2 Managing Information and Technology

Learning Objectives
Define what an information system is by identifying its main components.
Describe the basic history of information systems.
Describe the role information systems play in an organization.
Describe the two primary categories of software.
Describe how ERP software plays in an organization.
Introduction
This chapter is written as an introductory text, meant for those with little or no experience with computers or information systems. While sometimes the descriptions can get a little bit technical, every effort has been made to convey the information essential to understanding a topic while not getting bogged down in detailed terminology or esoteric discussions.
Defining Information Systems
 Almost all programs in business require students to take a course in something called information systems. But what exactly does that term mean? Let’s take a look at some of the more popular definitions, first from Wikipedia and then from a couple of textbooks:
Almost all programs in business require students to take a course in something called information systems. But what exactly does that term mean? Let’s take a look at some of the more popular definitions, first from Wikipedia and then from a couple of textbooks:
- “Information systems (IS) is the study of complementary networks of hardware and software that people and organizations use to collect, filter, process, create, and distribute data.”
- “Information systems are combinations of hardware, software, and telecommunications networks that people build and use to collect, create, and distribute useful data, typically in organizational settings.”
- “Information systems are interrelated components working together to collect, process, store, and disseminate information to support decision making, coordination, control, analysis, and visualization in an organization.”
As you can see, these definitions focus on two different ways of describing information systems: the components that make up an information system and the role that those components play in an organization. Let’s take a look at each of these.
The Components of Information Systems
The first way we describe information systems to students is to tell them that they are made up of five components: hardware, software, data, people, and process. The first three, fitting under the category technology, are generally what most students think of when asked to define information systems. But the last two, people and process, are really what separate the idea of information systems from more technical fields, such as computer science. In order to fully understand information systems, students must understand how all of these components work together to bring value to an organization.
Technology
Technology can be thought of as the application of scientific knowledge for practical purposes. From the invention of the wheel to the harnessing of electricity for artificial lighting, technology is a part of our lives in so many ways that we tend to take it for granted. As discussed before, the first three components of information systems – hardware, software, and data – all fall under the category of technology.
Hardware
Information systems hardware is the part of an information system you can touch – the physical components of the technology. Computers, keyboards, disk drives, iPads, and flash drives are all examples of information systems hardware.
Software
Software is a set of instructions that tells the hardware what to do. Software is not tangible – it cannot be touched. When programmers create software programs, what they are really doing is simply typing out lists of instructions that tell the hardware what to do. There are several categories of software, with the two main categories being operating-system software, which makes the hardware usable, and application software, which does something useful. Examples of operating systems include Microsoft Windows on a personal computer and Google’s Android on a mobile phone. Examples of application software are Microsoft Excel and Angry Birds.
Data
The third component is data. You can think of data as a collection of facts. For example, your street address, the city you live in, and your phone number are all pieces of data. Like software, data is also intangible. By themselves, pieces of data are not really very useful. But aggregated, indexed, and organized together into a database, data can become a powerful tool for businesses. In fact, all of the definitions presented at the beginning of this chapter focused on how information systems manage data. Organizations collect all kinds of data and use it to make decisions. These decisions can then be analyzed as to their effectiveness and the organization can be improved.
Networking Communication
Besides the components of hardware, software, and data, which have long been considered the core technology of information systems, it has been suggested that one other component should be added: communication. An information system can exist without the ability to communicate – the first personal computers were stand-alone machines that did not access the Internet. However, in today’s hyper-connected world, it is an extremely rare computer that does not connect to another device or to a network. Technically, the networking communication component is made up of hardware and software, but it is such a core feature of today’s information systems that it has become its own category.
People
When thinking about information systems, it is easy to get focused on the technology components and forget that we must look beyond these tools to fully understand how they integrate into an organization. A focus on the people involved in information systems is the next step. From the front-line help-desk workers, to systems analysts, to programmers, all the way up to the chief information officer (CIO), the people involved with information systems are an essential element that must not be overlooked.
Process
The last component of information systems is process. A process is a series of steps undertaken to achieve a desired outcome or goal. Information systems are becoming more and more integrated with organizational processes, bringing more productivity and better control to those processes. But simply automating activities using technology is not enough – businesses looking to effectively utilize information systems do more. Using technology to manage and improve processes, both within a company and externally with suppliers and customers, is the ultimate goal. Technology buzzwords such as “business process reengineering,” “business process management,” and “enterprise resource planning” all have to do with the continued improvement of these business procedures and the integration of technology with them. Businesses hoping to gain an advantage over their competitors are highly focused on this component of information systems.
