57 Understanding Null Hypothesis Testing
Learning Objectives
- Explain the purpose of null hypothesis testing, including the role of sampling error.
- Describe the basic logic of null hypothesis testing.
- Describe the role of relationship strength and sample size in determining statistical significance and make reasonable judgments about statistical significance based on these two factors.
The Purpose of Null Hypothesis Testing
As we have seen, psychological research typically involves measuring one or more variables in a sample and computing descriptive summary data (e.g., means, correlation coefficients) for those variables. These descriptive data for the sample are called statistics. In general, however, the researcher’s goal is not to draw conclusions about that sample but to draw conclusions about the population that the sample was selected from. Thus researchers must use sample statistics to draw conclusions about the corresponding values in the population. These corresponding values in the population are called parameters. Imagine, for example, that a researcher measures the number of depressive symptoms exhibited by each of 50 adults with clinical depression and computes the mean number of symptoms. The researcher probably wants to use this sample statistic (the mean number of symptoms for the sample) to draw conclusions about the corresponding population parameter (the mean number of symptoms for adults with clinical depression).
Unfortunately, sample statistics are not perfect estimates of their corresponding population parameters. This is because there is a certain amount of random variability in any statistic from sample to sample. The mean number of depressive symptoms might be 8.73 in one sample of adults with clinical depression, 6.45 in a second sample, and 9.44 in a third—even though these samples are selected randomly from the same population. Similarly, the correlation (Pearson’s r) between two variables might be +.24 in one sample, −.04 in a second sample, and +.15 in a third—again, even though these samples are selected randomly from the same population. This random variability in a statistic from sample to sample is called sampling error. (Note that the term error here refers to random variability and does not imply that anyone has made a mistake. No one “commits a sampling error.”)
One implication of this is that when there is a statistical relationship in a sample, it is not always clear that there is a statistical relationship in the population. A small difference between two group means in a sample might indicate that there is a small difference between the two group means in the population. But it could also be that there is no difference between the means in the population and that the difference in the sample is just a matter of sampling error. Similarly, a Pearson’s r value of −.29 in a sample might mean that there is a negative relationship in the population. But it could also be that there is no relationship in the population and that the relationship in the sample is just a matter of sampling error.
In fact, any statistical relationship in a sample can be interpreted in two ways:
- There is a relationship in the population, and the relationship in the sample reflects this.
- There is no relationship in the population, and the relationship in the sample reflects only sampling error.
The purpose of null hypothesis testing is simply to help researchers decide between these two interpretations.
The Logic of Null Hypothesis Testing
Null hypothesis testing (often called null hypothesis significance testing or NHST) is a formal approach to deciding between two interpretations of a statistical relationship in a sample. One interpretation is called the null hypothesis (often symbolized H0 and read as “H-zero”). This is the idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error. Informally, the null hypothesis is that the sample relationship “occurred by chance.” The other interpretation is called the alternative hypothesis (often symbolized as H1). This is the idea that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
Again, every statistical relationship in a sample can be interpreted in either of these two ways: It might have occurred by chance, or it might reflect a relationship in the population. So researchers need a way to decide between them. Although there are many specific null hypothesis testing techniques, they are all based on the same general logic. The steps are as follows:
- Assume for the moment that the null hypothesis is true. There is no relationship between the variables in the population.
- Determine how likely the sample relationship would be if the null hypothesis were true.
- If the sample relationship would be extremely unlikely, then reject the null hypothesis in favor of the alternative hypothesis. If it would not be extremely unlikely, then retain the null hypothesis.
Following this logic, we can begin to understand why Mehl and his colleagues concluded that there is no difference in talkativeness between women and men in the population. In essence, they asked the following question: “If there were no difference in the population, how likely is it that we would find a small difference of d = 0.06 in our sample?” Their answer to this question was that this sample relationship would be fairly likely if the null hypothesis were true. Therefore, they retained the null hypothesis—concluding that there is no evidence of a sex difference in the population. We can also see why Kanner and his colleagues concluded that there is a correlation between hassles and symptoms in the population. They asked, “If the null hypothesis were true, how likely is it that we would find a strong correlation of +.60 in our sample?” Their answer to this question was that this sample relationship would be fairly unlikely if the null hypothesis were true. Therefore, they rejected the null hypothesis in favor of the alternative hypothesis—concluding that there is a positive correlation between these variables in the population.
