Sevda Montakhaby Nodeh
Perception and Sensorimotor Lab
Welcome to the Perception and Sensorimotor Lab at McMaster University. As a budding cognitive psychologist here, you are about to embark on an explorative journey into the depth effect—a captivating psychological phenomenon that suggests visual events occurring in closer proximity (near space) are processed more efficiently than those farther away (far space). This effect provides a unique window into the cognitive architecture underpinning our sensory experiences, possibly implicating the involvement of the dorsal visual stream, which processes spatial relationships and movements in near space, and the ventral stream, known for its role in recognizing detailed visual information.
Your goal is to dissect whether the depth effect is task-dependent, aligning strictly with the dorsal/ventral stream dichotomy, or whether it represents a universal processing advantage for stimuli in near space across various cognitive tasks.
Your research journey begins in your lab. Imagine the lab as a gateway to a three-dimensional world, where the concept of depth is not only a subject of study but also a lived sensory experience for your participants! Seated inside a darkened tent, each participant grips a steering wheel, their primary tool for interaction and inputting responses. Before them, a screen comes to life with a 3D virtual environment meticulously engineered to test the frontiers of depth perception.
The virtual landscape participants encounter is a model of simplicity and complexity; as illustrated in the figure below, before the participants a ground plane extends into the depth of the screen, intersected by two sets of upright placeholder walls at varying depths—near and far. The walls stand on either side of the central axis, mirrored perfectly across the midline. The textures of the ground and placeholders—a random dot matrix and a checkerboard pattern, respectively—maintain a consistent density. These visual hints, alongside the textural gradients and the retinal size variance between near and far objects, act as subtle cues for depth perception.

From their first-person point of view, participants are asked to:
- Either discriminate the orientation of a red triangular target or localize a checkered square within this 3D dimensional immersive environment.
- The targets could appear in both near and far spaces, demanding keen sensory discrimination and localization.
Through this experiment, you are not just observing the depth effect; you are dissecting it, unearthing the cognitive processes that allow humans to navigate the intricate dance of depth in our daily lives!
Let’s begin by loading the required libraries and the dataset. To do so download the file “NearFarRep_Outlier.csv” and run the following code.
Note: Shaded boxes hold the R code, with the "#" sign indicating a comment that won't execute in RStudio.
# Loading the required
libraries library(tidyverse) # for data manipulation
library(rstatix) # for statistical analyses
library(emmeans) # for pairwise comparisons
library(afex) # for running anova using aov_ez and aov_car
library(kableExtra) # formatting html ANOVA tables
library(ggpubr) # for making plots
library(grid) # for plots
library(gridExtra) # for arranging multiple ggplots for extraction
library(lsmeans) # for pairwise comparisons
Read in the downloaded dataset “NearFarRep_Outlier.csv” as “NearFarData”. Remember to replace ‘path_to_your_downloaded_file’ with the actual path to the dataset on your system.
NearFarData <- read.csv('path_to_your_downloaded_file/NearFarRep_Outlier.csv')
The dataset contains the response times of participants and includes the following columns:
- “Response” indicates the type of task (Discrimination or Localization)
- “Con” indicating the target depth (Near or Far)
- “TarRT” represents the target response times.
Files to Download:
Please complete the accompanying exercises to the best of your abilities.
Answer Key
Exercise 1: Data Preparation and Exploration
Note: Shaded boxes hold the R code, while the white boxes display the code's output, just as it appears in RStudio.
The "#" sign indicates a comment that won't execute in RStudio.
1. Display the first few rows to understand your dataset. Display all column names in the dataset.
head(NearFarData) #Displaying the first few rows## X ID Response Con TarRT
## 1 1 10 Loc Near 0.6200754
## 2 2 10 Loc Near 0.2219719
## 3 3 1 Loc Near 0.2270377
## 4 4 9 Loc Near 0.5270686
## 5 5 25 Loc Near 0.2272455
## 6 6 18 Loc Near 0.2292785
colnames(NearFarData)
## [1] "X" "ID" "Response" "Con" "TarRT"
2. Set up “Response” and “Con” as factors, then check the structure of your data to make sure your factors and levels are set up correctly.
NearFarData <- NearFarData %>% convert_as_factor(Response, Con)str(NearFarData)## 'data.frame': 11154 obs. of 5 variables:
## $ X : int 1 2 3 4 5 6 7 8 9 10 ...
## $ ID : int 10 10 1 9 25 18 4 9 8 18 ...
## $ Response: Factor w/ 2 levels "Disc","Loc": 2 2 2 2 2 2 2 2 2 2 ...
## $ Con : Factor w/ 2 levels "Far","Near": 2 2 2 2 2 2 2 2 2 2 ...
## $ TarRT : num 0.62 0.222 0.227 0.527 0.227 ...
3. Perform basic data checks for missing values and data consistency.
sum(is.na(NearFarData)) # Checking for missing values in the dataset## [1] 0
4. Convert the values in your dependent measures column “TarRT” to seconds.
NearFarData$TarRT <- NearFarData$TarRT * 1000
Exercise 2: Visualizing Your Data
- Using the “dplyr” package, write R code to calculate the mean response time and the standard error of the mean (SERT) for each combination of your two factors (Response and Con).
