Point de départ en gestion des données de recherche
1 Les rudiments: une introduction à la gestion des données de recherche
Kristi Thompson
Objectifs d’apprentissage
À la fin de ce chapitre, vous pourrez:
- Définir les termes « données de recherche, » « gestion des données de recherche » et « plan de gestion des données. »
- Décrire les trois éléments de la Politique de 2021 des trois organismes sur la gestion des données de recherche.
- Comprendre le lien entre la gestion des données de recherche et la réplicabilité de la recherche.
- Énumérer les éléments courants d’un plan de gestion des données et expliquer leur importance.
Introduction
En 2021, les trois agences fédérales de financement de la recherche au Canada – les Instituts de recherche en santé du Canada (IRSC), le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG) et le Conseil de recherches en sciences humaines (CRSH) – ont publié la Politique des trois organismes sur la gestion des données de recherche. L’objectif de la politique est d’assurer que « les données recueillies par la recherche au moyen de fonds publics [soient] gérées de manière responsable et sûre. Elles doivent aussi, lorsque les obligations éthiques, juridiques et commerciales le permettent, être disponibles pour être réutilisées par d’autres » (Gouvernement du Canada, 2021a). Les agences de financement de plusieurs autres pays ont émis des politiques semblables.
Dans ce chapitre, nous discuterons de quelques-unes des questions fondamentales en lien avec la gestion des données de recherche (GDR) au Canada: d’où viennent ces efforts de formalisation de la GDR? En quoi consistent les données de recherche dans le contexte de cette politique et de façon générale? Quelles sont les exigences d’une bonne gestion des données?
Les agences fédérales de financement de la recherche au Canada
Le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG), le Conseil de recherches en sciences humaines (CRSH) et les Instituts de recherche en santé du Canada (IRSC) représentent les trois agences fédérales de financement de la recherche du Canada. Collectivement, elles sont parfois appelées les trois organismes ou trois conseils; tout au long du texte, nous emploierons souvent le terme « organismes subventionnaires » pour les désigner collectivement. Ils sont à la source d’une importante proportion des fonds de recherche au Canada et sont donc en mesure d’établir des politiques qui ont un grand impact sur la façon dont les recherches sont menées au Canada. En plus de la Politique des trois organismes sur la gestion des données de recherche, ils sont également responsables de l’Énoncé de politique sur l’éthique de la recherche avec des êtres humains (EPTC 2), la Politique sur le libre accès aux publications et autres. Leurs politiques ne constituent pas des lois. Les organismes subventionnaires peuvent décider d’accorder ou non des fonds à certaines chercheuses ou certains chercheurs, mais ils peuvent aussi interdire à un établissement entier de gérer des fonds de recherches, rendant ainsi chaque chercheuse et chercheur de cet établissement inéligible à soumettre des demandes de fonds. Les organismes subventionnaires ont donc une influence énorme sur la façon dont les recherches sont menées au Canada.
En quoi consistent les données de recherche?
Pour bien comprendre les exigences en GDR, vous devez comprendre la définition des données de recherche. Le terme « données de recherche » combine deux concepts : la recherche et les données. La recherche peut être décrite comme étant un processus d’enquête systématique, un moyen d’en apprendre plus sur des phénomènes variés. La recherche transforme l’information en connaissances et constitue un moyen par lequel nous découvrons le monde. Les données peuvent représenter une part importante de cette découverte de connaissances. Les données constituent des types d’informations ou de preuves qui servent de base à une recherche. Mais ce ne sont pas toutes les informations incluses dans un projet de recherche qui sont des données.
La foire aux questions (2021) des trois organismes du Canada établit que « la définition des données de recherche pertinentes est très souvent contextuelle et la détermination de ce qui compte comme tel devrait être guidée par les normes disciplinaires » (Gouvernement du Canada, 2021b). Autrement dit, le contexte est important; les données de recherche ne peuvent être définies sans savoir de quelle façon elles seront générées et utilisées. La section de la FAQ qui traite des liens entre les documents de recherche et les données de recherche se penche sur cette question : « les matériaux de recherche font l’objet d’une enquête – de nature scientifique, universitaire, littéraire ou artistique – et sont utilisés pour créer des données de recherche. Ils sont transformés en données par la méthode ou la pratique. »
Cette transformation est fondamentale pour séparer les informations générales des données de recherche. Les données sont le résultat de la collecte d’informations brutes issues d’une source quelconque (p. ex., des réponses à un sondage, des données d’archives ou bibliographiques, des médias sociaux, des instruments scientifiques, des documents textuels) et de l’assemblage de cette information en une forme structurée qui peut servir de base à des recherches éventuelles. En raison du travail nécessaire pour structurer, annoter et organiser les données de recherche, elles peuvent aussi être considérées comme des résultats de recherche, au même titre que les livres, les articles et autres éléments créés par des chercheuses et chercheurs. Les données de recherche constituent une source vitale d’informations, mais elles demeurent souvent inaccessibles. Si elles sont publiées ou partagées, d’autres chercheuses et chercheurs peuvent les consulter et elles peuvent être citées comme tout autre résultat de recherche.
