9.3 Modeling Linear Relationships
If you know a person’s pinky (smallest) finger length, do you think you could predict that person’s height? Imagine collecting data on this and constructing a scatterplot of the points on graph paper. Then draw a line that appears to “fit” the data. For your line, pick two convenient points and use them to find the slope of the line. Find the y-intercept of the line by extending your line so it crosses the y-axis. Using the slopes and the y-intercepts, write your equation of “best fit.” According to your equation, what is the predicted height for a pinky length of 2.5 inches? You have just started the process of linear regression.
Linear Regression
Data rarely perfectly fit a straight line, but we can be satisfied with rough predictions. Typically, you have a set of data whose scatter plot appears to “fit” a straight line. This is called a Line of Best Fit or Least-Squares Line. This process of fitting the best-fit line is called linear regression.
The equation of the regression line is ŷ =a+bx
The ŷ is read “y hat” and is the estimated value of y. It is the value of y obtained using the regression line. It may or may not be equal to values of y observed from the data.
The sample means of the x values and the y values are  and
and  , respectively. The best fit line always passes through the point
, respectively. The best fit line always passes through the point  .
.
The slope, b can be written as  where sy = the standard deviation of the y values and sx = the standard deviation of the x values. r is the correlation coefficient, which is discussed in the next section.
where sy = the standard deviation of the y values and sx = the standard deviation of the x values. r is the correlation coefficient, which is discussed in the next section.
The y-intercept, a, can then be calculated by using the slope, and means of x and y.
Example
Recall our example:
A random sample of 11 statistics students produced the following data, where x is the third exam score out of 80, and y is the final exam score out of 200. Can you predict the final exam score of a random student if you know the third exam score?
| x (third exam score) | y (final exam score) |
|---|---|
| 65 | 175 |
| 67 | 133 |
| 71 | 185 |
| 71 | 163 |
| 66 | 126 |
| 75 | 198 |
| 67 | 153 |
| 70 | 163 |
| 71 | 159 |
| 69 | 151 |
| 69 | 159 |
Consider the following diagram. Each point of data is of the the form (x, y) and each point of the line of best fit using least-squares linear regression has the form (x, ŷ).
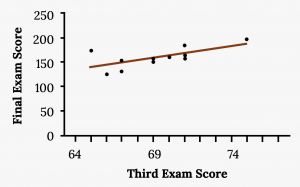
Your turn!
SCUBA divers have maximum dive times they cannot exceed when going to different depths. The data in the figure below show different depths with the maximum dive times in minutes. Use your calculator to find the least squares regression line and predict the maximum dive time for 110 feet.
| X (depth in feet) | Y (maximum dive time) |
|---|---|
| 50 | 80 |
| 60 | 55 |
| 70 | 45 |
| 80 | 35 |
| 90 | 25 |
| 100 | 22 |
Understanding Slope
The slope of the line, b, describes how changes in the variables are related. It is important to interpret the slope of the line in the context of the situation represented by the data. You should be able to write a sentence interpreting the slope in plain English.
INTERPRETATION: The slope of the best-fit line tells us how the dependent variable (y) changes for every one unit increase in the independent (x) variable, on average.
Example
[Previous Example Continued]
The slope of the line is b = 4.83.
Interpretation: For a one-point increase in the score on the third exam, the final exam score increases by 4.83 points, on average.
Understanding the Y-Intercept
The y-intercept of the line, a, can tell us what we would predict the value of y to be when x is 0. This may make sense in some cases, but in many it may not make sense for x to be equal to 0, therefore the y intercept may not be useful.
Example
[Previous Example Continued]
The y-intercept of the line is –173.51
Interpretation: In this context it does not really make sense for x to be 0 (unless a student did not take the exam or try at all). Therefore our y intercept does not make sense.
Prediction
The next, and most useful step in regression is to actually use that equation to predict future values of y.
Recall in our example we have examined the scatterplot and found the correlation coefficient and coefficient of determination. We found the equation of the best-fit line for the final exam grade as a function of the grade on the third-exam. We can now use the least-squares regression line for prediction.
Example
[Previous Example Continued]
Suppose you want to estimate, or predict, the mean final exam score of statistics students who received 73 on the third exam. The exam scores (x-values) range from 65 to 75. Since 73 is between the x-values 65 and 75, substitute x = 73 into the equation. Then:

What would you predict the final exam score to be for a student who scored a 66 on the third exam?
What would you predict the final exam score to be for a student who scored a 90 on the third exam?
Your turn!
Data are collected on the relationship between the number of hours per week practicing a musical instrument and scores on a math test. The line of best fit is as follows:
ŷ = 72.5 + 2.8x
What would you predict the score on a math test would be for a student who practices a musical instrument for five hours a week?
Image References
Figure 9.10: Kindred Grey via Virginia Tech (2020). “Figure 9.10” CC BY-SA 4.0. Retrieved from https://commons.wikimedia.org/wiki/File:Figure_9.10.png . Adaptation of Figure 12.11 from OpenStax Introductory Statistics (2013) (CC BY 4.0). Retrieved from https://openstax.org/books/introductory-statistics/pages/12-3-the-regression-equation
A mathematical model of a linear association
Tells us how the dependent variable (y) changes for every one unit increase in the independent (x) variable, on average
The value of y when x is 0 in your regression equation
A numerical measure that provides a measure of strength and direction of the linear association between the independent variable x and the dependent variable y
A numerical measure of the percentage or proportion of variation in the dependent variable (y) that can be explained by the independent variable (x)