A crucial step in null hypothesis testing is finding the probability of the sample result or a more extreme result if the null hypothesis were true (Lakens, 2017).[1] This probability is called the p value. A low p value means that the sample or more extreme result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A p value that is not low means that the sample or more extreme result would be likely if the null hypothesis were true and leads to the retention of the null hypothesis. But how low must the p value criterion be before the sample result is considered unlikely enough to reject the null hypothesis? In null hypothesis testing, this criterion is called α (alpha) and is almost always set to .05. If there is a 5% chance or less of a result at least as extreme as the sample result if the null hypothesis were true, then the null hypothesis is rejected. When this happens, the result is said to be statistically significant. If there is greater than a 5% chance of a result as extreme as the sample result when the null hypothesis is true, then the null hypothesis is retained. This does not necessarily mean that the researcher accepts the null hypothesis as true—only that there is not currently enough evidence to reject it. Researchers often use the expression “fail to reject the null hypothesis” rather than “retain the null hypothesis,” but they never use the expression “accept the null hypothesis.”
The Misunderstood p Value
The p value is one of the most misunderstood quantities in psychological research (Cohen, 1994)[2]. Even professional researchers misinterpret it, and it is not unusual for such misinterpretations to appear in statistics textbooks!
The most common misinterpretation is that the p value is the probability that the null hypothesis is true—that the sample result occurred by chance. For example, a misguided researcher might say that because the p value is .02, there is only a 2% chance that the result is due to chance and a 98% chance that it reflects a real relationship in the population. But this is incorrect. The p value is really the probability of a result at least as extreme as the sample result if the null hypothesis were true. So a p value of .02 means that if the null hypothesis were true, a sample result this extreme would occur only 2% of the time.
You can avoid this misunderstanding by remembering that the p value is not the probability that any particular hypothesis is true or false. Instead, it is the probability of obtaining the sample result if the null hypothesis were true.

Role of Sample Size and Relationship Strength
Recall that null hypothesis testing involves answering the question, “If the null hypothesis were true, what is the probability of a sample result as extreme as this one?” In other words, “What is the p value?” It can be helpful to see that the answer to this question depends on just two considerations: the strength of the relationship and the size of the sample. Specifically, the stronger the sample relationship and the larger the sample, the less likely the result would be if the null hypothesis were true. That is, the lower the p value. This should make sense. Imagine a study in which a sample of 500 women is compared with a sample of 500 men in terms of some psychological characteristic, and Cohen’s d is a strong 0.50. If there were really no sex difference in the population, then a result this strong based on such a large sample should seem highly unlikely. Now imagine a similar study in which a sample of three women is compared with a sample of three men, and Cohen’s d is a weak 0.10. If there were no sex difference in the population, then a relationship this weak based on such a small sample should seem likely. And this is precisely why the null hypothesis would be rejected in the first example and retained in the second.
Of course, sometimes the result can be weak and the sample large, or the result can be strong and the sample small. In these cases, the two considerations trade off against each other so that a weak result can be statistically significant if the sample is large enough and a strong relationship can be statistically significant even if the sample is small. Table 13.1 shows roughly how relationship strength and sample size combine to determine whether a sample result is statistically significant. The columns of the table represent the three levels of relationship strength: weak, medium, and strong. The rows represent four sample sizes that can be considered small, medium, large, and extra large in the context of psychological research. Thus each cell in the table represents a combination of relationship strength and sample size. If a cell contains the word Yes, then this combination would be statistically significant for both Cohen’s d and Pearson’s r. If it contains the word No, then it would not be statistically significant for either. There is one cell where the decision for d and r would be different and another where it might be different depending on some additional considerations, which are discussed in Section 13.2 “Some Basic Null Hypothesis Tests”
| Relationship strength | |||
| Sample Size | Weak | Medium | Strong |
| Small (N = 20) | No | No | d = Maybe
r = Yes |
| Medium (N = 50) | No | Yes | Yes |
| Large (N = 100) | d = Yes
r = No |
Yes | Yes |
| Extra large (N = 500) | Yes | Yes | Yes |
Although Table 13.1 provides only a rough guideline, it shows very clearly that weak relationships based on medium or small samples are never statistically significant and that strong relationships based on medium or larger samples are always statistically significant. If you keep this lesson in mind, you will often know whether a result is statistically significant based on the descriptive statistics alone. It is extremely useful to be able to develop this kind of intuitive judgment. One reason is that it allows you to develop expectations about how your formal null hypothesis tests are going to come out, which in turn allows you to detect problems in your analyses. For example, if your sample relationship is strong and your sample is medium, then you would expect to reject the null hypothesis. If for some reason your formal null hypothesis test indicates otherwise, then you need to double-check your computations and interpretations. A second reason is that the ability to make this kind of intuitive judgment is an indication that you understand the basic logic of this approach in addition to being able to do the computations.
