2 Matrix Algebra
Introduction
In the study of systems of linear equations in Chapter 1, we found it convenient to manipulate the augmented matrix of the system. Our aim was to reduce it to row-echelon form (using elementary row operations) and hence to write down all solutions to the system. In the present chapter we consider matrices for their own sake. While some of the motivation comes from linear equations, it turns out that matrices can be multiplied and added and so form an algebraic system somewhat analogous to the real numbers. This “matrix algebra” is useful in ways that are quite different from the study of linear equations. For example, the geometrical transformations obtained by rotating the euclidean plane about the origin can be viewed as multiplications by certain  matrices. These “matrix transformations” are an important tool in geometry and, in turn, the geometry provides a “picture” of the matrices. Furthermore, matrix algebra has many other applications, some of which will be explored in this chapter. This subject is quite old and was first studied systematically in 1858 by Arthur Cayley.
matrices. These “matrix transformations” are an important tool in geometry and, in turn, the geometry provides a “picture” of the matrices. Furthermore, matrix algebra has many other applications, some of which will be explored in this chapter. This subject is quite old and was first studied systematically in 1858 by Arthur Cayley.
2.1 Matrix Addition, Scalar Multiplication, and Transposition
A rectangular array of numbers is called a matrix (the plural is matrices), and the numbers are called the entries of the matrix. Matrices are usually denoted by uppercase letters:  ,
,  ,
,  , and so on. Hence,
, and so on. Hence,
![\begin{equation*} A = \left[ \begin{array}{rrr} 1 & 2 & -1 \\ 0 & 5 & 6 \end{array} \right] \quad B = \left[ \begin{array}{rr} 1 & -1 \\ 0 & 2 \end{array} \right] \quad C = \left[ \begin{array}{r} 1 \\ 3 \\ 2 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-fcd4005cd6628968209b06c26113a40f_l3.png "Rendered by QuickLaTeX.com")
are matrices. Clearly matrices come in various shapes depending on the number of rows and columns. For example, the matrix shown has  rows and
rows and  columns. In general, a matrix with
columns. In general, a matrix with  rows and
rows and  columns is referred to as an
columns is referred to as an  matrix or as having size . Thus matrices , , and above have sizes
matrix or as having size . Thus matrices , , and above have sizes  , , and
, , and  , respectively. A matrix of size
, respectively. A matrix of size  is called a row matrix, whereas one of size
is called a row matrix, whereas one of size  is called a column matrix. Matrices of size
is called a column matrix. Matrices of size  for some are called square matrices.
for some are called square matrices.
Each entry of a matrix is identified by the row and column in which it lies. The rows are numbered from the top down, and the columns are numbered from left to right. Then the  -entry of a matrix is the number lying simultaneously in row
-entry of a matrix is the number lying simultaneously in row  and column
and column  . For example,
. For example,
![\begin{align*} \mbox{The } (1, 2) \mbox{-entry of } &\left[ \begin{array}{rr} 1 & -1 \\ 0 & 1 \end{array}\right] \mbox{ is } -1. \\ \mbox{The } (2, 3) \mbox{-entry of } &\left[ \begin{array}{rrr} 1 & 2 & -1 \\ 0 & 5 & 6 \end{array}\right] \mbox{ is } 6. \end{align*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-14e3d57d5a305ed2eba3f18ceca28ae3_l3.png "Rendered by QuickLaTeX.com")
A special notation is commonly used for the entries of a matrix. If is an  matrix, and if the
matrix, and if the  -entry of is denoted as
-entry of is denoted as  , then is displayed as follows:
, then is displayed as follows:
![\begin{equation*} A = \left[ \begin{array}{ccccc} a_{11} & a_{12} & a_{13} & \cdots & a_{1n} \\ a_{21} & a_{22} & a_{23} & \cdots & a_{2n} \\ \vdots & \vdots & \vdots & & \vdots \\ a_{m1} & a_{m2} & a_{m3} & \cdots & a_{mn} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-60548ab398daa026e03f00f588da6d67_l3.png "Rendered by QuickLaTeX.com")
This is usually denoted simply as ![A = \left[ a_{ij} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-4e31c1ef0ac00a4b1f249f3c262ac4be_l3.png "Rendered by QuickLaTeX.com") . Thus is the entry in row and column of . For example, a
. Thus is the entry in row and column of . For example, a  matrix in this notation is written
matrix in this notation is written
![\begin{equation*} A = \left[ \begin{array}{cccc} a_{11} & a_{12} & a_{13} & a_{14} \\ a_{21} & a_{22} & a_{23} & a_{24} \\ a_{31} & a_{32} & a_{33} & a_{34} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-b5e4fcf887d32ad59d0af79bbc22c735_l3.png "Rendered by QuickLaTeX.com")
It is worth pointing out a convention regarding rows and columns: Rows are mentioned before columns. For example:
- If a matrix has size , it has rows and columns.
- If we speak of the -entry of a matrix, it lies in row and column .
- If an entry is denoted , the first subscript refers to the row and the second subscript to the column in which lies.
Two points  and
and  in the plane are equal if and only if they have the same coordinates, that is
in the plane are equal if and only if they have the same coordinates, that is  and
and  . Similarly, two matrices and are called equal (written
. Similarly, two matrices and are called equal (written  ) if and only if:
) if and only if:
- They have the same size.
- Corresponding entries are equal.
If the entries of and are written in the form , ![B = \left[ b_{ij} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6c509f5987b8ea520fc00975ec23f18b_l3.png "Rendered by QuickLaTeX.com") , described earlier, then the second condition takes the following form:
, described earlier, then the second condition takes the following form:
![\begin{equation*} A = \left[ a_{ij} \right] = \left[ b_{ij} \right] \mbox{ means } a_{ij} = b_{ij} \mbox{ for all } i \mbox{ and } j \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e1f48a7909047d1f75e999450196c299_l3.png "Rendered by QuickLaTeX.com")
Example 2.1.1
![A = \left[ \begin{array}{cc} a & b \\ c & d \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-960f3d868d8e145702de168e1ea33a78_l3.png "Rendered by QuickLaTeX.com") ,
, ![B = \left[ \begin{array}{rrr} 1 & 2 & -1 \\ 3 & 0 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-b404b54047e563e4573ab38c44f37918_l3.png "Rendered by QuickLaTeX.com") and
and![C = \left[ \begin{array}{rr} 1 & 0 \\ -1 & 2 \end{array} \rightB]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a7eb95e148a1cbaec3e2fea23f4f32be_l3.png "Rendered by QuickLaTeX.com")
discuss the possibility that
,  ,
,  .
.Solution:
is impossible because and are of different sizes: is whereas is . Similarly, is impossible. But is possible provided that corresponding entries are equal:
![\left[ \begin{array}{cc} a & b \\ c & d \end{array} \right] = \left[ \begin{array}{rr} 1 & 0 \\ -1 & 2 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c4d180d462a8267f0d8f30d8240ee54d_l3.png "Rendered by QuickLaTeX.com")
means  ,
,  ,
,  , and
, and  .
.
Matrix Addition
Definition 2.1 Matrix Addition
and are matrices of the same size, their sum  is the matrix formed by adding corresponding entries.
is the matrix formed by adding corresponding entries.If and , this takes the form
![\begin{equation*} A + B = \left[ a_{ij} + b_{ij} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a569e8548f252bdea23a43b2b63dd051_l3.png "Rendered by QuickLaTeX.com")
Note that addition is not defined for matrices of different sizes.
Example 2.1.2
![A = \left[ \begin{array}{rrr} 2 & 1 & 3 \\ -1 & 2 & 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cad57b88c3cf20119062b871721c7b83_l3.png "Rendered by QuickLaTeX.com")
and
![B = \left[ \begin{array}{rrr} 1 & 1 & -1 \\ 2 & 0 & 6 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-fe359910d71cce65e15f3e9a5a1e946d_l3.png "Rendered by QuickLaTeX.com") ,
,compute
.Solution:
![\begin{equation*} A + B = \left[ \begin{array}{rrr} 2 + 1 & 1 + 1 & 3 - 1 \\ -1 + 2 & 2 + 0 & 0 + 6 \end{array} \right] = \left[ \begin{array}{rrr} 3 & 2 & 2 \\ 1 & 2 & 6 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f192e5ac04d7e84d571d0ab92b0f0a4c_l3.png "Rendered by QuickLaTeX.com")
Example 2.1.3
 ,
,  , and
, and  if
if ![\left[ \begin{array}{ccc} a & b & c \end{array} \right] + \left[ \begin{array}{ccc} c & a & b \end{array} \right] = \left[ \begin{array}{ccc} 3 & 2 & -1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c65a58bba8c3952a54184859a6f4110d_l3.png "Rendered by QuickLaTeX.com") .
.Solution:
Add the matrices on the left side to obtain
![\begin{equation*} \left[ \begin{array}{ccc} a + c & b + a & c + b \end{array} \right] = \left[ \begin{array}{rrr} 3 & 2 & -1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e763403fc5ed95cfcefa2254f0af03fe_l3.png "Rendered by QuickLaTeX.com")
Because corresponding entries must be equal, this gives three equations:  ,
,  , and
, and  . Solving these yields
. Solving these yields  ,
,  ,
,  .
.
If , , and are any matrices of the same size, then
(commutative law) 
In fact, if and , then the -entries of and  are, respectively,
are, respectively,  and
and  . Since these are equal for all and , we get
. Since these are equal for all and , we get
![\begin{equation*} A + B = \left[ \begin{array}{c} a_{ij} + b_{ij} \end{array} \right] = \left[ \begin{array}{c} b_{ij} + a_{ij} \end{array} \right] = B + A \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-237b6b72effafbc6a09c17433298510a_l3.png "Rendered by QuickLaTeX.com")
The associative law is verified similarly.
The matrix in which every entry is zero is called the zero matrix and is denoted as  (or
(or  if it is important to emphasize the size). Hence,
if it is important to emphasize the size). Hence,

holds for all matrices  . The negative of an matrix (written
. The negative of an matrix (written  ) is defined to be the matrix obtained by multiplying each entry of by
) is defined to be the matrix obtained by multiplying each entry of by  . If , this becomes
. If , this becomes ![-A = \left[ -a_{ij} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-2992d3b15d2ccc3626572f99485322f4_l3.png "Rendered by QuickLaTeX.com") . Hence,
. Hence,

holds for all matrices where, of course, is the zero matrix of the same size as .
A closely related notion is that of subtracting matrices. If and are two matrices, their difference  is defined by
is defined by

Note that if and , then
![\begin{equation*} A - B = \left[ a_{ij} \right] + \left[ -b_{ij} \right] = \left[ a_{ij} - b_{ij} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-edab65f482f4733c6a4ae3a2a2a84360_l3.png "Rendered by QuickLaTeX.com")
is the matrix formed by subtracting corresponding entries.
Example 2.1.4
![A = \left[ \begin{array}{rrr} 3 & -1 & 0 \\ 1 & 2 & -4 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e33744cc342eb377a33f8c4157acd83c_l3.png "Rendered by QuickLaTeX.com") ,
, ![B = \left[ \begin{array}{rrr} 1 & -1 & 1 \\ -2 & 0 & 6 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f5516eec15a608034b95232c6d8cfa3f_l3.png "Rendered by QuickLaTeX.com") ,
, ![C = \left[ \begin{array}{rrr} 1 & 0 & -2 \\ 3 & 1 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-25bc050f4c5ab86a251f4a657ad3a47d_l3.png "Rendered by QuickLaTeX.com") ., , and
., , and  .
.Solution:
![\begin{align*} -A &= \left[ \begin{array}{rrr} -3 & 1 & 0 \\ -1 & -2 & 4 \end{array} \right] \\ A - B &= \left[ \begin{array}{lcr} 3 - 1 & -1 - (-1) & 0 - 1 \\ 1 - (-2) & 2 - 0 & -4 - 6 \end{array} \right] = \left[ \begin{array}{rrr} 2 & 0 & -1 \\ 3 & 2 & -10 \end{array} \right] \\ A + B - C &= \left[ \begin{array}{rrl} 3 + 1 - 1 & -1 - 1 - 0 & 0 + 1 -(-2) \\ 1 - 2 - 3 & 2 + 0 - 1 & -4 + 6 -1 \end{array} \right] = \left[ \begin{array}{rrr} 3 & -2 & 3 \\ -4 & 1 & 1 \end{array} \right] \end{align*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-8297271fe9f34109b21556ca55de37db_l3.png "Rendered by QuickLaTeX.com")
Example 2.1.5
![\left[ \begin{array}{rr} 3 & 2 \\ -1 & 1 \end{array} \right] + X = \left[ \begin{array}{rr} 1 & 0 \\ -1 & 2 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-5f202ea3404ad3ada7db1fdd1d9934f3_l3.png "Rendered by QuickLaTeX.com")
where
is a matrix.We solve a numerical equation  by subtracting the number from both sides to obtain
by subtracting the number from both sides to obtain  . This also works for matrices. To solve
. This also works for matrices. To solve
simply subtract the matrix
![\left[ \begin{array}{rr} 3 & 2 \\ -1 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-452bef18dcecf9943c258891d75ee71d_l3.png "Rendered by QuickLaTeX.com")
from both sides to get
![\begin{equation*} X = \left[ \begin{array}{rr} 1 & 0 \\ -1 & 2 \end{array} \right]- \left[ \begin{array}{rr} 3 & 2 \\ -1 & 1 \end{array} \right] = \left[ \begin{array}{cr} 1 - 3 & 0 - 2 \\ -1 - (-1) & 2 - 1 \end{array} \right] = \left[ \begin{array}{rr} -2 & -2 \\ 0 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-1108ecb7d262acaed7df353bf6be6392_l3.png "Rendered by QuickLaTeX.com")
The reader should verify that this matrix does indeed satisfy the original equation.
The solution in Example 2.1.5 solves the single matrix equation  directly via matrix subtraction:
directly via matrix subtraction:  . This ability to work with matrices as entities lies at the heart of matrix algebra.
. This ability to work with matrices as entities lies at the heart of matrix algebra.
It is important to note that the sizes of matrices involved in some calculations are often determined by the context. For example, if
![\begin{equation*} A + C = \left[ \begin{array}{rrr} 1 & 3 & -1 \\ 2 & 0 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-51f8712fdcbe02070146fda7b131d537_l3.png "Rendered by QuickLaTeX.com")
then and must be the same size (so that  makes sense), and that size must be (so that the sum is ). For simplicity we shall often omit reference to such facts when they are clear from the context.
makes sense), and that size must be (so that the sum is ). For simplicity we shall often omit reference to such facts when they are clear from the context.
Scalar Multiplication
In gaussian elimination, multiplying a row of a matrix by a number  means multiplying every entry of that row by .
means multiplying every entry of that row by .
Definition 2.2 Matrix Scalar Multiplication
is any matrix and is any number, the scalar multiple  is the matrix obtained from by multiplying each entry of by .
is the matrix obtained from by multiplying each entry of by .
The term scalar arises here because the set of numbers from which the entries are drawn is usually referred to as the set of scalars. We have been using real numbers as scalars, but we could equally well have been using complex numbers.
Example 2.1.6
![A = \left[ \begin{array}{rrr} 3 & -1 & 4 \\ 2 & 0 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-488ed59f8747107b59a88b3be7a22b51_l3.png "Rendered by QuickLaTeX.com")
and
![B = \left[ \begin{array}{rrr} 1 & 2 & -1 \\ 0 & 3 & 2 \end{array} \right],](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e3caaef7dad35c91b37e791e9cc51bb8_l3.png "Rendered by QuickLaTeX.com")
compute
 ,
,  , and
, and  .
.Solution:
![\begin{align*} 5A &= \left[ \begin{array}{rrr} 15 & -5 & 20 \\ 10 & 0 & 30 \end{array} \right], \quad \frac{1}{2}B = \left[ \begin{array}{rrr} \frac{1}{2} & 1 & -\frac{1}{2} \\ 0 & \frac{3}{2} & 1 \end{array} \right] \\ 3A - 2B &= \left[ \begin{array}{rrr} 9 & -3 & 12 \\ 6 & 0 & 18 \end{array} \right] - \left[ \begin{array}{rrr} 2 & 4 & -2 \\ 0 & 6 & 4 \end{array} \right] = \left[ \begin{array}{rrr} 7 & -7 & 14 \\ 6 & -6 & 14 \end{array} \right] \end{align*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-11453525d60950649bb2baad5d426259_l3.png "Rendered by QuickLaTeX.com")
If is any matrix, note that is the same size as for all scalars . We also have