The Role of Information Systems
Now that we have explored the different components of information systems, we need to turn our attention to the role that information systems play in an organization. So far we have looked at what the components of an information system are, but what do these components actually do for an organization? From our definitions above, we see that these components collect, store, organize, and distribute data throughout the organization. In fact, we might say that one of the roles of information systems is to take data and turn it into information, and then transform that into organizational knowledge. As technology has developed, this role has evolved into the backbone of the organization. To get a full appreciation of the role information systems play, we will review how they have changed over the years.
The Mainframe Era
From the late 1950s through the 1960s, computers were seen as a way to more efficiently do calculations. These first business computers were room-sized monsters, with several refrigerator-sized machines linked together. The primary work of these devices was to organize and store large volumes of information that were tedious to manage by hand. Only large businesses, universities, and government agencies could afford them, and they took a crew of specialized personnel and specialized facilities to maintain. These devices served dozens to hundreds of users at a time through a process called time-sharing. Typical functions included scientific calculations and accounting, under the broader umbrella of “data processing.”
In the late 1960s, the Manufacturing Resources Planning (MRP) systems were introduced. This software, running on a mainframe computer, gave companies the ability to manage the manufacturing process, making it more efficient. From tracking inventory to creating bills of materials to scheduling production, the MRP systems (and later the MRP II systems) gave more businesses a reason to want to integrate computing into their processes.
Example
The PC Revolution
In 1975, the first microcomputer was announced on the cover of Popular Mechanics: the Altair 8800. Its immediate popularity sparked the imagination of entrepreneurs everywhere, and there were quickly dozens of companies making these “personal computers.” Though at first just a niche product for computer hobbyists, improvements in usability and the availability of practical software led to growing sales. The most prominent of these early personal computer makers was a little company known as Apple Computer, headed by Steve Jobs and Steve Wozniak, with the hugely successful “Apple II.” Not wanting to be left out of the revolution, in 1981 IBM (teaming with a little company called Microsoft for their operating system software) hurriedly released their own version of the personal computer, simply called the “PC.” Businesses, who had used IBM mainframes for years to run their businesses, finally had the permission they needed to bring personal computers into their companies, and the IBM PC took off. The IBM PC was named Time magazine’s “Man of the Year” for 1982.
Because of the IBM PC’s open architecture, it was easy for other companies to copy, or “clone” it. During the 1980s, many new computer companies sprang up, offering less expensive versions of the PC. This drove prices down and spurred innovation. Microsoft developed its Windows operating system and made the PC even easier to use. Common uses for the PC during this period included word processing, spreadsheets, and databases. These early PCs were not connected to any sort of network; for the most part they stood alone as islands of innovation within the larger organization.
Client-Server
In the mid-1980s, businesses began to see the need to connect their computers together as a way to collaborate and share resources. This networking architecture was referred to as “client-server” because users would log in to the local area network (LAN) from their PC (the “client”) by connecting to a powerful computer called a “server,” which would then grant them rights to different resources on the network (such as shared file areas and a printer). Software companies began developing applications that allowed multiple users to access the same data at the same time. This evolved into software applications for communicating, with the first real popular use of electronic mail appearing at this time.
This networking and data sharing all stayed within the confines of each business, for the most part. While there was sharing of electronic data between companies, this was a very specialized function. Computers were now seen as tools to collaborate internally, within an organization. In fact, these networks of computers were becoming so powerful that they were replacing many of the functions previously performed by the larger mainframe computers at a fraction of the cost. It was during this era that the first Enterprise Resource Planning (ERP) systems were developed and run on the client-server architecture. An ERP system is a software application with a centralized database that can be used to run a company’s entire business. With separate modules for accounting, finance, inventory, human resources, and many, many more, ERP systems, with Germany’s SAP leading the way, represented the state of the art in information systems integration.