Par exemple, un chercheur peut utiliser une série d’articles de recherche comme point de départ pour sa recherche. S’il en fait simplement la lecture et se rapporte à leurs contenus par le biais de citations pour appuyer d’autres idées, les articles servent de matériaux de recherche et non de données de recherche. Si toutefois ce chercheur utilise la même série d’articles, les importe dans un logiciel, les étudie et les annote sous une forme structurée pour ensuite formuler une conclusion globale sur l’ensemble des articles, ces articles deviennent alors un jeu de données et représentent des données de recherche.
Les données de recherches peuvent être des données secondaires, ce qui implique que la chercheuse ou le chercheur n’a pas recueilli ou assemblé les matériaux lui-même. Dans ce cas, le travail fait pour structurer ou peaufiner les données pour qu’elles servent d’intrant peut avoir été fait par quelqu’un d’autre. Ou encore, les données peuvent déjà arriver avec une structure s’il s’agit de données administratives (extraites, par exemple, d’une base de données d’un bureau d’admission). Mais un ensemble structuré d’informations qui est affiné lors de la recherche par le biais d’une analyse représente tout de même des données de recherche.
La structure des données
Utilisé pour les tableurs et fichiers statistiques, le rectangle est une structure courante pour les données. À l’intérieur de ce format, les données sont organisées en rangées et en colonnes. Chacune des rangées contient un cas – soit une unité simple de l’objet étudié (p. ex., une personne dans une enquête ou une mouche à fruits dans une expérience). Chacune des colonnes sera utilisée pour stocker une variable ou caractéristique pour chacun des cas, tels que l’âge de chaque personne (ou des mouches à fruits) dans l’étude.
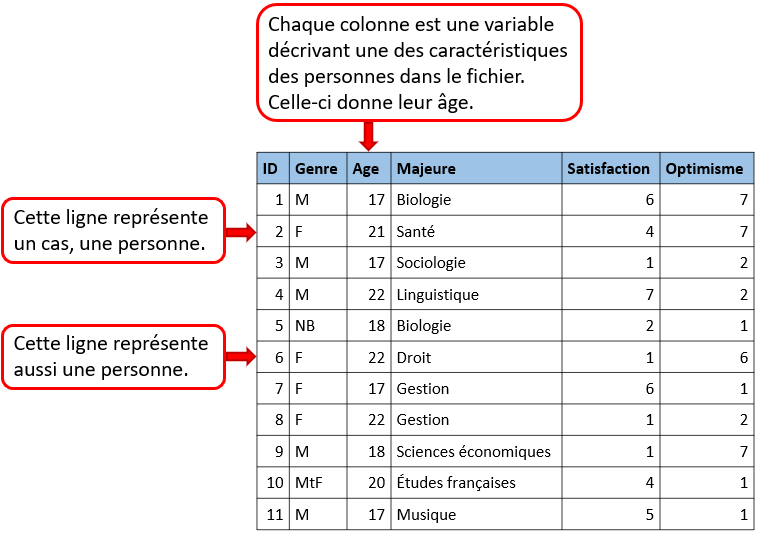
Puisque nous discutons de structure des données, voici quelques règles de base pour bien organiser les données en rectangle, de type tableur, afin d’en faciliter la gestion :
- Organisez les données dans un seul rectangle, avec les sujets/cas dans chacune des rangées et les variables/caractéristiques dans chacune des colonnes; ajoutez une rangée en haut pour l’en-tête avec des noms brefs qui décrivent ce que représente chacune des colonnes;
- Inscrivez un seul élément par cellule et ne jumelez pas les cellules. Chacune des cellules devrait comporter une seule information qui correspond à une rangée et une colonne (un cas et une variable);
- Créez un dictionnaire des données – un document distinct qui explique le contenu de vos rangées et colonnes;
- N’ajoutez pas de calculs ou de fonctions dans les fichiers de données originales;
- N’utilisez pas de polices colorées ou de surlignage en tant que données.
La figure ci-dessus illustre à quoi ressembleront des données ainsi structurées. Les données organisées dans ce type de format peuvent être lues et utilisées par tout logiciel de tableur ou progiciel statistique.
Qu’est-ce que la gestion des données de recherche?
