avec certains types de modèles ou d’analyses de données. Par exemple, une valeur aberrante peut affecter la moyenne en étant anormalement petite ou grande. Certes, les valeurs aberrantes peuvent affecter les résultats d’une analyse, mais il faut faire preuve de prudence avant de les éliminer. Éliminez seulement une valeur aberrante que si vous êtes en mesure de prouver qu’elle est erronée (p. ex., si elle est attribuable à une erreur évidente dans la saisie de données). Un moyen simple d’identifier les valeurs aberrantes est de visualiser la distribution des données. Par exemple, inscrivez la commande suivante, qui demandera à R de générer une boîte à moustache (box plot).
> boxplot(mydata_csv$Longueur)
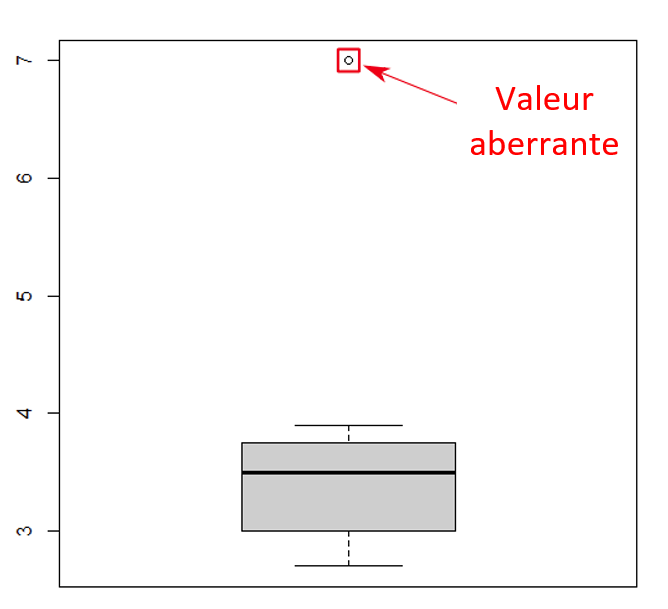
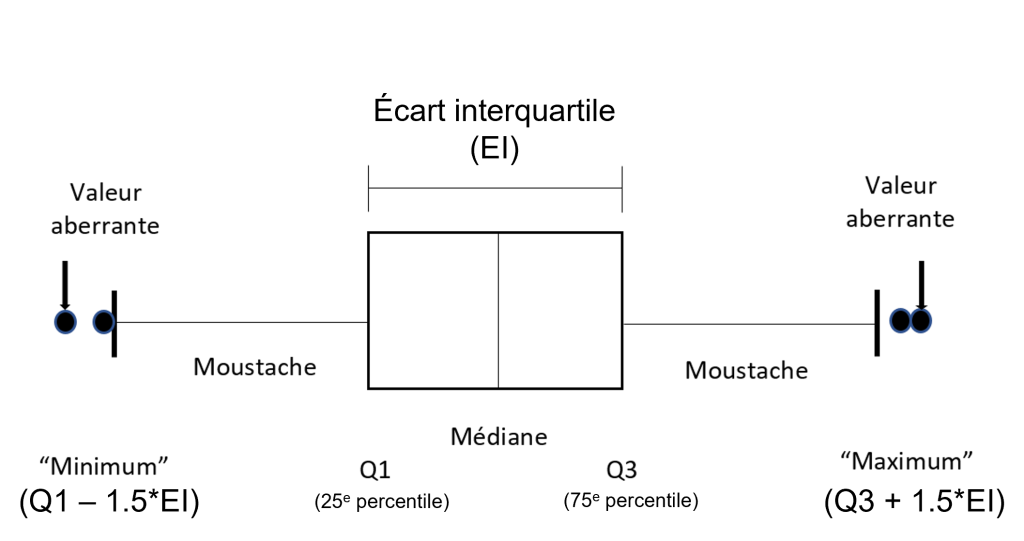
Les boîtes à moustache sont utiles pour détecter des valeurs aberrantes potentielles (voir figure 9). Une boîte à moustache aide à visualiser une colonne de données quantitatives en affichant le résumé des cinq emplacements courants : le minimum, la médiane, les premier et troisième quartiles (Q1 et Q3) et le maximum. Elle affiche également toute observation qui pourrait être qualifiée de valeur aberrante potentielle en utilisant le critère de l’écart interquartile, c’est-à-dire l’écart ou la différence entre le premier et troisième quartile (voir figure 10). Une valeur aberrante se définit comme étant un point de données situé à l’extérieur des moustaches de la boîte à moustache. Dans la boîte à moustache de la figure 9, un cercle au haut de la figure représente un point de données particulièrement éloigné des autres; la plupart des données se retrouvent à l’intérieur de la boîte du diagramme.
