8.2 The Hypothesis Test Process
LEARNING OBJECTIVES
- Describe hypothesis testing in general and in practice.
- Identify the distribution required to conduct a hypothesis test.
- Define a rare event and identify how a rare event is used in a hypothesis test.
- Define the [latex]p-\text{value}[/latex] and significance level and identify how they are used in determining the outcome of a hypothesis test.
Broadly speaking, a hypothesis test consists of the following steps:
- State the null and alternative hypotheses in terms of the population parameter being tested.
- Use the form of the alternative hypothesis to determine if the test is left-tailed, right-tailed, or two-tailed.
- Collect the sample information and identify the significance level.
- Identify the distribution required to conduct the hypothesis test. Use this distribution to calculate out the [latex]p-\text{value}[/latex].
- Compare the [latex]p-\text{value}[/latex] to the significance level and determine the outcome of the test.
- Write down a conclusion about the outcome of the test.
Step 1: State the Null and Alternative Hypotheses
In the previous section, we looked at the null and alternative hypotheses.
- The null hypothesis,[latex]H_0[/latex], is the original claim about the population parameter. The null hypothesis is a claim that a population parameter equals some value.
- The alternative hypothesis, [latex]H_a[/latex], is a contradictory claim about the population parameter. The alternative hypothesis is a claim that a population parameter is greater than, less than, or not equal to some value. The form of the alternative hypothesis depends on the wording of the hypothesis test.
Recall that these hypotheses contain opposing viewpoints, and only one of these hypotheses is true. The purpose of the hypothesis test is to determine which hypothesis is most likely true.
Step 2: Determine if the Test is Left-Tail, Right-Tail, or Two-Tail
The form of the alternative hypothesis determines if the test is left-tail, right-tail or two-tail. The alternative hypothesis is one (and only one) of the following:
- The alternative hypothesis is less than [latex](\lt)[/latex] the claim from the null hypothesis. In this case, the test is a left-tailed test. The [latex]p-\text{value}[/latex] is the area in the left tail of the corresponding distribution.
- The alternative hypothesis is greater than [latex](\gt)[/latex] the claim from the null hypothesis. In this case, the test is a right-tailed test. The [latex]p-\text{value}[/latex] is the area in the right-tail of the corresponding distribution.
- The alternative hypothesis is not equal to [latex](\neq)[/latex] the claim from the null hypothesis. In this case, the test is a two-tailed test. The [latex]p-\text{value}[/latex] is the sum of the area in both tails of the corresponding distribution.
Step 3: Collect the Sample Information and Identify the Significance Level
Sample information is used to determine which of the two hypotheses is most likely true. Collect a random sample from the population under study. In practice, the researcher collects the sample required for the test. Because collecting a sample for the purposes of learning in this book, the sample data or summary statistics are provided in the question.
The Significance Level and Rare Events
In order to determine which of the two hypotheses is true, we need to establish a significance level, denoted by [latex]\alpha[/latex], before running the test. The significance level is the cut-off value for likely versus unlikely when compared to the [latex]p-\text{value}[/latex]. But what do we mean by likely or unlikely in the context of a hypothesis test?
Suppose we make an assumption about the value of a population parameter (this assumption is the null hypothesis). We conduct the hypothesis under the assumption that the null hypothesis is true. Then, we randomly select a sample from the population. If the sample has properties that would be very unlikely to occur under the assumption the null hypothesis is true, then we would conclude that our assumption about the population is probably incorrect. Remember that our assumption is just an assumption—it is not a fact, and it may or may not be true. But the sample data we collect is real, and the information from that sample is a fact that may or may not support the assumption we make about the null hypothesis.
For example, Didi and Ali are at the birthday party of a very wealthy friend. They hurry to be first in line to grab a prize from a tall basket that they cannot see inside of because they will be blindfolded. There are [latex]200[/latex] plastic bubbles in the basket, and Didi and Ali have been told that there is only one with a [latex]\$100[/latex] bill. Didi is the first person to reach into the basket and pull out a bubble. Her bubble contains a [latex]\$100[/latex] bill. The probability of this happening is [latex]\displaystyle{\frac{1}{200}=0.005}[/latex]. Because this is such an unlikely occurrence, Ali is hoping that what the two of them were told is wrong and there are more [latex]\$100[/latex] bills in the basket. In this case, a "rare event" has occurred (Didi getting the [latex]\$100[/latex] bill), so Ali doubts the original assumption about only one [latex]\$100[/latex] bill being in the basket.
