27 Le modèle logique
La modélisation des données est la première étape du processus de conception d’une base de données. Cette étape est parfois considérée comme une phase de conception de haut niveau et abstraite, également appelée élaboration du modèle conceptuel. L’objectif de cette phase est de décrire :
- Les données contenues dans la base de données (par exemple, les entités : étudiants, enseignants, cours, matières)
- Les relations entre les éléments de données (par exemple, les étudiants sont supervisés par des professeurs ; les professeurs enseignent des cours)
- Les contraintes sur les données (par exemple, le numéro d’étudiant a exactement huit chiffres ; une matière n’a que quatre ou six unités de crédit)
Dans la deuxième étape, les éléments de données, les relations et les contraintes sont tous exprimés à l’aide des concepts fournis par le modèle de données de haut niveau. Comme ces concepts n’incluent pas les détails de mise en œuvre, le résultat du processus de modélisation des données est une représentation (semi) formelle de la structure de la base de données. Ce résultat est assez facile à comprendre et est donc utilisé comme référence pour s’assurer que toutes les exigences de l’utilisateur sont satisfaites.
La troisième étape est la conception de la base de données. Au cours de cette étape, nous pouvons avoir deux sous-étapes : l’une appelée conception du modèle logique de la base de données, qui définit une base de données dans un modèle de données d’un SGBD spécifique, et l’autre appelée conception du modèle physique de la base de données, qui définit la structure de stockage interne de la base de données, l’organisation des fichiers ou les techniques d’indexation. Ces deux sous-étapes sont les étapes de mise en œuvre de la base de données et de construction des opérations/interfaces utilisateur.
Dans les phases de conception de la base de données, les données sont représentées à l’aide d’un certain modèle de données. Le modèle de données est un ensemble de concepts ou de notations permettant de décrire les données, leurs relations, leur sémantique et leurs contraintes. La plupart des modèles de données comprennent également un ensemble d’opérations de base pour manipuler les données dans la base de données.
Degrés d’abstraction des données
Dans cette section, nous allons examiner le processus de conception des bases de données en termes de spécificité. Tout comme chaque conception commence à un niveau élevé et progresse vers un niveau de détail sans cesse croissant, il en va de même pour la conception de bases de données. Par exemple, lorsque vous construisez une maison, vous commencez par déterminer le nombre de chambres et de salles de bains qu’elle comportera, si elle sera sur un ou plusieurs niveaux, etc. L’étape suivante consiste à demander à un architecte de concevoir la maison d’un point de vue plus structuré. Ce niveau devient plus détaillé en ce qui concerne la taille réelle des pièces, la façon dont la maison sera câblée, l’emplacement des appareils de plomberie, etc. La dernière étape consiste à embaucher un entrepreneur pour construire la maison. Cela revient à considérer la conception à partir d’un haut niveau d’abstraction vers un niveau de détail croissant.
La conception d’une base de données ressemble beaucoup à cela. Elle commence par l’identification des règles d’affaires par les utilisateurs ; ensuite, les concepteurs et les analystes de la base de données créent le modèle de la base de données ; puis l’administrateur de la base de données implémente la conception à l’aide d’un SGBD.
Les sous-sections suivantes résument les modèles par ordre décroissant de niveau d’abstraction.
