Annexe 3: Exercices du chapitre 10
Introduction
L’objectif de cet exercice est de démontrer la relation entre les données ouvertes, les cahiers de laboratoire électroniques et les conteneurs informatiques dans la recherche reproductible. Vous allez interagir avec le code d’un cahier de laboratoire hébergé sur GitHub et rendu interopérable à l’aide de myBinder. La plupart des principes fondamentaux décrits au chapitre 10 seront illustrés ici.
Cet exercice inclut une activité d’introduction et une activité avancée. Dans l’activité d’introduction, vous allez explorer le code sur GitHub et examiner une version statique d’un cahier de laboratoire. Dans l’activité avancée, vous lancerez un conteneur informatique dans une interface appelée Binder. Le conteneur héberge un cahier de laboratoire électronique qui interroge un jeu de données ouvert. Vous pouvez interagir avec le jeu de données en ligne sans modifier la copie originale. Le conteneur en ligne vous permet d’exécuter le code sans installer de logiciels sur votre ordinateur. L’activité avancée nécessite des connaissances plus poussées en matière de codage ou simplement de la persévérance. Le conteneur informatique ne se charge pas toujours du premier coup et le code ne fonctionnera pas s’il n’est pas parfaitement saisi. Cet exercice a pour but de montrer les avantages et la complexité de la recherche reproductible. N’hésitez pas à chercher sur Google les termes que vous ne comprenez pas. De plus, ChatGPT est un bon outil pour expliquer le code et son fonctionnement.
À la toute fin de l’exercice, il y a une question de réflexion. Vous pouvez répondre à cette question même si vous n’avez pas fait l’activité avancée.
Partie 1 (introduction) : explorer les données et le dépôt de codes
Le Programme international pour le suivi des acquis des élèves (PISA) est une initiative internationale qui mesure les réalisations en éducation des élèves de 15 ans. Ce jeu de données (en anglais uniquement) libre d’accès est disponible aux chercheuses et chercheurs qui mènent leurs propres analyses. Cette activité utilise une analyse du jeu de données du PISA menée par Klajnerok (2021) et publiée dans GitHub à l’aide d’un cahier Jupyter.
Pour les fins de cette activité, nous avons créé une fourche à partir du dépôt de ce projet dans notre propre dépôt Git : https://github.com/mediagestalt/PISA (en anglais uniquement). Dans GitHub, une fourche (ou fork) représente une copie d’un jeu de données qui conserve son lien aux créateurs originaux (Documentation GitHub, s.d.). Dans la capture d’écran ci-dessous, vous pouvez voir le symbole de fourche et un lien vers le jeu de données qui le précède. Ces liens sont importants puisqu’ils démontrent la provenance du jeu de données.
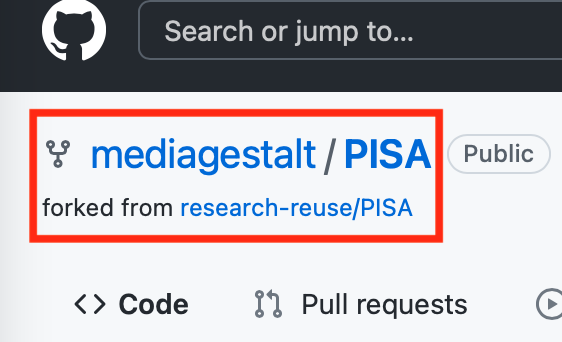
QUESTION 1: Quel est le nom du dépôt où ce code a été déposé à l’origine?
Réponse: Le créateur d’origine de ce code est : <https://github.com/mklajnerok/PISA>.Pour ce projet, le code et les données ont été réutilisés par <https://github.com/research-reuse/PISA> et placées dans un conteneur informatique appelé Binder. Cette activité est une fourche de <https://github.com/research-reuse/PISA> et a été adaptée pour ce manuel. Le jeu de données original a été publié par PISA.