A rare event is something we consider to be unlikely to happen (i.e. the probability of that event happening is very small). This is what we are looking for in a hypothesis test. We want to determine if the sample collected for the test is a rare event (unlikely to happen) under the assumption the null hypothesis is true. To determine if the sample is a rare event, we calculate the probability (the [latex]p-\text{value}[/latex]) of the sample occurring, assuming that the null hypothesis is true. This is where the significance level comes in. We use the significance level as the "cut-off" mark for this probability. If the probability of the sample occurring is small (less than the significance level), then the sample is a "rare event" and unlikely to occur under the assumption the null hypothesis is true. In such a case, we would conclude that the original assumption that the null hypothesis is true must be incorrect, and so we would reject the null hypothesis in favour of the alternative hypothesis. If the probability of the sample occurring is not small (greater than the significance level), then the sample is not a "rare event" and is actually likely to occur under the assumption the null hypothesis is true. In this case we would conclude the original assumption that the null hypothesis is true must be correct, and so we would not reject the null hypothesis.
Remember, a rare event is an event that is unlikely to happen. But unlikely does not mean impossible. The probability of a rare event is very small (less than the significance level), which means that the chance of it happening is very small. But as long as the probability is not zero, there is still a possibility the event could happen.
In general, the significance level is a small probability. Typical significance levels used in hypothesis testing are [latex]5\%[/latex] and [latex]1\%[/latex]. As noted above, the significance level is used as the "cut-off" for likely or unlikely under the assumption the null hypothesis is true. Another way to think of the significance level is that the significance level is the probability of rejecting a null hypothesis when the null hypothesis is actually true. Rejecting a null hypothesis when it is true is called a Type I error, which is discussed in more detail in the next section.
NOTE
It is very important that the significance level is set before collecting and analyzing the sample, calculating the [latex]p-\text{value}[/latex], and running the test. Setting the significance level after the fact allows us to manipulate the test to get the outcome we want, which would invalidate the result.
Step 4: Identify the Distribution and Calculate the [latex]p-\text{value}[/latex]
In this chapter, we will look at the hypothesis test for two different population parameters: mean and proportion. The parameter we are testing helps us determine which distribution to use in the calculation of the [latex]p-\text{value}[/latex].
Distribution for a Hypothesis Test on a Population Mean
If the hypothesis test is on a population mean, we use the distribution of the sample means in the hypothesis test. As we learned previously, the distribution of the sample means follows a normal distribution if the population the sample is taken from is normal or if the sample size is large enough ([latex]n\geq 30[/latex]). For a hypothesis test on a population mean we use a normal distribution when the population standard deviation is known or a [latex]t[/latex]-distribution when the population standard deviation is unknown.
When we perform a hypothesis test of a single population mean [latex]\mu[/latex] and the population standard deviation is known, we take a simple random sample from the population. We use a normal distribution, assuming the population is normal or the sample size is large enough ([latex]n\geq 30[/latex]). The [latex]z[/latex]-score we need is the [latex]z[/latex]-score from the distribution of the sample means: [latex]\displaystyle{z=\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}}[/latex].
When we perform a hypothesis test of a single population mean [latex]\mu[/latex] and the population standard deviation is unknown, we take a simple random sample from the population. We use a [latex]t[/latex]-distribution, assuming the population is normal or the sample size is large enough ([latex]n\geq 30[/latex]). We use the sample standard deviation to approximate the population standard deviation. The [latex]t[/latex]-score we need is: [latex]\displaystyle{t=\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}}[/latex].
Distribution for a Hypothesis Test on a Population Proportion
If the hypothesis test is on a population proportion, we use the distribution of the sample proportions in the hypothesis test. As we learned previously, the distribution of the sample proportions follows a normal distribution if [latex]n\times p\geq 5[/latex] and [latex]n\times(1-p)\geq 5[/latex] or a binomial distribution if one of [latex]n\times p\lt 5[/latex] or [latex]n\times(1-p)\lt 5[/latex]. For a hypothesis test on a population proportion, we use either a normal distribution or a binomial distribution, depending on which of the above conditions is met.
When we perform a hypothesis test of a single population proportion [latex]p[/latex], we take a simple random sample from the population. We use a normal distribution when [latex]n\times p\geq 5[/latex] and [latex]n\times(1-p)\geq 5[/latex]. In this case, the [latex]z[/latex]-score we need is the [latex]z[/latex]-score from the distribution of the sample proportions: [latex]\displaystyle{z=\sqrt{\frac{p\times(1-p)}{n}}}[/latex]. Otherwise, we use a binomial distribution when one of [latex]n\times p\lt 5[/latex] or [latex]n\times(1-p)\lt 5[/latex].