Modèles externes
- Représentent la vue de la base de données par l’utilisateur
- Contiennent plusieurs vues externes différentes
- Sont étroitement liés au monde réel tel qu’il est perçu par chaque utilisateur
Modèles conceptuels
- Fournissent des capacités flexibles de structuration des données
- Présentent une « vue communautaire » : la structure logique de l’ensemble de la base de données
- Contiennent des données stockées dans la base de données
- Montrer les relations entre les données, notamment :
- Contraintes
- Informations sémantiques (p. ex., règles d’affaires)
- Informations sur la sécurité et l’intégrité
- Considèrent une base de données comme une collection d’entités (objets) de différents types
- Constituent la base de l’identification et de la description de haut niveau des principaux objets de données ; ils évitent les détails
- Sont indépendants de la base de données, quelle que soit la base de données que vous utiliserez
Modèles internes
Les trois modèles les plus connus de ce type sont le modèle de données relationnel, le modèle de données réseau et le modèle de données hiérarchique. Ces modèles internes:
- Considèrent une base de données comme une collection d’enregistrements de taille fixe
- Sont plus proches du niveau physique ou de la structure du fichier
- Sont une représentation de la base de données telle que vue par le SGBD
- Exigent du concepteur qu’il fasse correspondre les caractéristiques et les contraintes du modèle conceptuel à celles du modèle de mise en œuvre sélectionné
- Impliquent la mise en correspondance des entités du modèle conceptuel aux tables du modèle relationnel
Modèles physiques
- Sont la représentation physique de la base de données
- Ont le plus bas niveau d’abstraction
- Sont la façon dont les données sont stockées ; ils traitent des aspects suivants :
- Performance d’exécution
- Utilisation du stockage et compression
- Organisation des fichiers et méthodes d’accès
- Cryptage des données
- Sont le niveau physique – géré par le système d’exploitation (operating system [OS])
- Fournissent des concepts qui décrivent les détails de la façon dont les données sont stockées dans la mémoire de l’ordinateur
Connectez vos données avec un modèle de données relationnelles
Définissez les structures logiques d’une entité
Maintenant que vous avez compris les principes de base des entités, des attributs et des types de données, commençons à élaborer un plan de base de données !
Le modèle de données relationnelles permet de s’assurer que les données ne sont saisies ou mises à jour qu’à un seul endroit, évitant ainsi à la base de données des problèmes potentiels. Cela dit, il se compose d’un certain nombre de tables liées qui donnent accès à toutes les données relatives à un enregistrement ou à un ensemble d’enregistrements particulier.
N’oubliez pas que les entités sont des éléments uniques qui peuvent être décrits comme des livres, des auteurs, des clients, des commandes, etc. Elles s’écrivent généralement avec une majuscule et se traduisent par des tables de base de données où elles sont souvent divisées en deux ou plusieurs tables lorsque vous normalisez (mettez à jour les données à un seul endroit).

Exemple d’entité avec ses attributs
Une instance d’entité est une occurrence unique d’une entité et équivaut à un enregistrement dans la base de données. Dans l’exemple ci-dessous, la table Éditeurs, suivie d’un enregistrement de cette table définie par la clé primaire IDEditeur, dont la valeur est 1 dans cette instance.
![]()
Exemple d’instance d’entité
L’idée d’une entité s’appuie sur les types d’entités, qui sont des collections de deux ou plusieurs tables possédant des attributs similaires. Elles décrivent souvent des données très similaires ou liées, comme dans le type d’entité ci-dessous : la table Client avec les détails du client, la table Commandes avec les détails de la commande et la table CommandeDetails avec les détails des articles pour chaque commande.
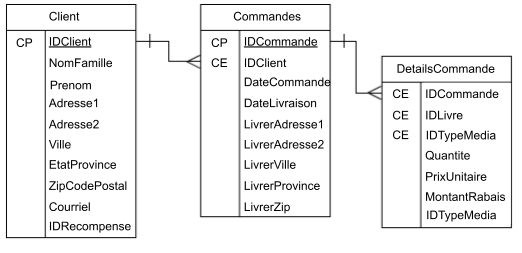
Exemple d’un type d’entité.
Définissez les clés primaires et étrangères
La clé primaire est l’attribut qui identifie de manière unique un enregistrement dans une table.
La clé étrangère est cette même valeur unique, mais dans une table différente, fournissant un lien entre les deux tables.
Les clés primaires sont presque toujours numériques et sont souvent générées automatiquement par le système de gestion de base de données lorsqu’un nouvel enregistrement est inséré. C’est généralement l’un des moyens les plus simples de maintenir des valeurs de clé primaire uniques et cohérentes, sans que les personnes qui construisent ou maintiennent les tables aient à s’inquiéter.
Dans les diagrammes ci-dessus, CP identifie les clés primaires et CE identifie les clés étrangères. Par exemple, dans la table Commandes ci-dessus, l’attribut IDCommande est l’identifiant unique de cette table, il est donc défini comme clé primaire. L’attribut IDClient renvoie à la table Clients, où IDClient est défini comme la clé primaire de cette table. Dans la table Commandes, IDClient est donc défini comme une clé étrangère.