because the zero matrix has every entry zero. In other words,  if either
if either  or
or  . The converse of this statement is also true, as Example 2.1.7 shows.
. The converse of this statement is also true, as Example 2.1.7 shows.
Example 2.1.7
, show that either or .Solution:
Write so that means  for all and . If , there is nothing to do. If
for all and . If , there is nothing to do. If  , then implies that
, then implies that  for all and ; that is, .
for all and ; that is, .
For future reference, the basic properties of matrix addition and scalar multiplication are listed in Theorem 2.1.1.
Theorem 2.1.1
Let , , and denote arbitrary matrices where and are fixed. Let and  denote arbitrary real numbers. Then
denote arbitrary real numbers. Then
-
 .
.  .
.- There is an matrix , such that
 for each .
for each . - For each there is an matrix, , such that
 .
. -
 .
. -
 .
. -
 .
. -
 .
.
Proof:
Properties 1–4 were given previously. To check Property 5, let and denote matrices of the same size. Then ![A + B = \left[ a_{ij} + b_{ij} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-7f1cf731e19083a1c3161e1fed10f333_l3.png "Rendered by QuickLaTeX.com") , as before, so the -entry of
, as before, so the -entry of  is
is

But this is just the -entry of  , and it follows that . The other Properties can be similarly verified; the details are left to the reader.
, and it follows that . The other Properties can be similarly verified; the details are left to the reader.
The Properties in Theorem 2.1.1 enable us to do calculations with matrices in much the same way that
numerical calculations are carried out. To begin, Property 2 implies that the sum

is the same no matter how it is formed and so is written as  . Similarly, the sum
. Similarly, the sum

is independent of how it is formed; for example, it equals both  and
and ![A + \left[ B + (C + D) \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a758e551e98b614294fd6e92fbbef611_l3.png "Rendered by QuickLaTeX.com") . Furthermore, property 1 ensures that, for example,
. Furthermore, property 1 ensures that, for example,

In other words, the order in which the matrices are added does not matter. A similar remark applies to sums of five (or more) matrices.
Properties 5 and 6 in Theorem 2.1.1 are called distributive laws for scalar multiplication, and they extend to sums of more than two terms. For example,


Similar observations hold for more than three summands. These facts, together with properties 7 and 8, enable us to simplify expressions by collecting like terms, expanding, and taking common factors in exactly the same way that algebraic expressions involving variables and real numbers are manipulated. The following example illustrates these techniques.
Example 2.1.8
![2(A + 3C) - 3(2C - B) - 3 \left[ 2(2A + B - 4C) - 4(A - 2C) \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-771ffbc46a98c53b0c48fd12cdf44f14_l3.png "Rendered by QuickLaTeX.com") where
where  and are all matrices of the same size.
and are all matrices of the same size.Solution:
The reduction proceeds as though , , and were variables.
![\begin{align*} 2(A &+ 3C) - 3(2C - B) - 3 \left[ 2(2A + B - 4C) - 4(A - 2C) \right] \\ &= 2A + 6C - 6C + 3B - 3 \left[ 4A + 2B - 8C - 4A + 8C \right] \\ &= 2A + 3B - 3 \left[ 2B \right] \\ &= 2A - 3B \end{align*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-45e5ae1d1480bdaf9f19ecd41ca98e77_l3.png "Rendered by QuickLaTeX.com")
Transpose of a Matrix
Many results about a matrix involve the rows of , and the corresponding result for columns is derived in an analogous way, essentially by replacing the word row by the word column throughout. The following definition is made with such applications in mind.
Definition 2.3 Transpose of a Matrix
is an matrix, the transpose of , written  , is the
, is the  matrix whose rows are just the columns of in the same order.
matrix whose rows are just the columns of in the same order.In other words, the first row of is the first column of (that is it consists of the entries of column 1 in order). Similarly the second row of is the second column of , and so on.
Example 2.1.9
![\begin{equation*} A = \left[ \begin{array}{r} 1 \\ 3 \\ 2 \end{array} \right] \quad B = \left[ \begin{array}{rrr} 5 & 2 & 6 \end{array} \right] \quad C = \left[ \begin{array}{rr} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{array} \right] \quad D = \left[ \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & 2 \\ -1 & 2 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a0da49245fb2b147f46e2e36c8bc9f81_l3.png "Rendered by QuickLaTeX.com")
Solution:
![\begin{equation*} A^{T} = \left[ \begin{array}{rrr} 1 & 3 & 2 \end{array} \right],\ B^{T} = \left[ \begin{array}{r} 5 \\ 2 \\ 6 \end{array} \right],\ C^{T} = \left[ \begin{array}{rrr} 1 & 3 & 5 \\ 2 & 4 & 6 \end{array} \right], \mbox{ and } D^{T} = D. \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-40fd27d13cb810f642d6799c6a294a30_l3.png "Rendered by QuickLaTeX.com")
If is a matrix, write ![A^{T} = \left[ b_{ij} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e0b4da699d6686295389a798f9116165_l3.png "Rendered by QuickLaTeX.com") . Then
. Then  is the th element of the th row of and so is the th element of the th column of . This means
is the th element of the th row of and so is the th element of the th column of . This means  , so the definition of can be stated as follows:
, so the definition of can be stated as follows:
(2.1) ![\begin{equation*} \mbox{If } A = \left[ a_{ij} \right] \mbox{, then } A^{T} = \left[ a_{ji} \right]. \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-708589864cf76f3f421fd9278c5dfcfc_l3.png "Rendered by QuickLaTeX.com")
This is useful in verifying the following properties of transposition.
Theorem 2.1.2
Let and denote matrices of the same size, and let denote a scalar.
- If is an matrix, then is an matrix.
 .
.-
 .
.  .
.
Proof:
Property 1 is part of the definition of , and Property 2 follows from (2.1). As to Property 3: If  , then
, then  , so (2.1) gives
, so (2.1) gives
![\begin{equation*} (kA)^{T} = \left[ ka_{ji} \right] = k \left[ a_{ji} \right] = kA^{T} \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-06f3586c6222b1cd23e96466904ac85e_l3.png "Rendered by QuickLaTeX.com")
Finally, if , then ![A + B = \left[ c_{ij} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-705be5c1b3318227c08e02501779dd98_l3.png "Rendered by QuickLaTeX.com") where
where  Then (2.1) gives Property 4:
Then (2.1) gives Property 4:
![\begin{equation*} (A + B)^{T} = \left[ c_{ij} \right]^{T} = \left[ c_{ji} \right] = \left[ a_{ji} + b_{ji} \right] = \left[ a_{ji} \right] + \left[ b_{ji} \right] = A^{T} + B^{T} \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-092b6eb7d1d5f53e5da5e82f92b5f832_l3.png "Rendered by QuickLaTeX.com")
There is another useful way to think of transposition. If is an matrix, the elements  are called the main diagonal of . Hence the main diagonal extends down and to the right from the upper left corner of the matrix ; it is shaded in the following examples:
are called the main diagonal of . Hence the main diagonal extends down and to the right from the upper left corner of the matrix ; it is shaded in the following examples:
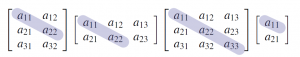
Thus forming the transpose of a matrix can be viewed as “flipping” about its main diagonal, or as “rotating” through  about the line containing the main diagonal. This makes Property 2 in Theorem~?? transparent.
about the line containing the main diagonal. This makes Property 2 in Theorem~?? transparent.
Example 2.1.10
if ![\left(2A^{T} - 3 \left[ \begin{array}{rr} 1 & 2 \\ -1 & 1 \end{array} \right] \right)^{T} = \left[ \begin{array}{rr} 2 & 3 \\ -1 & 2 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-412707efa97069310ef423847f21291f_l3.png "Rendered by QuickLaTeX.com") .
.Solution:
Using Theorem 2.1.2, the left side of the equation is
![\begin{equation*} \left(2A^{T} - 3 \left[ \begin{array}{rr} 1 & 2 \\ -1 & 1 \end{array} \right]\right)^{T} = 2\left(A^{T}\right)^{T} - 3 \left[ \begin{array}{rr} 1 & 2 \\ -1 & 1 \end{array} \right]^{T} = 2A - 3 \left[ \begin{array}{rr} 1 & -1 \\ 2 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e891c21f1c92d3fc970bb1bac79f365d_l3.png "Rendered by QuickLaTeX.com")
Hence the equation becomes
![\begin{equation*} 2A - 3 \left[ \begin{array}{rr} 1 & -1 \\ 2 & 1 \end{array} \right] = \left[ \begin{array}{rr} 2 & 3 \\ -1 & 2 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-906ac48eeed25835be895c7066dff524_l3.png "Rendered by QuickLaTeX.com")
Thus
![2A = \left[ \begin{array}{rr} 2 & 3 \\ -1 & 2 \end{array} \right] + 3 \left[ \begin{array}{rr} 1 & -1 \\ 2 & 1 \end{array} \right] = \left[ \begin{array}{rr} 5 & 0 \\ 5 & 5 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-3a24df647f7ad3c8573f612eef77a042_l3.png "Rendered by QuickLaTeX.com") , so finally
, so finally
![A = \frac{1}{2} \left[ \begin{array}{rr} 5 & 0 \\ 5 & 5 \end{array} \right] = \frac{5}{2} \left[ \begin{array}{rr} 1 & 0 \\ 1 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-066d9a533f4450ffeb42fc0c1b1a13ae_l3.png "Rendered by QuickLaTeX.com") .
.
Note that Example 2.1.10 can also be solved by first transposing both sides, then solving for , and so obtaining  . The reader should do this.
. The reader should do this.
The matrix ![D = \left[ \begin{array}{rr} 1 & 2 \\ 2 & 5 \end{array}\right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-1e5167b29ed8d8778155db3011cdf26d_l3.png "Rendered by QuickLaTeX.com") in Example 2.1.9 has the property that
in Example 2.1.9 has the property that  . Such matrices are important; a matrix is called symmetric if
. Such matrices are important; a matrix is called symmetric if  . A symmetric matrix is necessarily square (if is , then is , so forces
. A symmetric matrix is necessarily square (if is , then is , so forces  ). The name comes from the fact that these matrices exhibit a symmetry about the main diagonal. That is, entries that are directly across the main diagonal from each other are equal.
). The name comes from the fact that these matrices exhibit a symmetry about the main diagonal. That is, entries that are directly across the main diagonal from each other are equal.
For example, ![\left[ \begin{array}{ccc} a & b & c \\ b^\prime & d & e \\ c^\prime & e^\prime & f \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c874e4fc13043e1eb1536b3d3b88b25f_l3.png "Rendered by QuickLaTeX.com") is symmetric when
is symmetric when  ,
,  , and
, and  .
.
Example 2.1.11
and are symmetric matrices, show that is symmetric.Solution:
We have  and
and  , so, by Theorem 2.1.2, we have
, so, by Theorem 2.1.2, we have  . Hence is symmetric.
. Hence is symmetric.
Example 2.1.12
satisfies  . Show that necessarily .
. Show that necessarily .Solution:
If we iterate the given equation, Theorem 2.1.2 gives
![\begin{equation*} A = 2A^{T} = 2 {\left[ 2A^{T} \right]}^T = 2 \left[ 2(A^{T})^{T} \right] = 4A \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-1086bce8b76f0c9e49e4dc99af26b31b_l3.png "Rendered by QuickLaTeX.com")
Subtracting from both sides gives  , so
, so  .
.
2.2 Matrix-Vector Multiplication
Up to now we have used matrices to solve systems of linear equations by manipulating the rows of the augmented matrix. In this section we introduce a different way of describing linear systems that makes more use of the coefficient matrix of the system and leads to a useful way of “multiplying” matrices.
Vectors
It is a well-known fact in analytic geometry that two points in the plane with coordinates  and
and  are equal if and only if
are equal if and only if  and
and  . Moreover, a similar condition applies to points
. Moreover, a similar condition applies to points  in space. We extend this idea as follows.
in space. We extend this idea as follows.
An ordered sequence  of real numbers is called an ordered
of real numbers is called an ordered  –tuple. The word “ordered” here reflects our insistence that two ordered -tuples are equal if and only if corresponding entries are the same. In other words,
–tuple. The word “ordered” here reflects our insistence that two ordered -tuples are equal if and only if corresponding entries are the same. In other words,