La gestion des données de recherche est un terme général qui décrit ce que font les chercheuses et chercheurs pour structurer, organiser et entretenir les données avant, pendant et après leur travail de recherche. En ce sens, toute personne qui recueille ou utilise des données avec l’intention de mener une recherche fait de la gestion des données de recherche. Créer un fichier de données, décider où il sera sauvegardé, lui attribuer un nouveau nom ou le déplacer dans un nouvel emplacement représentent toutes des activités de gestion des données de recherche. La gestion des données de recherche (GDR) est également un domaine d’étude émergent. Cette nouvelle discipline se préoccupe d’étudier et de développer des moyens plus efficaces de gérer des données de recherche. L’idée qui sous-tend la gestion des données est l’utilisation d’un ensemble de techniques pour structurer, organiser et documenter les informations qui serviront de base à la recherche et de le faire de façon à ce que d’autres puissent comprendre et reproduire votre recherche, ainsi qu’utiliser les données qui ont servi à votre recherche.
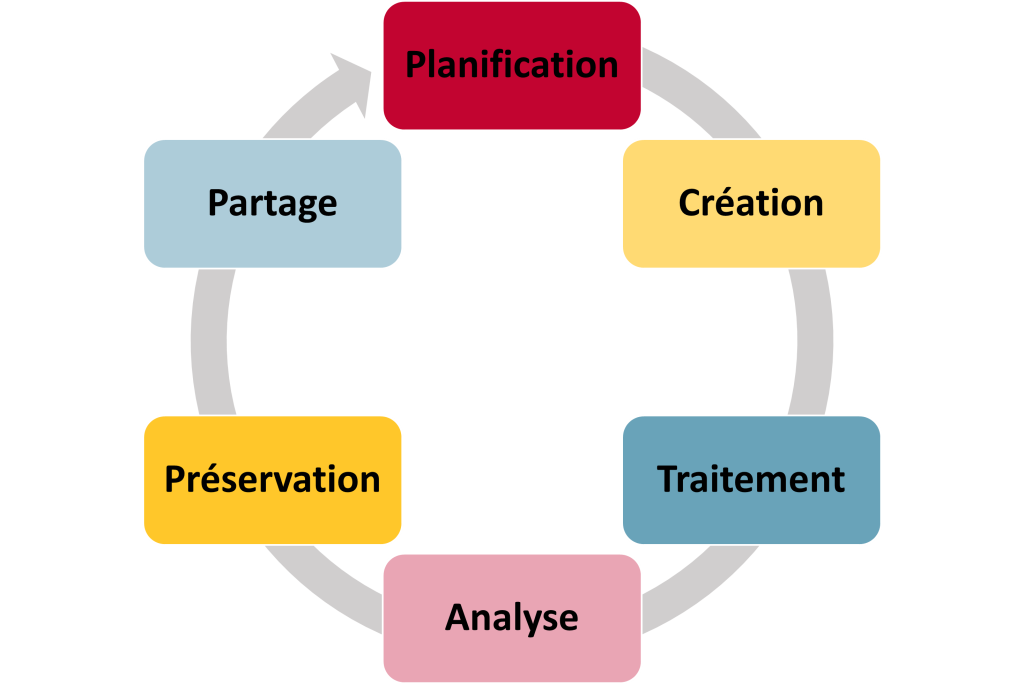
Le cycle de vie des données de recherche est souvent utilisé pour illustrer la nature cyclique d’une recherche. Les chercheuses et chercheurs commencent par planifier leur recherche. Ensuite, les données sont recueillies, traitées et nettoyées avant d’être analysées pour permettre aux chercheuses et chercheurs de formuler des conclusions. Finalement, des mesures sont prises pour préserver les données à long terme et pour les rendre disponibles à d’autres qui les utiliseront pour leur étude. En pratique, le cycle est plus complexe avec plusieurs étapes qui se chevauchent. Par exemple, la préservation des données originales doit commencer dès la collecte des données pour éviter tout risque de perte, et les chercheuses et chercheurs peuvent souvent traiter, analyser et traiter à nouveau leurs données tout au long du processus. Il s’agit d’une perspective très axée autour des données, puisque le cycle de recherche comprend également plusieurs autres étapes, comme la soumission de demandes de financement, ainsi que la rédaction et la publication des résultats.
Reproductibilité, réplicabilité et traçabilité
La reproductibilité, la réplicabilité et la traçabilité sont trois concepts à la fois reliés mais distincts, qui sont essentiels pour bien comprendre l’importance d’une bonne GDR. Pour qu’une recherche soit reproductible, il faut que des chercheuses ou chercheurs qui ne faisaient pas partie de l’équipe de recherche originale puissent reprendre la recherche en utilisant les mêmes données, méthodes et codes et aboutir aux mêmes résultats. Concrètement, cela implique que les chercheuses ou chercheurs externes doivent avoir accès aux données, au code et à une documentation détaillée.
Pour qu’une recherche soit réplicable, les chercheuses ou chercheurs qui ne faisaient pas partie de l’équipe de recherche originale doivent être en mesure de reproduire la recherche originale avec des données différentes ou nouvellement recueillies et arriver aux mêmes résultats ou à des résultats semblables. Pour ce faire, les méthodes de l’équipe de recherche originale doivent avoir été documentées et publiées, mais les données originales ne doivent pas nécessairement être disponibles.