Statistical Significance Versus Practical Significance
Table 13.1 illustrates another extremely important point. A statistically significant result is not necessarily a strong one. Even a very weak result can be statistically significant if it is based on a large enough sample. This is closely related to Janet Shibley Hyde’s argument about sex differences (Hyde, 2007)[3]. The differences between women and men in mathematical problem solving and leadership ability are statistically significant. But the word significant can cause people to interpret these differences as strong and important—perhaps even important enough to influence the college courses they take or even who they vote for. As we have seen, however, these statistically significant differences are actually quite weak—perhaps even “trivial.”
This is why it is important to distinguish between the statistical significance of a result and the practical significance of that result. Practical significance refers to the importance or usefulness of the result in some real-world context. Many sex differences are statistically significant—and may even be interesting for purely scientific reasons—but they are not practically significant. In clinical practice, this same concept is often referred to as “clinical significance.” For example, a study on a new treatment for social phobia might show that it produces a statistically significant positive effect. Yet this effect still might not be strong enough to justify the time, effort, and other costs of putting it into practice—especially if easier and cheaper treatments that work almost as well already exist. Although statistically significant, this result would be said to lack practical or clinical significance.

- Lakens, D. (2017, December 25). About p-values: Understanding common misconceptions. [Blog post] Retrieved from https://correlaid.org/en/blog/understand-p-values/ ↵
- Cohen, J. (1994). The world is round: p < .05. American Psychologist, 49, 997–1003. ↵
- Hyde, J. S. (2007). New directions in the study of gender similarities and differences. Current Directions in Psychological Science, 16, 259–263. ↵
Used in qualitative research which involves small groups of people who participate together in interviews focused on a particular topic or issue.
Concerns the proper statistical treatment of data and the soundness of the researchers’ statistical conclusions.
Researchers start with the data and develop a theory or an interpretation that is “grounded in” those data.
Where the same mental process is used in both the laboratory and in the real world.
When the participants and the situation studied are similar to those that the researchers want to generalize to and participants encounter every day.
A method in which the order of the conditions is randomly determined for each participant.
Learning Objectives
- Critically evaluate the sources of the information you have found
- Apply the information from each source to your research proposal
- Identify how to be a responsible consumer of research
In Chapter 2, you developed a “working question” to guide your inquiry and learned how to use online databases to find sources. By now, you’ve hopefully collected a number of academic journal articles relevant to your topic area. It’s now time to evaluate the information you found. Not only do you want to be sure of the source and the quality of the information, but you also want to determine whether each item is an appropriate fit for your literature review.
This is also the point at which you make sure you have searched for and obtained publications for all areas of your research question and that you go back into the literature for another search, if necessary. You may also want to consult with your professor or the syllabus for your class to see what is expected for your literature review. In my class, I have specific questions I will ask students to address in their literature reviews.

It is likely that most of the resources you locate for your review will be from the scholarly literature of your discipline or your topic area. As we have already seen, peer-reviewed articles are written by and for experts in a field. They generally describe formal research studies or experiments with the purpose of providing insight on a topic. You may have located these articles through the four databases in Chapter 2 or through archival searching. You are now probably wondering how to evaluate the utility of the articles you've collected so you can use them for your research.
Generally, when we discuss the evaluation of sources, we are referring to the following aspects: accuracy, relevance, bias, reputation, currency, and credibility factors. These measures apply to all works, including books, ebooks, articles, websites, or blog postings to name a few. Before you include a source in your literature review, you should clearly understand what it is and why you are including it. According to Bennard et al. (2014), “Using inaccurate, irrelevant, or poorly researched sources can affect the quality of your own work” (para. 4). When evaluating a work for inclusion in, or exclusion from, your literature review, ask yourself a series of questions about each source.
