60 From the “Replicability Crisis” to Open Science Practices
Learning Objectives
- Describe what is meant by the “replicability crisis” in psychology.
- Describe some questionable research practices.
- Identify some ways in which scientific rigor may be increased.
- Understand the importance of openness in psychological science.
At the start of this book we discussed the “Many Labs Replication Project,” which failed to replicate the original finding by Simone Schnall and her colleagues that washing one’s hands leads people to view moral transgressions as less wrong (Schnall, Benton, & Harvey, 2008)[1]. Although this project is a good illustration of the collaborative and self-correcting nature of science, it also represents one specific response to psychology’s recent “replicability crisis,” a phrase that refers to the inability of researchers to replicate earlier research findings. Consider for example the results of the Reproducibility Project, which involved over 270 psychologists around the world coordinating their efforts to test the reliability of 100 previously published psychological experiments (Aarts et al., 2015)[2]. Although 97 of the original 100 studies had found statistically significant effects, only 36 of the replications did! Moreover, even the effect sizes of the replications were, on average, half of those found in the original studies (see Figure 13.5). Of course, a failure to replicate a result by itself does not necessarily discredit the original study as differences in the statistical power, populations sampled, and procedures used, or even the effects of moderating variables could explain the different results (Yong, 2015)[3].

Although many believe that the failure to replicate research results is an expected characteristic of cumulative scientific progress, others have interpreted this situation as evidence of systematic problems with conventional scholarship in psychology, including a publication bias that favors the discovery and publication of counter-intuitive but statistically significant findings instead of the duller (but incredibly vital) process of replicating previous findings to test their robustness (Aschwanden, 2015[4]; Frank, 2015[5]; Pashler & Harris, 2012[6]; Scherer, 2015[7]). Worse still is the suggestion that the low replicability of many studies is evidence of the widespread use of questionable research practices by psychological researchers. These may include:
- The selective deletion of outliers in order to influence (usually by artificially inflating) statistical relationships among the measured variables.
- The selective reporting of results, cherry-picking only those findings that support one’s hypotheses.
- Mining the data without an a priori hypothesis, only to claim that a statistically significant result had been originally predicted, a practice referred to as “HARKing” or hypothesizing after the results are known (Kerr, 1998[8]).
- A practice colloquially known as “p-hacking” (briefly discussed in the previous section), in which a researcher might perform inferential statistical calculations to see if a result was significant before deciding whether to recruit additional participants and collect more data (Head, Holman, Lanfear, Kahn, & Jennions, 2015)[9]. As you have learned, the probability of finding a statistically significant result is influenced by the number of participants in the study.
- Outright fabrication of data (as in the case of Diederik Stapel, described at the start of Chapter 3), although this would be a case of fraud rather than a “research practice.”
It is important to shed light on these questionable research practices to ensure that current and future researchers (such as yourself) understand the damage they wreak to the integrity and reputation of our discipline (see, for example, the “Replication Index,” a statistical “doping test” developed by Ulrich Schimmack in 2014 for estimating the replicability of studies, journals, and even specific researchers). However, in addition to highlighting what not to do, this so-called “crisis” has also highlighted the importance of enhancing scientific rigor by:
- Designing and conducting studies that have sufficient statistical power, in order to increase the reliability of findings.
- Publishing both null and significant findings (thereby counteracting the publication bias and reducing the file drawer problem).
- Describing one’s research designs in sufficient detail to enable other researchers to replicate your study using an identical or at least very similar procedure.
- Conducting high-quality replications and publishing these results (Brandt et al., 2014)[10].