Pour qu’une recherche soit traçable, les chercheuses ou chercheurs qui ne faisaient pas partie de l’équipe de recherche originale doivent être en mesure de reproduire le jeu de données analysé à partir du jeu de données original, tel qu’il a été collecté ou acquis. Si les données sont traçables, il est possible de conclure avec confiance qu’aucune modification non documentée n’a été faite au jeu de données. Les chercheuses ou chercheurs externes devraient aussi pouvoir comprendre le raisonnement derrière chaque modification apportée aux données, qui a apporté ces modifications et le processus décisionnel derrière chacune d’elles. Les données de recherche constituent des preuves – pour les adeptes de séries d’enquêtes policières, c’est comme la chaîne de possession qui assure que les preuves d’une enquête criminelle n’ont pas été contaminées.
Vous vous rappelez des règles de structures des données mentionnées plus tôt dans le chapitre? Des formats et des structures simples, uniformisés et couramment utilisés sont importants pour la reproductibilité, la réplicabilité et la traçabilité.
Le fait de rendre obligatoires certaines normes particulières pour la gestion des données ne vise pas à créer des contraintes arbitraires pour compliquer la façon de mener une recherche. Les normes aident à préserver l’intégrité de la recherche en incitant les chercheuses et chercheurs à manipuler leurs données de façon à ce que leur démarche et leur travail soient compréhensibles. Ainsi, les données peuvent être reproduites et répliquées. Les conclusions de recherche qui ne peuvent être reprises ou reproduites perdent en crédibilité. Une application réglementée de la GDR augmente aussi la possibilité du partage des données, pas seulement pour que la recherche puisse être reproduite directement, mais aussi pour que les données puissent être réutilisées dans d’autres projets, créant ainsi plus d’occasions de recherche en limitant les coûts. La Politique des trois organismes de 2021 sur la gestion des données de recherches inclut trois exigences qui visent à réaliser cet objectif.
La crise de la réplicabilité
La crise de la réplicabilité est un problème récurrent dans les sciences physiques et sociales qui remet en question la crédibilité de ces sciences. Vers 2010, des psychologues qui ont voulu reprendre certaines études antérieures pour tenter de reproduire leurs résultats ont été incapables de le faire de façon systématique. Lors d’une importante initiative (document en anglais uniquement) qui visait à reproduire 28 études, près de la moitié d’entre elles ne pouvait être reproduite et 32% ont démontré des résultats contraires aux résultats originaux (Klein et al., 2018). Cela implique que certains individus qui dépendent de ces recherches peuvent avoir enseigné, mené des recherches supplémentaires et modifié des pratiques en se basant sur des résultats potentiellement erronés. Des problèmes semblables ont été rapportés dans d’autres domaines, tels que la biologie, la médecine et les sciences économiques. Les études originales peuvent avoir utilisé des données erronées, de mauvaises méthodes d’analyse ou des échantillons atypiques, parmi les nombreuses causes potentielles des erreurs. Quand les données originales ne sont pas disponibles ou traçables, difficile de le savoir.
Les trois exigences de la Politique des trois organismes
Les trois exigences comme établies par la Politique des trois organismes sur la gestion des données de recherche (Gouvernement du Canada, 2021a) sont :
- Les stratégies institutionnelles. Les établissements (généralement les établissements d’enseignement postsecondaire et les hôpitaux) admissibles à administrer des fonds des trois organismes doivent élaborer des stratégies formelles de GDR et les communiquer aux organismes subventionnaires selon une échéance établie. Ces stratégies doivent décrire la façon dont ils prévoient d’appuyer leurs chercheuses et chercheurs dans l’amélioration de leurs pratiques de GDR et dans l’application des deux autres exigences. Les liens vers les stratégies soumises aux organismes subventionnaires sont disponibles sur la page des stratégies institutionnelles.
- Les plans de gestion des données. Les organismes subventionnaires commenceront à exiger que les chercheuses et chercheurs soumettent des plans qui décrivent la façon dont leurs données seront gérées, du moins pour certaines opportunités de financement. Ces plans seront pris en compte lorsque les organismes subventionnaires auront déterminé la façon dont les fonds seront accordés .
- Le dépôt des données. Lorsque les bénéficiaires de financement publient un article ou tout autre résultat découlant de la recherche financée par les organismes subventionnaires, les données et le code qui appuient les résultats de la recherche doivent être déposés dans un dépôt numérique. Il s’agit d’une exigence assez limitée. Une chercheuse peut recueillir une douzaine de variables, mais rédiger un article qui n’utilise directement qu’une partie d’entre elles. C’est ce sous-ensemble qui doit être déposé. Il est également important de noter que le dépôt n’est pas synonyme de partage. Les données confidentielles ou qui ne devraient pas être partagées doivent être déposées dans un endroit privé et sécurisé.
