Copyright and (Open) Licenses
Copyright protects original expressions of content that are fixed in a tangible medium (either physical or digital) – note that there are some differences between various national copyright regimes, and in most cases the law applies in the national space where the expression is created. We recommend following up with your own institutional library or copyright office for specific questions about licensing.
Data could be protected by copyright if there was judgment or skill applied in the choice of data to include or its arrangement (raw data is not intellectual property, it is facts in public domain). External factors to your research team or project may determine if data is protected by copyright and who owns it. It is advisable to document data and copyright ownership in the early stages of a project.
A licence is a permission provided by the copyright owner allowing someone else to use their work for certain purposes and under certain conditions. The copyright remains with the copyright owner. Open licences are used by copyright owners to indicate which rights they wish to keep, while communicating which types of use others can make of their work, without having to ask for permission every time.
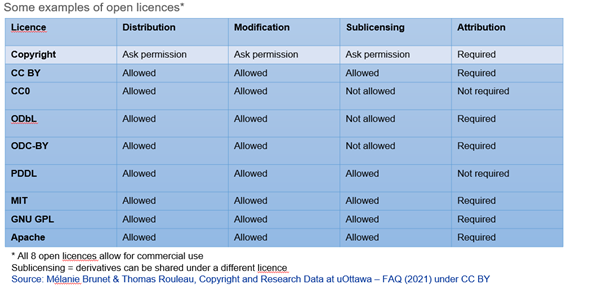
The above table shows us, from the point of view of a researcher who wishes to reuse content that is not under their ownership, how copyright compares to popular open licenses for data sharing or for sharing software or code. You may apply different licenses to the published research, writing, data, and the code outputs of your research. Note that, because the particular mechanics of code and data reuse differ from the way “creative works” (including academic writing) are reused or re-published, it is often recommended to use code and data-specific open licenses, instead of applying the same creative commons license that you may use for the creative output of the project (Creative Commons).
When planning for your own publication outputs, you want to make distinctions between open licensing and licensing that limits use. For example, you probably want to keep copyright on your research articles, and you want to be sure that you respect the copyright and licensing agreements with people whose intellectual or creative content you are sharing through various knowledge mobilization activities; however, you may want to put an open data licence on your metadata export.
Research material and research data is always situated from the perspective of the researcher. If you are working in research-creation and your outputs are artistic or cultural expressions that have value beyond academia, you may want to consider that your “research data,” as it is produced, circulated, cited and reused in an academic economy, is nonetheless creative work that belongs to you. Perhaps it should remain in copyright and not be shared through data publishing platforms. Or, you could consider your own art as possible potential research material for future researchers and artists. , It could be advantageous for you and the research community to take time to learn how to consciously use open licences and data repositories as parallel self-publishing and self-archiving systems that allow you to share your artistic expression on your own terms.
First Nations, Métis and Inuit laws on intellectual property including cultural expression and traditional knowledge, may be different from national and international copyright and intellectual property law. Note, for example, that the Canadian Copyright Act awards copyright in stories, songs, poetry, etc., to the first person to record them—that is, capture them in print or audio recordings. This has allowed traditional stories or songs to be ‘owned’ by researchers, rather than the Indigenous peoples who created them. This law does not respect the oral traditions of many Indigenous peoples in Canada. When working with data with Indigenous ownership, it is essential to inform yourself about Indigenous laws and their implications to your work. Each context of engagement will be different and shaped by distinct protocols of First Nations, Inuit, and Métis communities.
 In the SpokenWeb partnership, common standards that enable data sharing among the partnership and eventually, to the public include
In the SpokenWeb partnership, common standards that enable data sharing among the partnership and eventually, to the public include
- a shared ethics protocol with informed consent that permits data sharing to the public, and
- a shared digitization waiver for historical audio artefacts.
The primary site PI (Jason Camlot) sets a standard that other partner site PIs then follow. An Ethics protocol form for oral history interviews was submitted through Concordia University. Once this protocol form was accepted by the Concordia University Human Research Ethics Committee, it could then be adjusted to fit the requirements of the partnership site REBs and submitted for expedited review.
This means that the privacy and confidentiality restrictions on the use and sharing of these interviews are standardized across the partnership. These restrictions are set according to the interviewees choices made on the Consent Form. These interviews are “data” that have specific attributes regulating sharing. The principles of these ethics protocols for oral history interviews are also applied to public events held by the SpokenWeb partnership. For example, Symposium attendees fill out a permissions and waiver form for recordings and future publications of their sessions.
➔Data Flow Model: Data Collection
Researcher questions:
If I am working with an anti-oppression framework or decolonial methodologies, should I use an existing database or descriptive system or invent a new one? What standards exist already? What are the labour, resources, relationships needed to adapt it? Is my process of adaptation or imagining new modes of description part of my data? Do I need to capture it, and if so, which parts of the process?
? ? ? ! *
Data Flow model questions that help you think through this complexity:
- Can you list your data types? What files will need metadata?
- Do you have protocols for collective ownership?
Start by thinking about all the different formats and types of data you will gather and create during your research project. Also think about where they reside and how they are used in the project. Ensure to organize them and to be consistent in your collecting processes and in your descriptive standards. Create an inventory of your data types and what file formats they are stored in. This step will also help you choose what is within or out of scope in terms of processing, preservation, and sharing.