Vous pouvez naviguer sur GitHub comme vous le feriez avec tout autre répertoire de fichiers imbriqués. La figure 2 est une capture d’écran de GitHub. Les noms de fichiers figurent dans la colonne de gauche; la colonne du milieu montre le commentaire qui décrit les dernières modifications apportées au fichier et la colonne de droite indique la dernière fois que le fichier a été modifié. Vous pouvez également voir la dernière personne qui a contribué au dépôt de code en haut à gauche du tableau et les informations sur la version en haut à droite du tableau. Celles-ci sont illustrées dans la figure 2 avec le terme « 83 commits. »
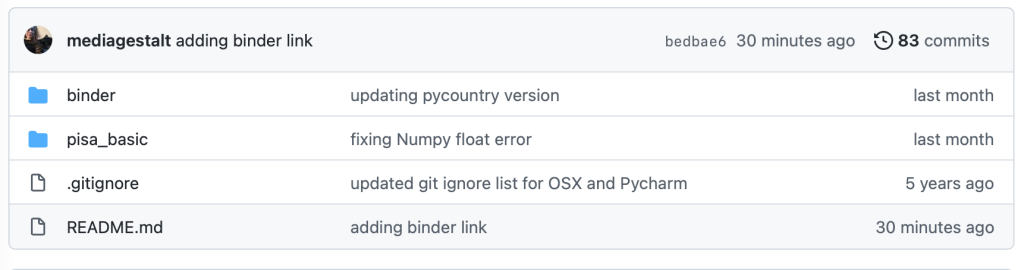
Dossiers GitHub
Pour la prochaine question, trouvez les fichiers suivants dans le dépôt du PISA. Vous trouverez les fichiers dans différents dossiers, donc n’hésitez pas à fouiller.
requirements.txtpisa_project_part1.ipynb
Cliquez sur le titre du fichier pour l’afficher. Puis, défilez vers le bas pour regarder le contenu de chacun des fichiers. Vous cherchez une liste de dépendances, c’est-à-dire les progiciels nécessaires a l’exécution du code dans le cahier. Dans le fichier pisa_project_part1.ipynb, vous trouverez la liste sous le titre « Extracting PISA dataset » comme le montre l’image ci-dessous.

QUESTION 2: Comparez les dépendances énumérées dans le fichier requirements.txt avec celles du cahier pisa_project_part1.ipynb. De quelles façons sont-elles différentes?
Réponse: Le fichier requirements.txt comprend des numéros de version des dépendances tandis que le fichier du carnet ne fait que lister leur nom. L’information sur le versionnage est très importante pour les dépendances, car des changements inconnus effectués sur le code peuvent l’empêcher de fonctionner correctement. Il s’agit ici d’un scénario où mettre à jour la plus récente version d’un programme n’est pas la meilleure option. Effectuer la curation de code à des fins de réutilisation équivaut essentiellement à « geler » le code dans le temps afin qu’il roule exactement de la même manière que lorsqu’il a été créé.
Les noms de fichiers et leurs répertoires démontrent l’importance des chemins d’accès relatifs. Dans le répertoire Git, trouvez l’emplacement des fichiers CSV suivants. Faites-les correspondre à l’endroit où ils sont nommés dans le fichier du cahier.
- pisa_math_2003_2015.csv;
- pisa_read_2000_2015.csv;
- pisa_science_2006_2015.csv. Indice : les fichiers se trouvent dans la deuxième cellule de code sous les dépendances.
Partie 2 (avancée): Exécuter et modifier le code
C’est le temps d’explorer le conteneur informatique. Puisque le chercheur original a écrit le code dans un cahier Jupyter (une sorte de cahier de laboratoire électronique couramment utilisé), il est possible de mettre en conteneur le code et les données pour qu’ils puissent être utilisés par d’autres.
Revenez à la page principale du dépôt GitHub aussi connu sous le nom de « README » (ou LISEZ-MOI). Cliquez sur le bouton « launch binder », tel qu’illustré dans la figure 4.
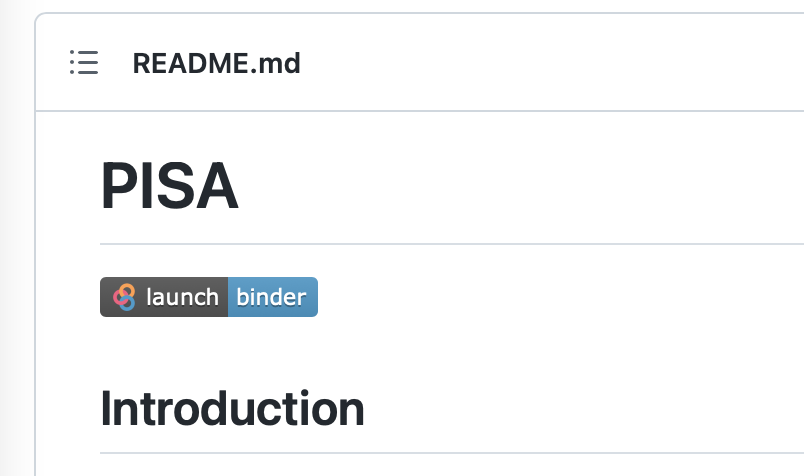
Selon votre ordinateur ou votre vitesse Internet, le chargement du conteneur peut prendre quelques minutes. Si cela prend trop de temps, fermez la page et essayez de lancer à nouveau le chargement à partir du lien GitHub Binder. Vous pouvez voir l’écran de chargement du Binder à la figure 5.

