12.6 Standard Error of the Estimate
LEARNING OBJECTIVES
- Calculate and interpret the standard error of the estimate.
The difference between the actual value of the dependent variable [latex]y[/latex] (in the sample data) and the predicted value of the dependent variable [latex]\hat{y}[/latex] obtained from the linear regression equation is called the error or residual.
[latex]\begin{eqnarray*}\text{Error}&=&\text{Actual Value}-\text{Predicted Value}\end{eqnarray*}[/latex]
Graphically, the absolute value of the error is the vertical distance between the actual value of [latex]y[/latex] (the point on the scatter diagram) and the predicted value of [latex]\hat{y}[/latex] (the point on the linear regression line). In other words, the absolute value of the error measures the vertical distance between the actual data point and the line.
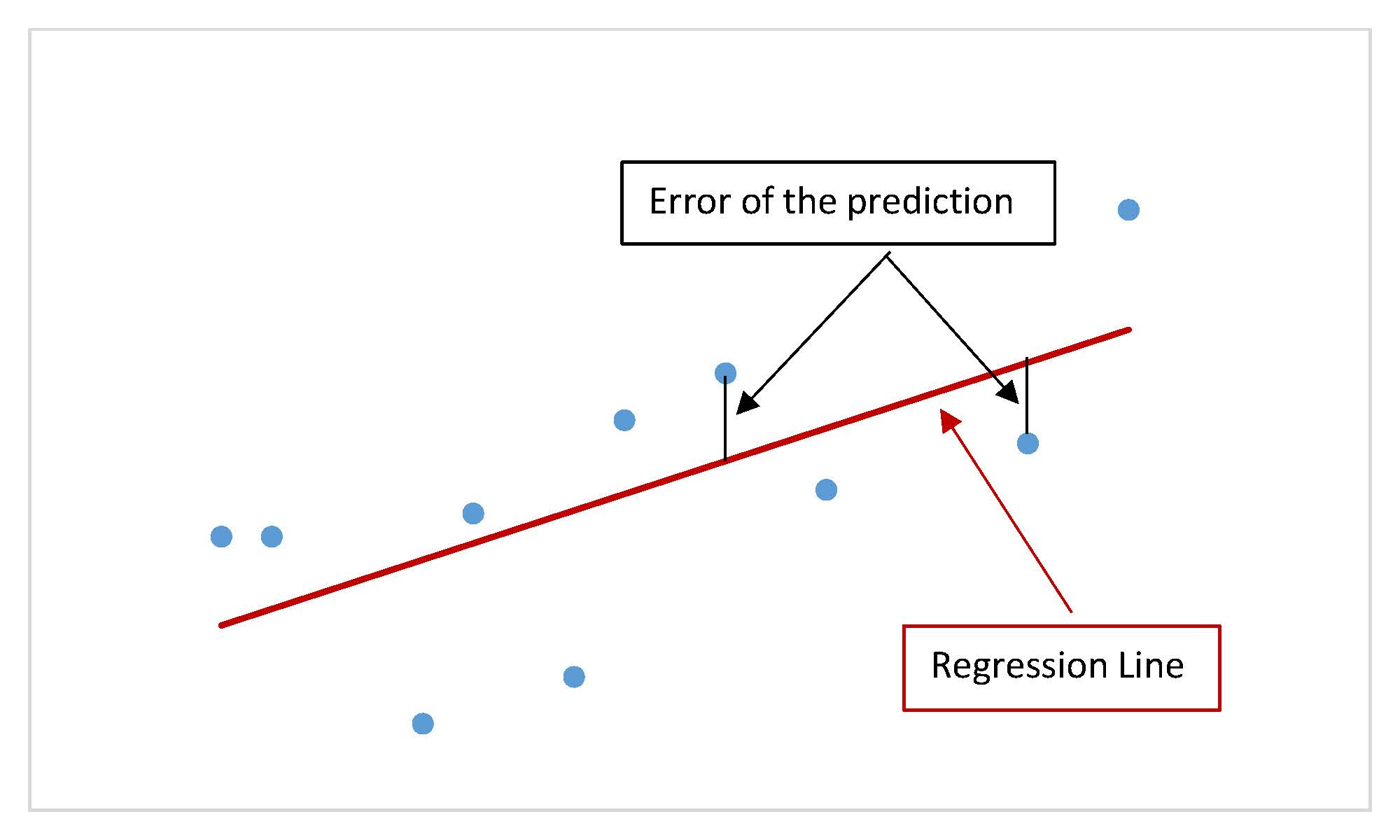
The standard error of the estimate, denoted [latex]s_e[/latex], is a measure of the standard deviation of the errors in a regression model. The standard error of the estimate is a measure of the average deviation or dispersion of the points on the scatter diagram around the line of best fit. The standard error of the estimate for the linear regression model is analogous to the standard deviation for a set of points, but instead of measuring the average distance from the mean, we are measuring the average distance from the regression line. Graphically, the standard error of the estimate measures the average vertical distance (the absolute value of the errors) between the points on the scatter diagram and the regression line.