Calculating the [latex]p-\text{value}[/latex]
Once we know which distribution to use, we calculate the [latex]p-\text{value}[/latex] for the test. The [latex]p-\text{value}[/latex] is the actual probability of getting the selected sample under the assumption the null hypothesis is true. The [latex]p-\text{value}[/latex] is the probability that, if the null hypothesis is true, the results from another randomly selected sample will be as extreme or more extreme as the results obtained from the given sample.
The [latex]p-\text{value}[/latex] is the area in the corresponding tail of the distribution based on the form of the alternative hypothesis:
- If the alternative hypothesis is less than [latex](\lt)[/latex] the claim from the null hypothesis, the [latex]p-\text{value}[/latex] is the area in the left-tail of the corresponding distribution.
- If the alternative hypothesis is greater than [latex](\gt)[/latex] the claim from the null hypothesis, the [latex]p-\text{value}[/latex] is the area in the right-tail of the corresponding distribution.
- If the alternative hypothesis is not equal to [latex](\neq)[/latex] the claim from the null hypothesis, the [latex]p-\text{value}[/latex] is the sum of the area in both tails of the corresponding distribution.
We calculate out the [latex]p-\text{value}[/latex] using the techniques learned in previous chapters about calculating probabilities in the normal distribution, [latex]t[/latex]-distribution, or binomial distribution. Once we have calculated the [latex]p-\text{value}[/latex], we use the [latex]p-\text{value}[/latex] to determine the outcome of the test. A large [latex]p-\text{value}[/latex] (greater than the significance level) calculated from the sample data indicates that we should not reject the null hypothesis. A small [latex]p-\text{value}[/latex] (less than the significance level) suggests strong evidence against the null hypothesis, and we would reject the null hypothesis if the evidence is strongly against it.
EXAMPLE
The customers of a local bakery claim that the height of the bakery's bread is, on average, [latex]15[/latex] cm. The baker believes his customers are wrong and that the average height of the bread is more than [latex]15[/latex] cm. To persuade his customers that he is right, the baker decides to do a hypothesis test. He bakes [latex]10[/latex] loaves of bread. The mean height of the sample loaves is [latex]17[/latex] cm. The baker knows from baking hundreds of loaves of bread that the standard deviation for the height is [latex]1[/latex] cm, and the distribution of the heights is normal. Based on this sample, who is right: the customers or the baker?
Solution
Here, the population under study is the height of the loaves of bread, and [latex]\mu[/latex] is the average height of the loaves of bread.
The customers' claim is the null hypothesis: [latex]\mu=15[/latex]. The alternative hypothesis is the baker's claim: [latex]\mu\gt 15[/latex]. In mathematical notation, the hypothesis are:
[latex]\begin{eqnarray*}H_0:&&\mu=15\text{ cm}\\H_a:&&\mu\gt 15\text{ cm}\end{eqnarray*}[/latex]
Because the population standard deviation is known ([latex]\sigma=1[/latex]), the distribution we would use is the normal distribution.
Suppose the null hypothesis is true. That is, suppose [latex]\mu=15[/latex]. Under this assumption, we have to ask if the sample mean of [latex]17[/latex] is likely or unlikely to occur. The hypothesis test works by asking the question of how unlikely is this sample mean if the null hypothesis is true. The graph shows how far out the sample mean is on the normal curve. The [latex]p-\text{value}[/latex] is the probability that, if we took another sample of size [latex]10[/latex], any other sample mean would fall at least as far out as [latex]17[/latex] cm.