Lorsque le chargement du cahier est terminé, défilez vers le bas et explorez la page. Le cahier chargé ressemble exactement au cahier consulté dans le dépôt Github.
Alors que vous examinerez le cahier, vous verrez du texte narratif parsemé de cellules de blocs de code. Des commentaires supplémentaires se retrouvent à l’intérieur des cellules de code. Il s’agit là d’un exemple de programmation lettrée.
Afin de faciliter la suite de l’activité, activez la fonction de numérotation des lignes dans le fichier. Les numéros de chacune des lignes de blocs de code seront affichés, permettant d’identifier plus facilement des lignes de code spécifiques. L’emplacement de cette commande est indiqué à la figure 6. Vous ne verrez pas de changement immédiat sur la page, car il s’agit simplement d’un changement de paramètre.
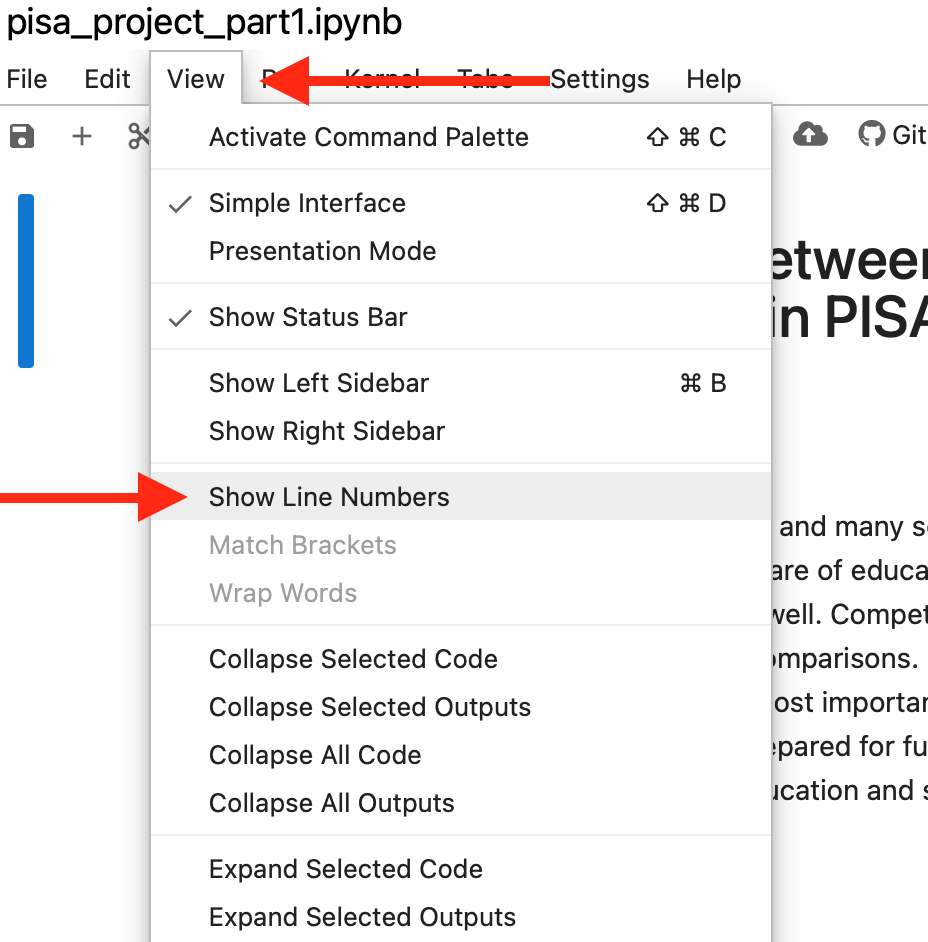
C’est maintenant le temps d’exécuter le code. Pour débuter, exécutez toutes les cellules de code. L’emplacement de cette commande est indiqué à la figure 7. En faisant défiler la page, vous trouverez du nouveau contenu sous quelques-uns des blocs de code. Il s’agit des résultats de l’analyse pour laquelle le code a été écrit. Il peut s’agir de texte, de tableaux ou de visualisations.