Example
Walmart Uses Information Systems to Become the World’s Leading Retailer
Walmart is the world’s largest retailer, earning $15.2 billion on sales of $443.9 billion in the fiscal year that ended on January 31, 2012. Walmart currently serves over 200 million customers every week, worldwide.5 Walmart’s rise to prominence is due in no small part to their use of information systems. One of the keys to this success was the implementation of Retail Link, a supply-chain management system. This system, unique when initially implemented in the mid-1980s, allowed Walmart’s suppliers to directly access the inventory levels and sales information of their products at any of Walmart’s more than ten thousand stores. Using Retail Link, suppliers can analyze how well their products are selling at one or more Walmart stores, with a range of reporting options. Further, Walmart requires the suppliers to use Retail Link to manage their own inventory levels. If a supplier feels that their products are selling out too quickly, they can use Retail Link to petition Walmart to raise the levels of inventory for their products. This has essentially allowed Walmart to “hire” thousands of product managers, all of whom have a vested interest in the products they are managing. This revolutionary approach to managing inventory has allowed Walmart to continue to drive prices down and respond to market forces quickly. Today, Walmart continues to innovate with information technology. Using its tremendous market presence, any technology that Walmart requires its suppliers to implement immediately becomes a business standard.
Data, Information, and Knowledge
Data are the raw bits and pieces of information with no context. If I told you, “15, 23, 14, 85,” you would not have learned anything. But I would have given you data. Data can be quantitative or qualitative. Quantitative data is numeric, the result of a measurement, count, or some other mathematical calculation. Qualitative data is descriptive. “Ruby Red,” the color of a 2013 Ford Focus, is an example of qualitative data. A number can be qualitative too: if I tell you my favorite number is 5, that is qualitative data because it is descriptive, not the result of a measurement or mathematical calculation.
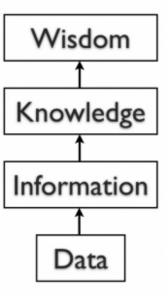
By itself, data is not that useful. To be useful, it needs to be given context. Returning to the example above, if I told you that “15, 23, 14, and 85″ are the numbers of students that had registered for upcoming classes, that would be information. By adding the context – that the numbers represent the count of students registering for specific classes – I have converted data into information. Once we have put our data into context, aggregated and analyzed it, we can use it to make decisions for our organization. We can say that this consumption of information produces knowledge. This knowledge can be used to make decisions, set policies, and even spark innovation. The final step up the information ladder is the step from knowledge (knowing a lot about a topic) to wisdom. We can say that someone has wisdom when they can combine their knowledge and experience to produce a deeper understanding of a topic. It often takes many years to develop wisdom on a particular topic, and requires patience.
Examples of Data
 Almost all software programs require data to do anything useful. For example, if you are editing a document in a word processor such as Microsoft Word, the document you are working on is the data. The wordprocessing software can manipulate the data: create a new document, duplicate a document, or modify a document. Some other examples of data are: an MP3 music file, a video file, a spreadsheet, a web page, and an e-book. In some cases, such as with an e-book, you may only have the ability to read the data.
Almost all software programs require data to do anything useful. For example, if you are editing a document in a word processor such as Microsoft Word, the document you are working on is the data. The wordprocessing software can manipulate the data: create a new document, duplicate a document, or modify a document. Some other examples of data are: an MP3 music file, a video file, a spreadsheet, a web page, and an e-book. In some cases, such as with an e-book, you may only have the ability to read the data.
Databases
The goal of many information systems is to transform data into information in order to generate knowledge that can be used for decision making. In order to do this, the system must be able to take data, put the data into context, and provide tools for aggregation and analysis. A database is designed for just such a purpose. A database is an organized collection of related information. It is an organized collection, because in a database, all data is described and associated with other data. All information in a database should be related as well; separate databases should be created to manage unrelated information. For example, a database that contains information about students should not also hold information about company stock prices. Databases are not always digital – a filing cabinet, for instance, might be considered a form of database. For the purposes of this text, we will only consider digital databases.
Relational Databases
Databases can be organized in many different ways, and thus take many forms. The most popular form of database today is the relational database. Popular examples of relational databases are Microsoft Access, MySQL, and Oracle. A relational database is one in which data is organized into one or more tables. Each table has a set of fields, which define the nature of the data stored in the table. A record is one instance of a set of fields in a table. To visualize this, think of the records as the rows of the table and the fields as the columns of the table. In the example below, we have a table of student information, with each row representing a student and each column representing one piece of information about the student.