Les plans de gestion des données (PGD)
Un plan de gestion des données (PGD) est une description formelle de tout le processus de la chercheuse ou du chercheur, de la collecte des données jusqu’à leur élimination ou suppression. Les PGD ont existé sous différentes formes depuis les années 1960 (Smale et al., 2020), mais leur adoption a été lente et reste toujours peu répandue dans certaines disciplines. À l’international, les PGD sont souvent exigés par les organismes subventionnaires, notamment au Royaume-Uni et aux États-Unis. Des outils ou gabarits ont été développés pour aider les chercheuses et chercheurs à élaborer des plans qui pourront répondre aux exigences des organismes subventionnaires. L’outil principal utilisé au Canada est l’Assistant PGD. Il s’agit d’un outil en ligne qui pose aux personnes qui l’utilisent une série de questions sur leurs données et plans de recherche en offrant des conseils et une aide contextuelle qui aident à répondre aux questions.
L’objectif des PGD est d’aider les chercheuses et chercheurs dans la gestion de leurs données au cours de toutes les étapes du cycle des données de recherche, de la collecte jusqu’au partage. Ils sont souvent décrits comme des documents vivants ou évolutifs qui doivent être mis à jour au fil des besoins identifiés par les chercheuses ou chercheurs pendant leur travail avec les données. Ils peuvent comporter une variété d’éléments – Williams et al. (2017) ont identifié 43 sujets pouvant constituer des éléments nécessaires à un PGD – et les éléments exigés ou utiles peuvent varier d’une discipline ou d’un type de données à l’autre. Les éléments d’un PGD visent à inciter les chercheuses et chercheurs à tenir compte de la façon dont leurs données seront manipulées et des ressources nécessaires avant le début de leur recherche. La Politique des trois organismes demande aux chercheuses et chercheurs de soumettre un plan qui aborde les éléments suivants :
- comment les données seront recueillies, documentées, formatées, protégées et préservées;
- comment seront utilisés les jeux de données existants et quelles nouvelles données seront créées au cours du projet de recherche;
- est-ce que les données seront partagées et si oui, comment;
- l’endroit où les données seront déposées.
Les agences qui financent la recherche au Canada et à l’international veulent que les chercheuses et chercheurs utilisent des PGD pour démontrer que leurs données seront recueillies, stockées et conservées de façon à faciliter la transparence, le partage et la réutilisation des données ainsi que la reproductibilité des résultats. Les chercheuses et chercheurs qui en font usage jouissent d’un avantage lors du dépôt d’une demande de financement pour la collecte ou l’utilisation des données. Les PGD représentent aussi des avantages pour les chercheuses et chercheurs, leur permettant de mieux planifier et de travailler plus efficacement avec leurs données. Les exigences pour les PGD constituent, en fait, une forme d’ingénierie sociale qui vise à inciter les chercheuses et chercheurs à améliorer leur recherche.
Ces bienfaits ne sont généralement pas prouvés. En théorie, la prise en compte minutieuse de tous les éléments d’un PGD devrait entraîner une amélioration de la recherche. Toutefois, la théorie ne répond pas toujours à la pratique. En effet, un examen de toute la littérature montre qu’il existe très peu de preuves publiées et systématiques des bienfaits réels des PGD pour les chercheuses et chercheurs, établissements et organismes de financement (Smale et al., 2020). Puisque les PGD ont été conçus pour améliorer les activités de recherche, il est regrettable que si peu d’attention ait été accordée à étudier s’ils réussissent à répondre à cet objectif ou s’ils peuvent être modifiés et améliorés.
Nous ferons un survol rapide des sujets qui font régulièrement partie des PGD.
La collecte des données
Les chercheuses et chercheurs doivent faire la liste des types de données qui seront probablement recueillies ou acquises, et identifier les formats de fichiers dans lesquels ces données seront sauvegardées. Dès le début, les chercheuses et chercheurs devraient envisager l’utilisation de formats qui permettent la préservation, le partage et la réutilisation des données; de bons formats sont ceux qui peuvent être utilisés par des progiciels facilement accessibles. Les formats ouverts sont encore mieux; ils ont des normes publiées de sorte que toute personne ayant la formation nécessaire peut écrire un logiciel pour les lire. Les formats ouverts sont à l’épreuve du temps.