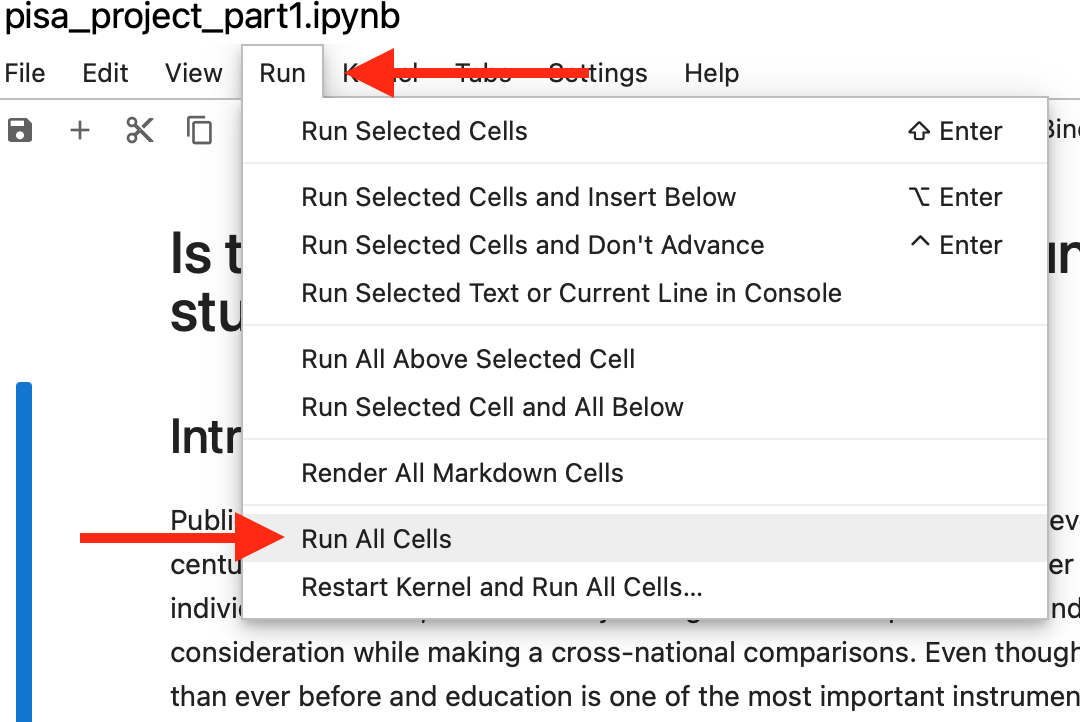
Vous verrez également un numéro entre crochets dans la marge gauche à côté de chaque bloc de code. Commencez la lecture au début de la page et rendez-vous à la cellule numéro 6. Si vous n’arrivez pas à comprendre le code, ne vous en faites pas. Portez plutôt votre attention sur les descriptions textuelles et sur les commentaires à l’intérieur des cellules. Un commentaire est facile à identifier parce qu’il est précédé du symbole [#] ou [“””]. Lisez les descriptions narratives jusqu’à la cellule n° 6. Voir la figure 8.
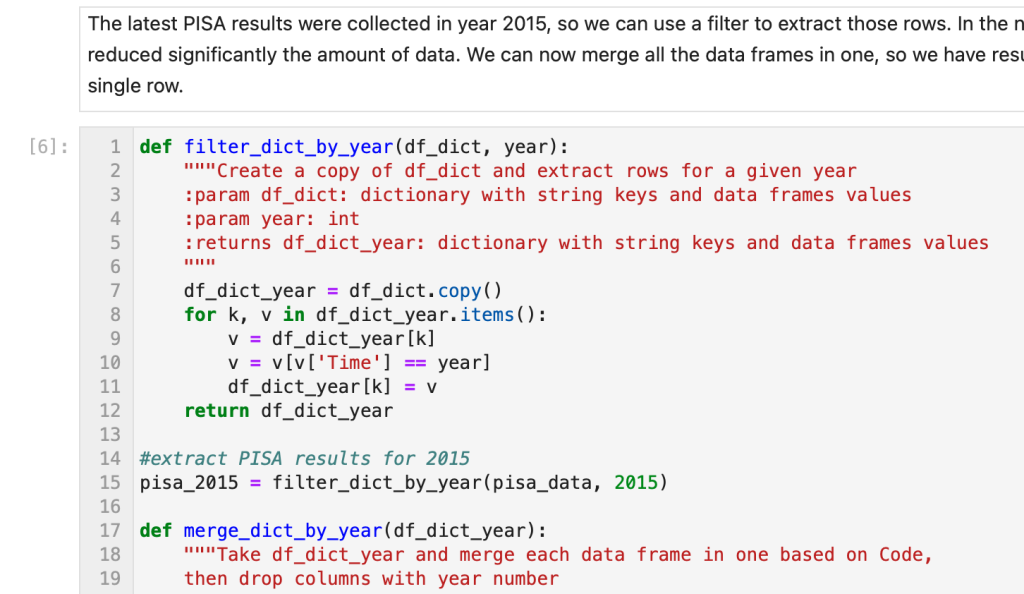
Réponse: « #extract PISA results for 2015. » C’est-à-dire, extraire les résultats du PISA pour 2015. Indice: si vous ne l’avez pas trouvé, utilisez la fonction « Rechercher » de votre navigateur pour rechercher la phrase. Vous verrez alors le numéro de la ligne et de la cellule.