Thus the ordered -tuples and -tuples are just the ordered pairs and triples familiar from geometry.
Definition 2.4 The set  of ordered -tuples of real numbers
of ordered -tuples of real numbers
 denote the set of all real numbers. The set of all ordered -tuples from has a special notation:
denote the set of all real numbers. The set of all ordered -tuples from has a special notation: 
There are two commonly used ways to denote the -tuples in  : As rows
: As rows  or columns
or columns ![\left[ \begin{array}{c} r_{1} \\ r_{2} \\ \vdots \\ r_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-d59e5aa1da597bde97ec684c023433d0_l3.png "Rendered by QuickLaTeX.com") ;
;
the notation we use depends on the context. In any event they are called vectors or –vectors and will be denoted using bold type such as x or v. For example, an matrix will be written as a row of columns:
![\begin{equation*} A = \left[ \begin{array}{cccc} \textbf{a}_{1} & \textbf{a}_{2} & \cdots & \textbf{a}_{n} \end{array} \right] \mbox{ where } \textbf{a}_{j} \mbox{ denotes column } j \mbox{ of } A \mbox{ for each } j. \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-86fe41a93a6e40ab3a29d4069ddfd55e_l3.png "Rendered by QuickLaTeX.com")
If  and
and  are two -vectors in
are two -vectors in  , it is clear that their matrix sum
, it is clear that their matrix sum  is also in as is the scalar multiple
is also in as is the scalar multiple  for any real number . We express this observation by saying that is closed under addition and scalar multiplication. In particular, all the basic properties in Theorem 2.1.1 are true of these -vectors. These properties are fundamental and will be used frequently below without comment. As for matrices in general, the
for any real number . We express this observation by saying that is closed under addition and scalar multiplication. In particular, all the basic properties in Theorem 2.1.1 are true of these -vectors. These properties are fundamental and will be used frequently below without comment. As for matrices in general, the  zero matrix is called the zero –vector in and, if is an -vector, the -vector
zero matrix is called the zero –vector in and, if is an -vector, the -vector  is called the negative .
is called the negative .
Of course, we have already encountered these -vectors in Section 1.3 as the solutions to systems of linear equations with variables. In particular we defined the notion of a linear combination of vectors and showed that a linear combination of solutions to a homogeneous system is again a solution. Clearly, a linear combination of -vectors in is again in , a fact that we will be using.
Matrix-Vector Multiplication
Given a system of linear equations, the left sides of the equations depend only on the coefficient matrix and the column of variables, and not on the constants. This observation leads to a fundamental idea in linear algebra: We view the left sides of the equations as the “product”  of the matrix and the vector . This simple change of perspective leads to a completely new way of viewing linear systems—one that is very useful and will occupy our attention throughout this book.
of the matrix and the vector . This simple change of perspective leads to a completely new way of viewing linear systems—one that is very useful and will occupy our attention throughout this book.
To motivate the definition of the “product” , consider first the following system of two equations in three variables:
(2.2) 
and let ![A = \left[ \begin{array}{ccc} a & b & c \\ a^\prime & b^\prime & c^\prime \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cc11e1a75b292c31cc5e472dc49ffd14_l3.png "Rendered by QuickLaTeX.com") ,
, ![\textbf{x} = \left[ \begin{array}{c} x_{1} \\ x_{2} \\ x_{3} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f014d740858c61dd437c3f45b93d9276_l3.png "Rendered by QuickLaTeX.com") ,
, ![\textbf{b} = \left[ \begin{array}{c} b_{1} \\ b_{2} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-237f3b4bf6b1ecd4375181334c3ec812_l3.png "Rendered by QuickLaTeX.com") denote the coefficient matrix, the variable matrix, and the constant matrix, respectively. The system (2.2) can be expressed as a single vector equation
denote the coefficient matrix, the variable matrix, and the constant matrix, respectively. The system (2.2) can be expressed as a single vector equation
![\begin{equation*} \left[ \arraycolsep=1pt \begin{array}{rrrrr} ax_{1} & + & bx_{2} & + & cx_{3} \\ a^\prime x_{1} & + & b^\prime x_{2} & + & c^\prime x_{3} \end{array} \right] = \left[ \begin{array}{c} b_{1} \\ b_{2} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-71887e51119350ce34dfbc330ea04b5c_l3.png "Rendered by QuickLaTeX.com")
which in turn can be written as follows:
![\begin{equation*} x_{1} \left[ \begin{array}{c} a \\ a^\prime \end{array} \right] + x_{2} \left[ \begin{array}{c} b \\ b^\prime \end{array} \right] + x_{3} \left[ \begin{array}{c} c \\ c^\prime \end{array} \right] = \left[ \begin{array}{c} b_{1} \\ b_{2} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-de1617b7b63fc6ffc2e5dbd6eb79ae21_l3.png "Rendered by QuickLaTeX.com")
Now observe that the vectors appearing on the left side are just the columns
![\begin{equation*} \textbf{a}_{1} = \left[ \begin{array}{c} a \\ a^\prime \end{array} \right], \textbf{a}_{2} = \left[ \begin{array}{c} b \\ b^\prime \end{array} \right], \mbox{ and } \textbf{a}_{3} = \left[ \begin{array}{c} c \\ c^\prime \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-0e71a45635a68e822136a1e50ed71a8b_l3.png "Rendered by QuickLaTeX.com")
of the coefficient matrix . Hence the system (2.2) takes the form
(2.3) 
This shows that the system (2.2) has a solution if and only if the constant matrix  is a linear combination of the columns of , and that in this case the entries of the solution are the coefficients
is a linear combination of the columns of , and that in this case the entries of the solution are the coefficients  ,
,  , and
, and  in this linear combination.
in this linear combination.
Moreover, this holds in general. If is any matrix, it is often convenient to view as a row of columns. That is, if  are the columns of , we write
are the columns of , we write
![\begin{equation*} A = \left[ \begin{array}{cccc} \textbf{a}_{1} & \textbf{a}_{2} & \cdots & \textbf{a}_{n} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-7d8ab494638c5c1424d2fba3f1cc7a00_l3.png "Rendered by QuickLaTeX.com")
and say that ![A = \left[ \begin{array}{cccc}\textbf{a}_{1} & \textbf{a}_{2} & \cdots & \textbf{a}_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-4712de4438a9dd48ce7cb5b9d1e87b83_l3.png "Rendered by QuickLaTeX.com") is given in terms of its columns.
is given in terms of its columns.
Now consider any system of linear equations with coefficient matrix . If is the constant matrix of the system, and if ![\textbf{x} = \left[ \begin{array}{c} x_{1} \\ x_{2} \\ \vdots \\ x_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-106c7c5485d7f7fc87cca59ba85b2a28_l3.png "Rendered by QuickLaTeX.com")
is the matrix of variables then, exactly as above, the system can be written as a single vector equation
(2.4) 
Example 2.2.1

in the form given in (2.4).
Solution:
![\begin{equation*} x_{1} \left[ \begin{array}{r} 3 \\ 1 \\ 0 \end{array} \right] + x_{2} \left[ \begin{array}{r} 2 \\ -3 \\ 1 \end{array} \right] + x_{3} \left[ \begin{array}{r} -4 \\ 1 \\ -5 \end{array} \right] = \left[ \begin{array}{r} 0 \\ 3 \\ -1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c1404d3d4fa735227aff6c942086b725_l3.png "Rendered by QuickLaTeX.com")
As mentioned above, we view the left side of (2.4) as the product of the matrix and the vector . This basic idea is formalized in the following definition:
Definition 2.5 Matrix-Vector Multiplication
![A = \left[ \begin{array}{cccc} \textbf{a}_{1} &\textbf{a}_{2} & \cdots & \textbf{a}_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-dbb5a2778dd46c36260d2751f566f8ee_l3.png "Rendered by QuickLaTeX.com") be an matrix, written in terms of its columns . If
be an matrix, written in terms of its columns . If is any n-vector, the product
is defined to be the -vector given by:

In other words, if is and is an -vector, the product is the linear combination of the columns of where the coefficients are the entries of (in order).
Note that if is an matrix, the product is only defined if is an -vector and then the vector is an -vector because this is true of each column  of . But in this case the system of linear equations with coefficient matrix and constant vector takes the form of a single matrix equation
of . But in this case the system of linear equations with coefficient matrix and constant vector takes the form of a single matrix equation

The following theorem combines Definition 2.5 and equation (2.4) and summarizes the above discussion. Recall that a system of linear equations is said to be consistent if it has at least one solution.
Theorem 2.2.1
- Every system of linear equations has the form
 where is the coefficient matrix, is the constant matrix, and is the matrix of variables.
where is the coefficient matrix, is the constant matrix, and is the matrix of variables. - The system is consistent if and only if is a linear combination of the columns of .
- If are the columns of and if , then is a solution to the linear system if and only if
 are a solution of the vector equation
are a solution of the vector equation

A system of linear equations in the form as in (1) of Theorem 2.2.1 is said to be written in matrix form. This is a useful way to view linear systems as we shall see.
Theorem 2.2.1 transforms the problem of solving the linear system into the problem of expressing the constant matrix as a linear combination of the columns of the coefficient matrix . Such a change in perspective is very useful because one approach or the other may be better in a particular situation; the importance of the theorem is that there is a choice.
Example 2.2.2
![A = \left[ \begin{array}{rrrr} 2 & -1 & 3 & 5 \\ 0 & 2 & -3 & 1 \\ -3 & 4 & 1 & 2 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-71a850c6d1766fa957cf52cf8c2ef491_l3.png "Rendered by QuickLaTeX.com") and
and![\textbf{x} = \left[ \begin{array}{r} 2 \\ 1 \\ 0 \\ -2 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6c9931265e1a362abea7ad860a6fe19b_l3.png "Rendered by QuickLaTeX.com") , compute .
, compute .Solution:
By Definition 2.5:
![A\textbf{x} = 2 \left[ \begin{array}{r} 2 \\ 0 \\ -3 \end{array} \right] + 1 \left[ \begin{array}{r} -1 \\ 2 \\ 4 \end{array} \right] + 0 \left[ \begin{array}{r} 3 \\ -3 \\ 1 \end{array} \right] - 2 \left[ \begin{array}{r} 5 \\ 1 \\ 2 \end{array} \right] = \left[ \begin{array}{r} -7 \\ 0 \\ -6 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-5302649dde2927a9338a2da4e6711af0_l3.png "Rendered by QuickLaTeX.com") .
.
Example 2.2.3
Given columns  ,
,  ,
,  , and
, and  in
in  , write
, write  in the form where is a matrix and is a vector.
in the form where is a matrix and is a vector.
Solution:
Here the column of coefficients is
![\textbf{x} = \left[ \begin{array}{r} 2 \\ -3 \\ 5 \\ 1 \end{array} \right].](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-caa9d432222f804c2b3d1ec95fb74f1f_l3.png "Rendered by QuickLaTeX.com")
Hence Definition 2.5 gives