Le fait de tenir compte des conventions pour le nommage des fichiers avant même de commencer la collecte des données peut être étonnamment important. Les chercheuses et chercheurs qui n’établissent pas d’avance leur système peuvent se retrouver avec une variété de fichiers avec des noms de type « donnees.csv, » « donnees2.csv, » « donneesfinales.csv, » « donneesnettoyees.csv, » etc. Un exemple d’un bon système pour nommer et pour faire le suivi des différentes versions d’une collection de données peut être « nomdescriptif-changementfait-date.ext. » L’inclusion du changement et de la date dans le nom du fichier constitue une forme rudimentaire de contrôle des versions; cette question sera abordée de façon plus détaillée dans le chapitre 10, « Soutenir la recherche reproductible avec la curation active de données. » Le contrôle des versions devrait également comprendre la mise en place d’autres systèmes pour améliorer la traçabilité des données, tels que de noter toute information liée aux changements apportés aux données dans un fichier principal de documentation ou d’effectuer tous les changements aux données en utilisant des codes qui sont mis à jour et sauvegardés après chaque changement.
Documentation et métadonnées
La documentation est essentielle, tant pour la préservation que pour la traçabilité. Si un fichier est sauvegardé sur disque en tant que séquence de 0 et de 1, mais que personne ne sait ce que représentent ces chiffres, le fichier n’a donc pas vraiment été préservé. La documentation doit comprendre des éléments tels qu’un document maître indiquant l’origine des données et de quelle façon elles ont été recueillies, des tableurs dont les noms de colonnes sont faciles à comprendre et l’enregistrement d’informations détaillées sur tous les changements apportés aux fichiers de données.
La documentation peut aussi inclure l’attribution de noms aux fichiers et aux dossiers qui sont directement lisibles par une personne ainsi que la création d’une structure raisonnée pour les dossiers et sous-dossiers. Une forme courante de documentation supplémentaire est le fichier LISEZ-MOI. Il s’agit tout simplement d’un fichier qui accompagne un dossier et qui fait la liste de tous les fichiers dans ce dossier, qui décrit le contenu de chacun des fichiers et qui explique le rapport entre les différents fichiers (p. ex., s’il y a un fichier qui contient le code utilisé pour générer des fichiers de données).
Pour plusieurs types de données, dont les fichiers de santé et de sondages, les guides de codification sont également importants. Les guides de codification décrivent la structure et le contenu des fichiers de données en fonction d’un schéma quelconque. Par exemple, un guide de codification pour un sondage fera la liste de toutes les questions posées (qui seront codées comme variables), décrira les différentes options de réponses potentielles, expliquera la façon dont les échantillons du sondage ont été sélectionnés et toutes les variables supplémentaires créées par les chercheuses ou chercheurs. Idéalement, vous devriez avoir suffisamment de documentation sur vos données déposées pour qu’une personne qui possède les connaissances dans votre domaine soit en mesure de :
- comprendre et suivre les étapes que vous avez effectuées pour recueillir vos données et les décisions que vous avez ensuite prises en cours de route;
- prendre votre fichier de données originales et reproduire les changements que vous avez apportés qui ont menés à la forme finale des données;
- exécuter les analyses qui ont produit vos résultats finaux publiés.
La section pour la documentation dans un PGD devrait également inclure les informations qui expliquent la façon dont les chercheuses et chercheurs s’assureront de suivre et d’enregistrer chaque modification apportée au fichier de données. Si plusieurs personnes travaillent avec les données, il est particulièrement important d’établir un système.
Les fichiers de code
Les programmes statistiques, tels que SPSS, Stata et R, ainsi que les langages de programmation à usage général, tels que Python, vous permettent de modifier et d’analyser les données en inscrivant des commandes dans un fichier de code et de les exécuter. Certains programmes, tels que SPSS, vous permettent aussi de générer des commandes par le biais d’options dans le menu. Si des changements ont été apportés à vos données en utilisant des fichiers de code, vous serez toujours en mesure d’y retourner pour bien comprendre la nature des changements apportés à vos données.
Le stockage et les sauvegardes
Dans la section sur le stockage et les copies de sauvegarde, les chercheuses et chercheurs peuvent expliquer où les données seront stockées et de quelles façons elles seront sécurisées. Le stockage d’une seule copie des données – sur un disque dur personnel qui peut ne pas fonctionner ou sur une clé USB qui peut être endommagée – est étonnamment courant (Cheung et al., 2022). Comme plusieurs l’ont découvert, c’est aussi une très mauvaise idée. Une bonne idée est la mise en place d’un système qui assure la sauvegarde régulière des données. La règle du 3-2-1 pour la sauvegarde est largement utilisée : il devrait y avoir 3 copies de chaque fichier, les copies devraient se retrouver sur deux médias différents et une des copies devrait se retrouver dans un emplacement externe. Si les données sont stockées là où il y a un système de sauvegarde automatisé (tel qu’un serveur départemental ou un service infonuagique), le besoin de créer des copies de sauvegardes supplémentaires est réduit puisqu’une copie se trouve déjà dans le système de sauvegarde.