Le jeu de données du PISA pour ce projet comporte des données qui remontent à l’année 2000. Nous pouvons charger plus de données en modifiant le code. Pour la suite de cette activité, vous devez ajouter un nouveau code au cahier de laboratoire électronique et réexécuter le bloc de code. Pour obtenir les lignes de code supplémentaires, consultez cet extrait de code (appelé un Gist) sur GitHub. Il s’agit d’une version modifiée de la cellule 6 du cahier.
La ligne 14 du Gist et la ligne 14 du bloc de code 6 du cahier sont identiques. Le ‘#’ devant le texte signifie que la ligne est un commentaire et non du code. C’est à la ligne 15 que le code commence. Dans ce Gist, il y a des lignes de code supplémentaires en dessous de la ligne 15 qui n’apparaissent pas dans le cahier. Copiez le code des lignes 16 et 17 et collez-les dans le cahier. Assurez-vous que le cahier correspond aux lignes 14-17 du Gist.
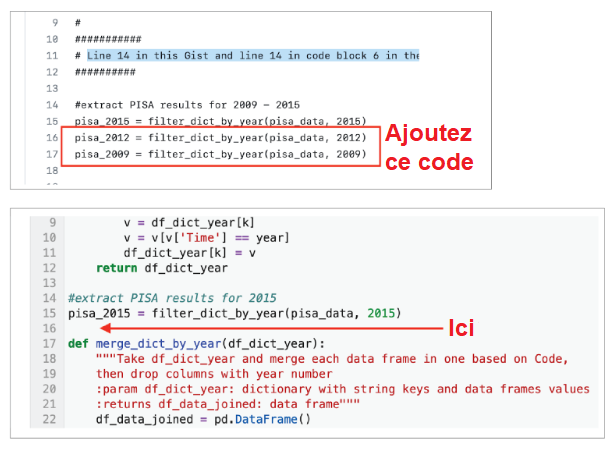
Ce code fait appel au jeu de données PISA. Avant l’ajout des lignes supplémentaires, les données de PISA ne concernaient que l’année 2015. L’ajout des deux lignes de code supplémentaires importe des années supplémentaires de données PISA, soit 2012 et 2009. Si vous souhaitez expérimenter davantage, vous pouvez ajouter des lignes supplémentaires avec des années différentes. Veillez simplement à suivre le format à la lettre.
Il ne suffit pas d’ajouter ces lignes. Vous allez devoir suivre le même processus pour les lignes 31 et 40. Ce code et d’autres instructions peuvent également être trouvés dans le Gist. Notez que les numéros de ligne dans le cahier changeront lorsque vous ajouterez du code supplémentaire.
Une fois que les paramètres supplémentaires ont été ajoutés au cahier, exécutez une nouvelle fois la cellule 6 du cahier en cliquant sur la cellule et en appuyant sur la touche Majuscule + Retour. En cas d’erreurs, vérifiez que votre code ne contient pas de fautes de frappe et essayez à nouveau. Vous pouvez également utiliser la commande de menu « Run > Run Selected Cells ».
À partir de maintenant, les numéros de cellules du cahier vont changer selon le nombre de fois que vous exécutez le code de la cellule.
Ensuite, laissez votre curseur sur la cellule que vous venez de modifier et insérez une nouvelle cellule pour chacune des années supplémentaires que vous avez ajoutées.