where ![A = \left[ \begin{array}{cccc} \textbf{a}_{1} & \textbf{a}_{2} & \textbf{a}_{3} & \textbf{a}_{4} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-03f1a947e8f0b814d780122bbadedc1e_l3.png "Rendered by QuickLaTeX.com") is the matrix with , , , and as its columns.
is the matrix with , , , and as its columns.
Example 2.2.4
Let be the matrix given in terms of its columns
![\textbf{a}_{1} = \left[ \begin{array}{r} 2 \\ 0 \\ -1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-9ad3fa247fd5675f3ace33dcb160eb55_l3.png "Rendered by QuickLaTeX.com") ,
, ![\textbf{a}_{2} = \left[ \begin{array}{r} 1 \\ 1 \\ 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-fae1cc4cb64558ef193267899832c219_l3.png "Rendered by QuickLaTeX.com") ,
, ![\textbf{a}_{3} = \left[ \begin{array}{r} 3 \\ -1 \\ -3 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-5215dfeaef4e8513bf6dfddcae012482_l3.png "Rendered by QuickLaTeX.com") , and
, and ![\textbf{a}_{4} = \left[ \begin{array}{r} 3 \\ 1 \\ 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-d4b5864bf23622ea195cf1e70f379925_l3.png "Rendered by QuickLaTeX.com") .
.
In each case below, either express as a linear combination of , , , and , or show that it is not such a linear combination. Explain what your answer means for the corresponding system of linear equations.
1. ![\textbf{b} = \left[ \begin{array}{r} 1 \\ 2 \\ 3 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-4f4fe6c08b26ba324eebfe368dbb8e7d_l3.png "Rendered by QuickLaTeX.com")
2. ![\textbf{b} = \left[ \begin{array}{r} 4 \\ 2 \\ 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-4d712ced9ac97ebc8265b0bbb068046d_l3.png "Rendered by QuickLaTeX.com")
Solution:
By Theorem 2.2.1, is a linear combination of , , , and if and only if the system is consistent (that is, it has a solution). So in each case we carry the augmented matrix ![\left[ A|\textbft{b} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-45be8b26fe7e75010efd321709e80722_l3.png "Rendered by QuickLaTeX.com") of the system to reduced form.
of the system to reduced form.
1. Here
![\left[ \begin{array}{rrrr|r} 2 & 1 & 3 & 3 & 1 \\ 0 & 1 & -1 & 1 & 2 \\ -1 & 1 & -3 & 0 & 3 \end{array} \right] \rightarrow \left[ \begin{array}{rrrr|r} 1 & 0 & 2 & 1 & 0 \\ 0 & 1 & -1 & 1 & 0 \\ 0 & 0 & 0 & 0 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-18edb84ce066f49223dc6a8f2f12658e_l3.png "Rendered by QuickLaTeX.com") , so the system has no solution in this case. Hence is \textit{not} a linear combination of , , , and .
, so the system has no solution in this case. Hence is \textit{not} a linear combination of , , , and .
2. Now
![\left[ \begin{array}{rrrr|r} 2 & 1 & 3 & 3 & 4 \\ 0 & 1 & -1 & 1 & 2 \\ -1 & 1 & -3 & 0 & 1 \end{array} \right] \rightarrow \left[ \begin{array}{rrrr|r} 1 & 0 & 2 & 1 & 1 \\ 0 & 1 & -1 & 1 & 2 \\ 0 & 0 & 0 & 0 & 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c74310da472b6032e71831afc81b986e_l3.png "Rendered by QuickLaTeX.com") , so the system is consistent.
, so the system is consistent.
Thus is a linear combination of , , , and in this case. In fact the general solution is  ,
,  ,
,  , and
, and  where
where  and
and  are arbitrary parameters. Hence
are arbitrary parameters. Hence ![x_{1}\textbf{a}_{1} + x_{2}\textbf{a}_{2} + x_{3}\textbf{a}_{3} + x_{4}\textbf{a}_{4} = \textbf{b} = \left[ \begin{array}{r} 4 \\ 2 \\ 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f3edcf6f72ca9b418a48fe4b6da8a042_l3.png "Rendered by QuickLaTeX.com")
for any choice of and . If we take  and
and  , this becomes
, this becomes  , whereas taking
, whereas taking  gives
gives  .
.
Example 2.2.5
to be the zero matrix, we have  for all vectors by Definition 2.5 because every column of the zero matrix is zero. Similarly,
for all vectors by Definition 2.5 because every column of the zero matrix is zero. Similarly,  for all matrices because every entry of the zero vector is zero.
for all matrices because every entry of the zero vector is zero.
Example 2.2.6
![I = \left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-713bc6c3634032ac1445ed97d0a604ee_l3.png "Rendered by QuickLaTeX.com") , show that
, show that  for any vector in .
for any vector in .Solution:
If ![\textbf{x} = \left[ \begin{array}{r} x_{1} \\ x_{2} \\ x_{3} \end{array} \right],](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c897de4fcf78c69b88c0a8d8b8cbaad7_l3.png "Rendered by QuickLaTeX.com") then Definition 2.5 gives
then Definition 2.5 gives
![\begin{equation*} I\textbf{x} = x_{1} \left[ \begin{array}{r} 1 \\ 0 \\ 0 \\ \end{array} \right] + x_{2} \left[ \begin{array}{r} 0 \\ 1 \\ 0 \\ \end{array} \right] + x_{3} \left[ \begin{array}{r} 0 \\ 0 \\ 1 \\ \end{array} \right] = \left[ \begin{array}{r} x_{1} \\ 0 \\ 0 \\ \end{array} \right] + \left[ \begin{array}{r} 0 \\ x_{2} \\ 0 \\ \end{array} \right] + \left[ \begin{array}{r} 0 \\ 0 \\ x_{3} \\ \end{array} \right] = \left[ \begin{array}{r} x_{1} \\ x_{2} \\ x_{3} \\ \end{array} \right] = \textbf{x} \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-31440a006d821ce12da10723f617a933_l3.png "Rendered by QuickLaTeX.com")
The matrix  in Example 2.2.6 is called the
in Example 2.2.6 is called the  identity matrix, and we will encounter such matrices again in future. Before proceeding, we develop some algebraic properties of matrix-vector multiplication that are used extensively throughout linear algebra.
identity matrix, and we will encounter such matrices again in future. Before proceeding, we develop some algebraic properties of matrix-vector multiplication that are used extensively throughout linear algebra.
Theorem 2.2.2
Let and be matrices, and let  and
and  be -vectors in
be -vectors in  . Then:
. Then:
 .
. for all scalars .
for all scalars . .
.
Proof:
We prove (3); the other verifications are similar and are left as exercises. Let ![A = \left[ \begin{array}{cccc} \textbf{a}_{1} & \textbf{a}_{2} & \cdots & \textbf{a}_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c606dd8f9536b5aa2b0e7830b2334ae1_l3.png "Rendered by QuickLaTeX.com") and
and ![B = \left[ \begin{array}{cccc} \textbf{b}_{1} & \textbf{b}_{2} & \cdots & \textbf{b}_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-5a8d60555a26db3d13032880ee6ab08f_l3.png "Rendered by QuickLaTeX.com") be given in terms of their columns. Since adding two matrices is the same as adding their columns, we have
be given in terms of their columns. Since adding two matrices is the same as adding their columns, we have
![\begin{equation*} A + B = \left[ \begin{array}{cccc} \textbf{a}_{1} + \textbf{b}_{1} & \textbf{a}_{2} + \textbf{b}_{2} & \cdots & \textbf{a}_{n} + \textbf{b}_{n} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c4f394040f907a596d6d540e783eef95_l3.png "Rendered by QuickLaTeX.com")
If we write ![\textbf{x} = \left[ \begin{array}{c} x_{1} \\ x_{2} \\ \vdots \\ x_{n} \end{array} \right].](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-2252eb90acdfd8ccbba2e52b8be65c49_l3.png "Rendered by QuickLaTeX.com")
Definition 2.5 gives

Theorem 2.2.2 allows matrix-vector computations to be carried out much as in ordinary arithmetic. For example, for any matrices and and any -vectors and , we have:

We will use such manipulations throughout the book, often without mention.
Linear Equations
Theorem 2.2.2 also gives a useful way to describe the solutions to a system
of linear equations. There is a related system

called the associated homogeneous system, obtained from the original system by replacing all the constants by zeros. Suppose  is a solution to and
is a solution to and  is a solution to
is a solution to  (that is
(that is  and
and  ). Then
). Then  is another solution to . Indeed, Theorem 2.2.2 gives
is another solution to . Indeed, Theorem 2.2.2 gives

This observation has a useful converse.
Theorem 2.2.3
is any particular solution to the system of linear equations. Then every solution  to has the form
to has the form

for some solution of the associated homogeneous system .
Proof:
Suppose is also a solution to , so that  . Write
. Write  . Then
. Then  and, using Theorem 2.2.2, we compute
and, using Theorem 2.2.2, we compute

Hence is a solution to the associated homogeneous system .
Note that gaussian elimination provides one such representation.
Example 2.2.7

Solution:
Gaussian elimination gives  ,
,  , , and where and are arbitrary parameters. Hence the general solution can be written
, , and where and are arbitrary parameters. Hence the general solution can be written
![\begin{equation*} \textbf{x} = \left[ \begin{array}{c} x_{1} \\ x_{2} \\ x_{3} \\ x_{4} \end{array} \right] = \left[ \begin{array}{c} 4 + 2s - t \\ 2 + s + 2t \\ s \\ t \end{array} \right] = \left[ \begin{array}{r} 4 \\ 2 \\ 0 \\ 0 \end{array} \right] + \left( s \left[ \begin{array}{r} 2 \\ 1 \\ 1 \\ 0 \end{array} \right] + t \left[ \begin{array}{r} -1 \\ 2 \\ 0 \\ 1 \end{array} \right] \right) \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-ffb756ee748aaa8f00edc0afdfa93da8_l3.png "Rendered by QuickLaTeX.com")
Thus
![\textbf{x}_1 = \left[ \begin{array}{r} 4 \\ 2 \\ 0 \\ 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-ed5f039acc8324c59130225ab5d86246_l3.png "Rendered by QuickLaTeX.com")
is a particular solution (where  ), and
), and
![\textbf{x}_{0} = s \left[ \begin{array}{r} 2 \\ 1 \\ 1 \\ 0 \end{array} \right] + t \left[ \begin{array}{r} -1 \\ 2 \\ 0 \\ 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f17840014483e6b964f4bb46b9902e85_l3.png "Rendered by QuickLaTeX.com") gives all solutions to the associated homogeneous system. (To see why this is so, carry out the gaussian elimination again but with all the constants set equal to zero.)
gives all solutions to the associated homogeneous system. (To see why this is so, carry out the gaussian elimination again but with all the constants set equal to zero.)
The following useful result is included with no proof.
Theorem 2.2.4
be a system of equations with augmented matrix ![\left[ \begin{array}{c|c} A & \textbf{b} \end{array}\right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f681910a31d8713f922dea98af1eec7d_l3.png "Rendered by QuickLaTeX.com") . Write
. Write  .
.![\text{rank} \left[ \begin{array}{c|c} A & \textbf{b} \end{array}\right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cac04fda0063d3821de9d3de8724ea73_l3.png "Rendered by QuickLaTeX.com") is either
is either  or
or  .
.![\text{rank} \left[ \begin{array}{c|c} A & \textbf{b} \end{array}\right] = r](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-84c08ae56def0268d555df95de1631fa_l3.png "Rendered by QuickLaTeX.com") .
.![\text{rank} \left[ \begin{array}{c|c} A & \textbf{b} \end{array}\right] = r+1](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-5fd36d3c379363c63b70797b8552274c_l3.png "Rendered by QuickLaTeX.com") .
.
The Dot Product
Definition 2.5 is not always the easiest way to compute a matrix-vector product because it requires that the columns of be explicitly identified. There is another way to find such a product which uses the matrix as a whole with no reference to its columns, and hence is useful in practice. The method depends on the following notion.
Definition 2.6 Dot Product in
and  are two ordered -tuples, their
are two ordered -tuples, their  is defined to be the number
is defined to be the number

obtained by multiplying corresponding entries and adding the results.
To see how this relates to matrix products, let denote a matrix and let be a  -vector. Writing
-vector. Writing
![\begin{equation*} \textbf{x} = \left[ \begin{array}{c} x_{1} \\ x_{2} \\ x_{3} \\ x_{4} \end{array} \right] \quad \mbox{ and } \quad A = \left[ \begin{array}{cccc} a_{11} & a_{12} & a_{13} & a_{14} \\ a_{21} & a_{22} & a_{23} & a_{24} \\ a_{31} & a_{32} & a_{33} & a_{34} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f3ea80e54da0842279bb70cc14a7e553_l3.png "Rendered by QuickLaTeX.com")
in the notation of Section 2.1, we compute
![\begin{align*} A\textbf{x} = \left[ \begin{array}{cccc} a_{11} & a_{12} & a_{13} & a_{14} \\ a_{21} & a_{22} & a_{23} & a_{24} \\ a_{31} & a_{32} & a_{33} & a_{34} \end{array} \right] \left[ \begin{array}{c} x_{1} \\ x_{2} \\ x_{3} \\ x_{4} \end{array} \right] &= x_{1} \left[ \begin{array}{c} a_{11} \\ a_{21} \\ a_{31} \end{array} \right] + x_{2} \left[ \begin{array}{c} a_{12} \\ a_{22} \\ a_{32} \end{array} \right] + x_{3} \left[ \begin{array}{c} a_{13} \\ a_{23} \\ a_{33} \end{array} \right] + x_{4} \left[ \begin{array}{c} a_{14} \\ a_{24} \\ a_{34} \end{array} \right] \\ &= \left[ \begin{array}{c} a_{11}x_{1} + a_{12}x_{2} + a_{13}x_{3} + a_{14}x_{4} \\ a_{21}x_{1} + a_{22}x_{2} + a_{23}x_{3} + a_{24}x_{4} \\ a_{31}x_{1} + a_{32}x_{2} + a_{33}x_{3} + a_{34}x_{4} \end{array} \right] \end{align*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f955525af3b1e82deb11d2087f779796_l3.png "Rendered by QuickLaTeX.com")
From this we see that each entry of is the dot product of the corresponding row of with . This computation goes through in general, and we record the result in Theorem 2.2.5.
Theorem 2.2.5 Dot Product Rule
be an matrix and let be an -vector. Then each entry of the vector is the dot product of the corresponding row of with .This result is used extensively throughout linear algebra.
If is and is an -vector, the computation of by the dot product rule is simpler than using Definition 2.5 because the computation can be carried out directly with no explicit reference to the columns of (as in Definition 2.5. The first entry of is the dot product of row 1 of with . In hand calculations this is computed by going across row one of , going down the column , multiplying corresponding entries, and adding the results. The other entries of are computed in the same way using the other rows of with the column .
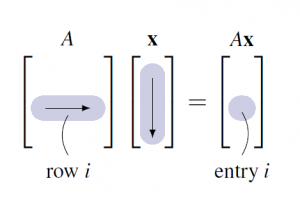
In general, compute entry of as follows (see the diagram):
Go across row of and down column , multiply corresponding entries, and add the results.
As an illustration, we rework Example 2.2.2 using the dot product rule instead of Definition 2.5.
Example 2.2.8
and
, compute .Solution:
The entries of are the dot products of the rows of with :
![\begin{equation*} A\textbf{x} = \left[ \begin{array}{rrrr} 2 & -1 & 3 & 5 \\ 0 & 2 & -3 & 1 \\ -3 & 4 & 1 & 2 \end{array} \right] \left[ \begin{array}{r} 2 \\ 1 \\ 0 \\ -2 \end{array} \right] = \left[ \begin{array}{rrrrrrr} 2 \cdot 2 & + & (-1)1 & + & 3 \cdot 0 & + & 5(-2) \\ 0 \cdot 2 & + & 2 \cdot 1 & + & (-3)0 & + & 1(-2) \\ (-3)2 & + & 4 \cdot 1 & + & 1 \cdot 0 & + & 2(-2) \end{array} \right] = \left[ \begin{array}{r} -7 \\ 0 \\ -6 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-5a5f96c3d90a54f0e655093b1d5c40c9_l3.png "Rendered by QuickLaTeX.com")
Of course, this agrees with the outcome in Example 2.2.2.
Example 2.2.9
.