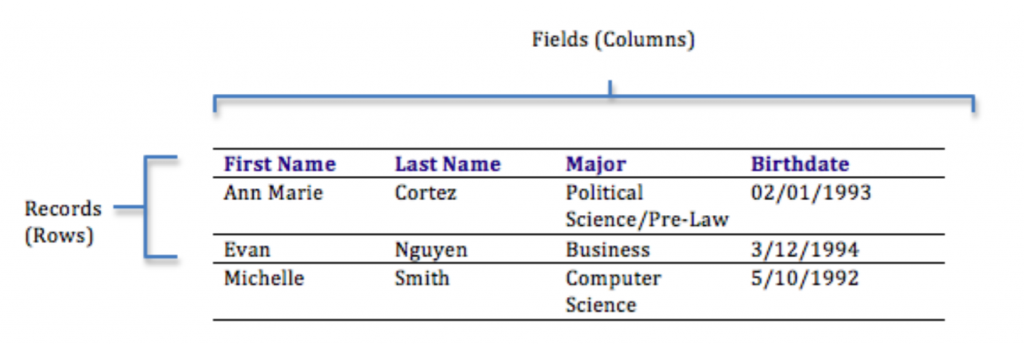
Rows and columns in a table
In a relational database, all the tables are related by one or more fields, so that it is possible to connect all the tables in the database through the field(s) they have in common. For each table, one of the fields is identified as a primary key. This key is the unique identifier for each record in the table. To help you understand these terms further, let’s walk through the process of designing a database.
Example
Designing a Database
Suppose a university wants to create an information system to track participation in student clubs. After interviewing several people, the design team learns that the goal of implementing the system is to give better insight into how the university funds clubs. This will be accomplished by tracking how many members each club has and how active the clubs are. From this, the team decides that the system must keep track of the clubs, their members, and their events. Using this information, the design team determines that the following tables need to be created:
- Clubs: this will track the club name, the club president, and a short description of the club.
- Students: student name, e-mail, and year of birth.
- Memberships: this table will correlate students with clubs, allowing us to have any given student join multiple clubs.
- Events: this table will track when the clubs meet and how many students showed up.
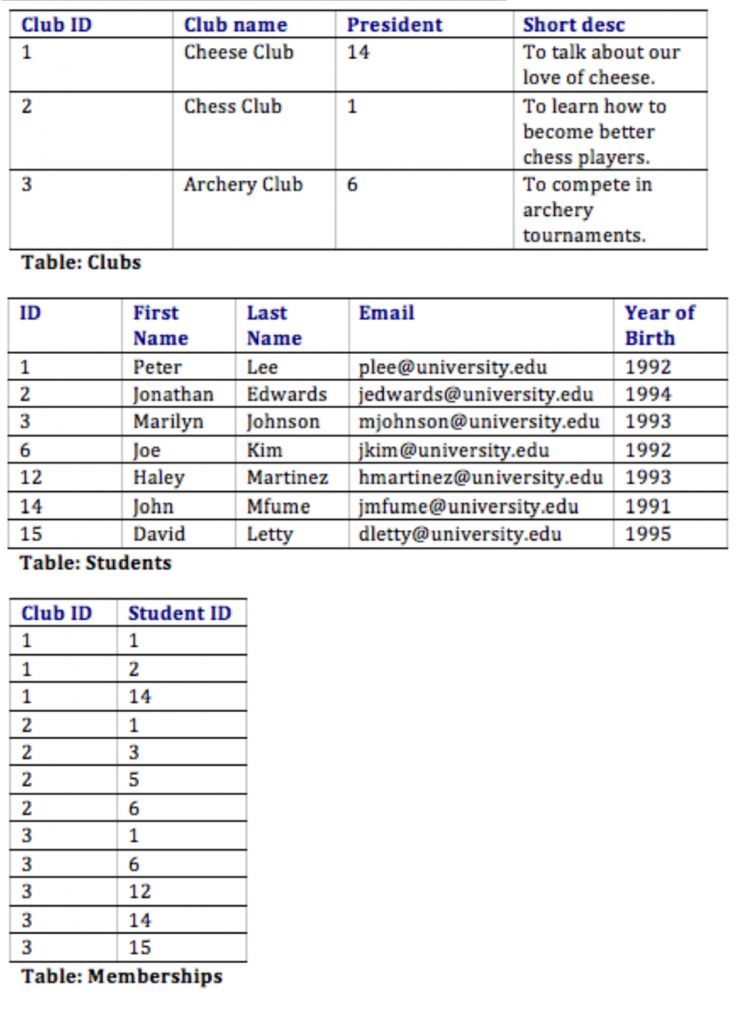 Now that the design team has determined which tables to create, they need to define the specific information that each table will hold. This requires identifying the fields that will be in each table. For example, Club Name would be one of the fields in the Clubs table. First Name and Last Name would be fields in the Students table. Finally, since this will be a relational database, every table should have a field in common with at least one other table (in other words: they should have a relationship with each other).