Éléments clés à retenir
- Les entités sont les éléments constitutifs du processus de conception logique et sont tout ce qui peut être décrit.
- Une instance d’entité est une occurrence unique d’une entité.
- Les types d’entités sont des collections de deux ou plusieurs entités ayant des propriétés similaires.
- Les clés primaires identifient de manière unique un enregistrement dans une base de données.
- Les clés étrangères sont le lien entre une table et la clé primaire d’une autre table.
Maintenant que nous connaissons les modèles de données relationnelles et les clés primaires et étrangères qui relient vos données, abordons les contraintes qui vous aideront à gérer vos relations de données.
Identifiez les contraintes d’intégrité de la base de données
Nous avons vu les éléments de base des entités, y compris les clés primaires, les clés étrangères et les types d’entités. Il est temps de développer ces idées pour voir comment garder votre base de données intacte et fournir des données exactes pour les années à venir.
L’intégrité de l’entité et pourquoi c’est important
Les bases de données relationnelles reposent sur l’idée que les tables sont liées les unes aux autres par des clés primaires et étrangères.
La clé primaire est utilisée comme identifiant unique pour une table. Deux enregistrements ou lignes ne peuvent pas avoir la même valeur pour la clé primaire. Si c’est le cas, il y aura des problèmes avec la qualité des données, et il sera très difficile de maintenir la base de données à l’avenir. Si les clés primaires ne sont pas uniques, vous ne saurez pas quels enregistrements correspondent vraiment à quelle clé primaire.
La clé primaire et tous les éléments qui la composent ne peuvent pas être nuls. Le SGBD applique l’intégrité de l’entité en n’autorisant aucune opération, telle que l’insertion ou la mise à jour, de produire une clé primaire qui viole ces règles. Les opérations de base de données qui produisent une valeur nulle ou non unique pour la clé primaire seront rejetées et le SGBD générera un message d’erreur. Dans la plupart des cas, il indiquera que l’intégrité de l’entité a été violée et que l’action ne validera pas les mauvaises données.
Jetez un coup d’œil à l’exemple ci-dessous. Voyez-vous des problèmes avec l’intégrité de l’entité ?
|
IDEditeur |
Nom |
Telephone |
Courriel |
SiteWeb |
|
1 |
American University in Cairo Press |
Null |
Null |
|
|
Null |
Michigan State University Press |
Null |
||
|
2 |
Westminster John Knox Press |
5551234 |
Null |
Null |
Dans cet exemple, l’intégrité de l’entité est violée car il n’y a pas de valeur pour la clé primaire dans la deuxième ligne (la valeur pour IDEditeur est manquante et nulle).
L’intégrité référentielle et son rapport avec les entités
L’intégrité référentielle définit les règles de gestion des clés étrangères. La clé étrangère doit faire référence à une clé primaire existante ou contenir une valeur nulle. Les clés étrangères ne sont souvent pas nécessaires, il est donc acceptable d’avoir une valeur nulle, mais pas dans un champ de clé primaire.
Le SGBD a également des règles pour empêcher la modification des valeurs de clé primaire sans modifier également la valeur de clé étrangère pour qu’elle corresponde. Aucune opération de mise à jour ou de suppression ne peut être effectuée sur un champ de clé primaire si la valeur de clé étrangère existe.
Cela permet d’éviter les enregistrements orphelins (données inutilisables), qui résultent du fait qu’une clé étrangère n’a pas de clé primaire à laquelle se référer.
De même, le SGBD empêcherait l’insertion ou la mise à jour d’un champ de clé étrangère qui entraînerait un enregistrement orphelin lorsqu’il n’y a pas de clé primaire correspondante. On pourrait dire qu’il y a un lien rompu entre la clé primaire et la clé étrangère puisque la clé étrangère n’a pas de valeur équivalente dans la table avec la clé primaire. La seule exception à cette règle est le paramétrage d’un champ de clé étrangère pour qu’il ne contienne pas de valeurs nulles, ce qui forcerait la valeur à être autre chose que nulle, et à avoir un champ de clé primaire correspondant dans une autre table.