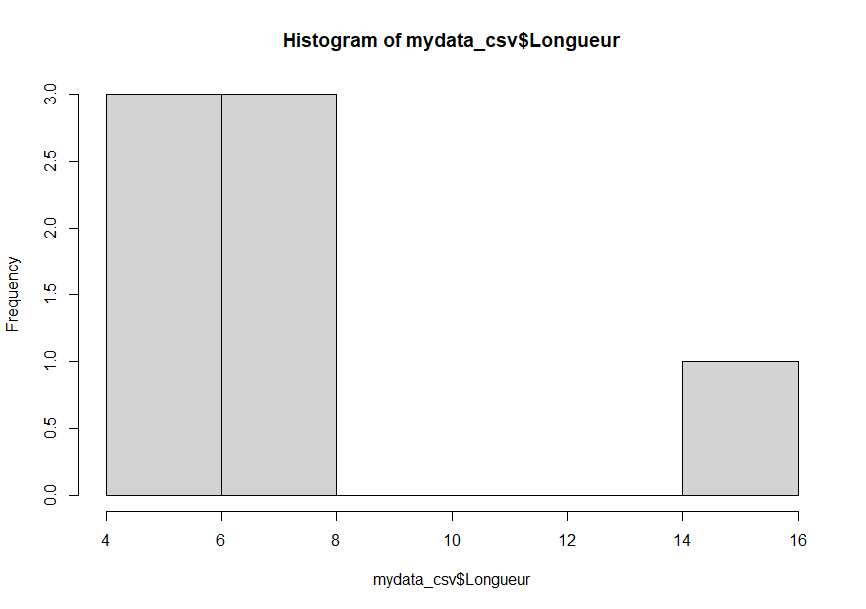
Un autre moyen courant de détecter les valeurs aberrantes est de dessiner un histogramme des données. Un histogramme illustre la distribution des différentes valeurs des données. Selon l’histogramme ci-dessous, une observation est plus élevée que toutes les autres (la barre à la droite), ce qui correspond à ce que démontre la boîte à moustache. La commande suivante peut générer un histogramme :
> hist(mydata_csv$Longueur)
> summary(mydata_csv$Longueur)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
4.100 5.400 6.300 7.314 7.550 14.900 1
À partir du sommaire, une des valeurs pour la longueur – 14,90 – semble anormalement élevée, bien qu’elle reste dans le domaine du possible. Un examen plus approfondi est donc nécessaire. Ce type de valeur aberrante peut avoir un impact important sur l’analyse des données; il faut donc bien comprendre sa validité. L’élimination des valeurs aberrantes doit être faite de façon judicieuse puisqu’elles peuvent représenter des observations réelles et importantes plutôt que des erreurs d’enregistrement.
Une fois que l’inspection préliminaire des données brutes est terminée, supposons que les données brutes contiennent quelques problèmes à corriger. Ces problèmes sont les suivants :
- un dédoublement de la colonne Site
- une erreur de frappe dans la colonne Espece
- des valeurs manquantes dans les colonnes Longueur et Largeur
- une valeur aberrante dans la colonne Longueur
Avec ces problèmes en tête, nous pouvons maintenant passer à la prochaine étape et commencer le nettoyage des données.
5. Nettoyer les données
Commençons par éliminer la colonne de trop. En utilisant les données ci-dessus, supposons que nous voulons éliminer la colonne Site. Tel que nous l’avons vu dans la sortie de la commande de sommaire, cette colonne est la cinquième du jeu de données. Pour l’éliminer, nous pouvons exécuter la commande suivante :
mydata_csv <- mydata_csv[-5]
La commande ci-dessus utilise les crochets pour préciser les colonnes de données originales. En utilisant un numéro négatif, nous indiquons à R de récupérer toutes les colonnes à l’exception de la colonne spécifiée. Dans ce cas-ci, la colonne Site est la cinquième colonne. Puisque nous voulons éliminer la cinquième colonne, mais conserver toutes les autres, nous inscrivons « -5 » entre crochets pour indiquer à R de récupérer toutes les colonnes sauf la cinquième. Ensuite, en réaffectant les nouvelles données récupérées à mydata_csv, nous réussissons à éliminer la cinquième colonne.
Pour confirmer que la colonne a bel et bien été éliminée, nous pouvons utiliser la commande dim, comme nous l’avons vu précédemment.
> dim(mydata_csv)
[1] 8 4
Le résultat montre que les données comptent désormais quatre (plutôt que cinq) colonnes.
Ensuite, il faut nettoyer les fautes de frappe. Dans ce cas-ci, nous savons que « set0sa » devrait être corrigée à « setosa ». Toutes les cellules concernées peuvent être remplacées en utilisant la commande suivante :
> mydata_csv[mydata_csv=="set0sa"] = "setosa"
> summary(mydata_csv)
ID Longueur Largeur Espece
1 :1 Min. : 4.100 Min. :2.700 set0sa :0
2 :1 1st Qu.: 5.400 1st Qu.:3.000 setosa :4
3 :1 Median : 6.300 Median :3.500 virginica:4
4 :1 Mean : 7.314 Mean :3.814
5 :1 3rd Qu.: 7.550 3rd Qu.:3.750
6 :1 Max. :14.900 Max. :7.000
(Other):2 NA's :1 NA's :1
À noter que l’opérateur d’égalité – == – sélectionne toutes les instances de set0sa (une seule dans ce cas-ci) et le symbole = lui attribue la valeur setosa. L’utilisation de deux signes d’égalité pour tester l’égalité et d’un seul signe d’égalité pour rendre quelque chose égal à quelque chose d’autre est une convention courante en programmation.