Now that the design team has determined which tables to create, they need to define the specific information that each table will hold. This requires identifying the fields that will be in each table. For example, Club Name would be one of the fields in the Clubs table. First Name and Last Name would be fields in the Students table. Finally, since this will be a relational database, every table should have a field in common with at least one other table (in other words: they should have a relationship with each other).
In order to properly create this relationship, a primary key must be selected for each table. This key is a unique identifier for each record in the table. For example, in the Students table, it might be possible to use students’ last name as a way to uniquely identify them. However, it is more than likely that some students will share a last name (like Rodriguez, Smith, or Lee), so a different field should be selected. A student’s e-mail address might be a good choice for a primary key, since e-mail addresses are unique. However, a primary key cannot change, so this would mean that if students changed their e-mail address we would have to remove them from the database and then re-insert them – not an attractive proposition. Our solution is to create a value for each student — a user ID — that will act as a primary key. We will also do this for each of the student clubs. This solution is quite common and is the reason you have so many user IDs!
With this design, not only do we have a way to organize all of the information we need to meet the requirements, but we have also successfully related all the tables together. Here’s what the database tables might look like with some sample data. Note that the Memberships table has the sole purpose of allowing us to relate multiple students to multiple clubs.
Normalization
When designing a database, one important concept to understand is normalization. In simple terms, to normalize a database means to design it in a way that: 1) reduces duplication of data between tables and 2) gives the table as much flexibility as possible. In the Student Clubs database design, the design team worked to achieve these objectives. For example, to track memberships, a simple solution might have been to create a Members field in the Clubs table and then just list the names of all of the members there. However, this design would mean that if a student joined two clubs, then his or her information would have to be entered a second time. Instead, the designers solved this problem by using two tables: Students and Memberships. In this design, when a student joins their first club, we first must add the student to the Students table, where their first name, last name, e-mail address, and birth year are entered. This addition to the Students table will generate a student ID. Now we will add a new entry to denote that the student is a member of a specific club. This is accomplished by adding a record with the student ID and the club ID in the Memberships table. If this student joins a second club, we do not have to duplicate the entry of the student’s name, e-mail, and birth year; instead, we only need to make another entry in the Memberships table of the second club’s ID and the student’s ID. The design of the Student Clubs database also makes it simple to change the design without major modifications to the existing structure. For example, if the design team were asked to add functionality to the system to track faculty advisors to the clubs, we could easily accomplish this by adding a Faculty Advisors table (similar to the Students table) and then adding a new field to the Clubs table to hold the Faculty Advisor ID.
Data Types
When defining the fields in a database table, we must give each field a data type. For example, the field Birth Year is a year, so it will be a number, while First Name will be text. Most modern databases allow for several different data types to be stored. Some of the more common data types are listed here:
- Text: for storing non-numeric data that is brief, generally under 256 characters. The database designer can identify the maximum length of the text.
- Number: for storing numbers. There are usually a few different number types that can be selected, depending on how large the largest number will be.
- Yes/No: a special form of the number data type that is (usually) one byte long, with a 0 for “No” or “False” and a 1 for “Yes” or “True”.
- Date/Time: a special form of the number data type that can be interpreted as a number or a time.
- Currency: a special form of the number data type that formats all values with a currency indicator and two decimal places.
- Paragraph Text: this data type allows for text longer than 256 characters.
- Object: this data type allows for the storage of data that cannot be entered via keyboard, such as an image or a music file.
There are two important reasons that we must properly define the data type of a field. First, a data type tells the database what functions can be performed with the data. For example, if we wish to perform mathematical functions with one of the fields, we must be sure to tell the database that the field is a number data type. So if we have, say, a field storing birth year, we can subtract the number stored in that field from the current year to get age.
The second important reason to define data type is so that the proper amount of storage space is allocated for our data. For example, if the First Name field is defined as a text(50) data type, this means fifty characters are allocated for each first name we want to store. However, even if the first name is only five characters long, fifty characters (bytes) will be allocated. While this may not seem like a big deal, if our table ends up holding 50,000 names, we are allocating 50 * 50,000 = 2,500,000 bytes for storage of these values. It may be prudent to reduce the size of the field so we do not waste storage space.
Database Management Systems
To the computer, a database looks like one or more files. In order for the data in the database to be read, changed, added, or removed, a software program must access it. Many software applications have this ability: iTunes can read its database to give you a listing of its songs (and play the songs); your mobile-phone software can interact with your list of contacts. But what about applications to create or manage a database? What software can you use to create a database, change a database’s structure, or simply do analysis? That is the purpose of a category of software applications called database management systems (DBMS).