Jetez un coup d’œil à l’exemple ci-dessous. Voyez-vous des problèmes d’intégrité référentielle ?
Table Auteurs
|
IDAuteur |
NomFamille |
Prenom |
|
1 |
Austen |
Jane |
|
2 |
Patterson |
James |
|
4 |
King |
Stephen |
Table LivreAuteur
|
IDAuteur |
IDLivre |
|
1 |
12 |
|
2 |
15 |
|
3 |
222 |
|
4 |
259 |
Dans cet exemple, l’intégrité référentielle est violée car il existe un lien brisé entre les deux tables. La clé étrangère IDAuteur dans la table LivreAuteur renvoie à la clé primaire IDAuteur dans la table Auteurs, mais la ligne contenant les informations pour la valeur IDAuteur de 3 n’a rien à quoi se référer ! Cette ligne de données est un enregistrement orphelin.
Éléments clés à retenir
- L’intégrité d’entité empêche le champ de la clé primaire d’être nul ou vide, ce qui est appliqué par le SGBD.
- L’intégrité référentielle garantit que les valeurs de la clé étrangère correspondent aux valeurs de la clé primaire d’une autre table.
- Les enregistrements orphelins résultent des liens brisés qui se forment lorsqu’il n’y a pas de clé primaire correspondante pour une clé étrangère existante.
Définissez les règles d’affaires
Les règles d’affaires sont obtenues auprès des utilisateurs lors de la collecte des exigences. Le processus de collecte des exigences est très important et ses résultats doivent être vérifiés par l’utilisateur avant la conception de la base de données. Si les règles d’affaires sont incorrectes, la conception sera incorrecte et, au final, l’application construite ne fonctionnera pas comme prévu par les utilisateurs.
Voici quelques exemples de règles d’affaires :
- Un enseignant peut enseigner plusieurs élèves.
- Une classe peut avoir au maximum 35 élèves.
- Un cours peut être enseigné plusieurs fois, mais par un seul enseignant.
- Tous les enseignants ne donnent pas de cours.
Réfléchissez aux cardinalités des associations

Schéma de l’association et de la cardinalité entre deux tables
Nous discuterons davantage des relations au chapitre concernant Access. Pour l’instant, passons aux types de dépendances.
Précisez les types de dépendances
Dépendances fonctionnelles
Une dépendance fonctionnelle (DF) est une relation entre deux attributs, généralement entre la CP et d’autres attributs non clés dans une table. Pour toute relation R, l’attribut Y est fonctionnellement dépendant de l’attribut X (généralement la CP), si pour toute instance valide de X, cette valeur de X détermine de manière unique la valeur de Y. Cette relation est indiquée par la représentation ci-dessous :
X ———–> Y
Le côté gauche du diagramme de DF ci-dessus est appelé le déterminant et le côté droit est le dépendant. Voici quelques exemples.
Dans le premier exemple ci-dessous, le numéro d’assurance sociale (NAS) détermine le nom, l’adresse et la date de naissance. À partir du NAS, nous pouvons déterminer n’importe lequel des autres attributs de la table.
Pour le deuxième exemple, le NAS et le Cours déterminent la date d’achèvement (DateAchèvement). Cela doit également fonctionner pour une CP concaténée.
Le troisième exemple indique que l’ISBN détermine le titre.
Maintenant que nous comprenons les dépendances fonctionnelles, apprenons comment optimiser la conception d’une base de données : avec la normalisation !
Construisez une base de données solide grâce à la normalisation
Nous avons couvert la plupart des concepts de base pour la conception d’un modèle logique, y compris ceux qui permettent de maintenir les données ensemble et de les garder exactes. Nous passons maintenant à quelques concepts finaux mais critiques pour nous assurer que vos données sont atomiques et restent intactes.
