How do you work through the data curation management process?
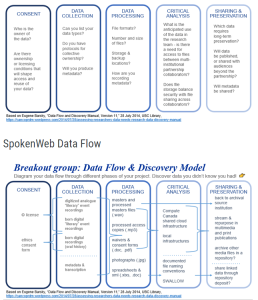 The Data Flow and Discovery Model (see the annex for an example worksheet) is a way of representing the flow of your data through digital humanities methodologies; it gathers information about the material and immaterial inputs and outputs of each entity and the process itself. Specific operations performed on the research material and data can be represented by a flowchart.
The Data Flow and Discovery Model (see the annex for an example worksheet) is a way of representing the flow of your data through digital humanities methodologies; it gathers information about the material and immaterial inputs and outputs of each entity and the process itself. Specific operations performed on the research material and data can be represented by a flowchart.
Although a flowchart suggests progress in one direction, the steps are interrelated. Consideration of final storage, for instance, may impact the earliest stages of data collecting. Likewise, you will notice that some of the crucial choices you make in how you organize and store your files have an impact on your ability to transform your data into scholarly or creative work, or your ability to govern conditional access.
The following section delves deeper into how to use a Data Flow and Discovery Model, section by section. Remember that even if this Primer calls for a linear representation of the model, it’s important to note that it is an iterative, sometimes repetitive, process. In many instances, some steps will have to be reviewed or skipped over and looked at in a different moment in time, depending on your project data, goals, and progress. Sometimes the most important outcome of this modeling is noting “further questions”, if there are steps in data curation management where you don’t know what to do.