Il y a maintenant zéro entrée dans la colonne Espece qui porte le nom set0sa dans la sortie summary(). Les données ont donc été nettoyées de cette faute de frappe.
Il existe plusieurs moyens de gérer les données manquantes. Une option implique d’exclure la valeur manquante de l’analyse. Avant d’éliminer « NA » de la colonne Longueur, la fonction mean() renvoie « NA » comme suit :
> mean(mydata_csv$Longueur)
[1] NA
En effet, il est impossible d’utiliser « NA » dans une analyse numérique. L’utilisation de na.rm pour éliminer la valeur manquante « NA » donne une moyenne de 7,314286 :
> mean(mydata_csv$Longueur, na.rm = T)
[1] 7.314286
Exercice 2
Vérifiez s’il y a des valeurs aberrantes dans la colonne Largeur de sample.csv en utilisant une boîte à moustache. Calculez ensuite la moyenne de la longueur en éliminant les valeurs aberrantes.
Voir le solutionnaire pour les réponses.
Conclusion
Les procédures de nettoyage des données sont d’une importance capitale pour une analyse des données réussie et elles devraient être appliquées avant de procéder à l’analyse. Dans ce chapitre, nous avons fait un survol rapide des problèmes et des solutions liées au nettoyage des données auxquels les chercheuses et chercheurs sont confrontés en utilisant Excel/Google Sheets et le langage R. Il existe des bibliothèques complètes de fonctions de manipulation des données et elles fournissent une panoplie de fonctionnalités pour vous aider dans votre processus de nettoyage des données. Vous pouvez trouver des informations supplémentaires sur le langage R sur les sites suivants (en anglais uniquement) : https://cran.r-project.org/manuals.html et https://cran.r-project.org/web/packages/available_packages_by_name.html.
Éléments clés à retenir
- Les procédures générales pour se préparer au nettoyage des données sont de faire une copie de sauvegarde, de comprendre les données, de planifier le processus de nettoyage et de choisir les outils qui conviennent.
- Les fonctionnalités de Excel peuvent servir à effectuer de nombreuses tâches de base de nettoyage des données.
- Le langage de programmation R est un progiciel utile et gratuit qui peut servir pour des procédures de nettoyage plus avancées.
Remerciements
Les autrices aimeraient remercier Kristi Thompson et d’autres éditrices dont les commentaires constructifs ont permis d’améliorer ce chapitre.
Processus qui vise à identifier et corriger les données altérées, inexactes ou non pertinentes. Cette étape fondamentale du traitement des données améliore la cohérence, la fiabilité et la valeur des données. (Talend, s.d.).
Terme qui décrit toutes les activités que les chercheuses et chercheurs effectuent pour structurer, organiser et préserver les données de recherche avant, pendant et après le processus de recherche.
Processus utilisé pour explorer, analyser et synthétiser des jeux de données au moyen de méthodes quantitatives et graphiques. L'analyse exploratoire des données aide à faire ressortir des patrons et facilite la découverte d'irrégularités et d'incohérences dans un jeu de données.
Éléments d’information utilisés pour décrire le contenu ou le contenant d’une ressource. Elles peuvent être structurées ou non.
Outil de manipulation de données à code source libre qui nettoie, remodèle et édite par lots les données désordonnées et non structurées.
Fichier texte délimité qui utilise la virgule pour séparer les valeurs d’un enregistrement de données. Chaque ligne du fichier correspond à un enregistrement de données.
Valeur ou variable utilisée par une fonction d’un logiciel tableur pour effectuer un calcul. Par exemple, dans Excel, les fonctions sont des formules intégrées au logiciel.
Structure de données qui contient un ensemble de valeurs de type particulier. Les objets R peuvent être créés, modifiés et utilisés pour effectuer des calculs et des analyses.
Programme informatique qui peut fonctionner à partir d'une interface en ligne de commande (ILC) d’un système d’exploitation. L'ILC est une interface à base de texte qui permet à une personne d’interagir avec un ordinateur en utilisant des commandes écrites plutôt que d’utiliser une interface graphique avec des menus et des icônes.
Application logicielle qui fournit un environnement complet de développement de logiciels. RStudio est un environnement de développement intégré qui permet aux personnes qui l’utilisent d’écrire, de déboguer, d’exécuter du code R et d’afficher les sorties correspondantes.
Fichier texte qui contient des séquences de commandes dans un langage de programmation particulier (par exemple, R) pouvant être exécutées de façon consécutive.
Caractère qui sépare les données.
Valeur qui divise une liste de numéros en quartier.
Point de données qui diffère de façon importante des autres points d’un jeu de données; elle peut entraîner des problèmes avec certains types de modèles ou d’analyses de données.
Représentation graphique d’un jeu de données qui affiche la distribution des données et de toute valeur aberrante potentielle. Aussi appelé diagramme en boîte.
Représentation graphique de la distribution d’un jeu de données continues ou de valeurs énumérables et identifiables séparément.