Découvrez la normalisation et son importance
La normalisation est une autre étape du processus de conception qui permet de s’assurer que vos données sont faciles à maintenir et à mettre à jour sans trop se soucier qu’elles soient stockées à plusieurs endroits ou mises à jour partout. L’un des principaux concepts d’une base de données relationnelle est la capacité de stocker, de mettre à jour et de manipuler les données à un seul endroit, ce qui élimine pratiquement tout risque de duplication ou d’obsolescence des données.
Vous normalisez les tables de votre base de données pour deux raisons principales :
- Pour éliminer la redondance des données.
- Pour vous assurer que vous disposez d’entités logiques, c’est-à-dire que toutes les données liées sont stockées logiquement et ensemble.
Non, car il n’y a aucune garantie que vous ayez éliminé toutes les anomalies. Avec le processus de normalisation, vous déterminez où les attributs sont regroupés pour former des entités qui ont le moins de chance de produire des anomalies de données et la meilleure chance d’avoir une base de données cohérente qui fonctionne comme prévu.
Examinez le casse-tête des tables de base de données non normalisées
Comme vous pouvez l’imaginer, une base de données non normalisée comporte des tables qui peuvent contenir des données en double à plusieurs endroits et qui finissent par devenir un casse-tête à gérer. Dans certains cas, il peut être impossible de mettre à jour toutes les données en double. Comme vous pouvez le deviner, cela se traduirait par des enregistrements d’une fiabilité et d’une précision très médiocres, aboutissant à un système que peu de gens voudraient utiliser en raison de son incohérence.
Les tables non normalisées occupent plus d’espace de stockage et encombrent les tables existantes avec des entrées de table inutiles. D’autres problèmes peuvent survenir, comme la lenteur des temps de réponse aux requêtes ou aux autres transactions, l’inexactitude des données extraites ou des résultats inattendus.
Dans l’ensemble, la maintenance et l’utilisation de la base de données deviendraient inefficaces. Les problèmes continueraient de croître au fil du temps, à mesure que des données seraient ajoutées.
Éléments clés à retenir
- La normalisation permet de s’assurer que les données en double ne sont enregistrées nulle part dans la base de données.
- Le processus de normalisation conduit souvent à la création de tables supplémentaires pour éviter la duplication de données.
Nous avons appris les bases de la normalisation. Passons pas à pas à la réalisation de la première, deuxième et troisième forme normale.
Normalisez aux première, deuxième et troisième formes normales
Normalisez votre base de données en 1FN
La première forme normale élimine les groupes répétitifs. Cela signifie que les attributs à valeurs multiples ont été supprimés et qu’il n’y a qu’une seule valeur au carrefour où l’enregistrement de la table et la colonne se rejoignent. Les clés primaires sont également établies avec la première forme normale ; identifiant de manière unique les enregistrements d’une table.
La 1FN existe si ces deux critères sont remplis :
- Une clé primaire a été définie pour identifier de manière unique les enregistrements.
- Il n’y a pas de groupes répétitifs dans la relation.
Vous commenceriez avec une collection d’enregistrements égale à ce que vous pourriez organiser et mettre dans une feuille de calcul, par exemple. C’est ainsi que vous prépareriez vos données pour la conversion pendant le processus de normalisation. Si vous vous intéressez toujours aux livres, vous pouvez voir l’exemple ci-dessous qui contient des informations sur les livres, y compris les médias disponibles tels que le format imprimé, le livre électronique ou en ligne. À partir de là, vous pouvez transformer les données en quelque chose de mieux adapté à une utilisation en base de données.
Table Livres (avec groupes répétitifs)
|
Titre |
TypeMedia |
|
Conception de bases de données |
Imprimé, livre électronique, |
|
PHP |
Livre électronique |
|
Introduction à la programmation |
Imprimé, livre électronique, en ligne |
Puisque la colonne TypeMedia avait des types répétitifs, la première chose à faire est de créer un enregistrement pour chaque groupe unique d’enregistrements et de les rassembler dans une nouvelle table pour les médias.
Une fois cela fait, vous pouvez établir une clé primaire sur la table Livres comme IDLivre. Vous savez ainsi que chaque enregistrement est unique.