Solution:
Write ![A = \left[ \begin{array}{rrrrr} 5 & -1 & 2 & 1 & -3 \\ 1 & 1 & 3 & -5 & 2 \\ -1 & 1 & -2 & 0 & -3 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-112544d87064dfb0bd7a54fe3140b6ef_l3.png "Rendered by QuickLaTeX.com") ,
, ![\textbf{b} = \left[ \begin{array}{r} 8 \\ -2 \\ 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f3918bb4bc4a794337ea2f30b7ff96ad_l3.png "Rendered by QuickLaTeX.com") , and
, and ![\textbf{x} = \left[ \begin{array}{c} x_{1} \\ x_{2} \\ x_{3} \\ x_{4} \\ x_{5} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-9dd15327ca7fc6a7383c8109bc157e79_l3.png "Rendered by QuickLaTeX.com") . Then the dot product rule gives
. Then the dot product rule gives ![A\textbf{x} = \left[ \arraycolsep=1pt \begin{array}{rrrrrrrrr} 5x_{1} & - & x_{2} & + & 2x_{3} & + & x_{4} & - & 3x_{5} \\ x_{1} & + & x_{2} & + & 3x_{3} & - & 5x_{4} & + & 2x_{5} \\ -x_{1} & + & x_{2} & - & 2x_{3} & & & - & 3x_{5} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-545617a04dedd29a416290f476a81cc9_l3.png "Rendered by QuickLaTeX.com") , so the entries of are the left sides of the equations in the linear system. Hence the system becomes because matrices are equal if and only corresponding entries are equal.
, so the entries of are the left sides of the equations in the linear system. Hence the system becomes because matrices are equal if and only corresponding entries are equal.
Example 2.2.10
If is the zero matrix, then for each -vector .
Solution:
For each , entry of is the dot product of row of with , and this is zero because row of consists of zeros.
Definition 2.7 The Identity Matrix
 , the
, the 
 is the matrix with 1s on the main diagonal (upper left to lower right), and zeros elsewhere.
is the matrix with 1s on the main diagonal (upper left to lower right), and zeros elsewhere.
The first few identity matrices are
![\begin{equation*} I_{2} = \left[ \begin{array}{rr} 1 & 0 \\ 0 & 1 \end{array} \right], \quad I_{3} = \left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right], \quad I_{4} = \left[ \begin{array}{rrrr} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{array} \right], \quad \dots \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-990bdeed4b6cad3c9d458beecc3e1b31_l3.png "Rendered by QuickLaTeX.com")
In Example 2.2.6 we showed that  for each -vector using Definition 2.5. The following result shows that this holds in general, and is the reason for the name.
for each -vector using Definition 2.5. The following result shows that this holds in general, and is the reason for the name.
Example 2.2.11
 we have
we have  for each -vector in .
for each -vector in .Solution:
We verify the case  . Given the -vector
. Given the -vector ![\textbf{x} = \left[ \begin{array}{c} x_{1} \\ x_{2} \\ x_{3} \\ x_{4} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-fa849393bb3cfee678eea44076481c2d_l3.png "Rendered by QuickLaTeX.com")
the dot product rule gives
![\begin{equation*} I_{4}\textbf{x} = \left[\begin{array}{rrrr} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{array} \right] \left[ \begin{array}{c} x_{1} \\ x_{2} \\ x_{3} \\ x_{4} \end{array} \right] = \left[ \begin{array}{c} x_{1} + 0 + 0 + 0 \\ 0 + x_{2} + 0 + 0 \\ 0 + 0 + x_{3} + 0 \\ 0 + 0 + 0 + x_{4} \end{array} \right] = \left[ \begin{array}{c} x_{1} \\ x_{2} \\ x_{3} \\ x_{4} \end{array} \right] = \vect{x} \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-19ec3618cdc90363702b9cdb2c834ed4_l3.png "Rendered by QuickLaTeX.com")
In general, because entry of  is the dot product of row of with , and row of has
is the dot product of row of with , and row of has  in position and zeros elsewhere.
in position and zeros elsewhere.
Example 2.2.12
be any matrix with columns . If  denotes column of the identity matrix , then
denotes column of the identity matrix , then  for each
for each  .
.Solution:
Write ![\textbf{e}_{j} = \left[ \begin{array}{c} t_{1} \\ t_{2} \\ \vdots \\ t_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e6e528df25293d56acf926df82c7cb23_l3.png "Rendered by QuickLaTeX.com")
where  , but
, but  for all
for all  . Then Theorem 2.2.5 gives
. Then Theorem 2.2.5 gives

Example 2.2.12will be referred to later; for now we use it to prove:
Theorem 2.2.6
and be matrices. If  for all in , then .
for all in , then .Proof:
Write and and in terms of their columns. It is enough to show that  holds for all . But we are assuming that
holds for all . But we are assuming that  , which gives by Example 2.2.12.
, which gives by Example 2.2.12.
We have introduced matrix-vector multiplication as a new way to think about systems of linear equations. But it has several other uses as well. It turns out that many geometric operations can be described using matrix multiplication, and we now investigate how this happens. As a bonus, this description provides a geometric “picture” of a matrix by revealing the effect on a vector when it is multiplied by . This “geometric view” of matrices is a fundamental tool in understanding them.
2.3 Matrix Multiplication
In Section 2.2 matrix-vector products were introduced. If is an matrix, the product was defined for any -column in as follows: If where the are the columns of , and if ,
Definition 2.5 reads
(2.5) 
This was motivated as a way of describing systems of linear equations with coefficient matrix . Indeed every such system has the form where is the column of constants.
In this section we extend this matrix-vector multiplication to a way of multiplying matrices in general, and then investigate matrix algebra for its own sake. While it shares several properties of ordinary arithmetic, it will soon become clear that matrix arithmetic is different in a number of ways.
Definition 2.9 Matrix Multiplication
be an matrix, let be an  matrix, and write
matrix, and write ![B = \left[ \begin{array}{cccc} \textbf{b}_{1} & \textbf{b}_{2} & \cdots & \textbf{b}_{k} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6e72e7b0d95fad19922a98b6c1601abd_l3.png "Rendered by QuickLaTeX.com") where
where  is column of for each . The product matrix
is column of for each . The product matrix  is the
is the  matrix defined as follows:
matrix defined as follows:
![\begin{equation*} AB = A \left[ \begin{array}{cccc} \textbf{b}_{1} & \textbf{b}_{2} & \cdots & \textbf{b}_{k} \end{array} \right] = \left[ \begin{array}{cccc} A\textbf{b}_{1} & A\textbf{b}_{2} & \cdots & A\textbf{b}_{k} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c988ad7eadb2adda436445f65af0e0b4_l3.png "Rendered by QuickLaTeX.com")
Thus the product matrix is given in terms of its columns  : Column of is the matrix-vector product
: Column of is the matrix-vector product  of and the corresponding column of . Note that each such product makes sense by Definition 2.5 because is and each
of and the corresponding column of . Note that each such product makes sense by Definition 2.5 because is and each  is in (since has rows). Note also that if is a column matrix, this definition reduces to Definition 2.5 for matrix-vector multiplication.
is in (since has rows). Note also that if is a column matrix, this definition reduces to Definition 2.5 for matrix-vector multiplication.
Given matrices and , Definition 2.9 and the above computation give
![\begin{equation*} A(B\vec{x}) = \left[ \begin{array}{cccc} A\vec{b}_{1} & A\vec{b}_{2} & \cdots & A\vec{b}_{n} \end{array} \right] \vec{x} = (AB)\vec{x} \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f6fd02f816ddb4cf3f66dd17d04b327e_l3.png "Rendered by QuickLaTeX.com")
for all  in
in  . We record this for reference.
. We record this for reference.
Theorem 2.3.1
be an matrix and let be an matrix. Then the product matrix is and satisfies

Here is an example of how to compute the product of two matrices using Definition 2.9.
Example 2.3.1
if ![A = \left[ \begin{array}{rrr} 2 & 3 & 5 \\ 1 & 4 & 7 \\ 0 & 1 & 8 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-150065d7fe1fd50383eb17d6412b1738_l3.png "Rendered by QuickLaTeX.com")
and
![B = \left[\begin{array}{rr} 8 & 9 \\ 7 & 2 \\ 6 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cabec8536af1589b0245e0257dcfd1c9_l3.png "Rendered by QuickLaTeX.com") .
.Solution:
The columns of are
![\vec{b}_{1} = \left[ \begin{array}{r} 8 \\ 7 \\ 6 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-be714baaba046440a96a706e8c30ef54_l3.png "Rendered by QuickLaTeX.com") and
and ![\vec{b}_{2} = \left[ \begin{array}{r} 9 \\ 2 \\ 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-70cdb66551245417b21df563eac9aae9_l3.png "Rendered by QuickLaTeX.com") , so Definition 2.5 gives
, so Definition 2.5 gives
![\begin{equation*} A\vec{b}_{1} = \left[ \begin{array}{rrr} 2 & 3 & 5 \\ 1 & 4 & 7 \\ 0 & 1 & 8 \end{array} \right] \left[ \begin{array}{r} 8 \\ 7 \\ 6 \end{array} \right] = \left[ \begin{array}{r} 67 \\ 78 \\ 55 \end{array} \right] \mbox{ and } A\vec{b}_{2} = \left[ \begin{array}{rrr} 2 & 3 & 5 \\ 1 & 4 & 7 \\ 0 & 1 & 8 \end{array} \right] \left[ \begin{array}{r} 9 \\ 2 \\ 1 \end{array} \right] = \left[\begin{array}{r} 29 \\ 24 \\ 10 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e078a867223cffb5fcc5ae6efe8d4375_l3.png "Rendered by QuickLaTeX.com")
Hence Definition 2.9 above gives ![AB = \left[ \begin{array}{cc} A\vec{b}_{1} & A\vec{b}_{2} \end{array} \right] = \left[ \begin{array}{rr} 67 & 29 \\ 78 & 24 \\ 55 & 10 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-19e38d5e5028c7808ba0f390ef34c203_l3.png "Rendered by QuickLaTeX.com") .
.
While Definition 2.9 is important, there is another way to compute the matrix product that gives a way to calculate each individual entry. In Section 2.2 we defined the dot product of two -tuples to be the sum of the products of corresponding entries. We went on to show (Theorem 2.2.5) that if is an matrix and is an -vector, then entry of the product  is the dot product of row of with . This observation was called the “dot product rule” for matrix-vector multiplication, and the next theorem shows that it extends to matrix multiplication in general.
is the dot product of row of with . This observation was called the “dot product rule” for matrix-vector multiplication, and the next theorem shows that it extends to matrix multiplication in general.
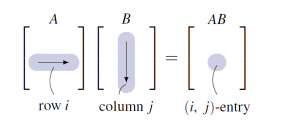
Theorem 2.3.2 Dot Product Rule
and be matrices of sizes and , respectively. Then the -entry of is the dotproduct of row
of with column of .Proof:
Write ![B = \left[ \begin{array}{cccc} \vec{b}_{1} & \vec{b}_{2} & \cdots & \vec{b}_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-73c690c6b94d501ff490416ac6a3de35_l3.png "Rendered by QuickLaTeX.com") in terms of its columns. Then
in terms of its columns. Then  is column of for each . Hence the -entry of is entry of , which is the dot product of row of with
is column of for each . Hence the -entry of is entry of , which is the dot product of row of with  . This proves the theorem.
. This proves the theorem.
Thus to compute the -entry of , proceed as follows (see the diagram):
Go across row of , and down column of , multiply corresponding entries, and add the results.
Note that this requires that the rows of must be the same length as the columns of . The following rule is useful for remembering this and for deciding the size of the product matrix .
Compatibility Rule
Let and denote matrices. If is and is  , the product can be formed if and only if
, the product can be formed if and only if  . In this case the size of the product matrix is , and we say that is defined, or that and are compatible for multiplication.
. In this case the size of the product matrix is , and we say that is defined, or that and are compatible for multiplication.
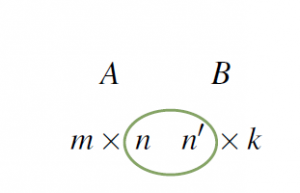
The diagram provides a useful mnemonic for remembering this. We adopt the following convention:
Whenever a product of matrices is written, it is tacitly assumed that the sizes of the factors are such that the product is defined.
To illustrate the dot product rule, we recompute the matrix product in Example 2.3.1.
Example 2.3.3
if and
![B = \left[ \begin{array}{rr} 8 & 9 \\ 7 & 2 \\ 6 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f01a349370b30ab76899f1fe24b42d0d_l3.png "Rendered by QuickLaTeX.com") .
.Solution:
Here is and is  , so the product matrix is defined and will be of size . Theorem 2.3.2 gives each entry of as the dot product of the corresponding row of with the corresponding column of
, so the product matrix is defined and will be of size . Theorem 2.3.2 gives each entry of as the dot product of the corresponding row of with the corresponding column of  that is,
that is,
![\begin{equation*} AB = \left[ \begin{array}{rrr} 2 & 3 & 5 \\ 1 & 4 & 7 \\ 0 & 1 & 8 \end{array} \right] \left[ \begin{array}{rr} 8 & 9 \\ 7 & 2 \\ 6 & 1 \end{array} \right]= \left[ \arraycolsep=8pt \begin{array}{cc} 2 \cdot 8 + 3 \cdot 7 + 5 \cdot 6 & 2 \cdot 9 + 3 \cdot 2 + 5 \cdot 1 \\ 1 \cdot 8 + 4 \cdot 7 + 7 \cdot 6 & 1 \cdot 9 + 4 \cdot 2 + 7 \cdot 1 \\ 0 \cdot 8 + 1 \cdot 7 + 8 \cdot 6 & 0 \cdot 9 + 1 \cdot 2 + 8 \cdot 1 \end{array} \right] = \left[ \begin{array}{rr} 67 & 29 \\ 78 & 24 \\ 55 & 10 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-7f81020ed592dab37b83237cc5cb4ce8_l3.png "Rendered by QuickLaTeX.com")
Of course, this agrees with Example 2.3.1.
Example 2.3.4
 – and
– and  -entries of where
-entries of where
![\begin{equation*} A = \left[ \begin{array}{rrr} 3 & -1 & 2 \\ 0 & 1 & 4 \end{array} \right] \mbox{ and } B = \left[ \begin{array}{rrrr} 2 & 1 & 6 & 0 \\ 0 & 2 & 3 & 4 \\ -1 & 0 & 5 & 8 \end{array} \right]. \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cbb13e6ee08e2383f978deae780bf269_l3.png "Rendered by QuickLaTeX.com")
Then compute .
Solution:
The -entry of is the dot product of row 1 of and column 3 of (highlighted in the following display), computed by multiplying corresponding entries and adding the results.
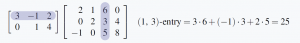
Similarly, the -entry of involves row 2 of and column 4 of .
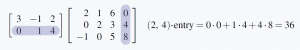
Since is and is , the product is  .
.
![\begin{equation*} AB = \left[ \begin{array}{rrr} 3 & -1 & 2 \\ 0 & 1 & 4 \end{array} \right] \left[ \begin{array}{rrrr} 2 & 1 & 6 & 0 \\ 0 & 2 & 3 & 4 \\ -1 & 0 & 5 & 8 \end{array} \right] = \left[ \begin{array}{rrrr} 4 & 1 & 25 & 12 \\ -4 & 2 & 23 & 36 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-af24c6d9eac17df7f4c5add5874eb5c5_l3.png "Rendered by QuickLaTeX.com")
Example 2.3.5
![A = \left[ \begin{array}{ccc} 1 & 3 & 2\end{array}\right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6d493a65ad4978c61a6ccf94494a29c5_l3.png "Rendered by QuickLaTeX.com") and
and ![B = \left[ \begin{array}{r} 5 \\ 6 \\ 4 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-5d2a61617fd897fffc16706f2f2d643c_l3.png "Rendered by QuickLaTeX.com") , compute
, compute  , ,
, ,  , and
, and  when they are defined.
when they are defined.Solution:
Here, is a  matrix and is a matrix, so and are not defined. However, the compatibility rule reads
matrix and is a matrix, so and are not defined. However, the compatibility rule reads