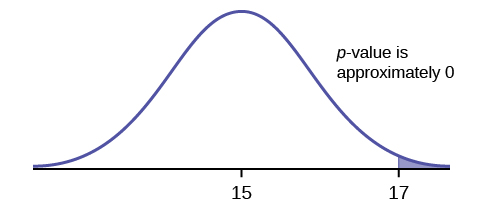
The [latex]p-\text{value}[/latex] is the probability that a sample mean is the same or greater than [latex]17[/latex] cm when the population mean is, in fact, [latex]15[/latex] cm. We can calculate this probability using the normal distribution for sample means. In fact, we are calculating the probability that in a sample of size [latex]10[/latex], the sample mean is greater than [latex]17[/latex]. We learned how to calculate this type of probability when we learned about the sampling distribution of the sample mean:
| Function | 1-norm.dist |
|---|---|
| Field 1 | 17 |
| Field 2 | 15 |
| Field 3 | 1/sqrt(10) |
| Field 4 | true |
| Answer | 0.0000000001 |
So [latex]p-\text{value}=0.0000000001[/latex], which tells us the probability of selecting a sample of size [latex]10[/latex] and getting a sample mean greater than [latex]17[/latex] is [latex]0.0000000001[/latex] under the assumption that the null hypothesis is true ([latex]\mu=15[/latex]). This is a very, very small probability, which tells us that a sample mean of [latex]17[/latex] is unlikely to happen if the population mean is [latex]15[/latex] cm. Because the sample mean of [latex]17[/latex] is so unlikely (meaning it is not happening by chance alone), we conclude that the assumption that the mean is [latex]15[/latex] cm is wrong. That is, the evidence provided by the sample is strongly against the claim of the null hypothesis. So, we reject the null hypothesis in favour of the alternative hypothesis. That is, based on the test, we believe the null hypothesis is false, and the alternative hypothesis is true. So there is enough evidence to suggest that the average height of the loaves of bread is greater than [latex]15[/latex] cm.
TRY IT
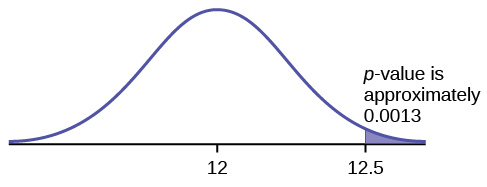
A normal distribution has a standard deviation of [latex]1[/latex]. The original claim is that the mean of the distribution is [latex]12[/latex]. An alternative claim is that the mean is greater than [latex]12[/latex]. The hypotheses are:
[latex]\begin{eqnarray*}H_0:&&\mu=12\\H_a:&&\mu\gt 12\end{eqnarray*}[/latex]
In a sample of [latex]36[/latex], the sample mean is [latex]12.5.[/latex] Calculate the [latex]p-\text{value}[/latex].
Click to see Solution
| Function | 1-norm.dist |
|---|---|
| Field 1 | 12.5 |
| Field 2 | 12 |
| Field 3 | 1/sqrt(36) |
| Field 4 | true |
| Answer | 0.0013 |
[latex]p-\text{value}=0.0013[/latex]
Step 5: The Outcome of the Test
The outcome of the test about whether to reject or not reject the null hypothesis is based on comparing the [latex]p-\text{value}[/latex] to the significance level [latex]\alpha[/latex]. Recall that the significance level is the cut-off value for likely versus unlikely when compared to the [latex]p-\text{value}[/latex]. When the [latex]p-\text{value}[/latex] is greater than the significance level, the sample is likely to occur under the assumption the null hypothesis is true, and so we would fail to reject the null hypothesis. When the [latex]p-\text{value}[/latex] is less than or equal to the significance level, the sample is unlikely to occur under the assumption the null hypothesis is true, and so we would reject the null hypothesis in favour of the alternative hypothesis.
When we make a decision to reject or not reject H0, do as follows:
- If [latex]p-\text{value}\leq\alpha[/latex], reject [latex]H_0[/latex] in favour of [latex]H_a[/latex].
- The results of the sample data are significant. There is sufficient evidence to conclude that the null hypothesis [latex]H_0[/latex] is an incorrect belief and that the alternative hypothesis [latex]H_a[/latex] is most likely correct.
- If [latex]p-\text{value}\gt\alpha[/latex], do not reject [latex]H_0[/latex].
- The results of the sample data are not significant. There is not sufficient evidence to conclude that the alternative hypothesis [latex]H_a[/latex] may be correct.
When we "do not reject [latex]H_0[/latex]," it does not mean that we should believe that [latex]H_0[/latex] is true. It simply means that the sample data have failed to provide sufficient evidence to cast serious doubt about the truthfulness of [latex]H_0[/latex].
Step 6: Conclusion
After comparing the [latex]p-\text{value}[/latex] and significance level to determine which hypothesis is most likely true, write a thoughtful conclusion about the hypotheses in terms of the given problem.
TRY IT
A genetics lab claims its product can increase the likelihood a pregnancy will result in a boy being born. Statisticians want to test this claim. Suppose the hypotheses are
[latex]\begin{eqnarray*}H_0:&&p=50\%\\H_a:&&p\gt 50\%\end{eqnarray*}[/latex]
After conducting the hypothesis test, [latex]p-\text{value}=0.025[/latex]. If the significance level is [latex]1\%[/latex], what is the conclusion of the test?