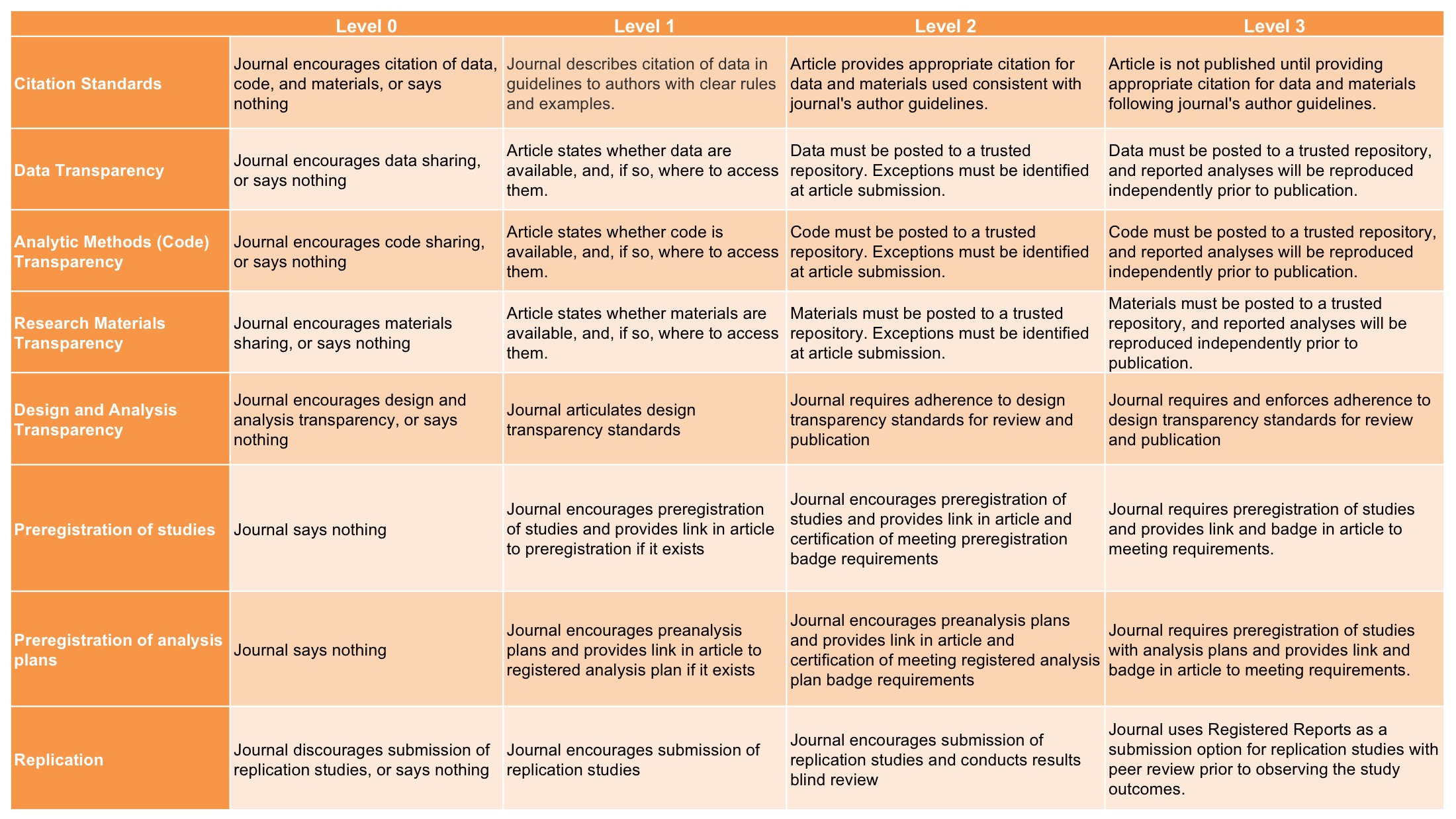
One particularly promising response to the replicability crisis has been the emergence of open science practices that increase the transparency and openness of the scientific enterprise. For example, Psychological Science (the flagship journal of the Association for Psychological Science) and other journals now issue digital badges to researchers who pre-registered their hypotheses and data analysis plans, openly shared their research materials with other researchers (e.g., to enable attempts at replication), or made available their raw data with other researchers (see Figure 13.6).