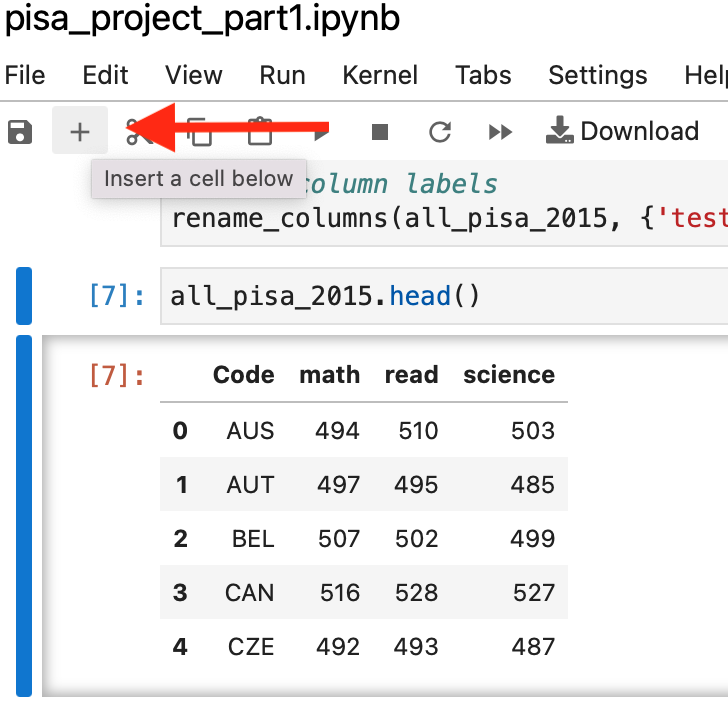
Dans les nouvelles cellules, inscrivez le nom des variables supplémentaires pour chacune des années que vous avez ajoutées et appuyez sur la touche Majuscule + Retour pour exécuter chacune d’elles.
Par exemple:
all_pisa_2012.head()
all_pisa_2009.head()
En cas d’erreurs, cherchez les fautes de frappe et essayez à nouveau.
Essayez de voir combien de cellules de plus vous pouvez faire fonctionner! Tant avec les variables existantes qu’avec les nouvelles que vous avez créées.
Si vous faites une erreur qui entraîne une défaillance irréparable dans le code, vous pouvez consulter le fichier source pour recopier et coller le code original. Vous pouvez aussi recharger le fichier au complet en sélectionnant « File > Reload Notebook from Disk » dans le menu principal du carnet.
Questions de réflexion
Selon ce que vous avez retenu du chapitre 10 et par votre exploration du conteneur informatique, quelles modifications apporteriez-vous à la structure du répertoire de fichiers pour en améliorer l’organisation ? Les données et logiciels sont-ils suffisamment documentés ? Passez à travers ce cadre pour la reproductibilité: Reproducibility Framework (Khair et al., 2019) pour vous aider dans votre évaluation.
-
- La provenance de ces données est-elle claire pour vous? Expliquez.
- Quelles caractéristiques de ce jeu de données ont facilité sa reproductibilité? Qu’est-ce que vous voudriez améliorer?
Bibliographie
Documentation GitHub. (s.d.). Fork a repo. https://docs.github.com/fr/get-started/quickstart/fork-a-repo
Klajnerok, M. (2021, 23 novembre). Is there a relationship between countries’ wealth or spending on schooling and its students’. Towards Data Science. https://towardsdatascience.com/is-there-a-relationship-between-countries-wealth-or-spending-on-schooling-and-its-students-a9feb669be8c
Khair, S., Sawchuk, S. et Zhang, Q. (2019) Reproducibiity Framework. https://docs.google.com/document/d/1E0c5-DDVo2MMoF2rPOiH2brIZyC_3YZZrcgp0x6VCPs/edit
Type d’outil en ligne basé sur la conception et l’utilisation des cahiers de laboratoire papier.
Dans GitHub, copie d’un jeu de données qui conserve son lien vers la création originale.
Documentation faisant référence à la source, l’historique et la propriété d’un artéfact, que celui-ci soit analogique ou numérique.
Document qui fournit des renseignements à propos d’un fichier ou d’un jeu de données. Il permet d’assurer la pérennité de l’interprétation correcte des données par toutes les personnes qui les consulteront.
Affichage de façon linéaire de code, commentaires et sorties, un peu comme une œuvre de littérature.