DBMS packages generally provide an interface to view and change the design of the database, create queries, and develop reports. Most of these packages are designed to work with a specific type of database, but generally are compatible with a wide range of databases.
For example, Apache OpenOffice.org Base (see screen shot) can be used to create, modify, and analyze databases in open-database (ODB) format. Microsoft’s Access DBMS is used to work with databases in its own Microsoft Access Database format. Both Access and Base have the ability to read and write to other database formats as well.
Microsoft Access and Open Office Base are examples of personal database-management systems. These systems are primarily used to develop and analyze single-user databases. These databases are not meant to be shared across a network or the Internet, but are instead installed on a particular device and work with a single user at a time.
Enterprise Databases
A database that can only be used by a single user at a time is not going to meet the needs of most organizations. As computers have become networked and are now joined worldwide via the Internet, a class of database has emerged that can be accessed by two, ten, or even a million people. These databases are sometimes installed on a single computer to be accessed by a group of people at a single location. Other times, they are installed over several servers worldwide, meant to be accessed by millions. These relational enterprise database packages are built and supported by companies such as Oracle, Microsoft, and IBM. The open-source MySQL is also an enterprise database.
As stated earlier, the relational database model does not scale well. The term scale here refers to a database getting larger and larger, being distributed on a larger number of computers connected via a network. Some companies are looking to provide large-scale database solutions by moving away from the relational model to other, more flexible models. For example, Google now offers the App Engine Datastore, which is based on NoSQL. Developers can use the App Engine Datastore to develop applications that access data from anywhere in the world. Amazon.com offers several database services for enterprise use, including Amazon RDS, which is a relational database service, and Amazon DynamoDB, a NoSQL enterprise solution.
Data Warehouse
As organizations have begun to utilize databases as the centerpiece of their operations, the need to fully understand and leverage the data they are collecting has become more and more apparent. However, directly analyzing the data that is needed for day-to-day operations is not a good idea; we do not want to tax the operations of the company more than we need to. Further, organizations also want to analyze data in a historical sense: How does the data we have today compare with the same set of data this time last month, or last year? From these needs arose the concept of the data warehouse. The concept of the data warehouse is simple: extract data from one or more of the organization’s databases and load it into the data warehouse (which is itself another database) for storage and analysis. However, the execution of this concept is not that simple. A data warehouse should be designed so that it meets the following criteria:
- It uses non-operational data. This means that the data warehouse is using a copy of data from the active databases that the company uses in its day-to-day operations, so the data warehouse must pull data from the existing databases on a regular, scheduled basis.
- The data is time-variant. This means that whenever data is loaded into the data warehouse, it receives a time stamp, which allows for comparisons between different time periods.
- The data is standardized. Because the data in a data warehouse usually comes from several different sources, it is possible that the data does not use the same definitions or units. For example, our Events table in our Student Clubs database lists the event dates using the mm/dd/yyyy format (e.g., 01/10/2013). A table in another database might use the format yy/mm/dd (e.g., 13/01/10) for dates. In order for the data warehouse to match up dates, a standard date format would have to be agreed upon and all data loaded into the data warehouse would have to be converted to use this standard format. This process is called extraction-transformation-load (ETL).
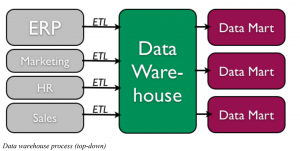 There are two primary schools of thought when designing a data warehouse: bottom-up and top-down. The bottom-up approach starts by creating small data warehouses, called data marts, to solve specific business problems. As these data marts are created, they can be combined into a larger data warehouse. The topdown approach suggests that we should start by creating an enterprise-wide data warehouse and then, as specific business needs are identified, create smaller data marts from the data warehouse.
There are two primary schools of thought when designing a data warehouse: bottom-up and top-down. The bottom-up approach starts by creating small data warehouses, called data marts, to solve specific business problems. As these data marts are created, they can be combined into a larger data warehouse. The topdown approach suggests that we should start by creating an enterprise-wide data warehouse and then, as specific business needs are identified, create smaller data marts from the data warehouse.
Benefits of Data Warehouses
Organizations find data warehouses quite beneficial for a number of reasons:
- The process of developing a data warehouse forces an organization to better understand the data that it is currently collecting and, equally important, what data is not being collected.