These initiatives, which have been spearheaded by the Center for Open Science, have led to the development of “Transparency and Openness Promotion guidelines” (see Table 13.7) that have since been formally adopted by more than 500 journals and 50 organizations, a list that grows each week. When you add to this the requirements recently imposed by federal funding agencies in Canada (the Tri-Council) and the United States (National Science Foundation) concerning the publication of publicly-funded research in open access journals, it certainly appears that the future of science and psychology will be one that embraces greater “openness” (Nosek et al., 2015)[11].
- Schnall, S., Benton, J., & Harvey, S. (2008). With a clean conscience: Cleanliness reduces the severity of moral judgments. Psychological Science, 19(12), 1219-1222. doi: 10.1111/j.1467-9280.2008.02227.x ↵
- Aarts, A. A., Anderson, C. J., Anderson, J., van Assen, M. A. L. M., Attridge, P. R., Attwood, A. S., … Zuni, K. (2015, September 21). Reproducibility Project: Psychology. Retrieved from osf.io/ezcuj ↵
- Yong, E. (August 27, 2015). How reliable are psychology studies? Retrieved from http://www.theatlantic.com/science/archive/2015/08/psychology-studies-reliability-reproducability-nosek/402466/ ↵
- Aschwanden, C. (2015, August 19). Science isn't broken: It's just a hell of a lot harder than we give it credit for. Fivethirtyeight. Retrieved from http://fivethirtyeight.com/features/science-isnt-broken/ ↵
- Frank, M. (2015, August 31). The slower, harder ways to increase reproducibility. Retrieved from http://babieslearninglanguage.blogspot.ie/2015/08/the-slower-harder-ways-to-increase.html ↵
- Pashler, H., & Harris, C. R. (2012). Is the replicability crisis overblown? Three arguments explained. Perspectives on Psychological Science, 7(6), 531-536. doi:10.1177/1745691612463401 ↵
- Scherer, L. (2015, September). Guest post by Laura Scherer. Retrieved from http://sometimesimwrong.typepad.com/wrong/2015/09/guest-post-by-laura-scherer.html ↵
- Kerr, N. L. (1998). HARKing: Hypothesizing after the results are known. Personality and Social Psychology Review, 2(3), 196-217. doi:10.1207/s15327957pspr0203_4 ↵
- Head M. L., Holman, L., Lanfear, R., Kahn, A. T., & Jennions, M. D. (2015). The extent and consequences of p-hacking in science. PLoS Biol, 13(3): e1002106. doi:10.1371/journal.pbio.1002106 ↵
- Brandt, M. J., IJzerman, H., Dijksterhuis, A., Farach, F. J., Geller, J., Giner-Sorolla, R., … can’t Veer, A. (2014). The replication recipe: What makes for a convincing replication? Journal of Experimental Social Psychology, 50, 217-224. doi:10.1016/j.jesp.2013.10.005 ↵
- Nosek, B. A., Alter, G., Banks, G. C., Borsboom, D., Bowman, S. D., Breckler, S. J., … Yarkoni, T. (2015). Promoting an open research culture. Science, 348(6242), 1422-1425. doi: 10.1126/science.aab2374 ↵
Learning Objectives
- Define the concept of a variable, distinguish quantitative from categorical variables, and give examples of variables that might be of interest to psychologists.
- Explain the difference between a population and a sample.
- Distinguish between experimental and non-experimental research.
- Distinguish between lab studies, field studies, and field experiments.
Identifying and Defining the Variables and Population
Variables and Operational Definitions
Part of generating a hypothesis involves identifying the variables that you want to study and operationally defining those variables so that they can be measured. Research questions in psychology are about variables. A variable is a quantity or quality that varies across people or situations. For example, the height of the students enrolled in a university course is a variable because it varies from student to student. The chosen major of the students is also a variable as long as not everyone in the class has declared the same major. Almost everything in our world varies and as such thinking of examples of constants (things that don't vary) is far more difficult. A rare example of a constant is the speed of light. Variables can be either quantitative or categorical. A quantitative variable is a quantity, such as height, that is typically measured by assigning a number to each individual. Other examples of quantitative variables include people’s level of talkativeness, how depressed they are, and the number of siblings they have. A categorical variable is a quality, such as chosen major, and is typically measured by assigning a category label to each individual (e.g., Psychology, English, Nursing, etc.). Other examples include people’s nationality, their occupation, and whether they are receiving psychotherapy.