-
- Is the information outdated? Is the source more than 5-10 years old? If so, it will not provide what we currently know about the topic--just what we used to know. Older sources are helpful for historical information, but unless historical analysis is the focus of your literature review, try to limit your sources to those that are current.
- How old are the sources used by the author? If you are reading an article from 10 years ago, they are likely citing material from 15-20 years ago. Again, this does not reflect what we currently know about a topic.
- Does the author have the credentials to write on the topic? Search the author’s name in a general web search engine like Google. What are the researcher’s academic credentials? What else has this author written? Search by author in the databases and see how much they have published on any given subject.
- Who published the source? Books published under popular press imprints (such as Random House or Macmillan) will not present scholarly research in the same way as Sage, Oxford, Harvard, or the University of Washington Press. For grey literature and websites, check the About Us page to learn more about potential biases and funding of the organization who wrote the report.
- Is the source relevant to your topic? How does the article fit into the scope of the literature on this topic? Does the information support your thesis or help you answer your question, or is it a challenge to make some kind of connection? Does the information present an opposite point of view, so you can show that you have addressed all sides of the argument in your paper? Many times, literature searches will include articles that ultimately are not that relevant to your final topic. You don’t need to read everything!
- How important is this source in the literature? If you search for the article on Google Scholar (see Figure 3.1 for an example of a search result from Google Scholar), you can see how many other sources cited this information. Generally, the higher the number of citations, the more important the article. This is a way to find seminal articles – “A classic work of research literature that is more than 5 years old and is marked by its uniqueness and contribution to professional knowledge” (Houser, 2018, p. 112).
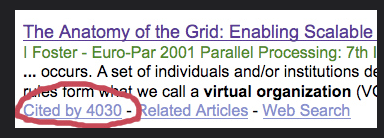
Figure 3.1 Google Scholar - Is the source accurate? Check the facts in the article. Can statistics be verified through other sources? Does this information seem to fit with what you have read in other sources?
- Is the source reliable and objective? Is a particular point of view or bias immediately obvious, or does it seem objective at first glance? What point of view does the author represent? Are they clear about their point of view? Is the article an editorial that is trying to argue a position? Is the article in a publication with a particular editorial position?
- What is the scope of the article? Is it a general work that provides an overview of the topic or is it specifically focused on only one aspect of your topic?
- How strong is the evidence in the article? What are the research methods used in the article? Where does the method fall in the hierarchy of evidence?
- Meta-analysis and meta-synthesis: a systematic and scientific review that uses quantitative or qualitative methods (respectively) to summarize the results of many studies on a topic.
- Experiments and quasi-experiments: include a group of patients in an experimental group, as well as a control group. These groups are monitored for the variables/outcomes of interest. Randomized control trials are the gold standard.
- Longitudinal surveys: follow a group of people to identify how variables of interest change over time.
- Cross-sectional surveys: observe individuals at one point in time and discover relationships between variables.
- Qualitative studies: use in-depth interviews and analysis of texts to uncover the meaning of social phenomenon
The last point above comes with some pretty strong caveats, as no study is really better than another. Foremost, your research question should guide which kinds of studies you collect for your literature review. If you are conducting a qualitative study, you should include some qualitative studies in your literature review so you can understand how others have studied the topic before you. Even if you are conducting a quantitative study, qualitative research is important for understanding processes and lived experiences. Any article that demonstrates rigor in both thought and methodology is appropriate to use in your inquiry.
At the beginning of a project, you may not know what kind of research project you will ultimately propose. At this point, consulting a meta-analysis, meta-synthesis, or systematic review might be especially helpful as these articles try to summarize an entire body of literature into one article. Every type of source listed here is reputable, but some have greater explanatory power than others.
Thinking about your project
Two of the initial steps in designing a research project are identifying the overarching goals of your project and conducting a literature review. Forming a working research question, as discussed in section 2.1, is another crucial step. Creating and refining your research question will help you identify the key concepts you will study. Once you have identified those concepts, you’ll need to define them and decide how you will know that you are observing them during your data collection. Defining your concepts, and knowing them when you see them, relates to conceptualization and operationalization. Of course, you also need to know what approach you will take to collect your data. Thus, identifying your research method is another important part of research design.