- A data warehouse provides a centralized view of all data being collected across the enterprise and provides a means for determining data that is inconsistent.
- Once all data is identified as consistent, an organization can generate one version of the truth. This is important when the company wants to report consistent statistics about itself, such as revenue or number of employees.
- By having a data warehouse, snapshots of data can be taken over time. This creates a historical record of data, which allows for an analysis of trends.
- A data warehouse provides tools to combine data, which can provide new information and analysis.
What Is a Business Process?
We have all heard the term process before, but what exactly does it mean? A process is a series of tasks that are completed in order to accomplish a goal. A business process, therefore, is a process that is focused on achieving a goal for a business. If you have worked in a business setting, you have participated in a business process. Anything from a simple process for making a sandwich at Subway to building a space shuttle utilizes one or more business processes.
Processes are something that businesses go through every day in order to accomplish their mission. The better their processes, the more effective the business. Some businesses see their processes as a strategy for achieving competitive advantage. A process that achieves its goal in a unique way can set a company apart. A process that eliminates costs can allow a company to lower its prices (or retain more profit).
Examples
Documenting a Process
Every day, each of us will conduct many processes without even thinking about them: getting ready for work, using an ATM, reading our e-mail, etc. But as processes grow more complex, they need to be documented. For businesses, it is essential to do this, because it allows them to ensure control over how activities are undertaken in their organization. It also allows for standardization: McDonald’s has the same process for building a Big Mac in all of its restaurants.
The simplest way to document a process is to simply create a list. The list shows each step in the process; each step can be checked off upon completion. For example, a simple process, such as how to create an account on eBay, might look like this:
- Go to ebay.com.
- Click on “register.”
- Enter your contact information in the “Tell us about you” box.
- Choose your user ID and password.
- Agree to User Agreement and Privacy Policy by clicking on “Submit.”
For processes that are not so straightforward, documenting the process as a checklist may not be sufficient. For example, here is the process for determining if an article for a term needs to be added to Wikipedia:
- Search Wikipedia to determine if the term already exists.
- If the term is found, then an article is already written, so you must think of another term. Go to 1
- If the term is not found, then look to see if there is a related term.
- If there is a related term, then create a redirect. 5. If there is not a related term, then create a new article.
This procedure is relatively simple – in fact, it has the same number of steps as the previous example – but because it has some decision points, it is more difficult to track with as a simple list. In these cases, it may make more sense to use a diagram to document the process.
Managing Business Process Documentation
As organizations begin to document their processes, it becomes an administrative task to keep track of them. As processes change and improve, it is important to know which processes are the most recent. It is also important to manage the process so that it can be easily updated! The requirement to manage process documentation has been one of the driving forces behind the creation of the document management system. A document management system stores and tracks documents and supports the following functions:
- Versions and timestamps. The document management system will keep multiple versions of documents. The most recent version of a document is easy to identify and will be served up by default.
- Approvals and workflows. When a process needs to be changed, the system will manage both access to the documents for editing and the routing of the document for approvals.
- Communication. When a process changes, those who implement the process need to be made aware of the changes. A document management system will notify the appropriate people when a change to a document is approved.
Of course, document management systems are not only used for managing business process documentation. Many other types of documents are managed in these systems, such as legal documents or design documents.
Examples
Reengineering the Bookstore
The process of purchasing the correct textbooks in a timely manner for university classes has always been problematic. And now, with online bookstores such as Amazon competing directly with the university bookstore for students’ purchases, the university bookstore is under pressure to justify its existence. But university bookstores have one big advantage over their competitors: they have access to students’ data. In other words, once a student has registered for classes, the bookstore knows exactly what books that student will need for the upcoming term. To leverage this advantage and take advantage of new technologies, the bookstore wants to implement a new process that will make purchasing books through the bookstore advantageous to students. Though they may not be able to compete on price, they can provide other advantages, such as reducing the time it takes to find the books and the ability to guarantee that the book is the correct one for the class. In order to do this, the bookstore will need to undertake a process redesign. The goal of the process redesign is simple: capture a higher percentage of students as customers of the bookstore. After diagramming the existing process and meeting with student focus groups, the bookstore comes up with a new process. In the new process, the bookstore utilizes information technology to reduce the amount of work the students need to do in order to get their books. In this new process, the bookstore sends the students an e-mail with a list of all the books required for their upcoming classes. By clicking a link in this e-mail, the students can log into the bookstore, confirm their books, and purchase the books. The bookstore will then deliver the books to the students.