Pour normaliser davantage la table, vous pouvez remplacer le mot qui décrit le type de média par un nombre qui correspond à la nouvelle table Media. Convertissez le champ TypeMedia en IDMedia, servant de clé étrangère dans la table Livres et faisant référence à la clé primaire de la table Media.
Table Livres (1FN)
|
(CP) IDLivre |
Titre |
(CE) IDMedia |
|
1 |
Conception de bases de données |
1 |
|
2 |
Conception de bases de données |
2 |
|
3 |
PHP |
2 |
|
4 |
Introduction à la programmation |
1 |
|
5 |
Introduction à la programmation |
2 |
|
6 |
Introduction à la programmation |
3 |
Table Media (1FN)
|
(CP) IDMedia |
Media |
|
1 |
Imprimé |
|
2 |
Livre électronique |
|
3 |
En ligne |
Normalisez votre base de données en 2FN
Utilisez les normalisations précédentes tout en continuant à normaliser vos données. Cela signifie que la deuxième forme normale (2FN) doit répondre aux exigences de la 1FN. De plus, 2FN exige que les dépendances fonctionnelles partielles soient supprimées. Cela crée de nouvelles entités mieux groupées.
La 2FN existe si ces deux critères sont remplis :
- La relation est en 1FN.
- Les dépendances fonctionnelles partielles sont supprimées.
Bonne question !
Les attributs d’une table doivent tous dépendre de la clé primaire.
Par exemple, une table Commandes comme celle ci-dessous aurait une clé primaire IDCommande. Les autres champs, tels que DateCommande, IDClient, etc., doivent être entièrement dépendants de la clé primaire et de rien d’autre.
|
IDCommande |
DateCommande |
IDClient |
NomFamille |
Adresse |
IDLivre |
Titre |
Prix |
Quantite |
Vous avez une dépendance fonctionnelle partielle lorsqu’un attribut ne dépend que partiellement de la clé primaire, comme vous l’avez probablement deviné ! Mais il faut une certaine expérience pour être capable de repérer les dépendances fonctionnelles partielles et de déterminer où une table pourrait être divisée en deux ou plusieurs tables distinctes.
Reprenons l’exemple.
Dans la table Commandes, les informations sur les livres (IDLivre, Titre et Prix) ne dépendent que partiellement de la clé primaire, IDCommande. Un livre peut être associé à plusieurs commandes.
Dans ce cas, vous diviseriez la table en trois tables distinctes, comme indiqué ci-dessous :
Table Commandes (2FN)
|
IDCommande |
DateCommande |
IDClient |
NomFamille |
Adresse |
Table LivresCout (3FN)
|
IDCommande |
Titre |
Prix |
Table LivreCommandeQuantite (3FN)
|
IDCommande |
IDLivre |
Quantite |
La table est transformée de la première forme normale à la deuxième forme normale. (LivreCommandeQuantite et LivresCout sont déjà dans la troisième forme normale puisque vous ne pouvez par normaliser les tables davantage.)
Si vous conserviez ces champs dans la table Commandes, vous vous retrouveriez avec des groupes répétitifs, que vous devez éliminer pour répondre aux critères 1FN.
En outre, la quantité dépend à la fois de IDCommande et de IDLivre. Dans la table LivreCommandeQuantite, les champs IDCommande et IDLivre forment une clé primaire composite, ce qui signifie que les deux champs constituent ensemble la clé primaire. Dans la table, tous les attributs non clés (ici uniquement l’attribut Quantite) doivent dépendre entièrement de cette clé primaire composite.
Normalisez votre base de données en 3FN
Comme mentionné, vous devez vous appuyer sur la forme normale précédente lorsque vous normalisez vos données. La troisième forme normale (3FN) doit répondre aux exigences de la 2FN. De plus, vous devez supprimer toutes les dépendances fonctionnelles transitives.
La 3FN existe si ces deux critères sont remplis :
- La relation est en 2FN.
- Les dépendances fonctionnelles transitives sont supprimées.
Les dépendances fonctionnelles transitives sont des valeurs qui ne dépendent pas du tout de la clé primaire de la table, mais plutôt d’un ou plusieurs autres champs de la table.
Examinons l’exemple suivant. Pouvez-vous repérer les dépendances fonctionnelles transitives qui subsistent ?