so both and can be formed and these are  and matrices, respectively.
and matrices, respectively.
![\begin{equation*} AB = \left[ \begin{array}{rrr} 1 & 3 & 2 \end{array} \right] \left[ \begin{array}{r} 5 \\ 6 \\ 4 \end{array} \right] = \left[ \begin{array}{c} 1 \cdot 5 + 3 \cdot 6 + 2 \cdot 4 \end{array} \right] = \arraycolsep=1.5pt \left[ \begin{array}{c} 31 \end{array}\right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-7afabbff2e1ff7670ae95558fc8eff68_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} BA = \left[ \begin{array}{r} 5 \\ 6 \\ 4 \end{array} \right] \left[ \begin{array}{rrr} 1 & 3 & 2 \end{array} \right] = \left[ \begin{array}{rrr} 5 \cdot 1 & 5 \cdot 3 & 5 \cdot 2 \\ 6 \cdot 1 & 6 \cdot 3 & 6 \cdot 2 \\ 4 \cdot 1 & 4 \cdot 3 & 4 \cdot 2 \end{array} \right] = \left[ \begin{array}{rrr} 5 & 15 & 10 \\ 6 & 18 & 12 \\ 4 & 12 & 8 \end{array} \right \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-20ecc1edfb2243fbba8a7f827b72adc7_l3.png "Rendered by QuickLaTeX.com")
Unlike numerical multiplication, matrix products and need not be equal. In fact they need not even be the same size, as Example 2.3.5 shows. It turns out to be rare that  (although it is by no means impossible), and and are said to commute when this happens.
(although it is by no means impossible), and and are said to commute when this happens.
Example 2.3.6
![A = \left[ \begin{array}{rr} 6 & 9 \\ -4 & -6 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-bdfc43a92e198b02e19b072d7ab5a289_l3.png "Rendered by QuickLaTeX.com") and
and ![B = \left[ \begin{array}{rr} 1 & 2 \\ -1 & 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-3376671e520bce856360af31e8caea77_l3.png "Rendered by QuickLaTeX.com") . Compute , , .
. Compute , , .Solution:
![A^{2} = \left[ \begin{array}{rr} 6 & 9 \\ -4 & -6 \end{array} \right] \left[ \begin{array}{rr} 6 & 9 \\ -4 & -6 \end{array} \right] = \left[ \begin{array}{rr} 0 & 0 \\ 0 & 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a611491746b1955294c8033955cfff6e_l3.png "Rendered by QuickLaTeX.com") , so
, so  can occur even if
can occur even if  . Next,
. Next,
![\begin{align*} AB & = \left[ \begin{array}{rr} 6 & 9 \\ -4 & -6 \end{array} \right] \left[ \begin{array}{rr} 1 & 2 \\ -1 & 0 \end{array} \right] = \left[ \begin{array}{rr} -3 & 12 \\ 2 & -8 \end{array} \right] \\ BA & = \left[ \begin{array}{rr} 1 & 2 \\ -1 & 0 \end{array} \right] \left[ \begin{array}{rr} 6 & 9 \\ -4 & -6 \end{array} \right] = \left[ \begin{array}{rr} -2 & -3 \\ -6 & -9 \end{array} \right] \end{align*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-90f6044a494dc0f209c0325f1b5eddd6_l3.png "Rendered by QuickLaTeX.com")
Hence  , even though and are the same size.
, even though and are the same size.
Example 2.3.7
is any matrix, then  and
and  , and where denotes an identity matrix of a size so that the multiplications are defined.
, and where denotes an identity matrix of a size so that the multiplications are defined.Solution:
These both follow from the dot product rule as the reader should verify. For a more formal proof, write ![A = \left[ \begin{array}{rrrr} \vec{a}_{1} & \vec{a}_{2} & \cdots & \vec{a}_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e3182d05a72e677e90a4eac2454c83f7_l3.png "Rendered by QuickLaTeX.com") where
where  is column of . Then Definition 2.9 and Example 2.2.1 give
is column of . Then Definition 2.9 and Example 2.2.1 give
![\begin{equation*} IA = \left[ \begin{array}{rrrr} I\vec{a}_{1} & I\vec{a}_{2} & \cdots & I\vec{a}_{n} \end{array} \right] = \left[ \begin{array}{rrrr} \vect{a}_{1} & \vect{a}_{2} & \cdots & \vect{a}_{n} \end{array} \right] = A \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a39f5b30d17fd438cf947b7cba1bab5d_l3.png "Rendered by QuickLaTeX.com")
If  denotes column of , then
denotes column of , then  for each by Example 2.2.12. Hence Definition 2.9 gives:
for each by Example 2.2.12. Hence Definition 2.9 gives:
![\begin{equation*} AI = A \left[ \begin{array}{rrrr} \vec{e}_{1} & \vec{e}_{2} & \cdots & \vec{e}_{n} \end{array} \right] = \left[ \begin{array}{rrrr} A\vec{e}_{1} & A\vec{e}_{2} & \cdots & A\vec{e}_{n} \end{array} \right] = \left[ \begin{array}{rrrr} \vec{a}_{1} & \vec{a}_{2} & \cdots & \vec{a}_{n} \end{array} \right] = A \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-20fcf0fcc583b2d810283fe031d0d1c0_l3.png "Rendered by QuickLaTeX.com")
The following theorem collects several results about matrix multiplication that are used everywhere in linear algebra.
Theorem 2.3.3
Assume that is any scalar, and that , , and are matrices of sizes such that the indicated matrix products are defined. Then:
1. and where denotes an identity matrix.
2.  .
.
3.  .
.
4.  .
.
5.  .
.
6.  .
.
Proof:
Condition (1) is Example 2.3.7; we prove (2), (4), and (6) and leave (3) and (5) as exercises.
1. If ![C = \left[ \begin{array}{cccc} \vec{c}_{1} & \vec{c}_{2} & \cdots & \vec{c}_{k} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-da2b82de7df077ed7edf54e9f49cba7a_l3.png "Rendered by QuickLaTeX.com") in terms of its columns, then
in terms of its columns, then ![BC = \left[ \begin{array}{cccc} B\vec{c}_{1} & B\vec{c}_{2} & \cdots & B\vec{c}_{k} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-9d58ca5a64c07bc5a8fd4f7990db4395_l3.png "Rendered by QuickLaTeX.com") by Definition 2.9, so
by Definition 2.9, so
![\begin{equation*} \begin{array}{lllll} A(BC) & = & \left[ \begin{array}{rrrr} A(B\vec{c}_{1}) & A(B\vec{c}_{2}) & \cdots & A(B\vec{c}_{k}) \end{array} \right] & & \mbox{Definition 2.9} \\ & & & & \\ & = & \left[ \begin{array}{rrrr} (AB)\vec{c}_{1} & (AB)\vec{c}_{2} & \cdots & (AB)\vec{c}_{k}) \end{array} \right] & & \mbox{Theorem 2.3.1} \\ & & & & \\ & = & (AB)C & & \mbox{Definition 2.9} \end{array} \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a554ce3a1b2e5bb6eab4b1347e58f982_l3.png "Rendered by QuickLaTeX.com")
4. We know (Theorem 2.2.) that  holds for every column . If we write in terms of its columns, we get
holds for every column . If we write in terms of its columns, we get
![\begin{equation*} \begin{array}{lllll} (B + C)A & = & \left[ \begin{array}{rrrr} (B + C)\vec{a}_{1} & (B + C)\vec{a}_{2} & \cdots & (B + C)\vec{a}_{n} \end{array} \right] & & \mbox{Definition 2.9} \\ & & & & \\ & = & \left[ \begin{array}{rrrr} B\vec{a}_{1} + C\vec{a}_{1} & B\vec{a}_{2} + C\vec{a}_{2} & \cdots & B\vec{a}_{n} + C\vec{a}_{n} \end{array} \right] & & \mbox{Theorem 2.2.2} \\ & & & & \\ & = & \left[ \begin{array}{rrrr} B\vec{a}_{1} & B\vec{a}_{2} & \cdots & B\vec{a}_{n} \end{array} \right] + \left[ \begin{array}{rrrr} C\vec{a}_{1} & C\vec{a}_{2} & \cdots & C\vec{a}_{n} \end{array} \right] & & \mbox{Adding Columns} \\ & & & & \\ & = & BA + CA & & \mbox{Definition 2.9} \end{array} \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cc87d4b3237ecf4f370a1a69712fae1e_l3.png "Rendered by QuickLaTeX.com")
6. As in Section 2.1, write ![A = [a_{ij}]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-57ec88ff10080a0ac83b7eea9c68d646_l3.png "Rendered by QuickLaTeX.com") and
and ![B = [b_{ij}]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-dbe99310ed5fe45faad33ca0e929cadc_l3.png "Rendered by QuickLaTeX.com") , so that
, so that ![A^{T} = [a^\prime_{ij}]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6f5547e429f072d9718246c38a058252_l3.png "Rendered by QuickLaTeX.com") and
and ![B^{T} = [b^\prime_{ij}]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-fd7e72c6ab01ee06a463ab7989f75570_l3.png "Rendered by QuickLaTeX.com") where
where  and
and  for all and . If
for all and . If  denotes the -entry of
denotes the -entry of  , then is the dot product of row of
, then is the dot product of row of  with column of . Hence
with column of . Hence

But this is the dot product of row of with column of ; that is, the  -entry of ; that is, the -entry of
-entry of ; that is, the -entry of  . This proves (6).
. This proves (6).
Property 2 in Theorem 2.3.3 is called the associative law of matrix multiplication. It asserts that the equation holds for all matrices (if the products are defined). Hence this product is the same no matter how it is formed, and so is written simply as  . This extends: The product
. This extends: The product  of four matrices can be formed several ways—for example,
of four matrices can be formed several ways—for example,  ,
, ![[A(BC)]D](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6daad989fbef471ddc7249611a042e2f_l3.png "Rendered by QuickLaTeX.com") , and
, and ![A[B(CD)]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a6d282e0bb5acab7d11ce5f521da619f_l3.png "Rendered by QuickLaTeX.com") —but the associative law implies that they are all equal and so are written as . A similar remark applies in general: Matrix products can be written unambiguously with no parentheses.
—but the associative law implies that they are all equal and so are written as . A similar remark applies in general: Matrix products can be written unambiguously with no parentheses.
However, a note of caution about matrix multiplication must be taken: The fact that and need not be equal means that the order of the factors is important in a product of matrices. For example and  may not be equal.
may not be equal.
Warning:
If the order of the factors in a product of matrices is changed, the product matrix may change (or may not be defined). Ignoring this warning is a source of many errors by students of linear algebra!}
Properties 3 and 4 in Theorem 2.3.3 are called distributive laws. They assert that and hold whenever the sums and products are defined. These rules extend to more than two terms and, together with Property 5, ensure that many manipulations familiar from ordinary algebra extend to matrices. For example

Note again that the warning is in effect: For example  need not equal
need not equal  . These rules make possible a lot of simplification of matrix expressions.
. These rules make possible a lot of simplification of matrix expressions.
Example 2.3.8
 .
.Solution:

Example 2.3.9 and Example 2.3.10 below show how we can use the properties in Theorem 2.3.2to deduce other facts about matrix multiplication. Matrices and are said to commute if .
Example 2.3.9
, , and are matrices and that both and commute with ; that is,  and
and  . Show that commutes with .
. Show that commutes with .Solution:
Showing that commutes with means verifying that  . The computation uses the associative law several times, as well as the given facts that and .
. The computation uses the associative law several times, as well as the given facts that and .