Enterprise Resource Planning System
An enterprise resource planning (ERP) system is a software application with a centralized database that can be used to run an entire company. Let’s take a closer look at the definition of each of these components:
- A software application: The system is a software application, which means that it has been developed with specific logic and rules behind it. It has to be installed and configured to work specifically for an individual organization.
- With a centralized database: All data in an ERP system is stored in a single, central database. This centralization is key to the success of an ERP – data entered in one part of the company can be immediately available to other parts of the company.
- That can be used to run an entire company: An ERP can be used to manage an entire organization’s operations. If they so wish, companies can purchase modules for an ERP that represent different functions within the organization, such as finance, manufacturing, and sales. Some companies choose to purchase many modules, others choose a subset of the modules.
An ERP system not only centralizes an organization’s data, but the processes it enforces are the processes the organization adopts. When an ERP vendor designs a module, it has to implement the rules for the associated business processes. A selling point of an ERP system is that it has best practices built right into it. In other words, when an organization implements an ERP, it also gets improved best practices as part of the deal!
For many organizations, the implementation of an ERP system is an excellent opportunity to improve their business practices and upgrade their software at the same time. But for others, an ERP brings them a challenge: Is the process embedded in the ERP really better than the process they are currently utilizing? And if they implement this ERP, and it happens to be the same one that all of their competitors have, will they simply become more like them, making it much more difficult to differentiate themselves?
This has been one of the criticisms of ERP systems: that they commoditize business processes, driving all businesses to use the same processes and thereby lose their uniqueness. The good news is that ERP systems also have the capability to be configured with custom processes. For organizations that want to continue using their own processes or even design new ones, ERP systems offer ways to support this through the use of customizations.
But there is a drawback to customizing an ERP system: organizations have to maintain the changes themselves. Whenever an update to the ERP system comes out, any organization that has created a custom process will be required to add that change to their ERP. This will require someone to maintain a listing of these changes and will also require retesting the system every time an upgrade is made. Organizations will have to wrestle with this decision: When should they go ahead and accept the best-practice processes built into the ERP system and when should they spend the resources to develop their own processes? It makes the most sense to only customize those processes that are critical to the competitive advantage of the company. Some of the best-known ERP vendors are SAP, Microsoft, and Oracle.
Key Takeaways
2. What are three examples of information system hardware?
3. Microsoft Windows is an example of which component of information systems?
4. What is application software?
5. What roles do people play in information systems?
6. What is the definition of a process?
7. What was invented first, the personal computer or the Internet (ARPANET)?
8. In what year were restrictions on commercial use of the Internet first lifted? When were eBay and Amazon founded?
9. What does it mean to say we are in a “post-PC world”?
10. What is Carr’s main argument about information technology?
Exercises
1. Suppose that you had to explain to a member of your family or one of your closest friends the concept of an information system. How would you define it? Write a one-paragraph description in your own words that you feel would best describe an information system to your friends or family.
2. Of the five primary components of an information system (hardware, software, data, people, process), which do you think is the most important to the success of a business organization? Write a one-paragraph answer to this question that includes an example from your personal experience to support your answer.
3. We all interact with various information systems every day: at the grocery store, at work, at school, even in our cars (at least some of us). Make a list of the different information systems you interact with every day. See if you can identify the technologies, people, and processes involved in making these systems work.
4. Do you agree that we are in a post-PC stage in the evolution of information systems? Some people argue that we will always need the personal computer, but that it will not be the primary device used for manipulating information. Others think that a whole new era of mobile and biological computing is coming. Do some original research and make your prediction about what business computing will look like in the next generation.
5. The Walmart case study introduced you to how that company used information systems to become the world’s leading retailer. Walmart has continued to innovate and is still looked to as a leader in the use of technology. Do some original research and write a one-page report detailing a new technology that Walmart has recently implemented or is pioneering.
6. How has information technology changed your life? Describe at least three areas (both personal and school- or work-related) where having access to better information has improved your decisions. Are there any negative effects? What steps can you take to manage information better?
Attributions
Information Systems for Business and Beyond by David T. Bourgeois is licensed under CC BY 4.0
Introduction to Business by OpenStax is licensed under CC BY 4.0
An electronic filing system that collects and organizes data and information.
An executive with responsibility for managing all information resources in an organization.
A management support system that helps managers make decisions using interactive computer models that describe real-world processes.
Special subset of a data warehouse that deals with a single area of data and is organized for quick analysis.
An information technology that combines many databases across a whole company into one central database that supports management decision-making.