As you organize your data and files, decide on naming conventions, and start to think about how to structure folders and files. Naming conventions (i.e., using a consistent and descriptive way to name your files) are important to easily locate the right files and to help with version control. This can seem tedious initially, but the frustration of opening a series of different files to try to find the correct document or version can be avoided by following simple guidelines. To structure your files, use folders (that also adhere to a naming convention!), be precise in what goes in each folder, and organize them hierarchically (from broader topic to more specific, i.e., Administration> Communications > Emails > Emails from Felicity). If the data is being returned or provided back to a First Nations, Métis or Inuit community, this structure should also be built in a way that reflects their needs and priorities, and is accessible to them and meets their capacity.
Plan your data collection with consideration of the contribution that the newly collected data may or may not make to existing data resources. Whether this contribution happens at the same time that you collect your data or later on in the project, this plan to merge your data with a pre-existing system will impact how you gather and record your data.
Best practices for managing your data include making a distinction between:
- Your administrative data (RA contracts, project management files, budgets, etc.) and your research data
- Your research materials and your research data
- Your platforms, software, code, and other resources developed to share or visualize your research
- The content of the data and the file format in which the data is stored (for example, it is possible to store texts in spreadsheets or databases in addition to storing texts in word documents).
The technical details of how you will plan and carry out your data collection for your specific research project are beyond the scope of this guide. It will be up to you to define and find the resources to support your specific technical requirements. However, once you’ve figured out your data collection plan, file structure, and naming conventions, it’s time to get started on adding context to your data to ensure others understand it. That’s where metadata comes in handy.
Metadata is the data that provides information about the data. Metadata is the best way to describe your data and to point back to the original sources; at this point, it’s a good idea to start thinking about the metadata that will be needed for your project files.
Do you remember when we made the distinction between research material and research data in the first section? In that case, the descriptions of the recording, and lots of the SpokenWeb partnership research data is actually metadata.
SpokenWeb began by researching and adopting existing metadata schemas for literary collections and audio file descriptions. This saved time, and also ensured that the data they produced could be imported into other existing systems, such as library catalogues and Wikidata. It also meant they could import or borrow metadata from existing systems. But the SpokenWeb teams also noted limitations that these schemas had, and built the necessary technical skills and labour into their project methodology in order to develop custom Metadata and Cataloguing conventions for analog audio artefacts. All audio artefacts are being described in a metadata ingest system affectionately named SWALLOW – alluding to the songbird of Romantic poetry and to the “swallowing” or ingesting of the data — this means that all collaborators in the partnership can search each other’s audio collections. Also, SpokenWeb Research Assistants are all trained in metadata entry and represent the majority of labour deployed in this contribution to the scholarly project.
Use metadata to describe your data by type, use, title, source, etc. for different audiences; it is also a way to track licensing, and conditions of consent. Metadata must be machine readable for computational searches, but also descriptive for humans (i.e., other researchers, collaborators, etc.) to allow them to find the data efficiently. Metadata can also be used to describe your methods. The methodology of your project is also data, and necessary information for collaborators, partners, and future researchers to cite, use or reuse your project.
Some disciplinary communities already have established metadata schemas (many can be found at the Metadata Standards Catalog), it is a good practice to start from there. By using an already existing schema, you can focus on modifying or expanding it to suit your needs, values, and questions. You then also contribute to the larger community’s data potential, and this practice does fit into the FAIR principles of findability, accessibility, interoperability, and reusability. Catalogues of metadata schemas can be helpful, or you can consult your librarian and other institutional metadata specialist.
At a minimum, create a README file that explains the choices you have made in this metadata description, and it should also describe the file structures to facilitate the understanding of the collection or decisions and observations, so that your collection can be reusable. Each data type, or file may have several different types of metadata:
- Administrative (chains of commands, logs, manifests)
- Technical (properties, characteristics of file)
- Descriptive (summaries, annotations, context, key terms)
- Preservation (condition and quality of file for example), and
- Consent and permission focus.
You can treat the writing of metadata in different ways; if you have access to the technical skill or knowledge, you can adapt or build a cataloguing system for this metadata that will allow for sophisticated data imports, exports, linking to sources, and searching that goes beyond a spreadsheet; but at its simplest expression, you can also treat the metadata as if you were writing a text. Metadata can be viewed as an encoded narrative that tells the story about your data. The metadata can function as a layer of description that guides the interpretation of your project. Adding metadata can be as simple or as complicated as you wish it to be; the important thing to remember is to describe your data so that others can collaborate more effectively with you, reuse your data or repeat your methodology. If you find the previously created directory does not suit your work, you can see if there are ways to add fields to correct it or to acknowledge a reality that wasn’t considered previously. In any case, it’s always best to try to reuse than to start from scratch.
The SpokenWeb partnership has had conversations with Cree-Métis literary critic, Deanna Reder, about Indigenous research methods and protocols for literary scholars. Reder and the team members of The People and the Text (TPatT) rely on the First Nations Principles of OCAP®: ownership, control, access, possession (in Health, it is the 4 R’s: respect, reciprocity, relevance, and responsibility) as well as nation or tribal-specific protocols. TPatT is inspired by work by Indigenous scholars and creatives such as Skawennati, Jason Lewis, Elizabeth LaPensee, and Maize Longboat, and benefits from the support and infrastructure of CWRC (Canadian Writing Research Collaboratory).