Click to see Solution
Because the [latex]p-\text{value}[/latex] is greater than the significance level ([latex]p-\text{value}=0.025\gt 0.01=\alpha[/latex]), we do not reject the null hypothesis. There is not enough evidence to support the lab's stated claim that their procedures improve the chances of a boy being born.
Video: "Simple hypothesis testing | Probability and Statistics | Khan Academy" by Khan Academy [6:25] is licensed under the Standard YouTube License.Transcript and closed captions available on YouTube.
Exercises
- Which distributions can you use for hypothesis testing for this chapter?
Click to see Answer
normal, [latex]t[/latex], binomial
- Which distribution do you use when you are testing a population mean and the standard deviation is known? Assume the sample size is large.
Click to see Answer
normal
- Which distribution do you use when the standard deviation is not known, and you are testing one population mean? Assume the sample size is large.
Click to see Answer
[latex]t[/latex]
- A population mean is [latex]13[/latex]. The sample mean is [latex]12.8[/latex], and the sample standard deviation is [latex]2[/latex]. The sample size is [latex]20[/latex]. What distribution should you use to perform a hypothesis test? Assume the underlying population is normal.
Click to see Answer
[latex]t[/latex]
- A population has a mean is [latex]25[/latex] and a standard deviation of [latex]5[/latex]. The sample mean is [latex]24[/latex], and the sample size is [latex]108[/latex]. What distribution should you use to perform a hypothesis test?
Click to see Answer
normal
- It is thought that [latex]42\%[/latex] of respondents in a taste test would prefer Brand A. In a particular test of [latex]100[/latex] people, [latex]39\%[/latex] preferred Brand A. What distribution should you use to perform a hypothesis test?
Click to see Answer
normal
- You are performing a hypothesis test of a single population proportion. What must be true about the quantities of [latex]n\times p[/latex] and [latex]n\times(1-p)[/latex] in order to use the normal distribution?
Click to see Answer
Both quantities must be greater than or equal to 5.
- You are performing a hypothesis test of a single population proportion. You find out that [latex]n\times p[/latex] is less than five. What must you do to be able to perform a valid hypothesis test?
Click to see Answer
Use the binomial distribution.
- When do you reject the null hypothesis?
Click to see Answer
When the [latex]p-\text{value}[/latex] is less than or equal to the significance level.
- The probability of winning the grand prize at a particular carnival game is [latex]0.5\%[/latex]. Is the outcome of winning very likely or very unlikely?
Click to see Answer
very unlikely
- The probability of winning the grand prize at a particular carnival game is [latex]0.5\%[/latex]. Michele wins the grand prize. Is this considered a rare or common event? Why?
Click to see Answer
Rare because the probability of the event happening is very small.
- What should you do when [latex]\alpha\gt p-\text{value}[/latex]?
Click to see Answer
Reject the null hypothesis.
- What should you do if [latex]\alpha=p-\text{value}[/latex]?
Click to see Answer
Reject the null hypothesis.
- If you do not reject the null hypothesis, then it must be true. Is this statement correct? State why or why not in complete sentences.
Click to see Answer
Incorrect because it is possible the test does not reject a false null hypothesis.
- Assume [latex]H_0:\mu=9[/latex] and [latex]H_a:\mu\lt 9[/latex]. Is this a left-tailed, right-tailed, or two-tailed test?
Click to see Answer
left-tailed
- Assume [latex]H_0:\mu=6[/latex] and [latex]H_a:\mu\gt 6[/latex]. Is this a left-tailed, right-tailed, or two-tailed test?
Click to see Answer
right-tailed
- Assume [latex]H_0:p=25\%[/latex] and [latex]H_a:p\neq 25\%[/latex]. Is this a left-tailed, right-tailed, or two-tailed test?
Click to see Answer
two-tailed
- Assume the null hypothesis states that the mean is equal to [latex]88[/latex]. The alternative hypothesis states that the mean is not equal to [latex]88[/latex]. Is this a left-tailed, right-tailed, or two-tailed test?
Click to see Answer
two-tailed
"8.4 Distributions Required for a Hypothesis Test", "8.5 Rare Events, The Sample, Decision, and Conclusion" and “8.9 Exercises” from Introduction to Statistics by Valerie Watts is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License, except where otherwise noted.