When the points on the scatter diagram are close to the regression line, the errors are small, and so the average of the dispersion of the points around the line will be small. In this case, the value of the standard error of the estimate will be relatively small, which reflects the fact that there is little variation between the actual data points (the points on the scatter diagram) and the linear regression model. This implies that the linear regression model is a good fit for the data, and predictions made with the linear regression model will be fairly accurate.
Conversely, when the points on the scatter diagram are widely dispersed around the regression line, the errors are large, and so the average dispersion of the points around the line will be large. In this case, the value of the standard error of the estimate will be large, which reflects the greater dispersion between the actual data points and the linear regression model. This implies that the linear regression model is not a good fit for the data, and predictions made with the linear regression model will be inaccurate.
The value of [latex]s_e[/latex] tells us, on average, how much the dependent variable differs from the regression line based on the independent variable. When interpreting the standard error of the estimate, remember to be specific to the question, using the actual names of the dependent and independent variables, and include appropriate units. The units of the standard error of the estimate are the same as the units of the dependent variable.
Although there is a formula to calculate the value of the standard error of the estimate, we will calculate the standard error of the estimate using the built-in function in Excel.
CALCULATING THE STANDARD ERROR OF THE ESTIMATE IN EXCEL
To calculate the standard error of the estimate, use the steyx(array for y's, array for x's) function.
- For array for y's, enter the cell array containing the dependent variable [latex]y[/latex] data.
- For array for x's, enter the cell array containing the independent variable [latex]x[/latex] data.
Visit the Microsoft page for more information about the steyx function.
NOTE
The order in which the data is entered into the steyx function is important. The data for the dependent variable is entered in the first array, and the data for the independent variable is entered in the second array. The output from the steyx function will be different when the order of the inputs is switched.
EXAMPLE
A statistics professor wants to study the relationship between a student's score on the third exam in the course and their final exam score. The professor took a random sample of [latex]11[/latex] students and recorded their third exam score (out of [latex]80[/latex]) and their final exam score (out of [latex]200[/latex]). The results are recorded in the table below. The professor wants to develop a linear regression model to predict a student's final exam score from the third exam score.
| Student | Third Exam Score | Final Exam Score |
|---|---|---|
| 1 | 65 | 175 |
| 2 | 67 | 133 |
| 3 | 71 | 185 |
| 4 | 71 | 163 |
| 5 | 66 | 126 |
| 6 | 75 | 198 |
| 7 | 67 | 153 |
| 8 | 70 | 163 |
| 9 | 71 | 159 |
| 10 | 69 | 151 |
| 11 | 69 | 159 |
Previously, we found the line-of-best-fit [latex]\hat{y}=-173.51+4.83x[/latex] where [latex]x[/latex] is the third exam score and [latex]\hat{y}[/latex] is the (predicted) final exam score.
- Find the standard error of the estimate.
- Interpret the standard error of the estimate found in part 1.
Solution
- Enter the data into an Excel spreadsheet. For this example, suppose we entered the data (without the column headings) so that the student column is in column A from A1 to A11, the third exam score is in column B from B1 to B11, and the final exam score is in column C from C1 to C11.
Function steyx Field 1 C1:C11 Field 2 B1:B11 Answer 16.41 The value of the standard error of the estimate is [latex]s_e=16.41[/latex].
- On average, the final exam score differs by [latex]16.41[/latex] points from the regression line based on the third exam score.
TRY IT
SCUBA divers have maximum dive times they cannot exceed when going to different depths. The data in the table below shows different depths with the maximum dive times in minutes. Previously, we found the regression line to predict the maximum dive time from depth.
| Depth (in feet) | Maximum Dive Time (in minutes) |
|---|---|
| 50 | 80 |
| 60 | 55 |
| 70 | 45 |
| 80 | 35 |
| 90 | 25 |
| 100 | 22 |
- Find the standard error of the estimate.
- Interpret the standard error of the estimate found in part 1.
Click to see Solution
- [latex]\displaystyle{s_e=6.53}[/latex].
- On average, the maximum dive time differs by [latex]6.53[/latex] minutes from the regression line based on depth.
Exercises
- In a random sample of ten professional athletes, the number of endorsements the player has and the amount of money (in millions of dollars) the player earns are recorded in the table below. (Note: for identification of the independent and dependent variables, refer back to Question 4 in Section 12.4.)
Player Number of Endorsements Money Earned (in millions) 1 0 2 2 3 8 3 2 7 4 1 3 5 5 13 6 5 12 7 4 9 8 3 9 9 0 3 10 4 10 - Calculate the standard error of the estimate.
- Interpret the standard error of the estimate.