After the researcher generates their hypothesis and selects the variables they want to manipulate and measure, the researcher needs to find ways to actually measure the variables of interest. This requires an operational definition—a definition of the variable in terms of precisely how it is to be measured. Most variables that researchers are interested in studying cannot be directly observed or measured and this poses a problem because empiricism (observation) is at the heart of the scientific method. Operationally defining a variable involves taking an abstract construct like depression that cannot be directly observed and transforming it into something that can be directly observed and measured. Most variables can be operationally defined in many different ways. For example, depression can be operationally defined as people’s scores on a paper-and-pencil depression scale such as the Beck Depression Inventory, the number of depressive symptoms they are experiencing, or whether they have been diagnosed with major depressive disorder. Researchers are wise to choose an operational definition that has been used extensively in the research literature.
Sampling and Measurement
In addition to identifying which variables to manipulate and measure, and operationally defining those variables, researchers need to identify the population of interest. Researchers in psychology are usually interested in drawing conclusions about some very large group of people. This is called the population. It could be all American teenagers, children with autism, professional athletes, or even just human beings—depending on the interests and goals of the researcher. But they usually study only a small subset or sample of the population. For example, a researcher might measure the talkativeness of a few hundred university students with the intention of drawing conclusions about the talkativeness of men and women in general. It is important, therefore, for researchers to use a representative sample—one that is similar to the population in important respects.
One method of obtaining a sample is simple random sampling, in which every member of the population has an equal chance of being selected for the sample. For example, a pollster could start with a list of all the registered voters in a city (the population), randomly select 100 of them from the list (the sample), and ask those 100 whom they intend to vote for. Unfortunately, random sampling is difficult or impossible in most psychological research because the populations are less clearly defined than the registered voters in a city. How could a researcher give all American teenagers or all children with autism an equal chance of being selected for a sample? The most common alternative to random sampling is convenience sampling, in which the sample consists of individuals who happen to be nearby and willing to participate (such as introductory psychology students). Of course, the obvious problem with convenience sampling is that the sample might not be representative of the population and therefore it may be less appropriate to generalize the results from the sample to that population.
Experimental vs. Non-Experimental Research
The next step a researcher must take is to decide which type of approach they will use to collect the data. As you will learn in your research methods course there are many different approaches to research that can be divided in many different ways. One of the most fundamental distinctions is between experimental and non-experimental research.
Experimental Research
Researchers who want to test hypotheses about causal relationships between variables (i.e., their goal is to explain) need to use an experimental method. This is because the experimental method is the only method that allows us to determine causal relationships. Using the experimental approach, researchers first manipulate one or more variables while attempting to control extraneous variables, and then they measure how the manipulated variables affect participants’ responses.
The terms independent variable and dependent variable are used in the context of experimental research. The independent variable is the variable the experimenter manipulates (it is the presumed cause) and the dependent variable is the variable the experimenter measures (it is the presumed effect).
Extraneous variables are any variable other than the dependent variable. Confounds are a specific type of extraneous variable that systematically varies along with the variables under investigation and therefore provides an alternative explanation for the results. When researchers design an experiment they need to ensure that they control for confounds; they need to ensure that extraneous variables don’t become confounding variables because in order to make a causal conclusion they need to make sure alternative explanations for the results have been ruled out.