# Calculate means and standard errors for each combination of 'Response' and 'Con'
summary_df <- NearFarData %>%
group_by(Response, Con) %>%
summarise(
MeanRT = mean(TarRT),
SERT = sd(TarRT) / sqrt(n())
)
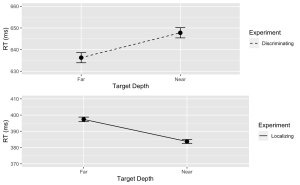
6. Using the “ggplot2” package, create a line plot with error bars for the Discrimination task.
- (a) The x-axis should represent the target depth (Con), and be labelled “Target Depth”.
- (b) The y-axis should represent the mean response time (MeanRT), and be labelled “RT (ms)”
- (c) Error bars should represent the standard error of the mean (SERT).
- (d) Ensure the line type is solid.
- (e) Set the minimum value of your y-axis to 630 and the maximum to 660.
# Now, using ggplot to create the plotDisc.plot <- ggplot(data = filter(summary_df, Response=="Disc"), aes(x = Con, y = MeanRT, group = Response)) + geom_line(aes(linetype = "Discriminating")) + # Add a linetype aesthetic geom_errorbar(aes(ymin = MeanRT - SERT, ymax = MeanRT + SERT), width = 0.1) + geom_point(size = 3) + theme_gray() + labs( x = "Target Depth", y = "RT (ms)", color = "Experiment", linetype = "Experiment") + scale_linetype_manual(values = "dashed") + # Set the linetype for "Disc" to dashed ylim(630, 660) # Set the y-axis limits
7. Similarly, create a line plot with error bars for the Localization task. Use a dashed line for this plot with the following exceptions:
- (a) Ensure the line type is dashed
- (b) Set the minimum value of your y-axis to 370 and the maximum to 410.
Loc.plot <- ggplot(data = filter(summary_df, Response=="Loc"), aes(x = Con, y = MeanRT, group = Response)) +
geom_line(aes(linetype = "Localizing")) + # Add a linetype aesthetic
geom_errorbar(aes(ymin = MeanRT - SERT, ymax = MeanRT + SERT), width = 0.1) +
geom_point(size = 3) +
theme_gray() +
labs(
x = "Target Depth",
y = "RT (ms)",
color = "Experiment",
linetype = "Experiment") +
scale_linetype_manual(values = "solid") + # Set the line type for "Disc" to dashed
ylim(370, 410) # Set the y-axis limits
8. Finally, use the grid.arrange() function from the “gridExtra” package to stack the plots for the Discrimination and Localization tasks on top of each other.
grid.arrange(Disc.plot, Loc.plot, ncol = 1) # Stack the plots on top of each other
Exercise 3: ANOVA Analysis
9. Using the “anova_test” function, conduct a two-way between-subjects ANOVA to investigate the effects of Con (Condition) and Response (Task type) on the target response times (TarRT). After running the ANOVA, use the “get_anova_table” function to present the results.
anova <- anova_test(
data = NearFarData, dv = TarRT, wid = ID,
between = c(Con, Response), detailed = TRUE, effect.size = "pes")
## Warning: The 'wid' column contains duplicate ids across between-subjects
## variables. Automatic unique id will be created
get_anova_table(anova)
## ANOVA Table (type III tests)
##
## Effect SSn SSd DFn DFd F p p<.05
## 1 (Intercept) 2.972143e+09 111582983 1 11150 296993.268 0.00e+00 *
## 2 Con 3.185839e+03 111582983 1 11150 0.318 5.73e-01
## 3 Response 1.762985e+08 111582983 1 11150 17616.741 0.00e+00 *
## 4 Con:Response 4.390483e+05 111582983 1 11150 43.872 3.67e-11 *
## pes
## 1 9.64e-01
## 2 2.86e-05
## 3 6.12e-01
## 4 4.00e-03
Exercise 4: Post Hoc Analysis
- Use “lm” function to fit a linear model to your data. Make sure to specify your dependent variable, independent variables, and interaction terms.
## Fitting a linear model to data
lm_model <- lm(TarRT ~ Con * Response, data = NearFarData)
- Use the “emmeans” function to get the estimated marginal means for your factors and their interaction. Then, use the pairs function to perform pairwise comparisons.
- (a) Set the adjust parameter in the test function to “Tukey” for Tukey’s honest significant difference test, to adjust for multiple comparisons to control the family-wise error rate.
# Get the estimated marginal means
emm <- emmeans(lm_model, specs = pairwise ~ Con * Response)
# View the results
print(post_hoc_results)
## contrast estimate SE df t.ratio p.value
## Far Disc - Near Disc -11.5 2.70 11150 -4.250 0.0001
## Far Disc - Far Loc 238.9 2.67 11150 89.348 <.0001
## Far Disc - Near Loc 252.6 2.67 11150 94.581 <.0001
## Near Disc - Far Loc 250.4 2.69 11150 93.131 <.0001
## Near Disc - Near Loc 264.0 2.68 11150 98.341 <.0001
## Far Loc - Near Loc 13.6 2.66 11150 5.124 <.0001
##
## P value adjustment: tukey method for comparing a family of 4 estimates