La préservation et le partage
La transparence d’une recherche ainsi que la préservation et le partage des données de recherche constituent les objectifs principaux de la GDR; il est donc essentiel d’en parler dans un PGD. Le modèle d’excellence pour le partage des données est de rendre accessible un jeu de données complet et bien documenté dans une archive en ligne afin qu’il puisse être téléchargé. Le jeu de données devrait être accompagné d’une licence ouverte ou Creative Commons, ce qui permet sa réutilisation de façon explicite. Certaines licences incluent une stipulation comme quoi les données utilisées pour des recherches éventuelles doivent être citées de façon appropriée (même si, sans stipulation, les bonnes pratiques et la courtoisie professionnelle encouragent à le faire).
Si les données sont partagées, l’étape la plus importante est d’identifier le dépôt approprié. Il existe plusieurs dépôts appropriés. Plusieurs établissements (universités, collèges, hôpitaux, etc.) ont des dépôts de données institutionnels dotés de fonctions permettant d’ingérer les données dans des formats conçus pour la préservation. Ces établissements s’engagent à préserver et à sauvegarder les données. Certaines publications savantes individuelles peuvent aussi héberger des archives qui donnent accès aux données liées aux articles qu’elles publient. Il existe également des dépôts disciplinaires qui hébergent des types particuliers de données, telles que des données génomiques ou géospatiales.
Toutefois, le partage ouvert dans un dépôt n’est pas toujours recommandé, et pour certains types de données (dont les données médicales), le partage peut être contraire à l’éthique. Des questions de confidentialité, d’engagements pris auprès de sujets de recherche, de souveraineté des données autochtones, de propriété des données et de propriété intellectuelle peuvent toutes représenter des situations où le partage ouvert de données n’est pas une option. Dans ces cas-là, les chercheuses et chercheurs doivent trouver des moyens alternatifs de partage. Une solution de rechange est de partager une documentation sur les données dans un dépôt et d’inviter les personnes intéressées à communiquer avec l’équipe de recherche pour obtenir un accès aux données. Parfois, certaines parties d’une collection de données peuvent être partagées tandis que d’autres sont considérées comme trop sensibles. Les personnes intéressées peuvent avoir à s’engager à respecter certaines normes éthiques ou d’autres conditions qui s’appliquent. Dans ces situations, les données devront être préservées autrement, dans une archive sécurisée ou sur un réseau privé. Consultez le chapitre 13 sur les données sensibles pour plus d’informations.
Dans le PGD, la section qui traite de préservation et de partage doit expliquer la façon précise dont les données seront préservées à long terme. Elle doit aussi énoncer les dispositions pour le partage des données, y compris le dépôt où elles seront stockées, les parties de données qui seront partagées et, le cas échéant, les conditions d’accès. Si les données ne peuvent être partagées, le PGD doit en expliquer les raisons.
Conclusion
La gestion des données de recherche est un terme général qui s’applique au travail des chercheuses et chercheurs en lien avec la façon dont leurs données sont organisées et maintenues pendant et après la tenue de leur recherche. Il s’agit d’un domaine en plein essor qui incite les bibliothécaires, les spécialistes des données et les chercheuses et chercheurs à se poser des questions sur les meilleurs moyens de gérer les données tout en intégrant la transparence de la recherche, la préservation ainsi que le partage des données pour qu’elles puissent être critiquées, étudiées et utilisées par d’autres chercheuses et chercheurs ainsi que par le public intéressé par la recherche. Ultimement, la GDR vise à améliorer la recherche.
Questions de réflexion
- Choisissez un domaine d’étude et décrivez quelques exemples de données de recherche qui pourraient être utilisées par des chercheuses ou chercheurs dans ce domaine. Quels types de défis pourraient être liés à la gestion de ces données?
- Consultez la Politique des trois organismes sur la gestion des données de recherche.
- Trouvez la stratégie de GDR de votre établissement (ou d’un établissement local). Qu’est-ce qu’elle vous dit sur la façon dont l’établissement perçoit la GDR?
- Consultez l’Assistant PGD ou utilisez le gabarit de l’Annexe 1 et créez un PGD pour un projet de recherche fictif.
Éléments clés à retenir
- La gestion des données de recherche (GDR) est un terme général qui se rapporte aux activités entreprises par des chercheuses et chercheurs dans leur travail avec les données. En tant que domaine d’étude, la GDR incite à examiner des questions fondamentales sur les meilleures façons de mener des recherches.
- Les trois agences fédérales de financement de la recherche du Canada ont établi une politique sur la gestion des données de recherche pour encourager les chercheuses et chercheurs à rendre leur recherche plus transparente, à préserver et à partager leurs données.
- Les plans de gestion des données (PGD) sont des documents préparés par les chercheuses et chercheurs pour décrire la façon dont leurs données seront gérées. Ces documents abordent plusieurs aspects du travail avec les données, dont la collecte des données, la documentation, le stockage, le partage et la préservation.