In addition to identifying your research method, you also need to think about who your research participants will be and the larger group(s) they may represent. Last but certainly not least, you should consider any potential ethical concerns that could arise during the course of your research project. These concerns might come up during your data collection, but they might also arise when you get to the point of analyzing or sharing your research results.
Decisions about the various research components do not necessarily occur in sequential order. In fact, you may have to think about potential ethical concerns before you even zero in on a specific research question. Similarly, the goal of being able to make generalizations about your population of interest could shape the decisions you make about your method of data collection. Putting it all together, the following list shows some of the major components you’ll need to consider as you design your research project. Make sure you have information that will help inform how you think about each component.
- Research question
- Literature review
- Research strategy (idiographic or nomothetic, inductive or deductive)
- Units of analysis and units of observation
- Key concepts (conceptualization and operationalization)
- Method of data collection
- Research participants (sample and population)
- Ethical concerns
Being a responsible consumer of research
Being a responsible consumer of research requires you to take your identity as a social scientist seriously. Now that you are familiar with how to conduct research and how to read the results of others’ research, you have some responsibility to put your knowledge and skills to use. To do so, you must be able to distinguish what you know based on research from what you do not know. It is also a matter of having some awareness about what you can and cannot reasonably know as you encounter research findings.
When assessing social scientific findings, think about what information has been provided to you. In a scholarly journal article, you will presumably be given a great deal of information about the researcher’s method of data collection, her sample, and information about how she identified and recruited research participants. All of these details provide important contextual information that can help you assess the researcher’s claims. On the other hand, a discussion of social scientific research in a popular magazine or newspaper will likely fail to provide the same level of detailed information. In this case, what you do and do not know is more limited than in the case of a scholarly journal article. If the research appears in popular media, search for the author or study title in an academic database.
Also, take into account whatever information is provided about a study’s funding source. Most times, the entities that fund a study require that they are acknowledged in the publication, but more popular press may leave out a funding source. In this Internet age, it can be relatively easy to obtain information about how a study was funded. If this information is not provided in the source from which you learned about a study, it might behoove you to do a quick search on the web to see if you can learn more about a researcher’s funding. Findings that seem to support a particular political agenda, for example, might have more or less weight once you know whether and by whom a study was funded.
There is some information that even the most responsible consumer of research cannot know. Because researchers are ethically bound to protect the identities of their subjects, for example, we will never know exactly who participated in a given study. Researchers may also choose not to reveal any personal stakes they hold in the research they conduct. While researchers may “start where they are,” we cannot know for certain whether or how researchers are personally connected to their work unless they choose to share such details. Neither of these “unknowables” are necessarily problematic, but having some awareness of what you may never know about a study does provide important contextual information from which to assess what one can “take away” from a given report of findings.
Key Takeaways
- Not all published articles are the same. Evaluating sources requires a careful investigation of each source.
- Being a responsible consumer of research means giving serious thought and understanding to what you do know, what you don’t know, what you can know, and what you can’t know.
Image attributions
130329-A-XX000-001 by Master Sgt. Michael Chann public domain
In this chapter, we’ll explore the connections between paradigms, social theories, and social scientific research methods. We’ll also consider how our analytic, paradigmatic, and theoretical perspective might shape or be shaped by our methodological choices. In short, we’ll discuss the relationship between theory and research methods.
Chapter Outline
- 6.1 Micro, meso, and macro approaches
- 6.2 Paradigms, theories, and how they shape a researcher’s approach
- 6.3 Inductive and deductive reasoning
Content Advisory
This chapter discusses or mentions the following topics: laws regulating rape, sodomy, and child sexual abuse; gang communication styles; racism, policing, and lynching; domestic violence and sexual harassment; and substance abuse.
When a researcher makes careful observations of one or more specific behaviors in a particular setting that is more structured than the settings used in naturalistic or participant observation.
An effect that is unlikely due to random chance and therefore likely represents a real effect in the population.
Holding extraneous variables constant in order to separate the effect of the independent variable from the effect of the extraneous variables.