Click to see Answer
- [latex]0.8363[/latex]
- On average, the money earned by the athlete differs by [latex]\$836,300[/latex] from the regression line based on the number of endorsements.
- The table below gives the percentage of workers who are paid hourly rates for the years 1979 to 1992. (Note: for identification of the independent and dependent variables, refer back to Question 7 in Section 12.2.)
Year Percent of Workers Paid Hourly Rates 1979 61.2 1980 60.7 1981 61.3 1982 61.3 1983 61.8 1984 61.7 1985 61.8 1986 62.0 1987 62.7 1990 62.8 1992 62.9 - Find the standard error of the estimate.
- Interpret the standard error of the estimate.
Click to see Answer
- [latex]0.2473[/latex]
- On average, the percent of workers paid an hourly rate differs by [latex]0.2473\%[/latex] from the regression line based on year.
- The table below contains real data for the first two decades of AIDS cases. (Note: for identification of the independent and dependent variables, refer back to Question 1 in Section 12.2.)
Year Number of AIDS Cases 1981 319 1982 1,170 1983 3,076 1984 6,240 1985 11,776 1986 19,032 1987 28,564 1988 35,447 1989 42,674 1990 48,634 1991 59,660 1992 78,530 1993 78,834 1994 71,874 1995 68,505 1996 59,347 1997 47,149 1998 38,393 1999 25,174 2000 25,522 2001 25,643 2002 26,464 - Calculate the standard error of the estimate.
- Interpret the standard error of the estimate.
Click to see Answer
- [latex]22,936.69[/latex]
- On average, the number of AIDS cases differs by [latex]22,936.69[/latex] from the regression line based on the year.
- Recently, the annual number of driver deaths per [latex]100,000[/latex] for the selected age groups was as shown in the table below. (Note: for identification of the independent and dependent variables, refer back to Question 8 in Section 12.2.)
Age Number of Driver Deaths per [latex]100,000[/latex] 17.5 38 22 36 29.5 24 44.5 20 64.5 18 80 28 - Find the standard error of the estimate.
- Interpret the standard error of the estimate.
Click to see Answer
- [latex]7.533[/latex]
- On average, the number of driver deaths per [latex]100,000[/latex] differs by [latex]7.533[/latex] from the regression line based on age.
- The table below shows the life expectancy for an individual born in the United States in certain years. (Note: for identification of the independent and dependent variables, refer back to Question 9 in Section 12.2.)
Year of Birth Life Expectancy 1930 59.7 1940 62.9 1950 70.2 1965 69.7 1973 71.4 1982 74.5 1987 75 1992 75.7 2010 78.7 - Calculate the standard error of the estimate.
- Interpret the standard error of the estimate.
Click to see Answer
- [latex]1.8202[/latex] years
- On average, the life expectancy differs by [latex]1.8202[/latex] years from the regression line based on the year.
- The height (sidewalk to roof) of notable tall buildings in America is compared to the number of stories of the building (beginning at street level). (Note: for identification of the independent and dependent variables, refer back to Question 10 in Section 12.2.)
Height (in feet) Number of Stories 1,050 57 428 28 362 26 529 40 790 60 401 22 380 38 1,454 110 1,127 100 700 46 - Calculate the standard error of the estimate.
- Interpret the standard error of the estimate
Click to see Answer
- [latex]132.76[/latex] feet
- On average, the height differs by [latex]132.76[/latex] feet from the regression line based on the number of stories.
- The following table shows data on average per capita wine consumption and heart disease rate in a random sample of 10 countries. (Note: for identification of the independent and dependent variables, refer back to Question 11 in Section 12.2.)
Per Capita Yearly Wine Consumption in Liters Per Capita Death from Heart Disease 2.5 221 3.9 167 2.9 131 2.4 191 2.9 220 0.8 297 9.1 71 2.7 172 0.8 211 0.7 300 - Calculate the standard error of the estimate.
- Interpret the standard error of the estimate.
Click to see Answer
- [latex]40.563[/latex]
- On average, the number of deaths from heart disease differs by [latex]40.563[/latex] from the regression line based on yearly wine consumption.
- The following table consists of one student athlete’s time (in minutes) to swim 2000 meters and the student’s heart rate (beats per minute) after swimming on a random sample of 10 days. (Note: for identification of the independent and dependent variables, refer back to Question 12 in Section 12.2.)
Swim Time Heart Rate 34.12 144 35.72 152 34.72 124 34.05 140 34.13 152 35.73 146 36.17 128 35.57 136 35.37 144 35.57 148 - Calculate the standard error of the estimate.
- Interpret the standard error of the estimate.
Click to see Answer
- [latex]10.024[/latex] bpm
- On average, the heart rate differs by [latex]10.024[/latex] bpm from the regression line based on swim time.
"12.7 Standard Error of the Estimate" and “12.8 Exercises” from Introduction to Statistics by Valerie Watts is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License, except where otherwise noted.