Example 2.3.10
if and only if  .
.Solution:
The following always holds:
(2.6) 
Hence if , then follows. Conversely, if this last equation holds, then equation (2.6 becomes

This gives  , and follows.
, and follows.
In Section 2.2 we saw (in Theorem 2.2.1 ) that every system of linear equations has the form

where is the coefficient matrix, is the column of variables, and  is the constant matrix. Thus the system of linear equations becomes a single matrix equation. Matrix multiplication can yield information about such a system.
is the constant matrix. Thus the system of linear equations becomes a single matrix equation. Matrix multiplication can yield information about such a system.
Example 2.3.11
 of linear equations where is an matrix. Assume that a matrix exists such that
of linear equations where is an matrix. Assume that a matrix exists such that  . If the system has a solution, show that this solution must be
. If the system has a solution, show that this solution must be  . Give a condition guaranteeing that is in fact a solution.
. Give a condition guaranteeing that is in fact a solution.Solution:
Suppose that is any solution to the system, so that . Multiply both sides of this matrix equation by to obtain, successively,

This shows that if the system has a solution , then that solution must be  , as required. But it does not guarantee that the system has a solution. However, if we write
, as required. But it does not guarantee that the system has a solution. However, if we write  , then
, then

Thus will be a solution if the condition  is satisfied.
is satisfied.
The ideas in Example 2.3.11 lead to important information about matrices; this will be pursued in the next section.
2.4 Matrix Inverse
Three basic operations on matrices, addition, multiplication, and subtraction, are analogs for matrices of the same operations for numbers. In this section we introduce the matrix analog of numerical division.
To begin, consider how a numerical equation  is solved when and are known numbers. If
is solved when and are known numbers. If  , there is no solution (unless ). But if
, there is no solution (unless ). But if  , we can multiply both sides by the inverse
, we can multiply both sides by the inverse  to obtain the solution
to obtain the solution  . Of course multiplying by
. Of course multiplying by  is just dividing by , and the property of that makes this work is that
is just dividing by , and the property of that makes this work is that  . Moreover, we saw in Section~?? that the role that plays in arithmetic is played in matrix algebra by the identity matrix . This suggests the following definition.
. Moreover, we saw in Section~?? that the role that plays in arithmetic is played in matrix algebra by the identity matrix . This suggests the following definition.
Definition 2.11 Matrix Inverses
is a square matrix, a matrix is called an inverse of if and only if

A matrix that has an inverse is called an 
Note that only square matrices have inverses. Even though it is plausible that nonsquare matrices and could exist such that  and
and  , where is and is , we claim that this forces . Indeed, if
, where is and is , we claim that this forces . Indeed, if  there exists a nonzero column such that
there exists a nonzero column such that  (by Theorem 1.3.1), so
(by Theorem 1.3.1), so  , a contradiction. Hence
, a contradiction. Hence  . Similarly, the condition implies that
. Similarly, the condition implies that  . Hence
. Hence  so is square.}
so is square.}
Example 2.4.1
![B = \left[ \begin{array}{rr} -1 & 1 \\ 1 & 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cf19b03b112d5d2923ab0e826c73f3e4_l3.png "Rendered by QuickLaTeX.com")
is an inverse of
![A = \left[ \begin{array}{rr} 0 & 1 \\ 1 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-d59edd2b72fc15508d3b90fa4c7c838c_l3.png "Rendered by QuickLaTeX.com") .
.Solution:
Compute and .
![\begin{equation*} AB = \left[ \begin{array}{rr} 0 & 1 \\ 1 & 1 \end{array} \right] \left[ \begin{array}{rr} -1 & 1 \\ 1 & 0 \end{array} \right] = \left[ \begin{array}{rr} 1 & 0 \\ 0 & 1 \end{array} \right] \quad BA = \left[ \begin{array}{rr} -1 & 1 \\ 1 & 0 \end{array} \right] \left[ \begin{array}{rr} 0 & 1 \\ 1 & 1 \end{array} \right] = \left[ \begin{array}{rr} 1 & 0 \\ 0 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-471b7a6ad651c3ee385fea11db0b90bf_l3.png "Rendered by QuickLaTeX.com")
Hence  , so is indeed an inverse of .
, so is indeed an inverse of .
Example 2.4.2
![A = \left[ \begin{array}{rr} 0 & 0 \\ 1 & 3 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-48aa3348c447cca2ffaef5a995e2a4a8_l3.png "Rendered by QuickLaTeX.com")
has no inverse.
Solution:
Let ![B = \left[ \begin{array}{rr} a & b \\ c & d \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-ce0543f6937335022195267d5d1d656c_l3.png "Rendered by QuickLaTeX.com")
denote an arbitrary matrix. Then
![\begin{equation*} AB = \left[ \begin{array}{rr} 0 & 0 \\ 1 & 3 \end{array} \right] \left[ \begin{array}{rr} a & b \\ c & d \end{array} \right] = \left[ \begin{array}{cc} 0 & 0 \\ a + 3c & b + 3d \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-856e97b0a65236e96e44d84d21d057f6_l3.png "Rendered by QuickLaTeX.com")
so has a row of zeros. Hence cannot equal for any .
The argument in Example 2.4.2 shows that no zero matrix has an inverse. But Example 2.4.2 also shows that, unlike arithmetic, it is possible for a nonzero matrix to have no inverse. However, if a matrix does have an inverse, it has only one.
Theorem 2.4.1
and are both inverses of , then .Proof:
Since and are both inverses of , we have  . Hence
. Hence

If is an invertible matrix, the (unique) inverse of is denoted  . Hence (when it exists) is a square matrix of the same size as with the property that
. Hence (when it exists) is a square matrix of the same size as with the property that

These equations characterize in the following sense:
Inverse Criterion: If somehow a matrix can be found such that  and
and  , then is invertible and is the inverse of ; in symbols,
, then is invertible and is the inverse of ; in symbols,  .}
.}
This is a way to verify that the inverse of a matrix exists. Example 2.3.3 and Example 2.3.4 offer illustrations.
Example 2.4.3
![A = \left[ \begin{array}{rr} 0 & -1 \\ 1 & -1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a5bf0e767b45d47ebab559be9923b89d_l3.png "Rendered by QuickLaTeX.com") , show that
, show that  and so find .
and so find .Solution:
We have ![A^{2} = \left[ \begin{array}{rr} 0 & -1 \\ 1 & -1 \end{array} \right] \left[ \begin{array}{rr} 0 & -1 \\ 1 & -1 \end{array} \right] = \left[ \begin{array}{rr} -1 & 1 \\ -1 & 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-87688b35e7955a00a0aee299c17b7b1a_l3.png "Rendered by QuickLaTeX.com") , and so
, and so
![\begin{equation*} A^{3} = A^{2}A = \left[ \begin{array}{rr} -1 & 1 \\ -1 & 0 \end{array} \right] \left[ \begin{array}{rr} 0 & -1 \\ 1 & -1 \end{array} \right] = \left[ \begin{array}{rr} 1 & 0 \\ 0 & 1 \end{array} \right] = I \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-2738b9633aeea180379eba8831dfd6eb_l3.png "Rendered by QuickLaTeX.com")
Hence , as asserted. This can be written as  , so it shows that is the inverse of . That is,
, so it shows that is the inverse of . That is, ![A^{-1} = A^{2} = \left[ \begin{array}{rr} -1 & 1 \\ -1 & 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6f582cdb79ef633bc1afa63934ab150b_l3.png "Rendered by QuickLaTeX.com") .
.
The next example presents a useful formula for the inverse of a matrix ![A = \left[ \begin{array}{cc} a & b \\ c & d \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a42b19e014d25e05cd0083a5eded3f97_l3.png "Rendered by QuickLaTeX.com") when it exists. To state it, we define the
when it exists. To state it, we define the 
 and the
and the 
 of the matrix as follows:
of the matrix as follows:
![\begin{equation*} \func{det}\left[ \begin{array}{cc} a & b \\ c & d \end{array} \right] = ad - bc, \quad \mbox{ and } \quad \func{adj} \left[ \begin{array}{cc} a & b \\ c & d \end{array} \right] = \left[ \begin{array}{rr} d & -b \\ -c & a \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-25e02c2ce8495b169cdb73766f18f066_l3.png "Rendered by QuickLaTeX.com")
Example 2.4.4
, show that has an inverse if and only if  , and in this case
, and in this case

Solution:
For convenience, write  and
and
![B = \func{adj } A = \left[ \begin{array}{rr} d & -b \\ -c & a \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-93b0ceb194a70f0aca76f7c98ed1fd10_l3.png "Rendered by QuickLaTeX.com") . Then
. Then  as the reader can verify. So if
as the reader can verify. So if  , scalar multiplication by
, scalar multiplication by  gives
gives

Hence is invertible and  . Thus it remains only to show that if exists, then .
. Thus it remains only to show that if exists, then .
We prove this by showing that assuming  leads to a contradiction. In fact, if , then
leads to a contradiction. In fact, if , then  , so left multiplication by gives
, so left multiplication by gives  ; that is,
; that is,  , so
, so  . But this implies that , , , and
. But this implies that , , , and  are all zero, so , contrary to the assumption that exists.
are all zero, so , contrary to the assumption that exists.
As an illustration, if ![A = \left[ \begin{array}{rr} 2 & 4 \\ -3 & 8 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-88aab1a74cde98b55b89b1e2e7f0b707_l3.png "Rendered by QuickLaTeX.com")
then  . Hence is invertible and
. Hence is invertible and ![A^{-1} = \frac{1}{\func{det } A} \func{adj } A = \frac{1}{28} \left[ \begin{array}{rr} 8 &-4 \\ 3 & 2 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-2bd453970956b8e3c517afbec71a6d0d_l3.png "Rendered by QuickLaTeX.com") , as the reader is invited to verify.
, as the reader is invited to verify.
The determinant and adjugate will be defined in Chapter 3 for any square matrix, and the conclusions in Example 2.4.4 will be proved in full generality.
Inverse and Linear systems
Matrix inverses can be used to solve certain systems of linear equations. Recall that a  of linear equations can be written as a
of linear equations can be written as a  matrix equation
matrix equation
where and are known and is to be determined. If is invertible, we multiply each side of the equation on the left by to get

This gives the solution to the system of equations (the reader should verify that  really does satisfy ). Furthermore, the argument shows that if is
really does satisfy ). Furthermore, the argument shows that if is  solution, then necessarily , so the solution is unique. Of course the technique works only when the coefficient matrix has an inverse. This proves Theorem 2.4.2.
solution, then necessarily , so the solution is unique. Of course the technique works only when the coefficient matrix has an inverse. This proves Theorem 2.4.2.
Theorem 2.4.2
equations in variables is written in matrix form as
If the coefficient matrix is invertible, the system has the unique solution

Example 2.4.5
 .
.Solution:
In matrix form this is where ![A = \left[ \begin{array}{rr} 5 & -3 \\ 7 & 4 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-06e4d97c70e5b3b84a00eb5bea3662a7_l3.png "Rendered by QuickLaTeX.com") ,
, ![\vec{x} = \left[ \begin{array}{c} x_{1} \\ x_{2} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-74d0f79d783bb1ddaa631d6d64736c17_l3.png "Rendered by QuickLaTeX.com") , and
, and ![\vec{b} = \left[ \begin{array}{r} -4 \\ 8 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6e8f51a183f19e61d8c3ef1c52340cb5_l3.png "Rendered by QuickLaTeX.com") . Then
. Then  , so is invertible and
, so is invertible and ![A^{-1} = \frac{1}{41} \left[ \begin{array}{rr} 4 & 3 \\ -7 & 5 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-31b2fe5996c819dbebaf414838d72661_l3.png "Rendered by QuickLaTeX.com")
by Example 2.4.4. Thus Theorem 2.4.2 gives
![\begin{equation*} \vec{x} = A^{-1}\vec{b} = \frac{1}{41} \left[ \begin{array}{rr} 4 & 3 \\ -7 & 5 \end{array} \right] \left[ \begin{array}{r} -4 \\ 8 \end{array} \right] = \frac{1}{41} \left[ \begin{array}{r} 8 \\ 68 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f53e66af40a4e19c64bcadcdd9bd46b4_l3.png "Rendered by QuickLaTeX.com")
so the solution is  and
and  .
.
An inversion method
If a matrix is and invertible, it is desirable to have an efficient technique for finding the inverse. The following procedure will be justified in Section 2.5.
Matrix Inversion Algorithm
is an invertible (square) matrix, there exists a sequence of elementary row operations that carry to the identity matrix of the same size, written  . This same series of row operations carries to ; that is,
. This same series of row operations carries to ; that is,  . The algorithm can be summarized as follows:
. The algorithm can be summarized as follows:
![\begin{equation*} \left[ \begin{array}{cc} A & I \end{array} \right] \rightarrow \left[ \begin{array}{cc} I & A^{-1} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e69eb40c109a1f494aef37a05c76342e_l3.png "Rendered by QuickLaTeX.com")
where the row operations on and are carried out simultaneously.
Example 2.4.6
![\begin{equation*} A = \left[ \begin{array}{rrr} 2 & 7 & 1 \\ 1 & 4 & -1 \\ 1 & 3 & 0 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f40d95ed68a3b8d4a6293659f7805c46_l3.png "Rendered by QuickLaTeX.com")
Solution:
Apply elementary row operations to the double matrix
![\begin{equation*} \left[ \begin{array}{rrr} A & I \end{array} \right] = \left[ \begin{array}{rrr|rrr} 2 & 7 & 1 & 1 & 0 & 0 \\ 1 & 4 & -1 & 0 & 1 & 0 \\ 1 & 3 & 0 & 0 & 0 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cc78fbe2bc855fe2f21553358eb7c9b6_l3.png "Rendered by QuickLaTeX.com")
so as to carry to . First interchange rows 1 and 2.
![\begin{equation*} \left[ \begin{array}{rrr|rrr} 1 & 4 & -1 & 0 & 1 & 0 \\ 2 & 7 & 1 & 1 & 0 & 0 \\ 1 & 3 & 0 & 0 & 0 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c6486d76c87127a5b2773ea9d7c1788b_l3.png "Rendered by QuickLaTeX.com")
Next subtract times row 1 from row 2, and subtract row 1 from row 3.
![\begin{equation*} \left[ \begin{array}{rrr|rrr} 1 & 4 & -1 & 0 & 1 & 0 \\ 0 & -1 & 3 & 1 & -2 & 0 \\ 0 & -1 & 1 & 0 & -1 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-fc2e64ffa0839ad2654b1c0c77b0106e_l3.png "Rendered by QuickLaTeX.com")
Continue to reduced row-echelon form.
![\begin{equation*} \left[ \begin{array}{rrr|rrr} 1 & 0 & 11 & 4 & -7 & 0 \\ 0 & 1 & -3 & -1 & 2 & 0 \\ 0 & 0 & -2 & -1 & 1 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-bae649907a67ba339bb403be2de79cac_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \left[ \def\arraystretch{1.5} \begin{array}{rrr|rrr} 1 & 0 & 0 & \frac{-3}{2} & \frac{-3}{2} & \frac{11}{2} \\ 0 & 1 & 0 & \frac{1}{2} & \frac{1}{2} & \frac{-3}{2} \\ 0 & 0 & 1 & \frac{1}{2} & \frac{-1}{2} & \frac{-1}{2} \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-059b8d000f37736c6eb3c83482e882ed_l3.png "Rendered by QuickLaTeX.com")
Hence ![A^{-1} = \frac{1}{2} \left[ \begin{array}{rrr} -3 & -3 & 11 \\ 1 & 1 & -3 \\ 1 & -1 & -1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-b789ae7ef4f2e2763174c4eece831580_l3.png "Rendered by QuickLaTeX.com") , as is readily verified.
, as is readily verified.
Given any matrix , Theorem 1.2.1 shows that can be carried by elementary row operations to a matrix  in reduced row-echelon form. If
in reduced row-echelon form. If  , the matrix is invertible (this will be proved in the next section), so the algorithm produces . If
, the matrix is invertible (this will be proved in the next section), so the algorithm produces . If  , then has a row of zeros (it is square), so no system of linear equations
, then has a row of zeros (it is square), so no system of linear equations  can have a unique solution. But then is not invertible by Theorem 2.4.2. Hence, the algorithm is effective in the sense conveyed in Theorem 2.4.3.
can have a unique solution. But then is not invertible by Theorem 2.4.2. Hence, the algorithm is effective in the sense conveyed in Theorem 2.4.3.
Theorem 2.4.3
is an matrix, either can be reduced to by elementary row operations or it cannot. In thefirst case, the algorithm produces
; in the second case, does not exist.
Properties of inverses
The following properties of an invertible matrix are used everywhere.
Example 2.4.7: Cancellation Laws
Let be an invertible matrix. Show that:
1. If  , then .
, then .
2. If  , then .
, then .
Solution:
Given the equation , left multiply both sides by to obtain  . Thus
. Thus  , that is . This proves (1) and the proof of (2) is left to the reader.
, that is . This proves (1) and the proof of (2) is left to the reader.
Properties (1) and (2) in Example 2.4.7 are described by saying that an invertible matrix can be “left cancelled” and “right cancelled”, respectively. Note however that “mixed” cancellation does not hold in general: If is invertible and  , then and may
, then and may  be equal, even if both are . Here is a specific example:
be equal, even if both are . Here is a specific example:
![\begin{equation*} A = \left[ \begin{array}{rr} 1 & 1 \\ 0 & 1 \end{array} \right],\ B = \left[ \begin{array}{rr} 0 & 0 \\ 1 & 2 \end{array} \right], C = \left[ \begin{array}{rr} 1 & 1 \\ 1 & 1 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-d90a38c8aa8d07e0d4d267775d63148a_l3.png "Rendered by QuickLaTeX.com")
Sometimes the inverse of a matrix is given by a formula. Example 2.4.4 is one illustration; Example 2.4.8 and Example 2.4.9 provide two more. The idea is the  : If a matrix can be found such that , then is invertible and
: If a matrix can be found such that , then is invertible and  .
.
Example 2.4.8
is an invertible matrix, show that the transpose is also invertible. Show further that the inverse of is just the transpose of ; in symbols,  .
.Solution:
exists (by assumption). Its transpose  is the candidate proposed for the inverse of . Using the inverse criterion, we test it as follows:
is the candidate proposed for the inverse of . Using the inverse criterion, we test it as follows:

Hence is indeed the inverse of ; that is, .
Example 2.4.9
and are invertible matrices, show that their product is also invertible and  .
.Solution:
We are given a candidate for the inverse of , namely  . We test it as follows:
. We test it as follows:

Hence is the inverse of ; in symbols, .
We now collect several basic properties of matrix inverses for reference.
Theorem 2.4.4
All the following matrices are square matrices of the same size.
1. is invertible and  .
.
2. If is invertible, so is , and  .
.
3. If and are invertible, so is , and .
4. If  are all invertible, so is their product
are all invertible, so is their product  , and
, and

5. If is invertible, so is  for any
for any  , and
, and  .
.
6. If is invertible and is a number, then  is invertible and
is invertible and  .
.
7. If is invertible, so is its transpose , and .
Proof:
1. This is an immediate consequence of the fact that  .
.
2. The equations  show that is the inverse of ; in symbols, .
show that is the inverse of ; in symbols, .
3. This is Example 2.4.9.
4. Use induction on . If  , there is nothing to prove, and if
, there is nothing to prove, and if  , the result is property 3. If
, the result is property 3. If  , assume inductively that
, assume inductively that  . We apply this fact together with property 3 as follows:
. We apply this fact together with property 3 as follows:
![\begin{align*} \left[ A_{1}A_{2} \cdots A_{k-1}A_{k} \right]^{-1} &= \left[ \left(A_{1}A_{2} \cdots A_{k-1}\right)A_{k} \right]^{-1} \\ &= A_{k}^{-1}\left(A_{1}A_{2} \cdots A_{k-1}\right)^{-1} \\ &= A_{k}^{-1}\left(A_{k-1}^{-1} \cdots A_{2}^{-1}A_{1}^{-1}\right) \end{align*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-dad725397856b469c17d774d7c6b7f23_l3.png "Rendered by QuickLaTeX.com")
So the proof by induction is complete.
5. This is property 4 with  .
.
6. The readers are invited to verify it.
7. This is Example 2.4.8.
The reversal of the order of the inverses in properties 3 and 4 of Theorem 2.4.4 is a consequence of the fact that matrix multiplication is not
commutative. Another manifestation of this comes when matrix equations are dealt with. If a matrix equation is given, it can be  by a matrix to yield . Similarly,
by a matrix to yield . Similarly,  gives . However, we cannot mix the two: If , it need be the case that even if is invertible, for example,
gives . However, we cannot mix the two: If , it need be the case that even if is invertible, for example, ![A = \left[ \begin{array}{rr} 1 & 1 \\ 0 & 1 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-49cfe7121b5e5cfa5d4be9f5e7cecf45_l3.png "Rendered by QuickLaTeX.com") ,
, ![B = \left[ \begin{array}{rr} 0 & 0 \\ 1 & 0 \end{array} \right] = C](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-8e7e417e9a7b47de6b8ab8d74557205c_l3.png "Rendered by QuickLaTeX.com") .
.
Part 7 of Theorem 2.4.4 together with the fact that gives
Corollary 2.4.1
is invertible if and only if is invertible.
Example 2.4.10
if ![(A^{T} - 2I)^{-1} = \left[ \begin{array}{rr} 2 & 1 \\ -1 & 0 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-1271135b960ed263a93075fb822ca7bf_l3.png "Rendered by QuickLaTeX.com") .
.Solution:
By Theorem 2.4.2 (2) and Example 2.4.4, we have
![\begin{equation*} (A^{T} - 2I) = \left[ \left(A^{T} - 2I\right)^{-1} \right]^{-1} = \left[ \begin{array}{rr} 2 & 1 \\ -1 & 0 \end{array} \right]^{-1} = \left[ \begin{array}{rr} 0 & -1 \\ 1 & 2 \end{array} \right] \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-ed219652afc7dcfc5166ba2f99b7e6c3_l3.png "Rendered by QuickLaTeX.com")
Hence ![A^{T} = 2I + \left[ \begin{array}{rr} 0 & -1 \\ 1 & 2 \end{array} \right] = \left[ \begin{array}{rr} 2 & -1 \\ 1 & 4 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-72ba4d972a3e4361e41403b3587fb70c_l3.png "Rendered by QuickLaTeX.com") , so
, so ![A = \left[ \begin{array}{rr} 2 & 1 \\ -1 & 4 \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-b4fddc8d3652977e629f7193f590b440_l3.png "Rendered by QuickLaTeX.com")
by Theorem 2.4.4(7).
The following important theorem collects a number of conditions all equivalent to invertibility. It will be referred to frequently below.
Theorem 2.4.5 Inverse Theorem
The following conditions are equivalent for an matrix :
1. is invertible.
2. The homogeneous system has only the trivial solution  .
.
3. can be carried to the identity matrix by elementary row operations.
4. The system has at least one solution for every choice of column .
5. There exists an matrix such that  .
.
Proof:
We show that each of these conditions implies the next, and that (5) implies (1).
(1)  (2). If exists, then gives
(2). If exists, then gives  .
.
(2) (3). Assume that (2) is true. Certainly  by row operations where is a reduced, row-echelon matrix. It suffices to show that
by row operations where is a reduced, row-echelon matrix. It suffices to show that  . Suppose that this is not the case. Then has a row of zeros (being square). Now consider the augmented matrix
. Suppose that this is not the case. Then has a row of zeros (being square). Now consider the augmented matrix ![\left[ \begin{array}{c|c} A & \vec{0} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-63cc1fb08e66102cf1ef7f4f041d0f6a_l3.png "Rendered by QuickLaTeX.com") of the system . Then
of the system . Then ![\left[ \begin{array}{c|c} A & \vec{0} \end{array} \right] \to \left[ \begin{array}{c|c} R & \vec{0} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-2241d05c11ed167f00f88b3186f1a9ef_l3.png "Rendered by QuickLaTeX.com") is the reduced form, and
is the reduced form, and ![\left[ \begin{array}{c|c} R & \vec{0} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e7ba0c4c443bdce73c5c2333b747f827_l3.png "Rendered by QuickLaTeX.com") also has a row of zeros. Since is square there must be at least one nonleading variable, and hence at least one parameter. Hence the system has infinitely many solutions, contrary to (2). So after all.
also has a row of zeros. Since is square there must be at least one nonleading variable, and hence at least one parameter. Hence the system has infinitely many solutions, contrary to (2). So after all.
(3) (4). Consider the augmented matrix ![\left[ \begin{array}{c|c} A & \vec{b} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f5985d0e61423b86fe7cff7d60e70a68_l3.png "Rendered by QuickLaTeX.com") of the system . Using (3), let
of the system . Using (3), let  by a sequence of row operations. Then these same operations carry
by a sequence of row operations. Then these same operations carry ![\left[ \begin{array}{c|c} A & \vec{b} \end{array} \right] \to \left[ \begin{array}{c|c} I_{n} & \vec{c} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-19a05d963c2c0dbef578ec0a56cfb972_l3.png "Rendered by QuickLaTeX.com") for some column
for some column  . Hence the system has a solution (in fact unique) by gaussian elimination. This proves (4).
. Hence the system has a solution (in fact unique) by gaussian elimination. This proves (4).
(4) (5). Write ![I_{n} = \left[ \begin{array}{cccc} \vec{e}_{1} & \vec{e}_{2} & \cdots & \vec{e}_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-021ad34ffa573a47e070324ded15105c_l3.png "Rendered by QuickLaTeX.com") where
where  are the columns of . For each \newline , the system
are the columns of . For each \newline , the system  has a solution
has a solution  by (4), so
by (4), so  . Now let
. Now let ![C = \left[ \begin{array}{cccc} \vec{c}_{1} & \vec{c}_{2} & \cdots & \vec{c}_{n} \end{array} \right]](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e059e1ff3eeba3f5f50b072875ffbe38_l3.png "Rendered by QuickLaTeX.com") be the matrix with these matrices as its columns. Then Definition 2.9 gives (5):
be the matrix with these matrices as its columns. Then Definition 2.9 gives (5):
![\begin{equation*} AC = A \left[ \begin{array}{cccc} \vec{c}_{1} & \vec{c}_{2} & \cdots & \vec{c}_{n} \end{array} \right] = \left[ \begin{array}{cccc} A\vec{c}_{1} & A\vec{c}_{2} & \cdots & A\vec{c}_{n} \end{array} \right] = \left[ \begin{array}{cccc} \vec{e}_{1} & \vec{e}_{2} & \cdots & \vec{e}_{n} \end{array} \right] = I_{n} \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f0da845fc37443d04d83972a341a6098_l3.png "Rendered by QuickLaTeX.com")
(5) (1). Assume that (5) is true so that for some matrix . Then  implies
implies  (because
(because  ). Thus condition (2) holds for the matrix rather than . Hence the argument above that (2) (3) (4) (5) (with replaced by ) shows that a matrix
). Thus condition (2) holds for the matrix rather than . Hence the argument above that (2) (3) (4) (5) (with replaced by ) shows that a matrix  exists such that
exists such that  . But then
. But then

Thus  which, together with , shows that is the inverse of . This proves (1).
which, together with , shows that is the inverse of . This proves (1).
The proof of (5) (1) in Theorem 2.4.5 shows that if  for square matrices, then necessarily
for square matrices, then necessarily  , and hence that and are inverses of each other. We record this important fact for reference.
, and hence that and are inverses of each other. We record this important fact for reference.
Corollary 2.4.1
and are square matrices such that , then also . In particular, both and are invertible,  , and
, and  .
.
Here is a quick way to remember Corollary 2.4.1. If is a square matrix, then
1. If  then
then  .
.
2. If  then .
then .
Observe that Corollary 2.4.1 is false if and are not square matrices. For example, we have
![\begin{equation*} \left[ \begin{array}{rrr} 1 & 2 & 1 \\ 1 & 1 & 1 \end{array} \right] \left[ \begin{array}{rr} -1 & 1 \\ 1 & -1 \\ 0 & 1 \end{array} \right] = I_{2} \quad \mbox{ but } \left[ \begin{array}{rr} -1 & 1 \\ 1 & -1 \\ 0 & 1 \end{array} \right] \left[ \begin{array}{rrr} 1 & 2 & 1 \\ 1 & 1 & 1 \end{array} \right] \neq I_{3} \end{equation*}](https://ecampusontario.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-1609874c4259626ab7f7448cf0e12644_l3.png "Rendered by QuickLaTeX.com")
In fact, it can be verified that if and , where is and is , then and and are (square) inverses of each other.
An matrix has  if and only if (3) of Theorem 2.4.5 holds. Hence
if and only if (3) of Theorem 2.4.5 holds. Hence
Corollary 2.4.2
matrix is invertible if and only if  .
.