Table Commandes (avec dépendances fonctionnelles transitives)
|
IDCommande |
DateCommande |
IDClient |
NomFamille |
Adresse |
NomFamille et Adresse dépendent du champ IDClient, qui n’est pas un champ clé dans cette table.
La conversion de 2FN en 3FN est aussi simple que de diviser l’entité en deux ou plusieurs entités distinctes, avec des attributs similaires regroupés :
Table Commandes (3FN)
|
IDCommande |
DateCommande |
IDClient |
Table Clients (3FN)
|
IDClient |
NomFamille |
Adresse |
C’est une étape facile (avec un peu de pratique) ! Vous trouverez des dépendances fonctionnelles transitives lorsque les champs d’une table créent des données en double et ne sont pas identifiés de manière unique par la clé primaire. Ici, nous divisons une table en deux, et un examen plus approfondi montre qu’il n’y a pas de données redondantes ou dupliquées une fois que vous commencez à créer et à peupler les tables.
Éléments clés à retenir
- Les données doivent être organisées dans un format semblable à une feuille de calcul pour commencer le processus de normalisation.
- Supprimez les groupes répétitifs comme première étape de la transformation des données en 1FN (ordre des étapes recommandé).
- Établissez des clés primaires sur chaque table qui identifient de façon unique l’enregistrement pour qu’il soit en 1FN pour la dernière étape (ordre des étapes recommandé).
- La deuxième forme normale, 2FN, doit être en 1FN et sans dépendances fonctionnelles partielles.
- La troisième forme normale, 3FN, doit être en 2FN et sans dépendances fonctionnelles transitives.
Entraînez-vous en concevant un modèle entité-association
C’est votre tour !
Vous êtes prêt à concevoir une base de données d’employés !
Vous avez été embauché en tant que pigiste par une entreprise de 50 employés pour concevoir un modèle logique de base de données.
Créez un seul modèle entité-association pour concevoir une base de données avec les tables suivantes :
- Employé (avec toutes les informations de contact plus un référencement d’attribut)
- Département (IDDepartement, NomDepartement, etc.)
- Clients (Informations de contact similaires à celles de la table Employé)
- Personnes à charge (il s’agit des personnes à charge de l’employé, il faut donc inclure les attributs IDEmployé)
Définissez les tables (entités), les attributs, les types de données et toutes les données par défaut. Indiquez également les clés primaires et étrangères.
Bon succès !
Vérifiez votre travail !
Mettons le tout ensemble
Wow, nous avons couvert de nombreux nouveaux sujets, alors faisons un bref retour sur tout ce que vous avez appris.
- Nous avons commencé par le modèle de base de données relationnelle et nous avons exploré les termes entité, attribut et modèle entité-association.
- En explorant le système de gestion de base de données (SGBD) choisi, nous avons examiné les tables, les procédures stockées, les tâches et les déclencheurs, ainsi que leurs rôles dans le SGBD.
- Ensuite, nous sommes passés aux types de données et à la manière de les utiliser pour stocker des types de données spécifiques tels que les nombres, les dates et heures, les booléens et le texte. Le maintien de la cohésion de la base de données grâce aux règles d’intégrité de l’entité et d’intégrité référentielle a complété notre discussion.
- Enfin, nous avons exploré les raisons qui sous-tendent la normalisation et la manière de réaliser chacune des formes normales pour réduire la redondance et améliorer la durée de vie de la base de données dans son ensemble.
Maintenant que vous avez appris à concevoir le modèle logique de votre base de données relationnelle, vous êtes prêt à construire une véritable base de données ! Passez à la section suivante, où je vous guiderai tout au long du processus de construction, de remplissage et de maintenance de votre base de données avec des exemples dans Microsoft Access.
Watt, A. et Eng, N. (2014). Database Design – 2nd Edition. BCcampus. https://ecampusontario.pressbooks.pub/databasedesign02/front-matter/preface/
Wilkinson, V. (2020). Design the Logical Model of Your Relational Database. OpenClassrooms. https://openclassrooms.com/fr/courses/5671741-design-the-logical-model-of-your-relational-database