As an example, if we manipulate the lighting in the room and examine the effects of that manipulation on workers’ productivity, then the lighting conditions (bright lights vs. dim lights) would be considered the independent variable and the workers’ productivity would be considered the dependent variable. If the bright lights are noisy then that noise would be a confound since the noise would be present whenever the lights are bright and the noise would be absent when the lights are dim. If noise is varying systematically with light then we wouldn’t know if a difference in worker productivity across the two lighting conditions is due to noise or light. So confounds are bad, they disrupt our ability to make causal conclusions about the nature of the relationship between variables. However, if there is noise in the room both when the lights are on and when the lights are off then noise is merely an extraneous variable (it is a variable other than the independent or dependent variable) and we don't worry much about extraneous variables. This is because unless a variable varies systematically with the manipulated independent variable it cannot be a competing explanation for the results.
Non-Experimental Research
Researchers who are simply interested in describing characteristics of people, describing relationships between variables, and using those relationships to make predictions can use non-experimental research. Using the non-experimental approach, the researcher simply measures variables as they naturally occur, but they do not manipulate them. For instance, if I just measured the number of traffic fatalities in America last year that involved the use of a cell phone but I did not actually manipulate cell phone use then this would be categorized as non-experimental research. Alternatively, if I stood at a busy intersection and recorded drivers' genders and whether or not they were using a cell phone when they passed through the intersection to see whether men or women are more likely to use a cell phone when driving, then this would be non-experimental research. It is important to point out that non-experimental does not mean nonscientific. Non-experimental research is scientific in nature. It can be used to fulfill two of the three goals of science (to describe and to predict). However, unlike with experimental research, we cannot make causal conclusions using this method; we cannot say that one variable causes another variable using this method.
Laboratory vs. Field Research
The next major distinction between research methods is between laboratory and field studies. A laboratory study is a study that is conducted in the laboratory environment. In contrast, a field study is a study that is conducted in the real-world, in a natural environment.
Laboratory experiments typically have high internal validity. Internal validity refers to the degree to which we can confidently infer a causal relationship between variables. When we conduct an experimental study in a laboratory environment we have very high internal validity because we manipulate one variable while controlling all other outside extraneous variables. When we manipulate an independent variable and observe an effect on a dependent variable and we control for everything else so that the only difference between our experimental groups or conditions is the one manipulated variable then we can be quite confident that it is the independent variable that is causing the change in the dependent variable. In contrast, because field studies are conducted in the real-world, the experimenter typically has less control over the environment and potential extraneous variables, and this decreases internal validity, making it less appropriate to arrive at causal conclusions.
But there is typically a trade-off between internal and external validity. External validity simply refers to the degree to which we can generalize the findings to other circumstances or settings, like the real-world environment. When internal validity is high, external validity tends to be low; and when internal validity is low, external validity tends to be high. So laboratory studies are typically low in external validity, while field studies are typically high in external validity. Since field studies are conducted in the real-world environment it is far more appropriate to generalize the findings to that real-world environment than when the research is conducted in the more artificial sterile laboratory.
Finally, there are field studies which are non-experimental in nature because nothing is manipulated. But there are also field experiments where an independent variable is manipulated in a natural setting and extraneous variables are controlled. Depending on their overall quality and the level of control of extraneous variables, such field experiments can have high external and high internal validity.
Would it surprise you learn that scientists who conduct research may withhold effective treatments from individuals with diseases? Perhaps it wouldn’t surprise you, since you may have heard of the Tuskegee Syphilis Experiment, in which treatments for syphilis were knowingly withheld from African-American participants for decades. I am sure that it would surprise you to learn the the practice of withholding treatment continues today. Multiple studies in the developing world continue to use placebo control groups in testing for cancer screenings, cancer treatments, and HIV treatments (Joffe & Miller, 2014). [1] What standards would you use to judge withholding treatment as ethical or unethical? Most importantly, how can you make sure that your study respects the human rights of your participants?
Chapter Outline
- 5.1 Research on humans
- 5.2 Specific ethical issues to consider
- 5.3 Ethics at micro, meso, and macro levels
- 5.4 The practice of science versus the uses of science
Content Advisory
This chapter discusses or mentions the following topics: unethical research that has occurred in the past against marginalized groups in America and during the Holocaust.
Researchers become a part of the group they are studying and they disclose their true identity as researchers to the group under investigation.