Bibliographie
Cheung, M., Cooper, A., Dearborn, D., Hill, E., Johnson, E., Mitchell, M. et Thompson, K. (2022). Les pratiques avant les politiques : comportements en matière de gestion des données de recherche au Canada. Partnership: Revue canadienne de la pratique et de la recherche en bibliothéconomie et sciences de l’information, 17(1), juillet 2022, 1-80. https://doi.org/10.21083/partnership.v17i1.6779.
Gouvernement du Canada. (2021a). Politique des trois organismes sur la gestion des données de recherche. https://science.gc.ca/site/science/fr/financement-interorganismes-recherche/politiques-lignes-directrices/gestion-donnees-recherche/politique-trois-organismes-gestion-donnees-recherche
Gouvernement du Canada. (2021b). Politique des trois organismes sur la gestion des données de recherche – Foire aux questions. https://science.gc.ca/site/science/fr/financement-interorganismes-recherche/politiques-lignes-directrices/gestion-donnees-recherche/politique-trois-organismes-gestion-donnees-recherche-foire-aux-questions#1b
Klein, R. A., Vianello, M., Hasselman, F., Adams, B. G., Adams Jr., R. B., Alper, S., Aveyard, M., Axt J. R., Babalola, M. T., Bahník, Š., Batra, R., Berkics, M., Bernstein, M. J., Berry D. R., Bialobrzeska, O., Binan E. D., Bocian, K., Brandt, M. J., Busching, R., … Nosek, B. A. (2018). Many Labs 2: Investigating variation in replicability across samples and settings. Advances in Methods and Practices in Psychological Science, 1(4), 443-490. https://doi.org/10.1177/2515245918810225
Smale, N. A., Unsworth, K., Denyer, G., Magatova, E. et Barr, D. (2020). A review of the history, advocacy and efficacy of data management plans. International Journal of Digital Curation, 15(1), 1-29. https://doi.org/10.2218/ijdc.v15i1.525
Williams, M., Bagwell, J. et Zozus, M. N. (2017). Data management plans: The missing perspective. Journal of Biomedical Informatics, 71, 130-142. https://doi.org/10.1016/j.jbi.2017.05.004
Politique qui s'applique aux données générées grâce au financement de la recherche par l'une des trois agences fédérales de financement du Canada. Cette politique vise à encourager l'amélioration de la recherche en obligeant les chercheuses et chercheurs à créer des plans de gestion de données et à préserver leurs données.
Le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG), le Conseil de recherches en sciences humaines du Canada (CRSH) et les Instituts de recherche en santé du Canada (IRSC) (les organismes subventionnaires) représentent les trois agences fédérales de financement de la recherche au Canada. Ils sont à la source d’une importante proportion des fonds de recherche au Canada.
Cadre principal harmonisé qui guide l’établissement des lois canadiennes et des paradigmes éthiques plus larges en lien avec le droit des êtres humains en recherche.
Sources d'informations ou de preuves qui ont été compilées pour servir de base à la recherche.
Données recueillies dans le cadre d’un travail de gestion administrative. Les données administratives peuvent être utilisées pour faire le suivi de personnes, d’achats, d’inscriptions, de prix, etc.
Terme qui décrit toutes les activités que les chercheuses et chercheurs effectuent pour structurer, organiser et préserver les données de recherche avant, pendant et après le processus de recherche.
Cycle au cours duquel les données sont recueillies, traitées, analysées, préservées et ensuite partagées avec d’autres chercheuses et chercheurs qui pourront recommencer le cycle.
Caractère d’une recherche qui peut être reprise par des chercheuses ou chercheurs qui ne faisaient pas partie de l'équipe de recherche originale, mais qui utilisent les mêmes données pour arriver aux mêmes résultats.
Caractère d’une recherche qui peut être reproduite par d’autres chercheuses ou chercheurs qui, avec des données différentes ou nouvelles, arriveront à des résultats semblables ou identiques à ceux de la recherche originale.
Caractère d’une recherche où des chercheuses ou chercheurs externes peuvent comprendre et répéter chacune des modifications apportées aux données brutes pour les préparer à l’analyse.
Description formelle de tout le processus de la chercheuse ou du chercheur, de la collecte des données à leur analyse puis comment elles seront traitées à la fin du projet.
Outil en ligne qui pose, aux personnes qui l'utilisent, une série de questions sur leurs données et leurs plans de recherche. De l'aide et des conseils contextuels sont disponibles pour aider à répondre aux questions.
Système qui fait automatiquement le suivi de chaque modification à un document ou fichier, permettant aux personnes qui l’utilisent de revenir à des versions sauvegardées antérieures sans avoir à continuellement enregistrer des copies sous différents noms.
Document qui fournit des renseignements à propos d’un fichier ou d’un jeu de données. Il permet d’assurer la pérennité de l’interprétation correcte des données par toutes les personnes qui les consulteront.
