Sally Jackson
[1]The web, or Worldwide Web as it was first known, is all of the services and content that a person can access using a web browser like Google Chrome, Firefox, Internet Explorer, Safari, or any of a number of less familiar products. My task in this chapter is to explore how critical thinkers use the web, but it is impossible to do this without also speculating about how the existence of the web may change what it means to think critically. Since the late 19th Century much of the world has gone through two media revolutions: from a media environment dominated by print to an electronic broadcast environment, and from an electronic broadcast environment to a digital networked environment (Finneman, 2011). The sum of available communication media at any point in time is sometimes called a “media ecology” (Postman, 2000), and media theorists who think in ecological terms believe that social practices, especially communication practices, reshape themselves to adapt to a change in environment of this kind. The central insight of media ecology has been that new technologies do not just add to prior technologies. They change the environment so that even older technologies get used differently. Habits formed under one configuration of communication technologies may or may not make sense when the configuration changes.
There is no guarantee that the tools and skills long associated with critical thinking will transition smoothly from one media ecology to another. It is altogether possible that the rise of a new media ecology may require not just new tools and new skills but also abandonment of some of the habits and assumptions associated with centuries of reliance on information appearing in print. A thoughtful discussion of how a critical thinker uses the web must be open to these possibilities.
I begin by offering a brief overview of certain features of the web that are especially significant for critical thinking. I then turn to a core set of web-related practices that demand either new critical thinking skills or new perspectives on critical thinking. Finally, I return to the speculation raised briefly above, that critical thinking itself may need to be reconceptualized in terms that are less tightly tethered to individual thinkers, and more tied to social arrangements in which societies delegate some responsibility for critical thinking to institutions, to specialized professions, and even to machines.
1 The web as information environment
The Internet (not the web) began in the 1960s as a US Defense Department project. First used to connect major computing resources across the US (Abbate, 1999), the Internet expanded rapidly as a tool for human communication. By the mid-1980s Internet services were available (via telephone infrastructure) to ordinary households in many countries, though these services bore little resemblance to what soon developed. The most common Internet application at that time was email, presented as a screenful of text navigated through keyboard interaction with a menu of options.
Today’s web is a global software system of platforms, applications, and data operating on the Internet and growing autonomously in interaction with billions of human users. Its core technology was invented by Tim Berners-Lee in 1989 and successfully prototyped in 1990 at CERN. Like email, the web was first presented to users as text menus on computer screens. But graphical web browsers appeared a few years later (starting with Mosaic, created by the National Center for Supercomputing Applications in 1992), making the web accessible to the general public. By the time the web was invented, a considerable amount of index-type material was already available over the Internet, sufficient to allow people to search online for information about offline resources (such as library collections or business directories). The rise of the web stimulated a burst of activity to digitize vast stores of print information that could be both located and consumed online, as well as a variety of service transactions performed entirely online.
From its beginnings, the web was designed to ingest new content from any of its endpoints (users and their devices), but it took more than a decade for this idea to take hold widely enough to expose the fundamentally participatory nature of the web. The web is not (and never was) just an online repository of information, but a platform for transactions of all kinds, including communication. At the time of this writing, the web has existed for less than 30 years, but it has infiltrated virtually every important domain of human experience, fundamentally altering many practices (such as news production and consumption) that are central to any discussion of critical thinking.
Both the design ideas behind the web and the technical components built from these ideas have consequences for critical thinking. From these ideas and the technologies they have inspired, three characteristics have emerged as especially relevant: accumulation of unreviewed content; algorithmic search; and personalization of the information environment.
1.1 Unreviewed content
The web was invented to allow for collaborative creation of content by an arbitrarily large set of creators. As explained by the web’s inventor (Tim Berners-Lee, 1996), “The intent was that this space should span . . . from high value carefully checked and designed material, to off-the-cuff ideas which make sense only to a few people and may never be read again.” Unreviewed content is a design feature of the web, not an unintended consequence.
For a very short time, the computer programming skills needed for publishing content to the web limited the number of people who could contribute, and during this short period, most individuals experienced the web simply as content available for consuming. But programmers, including many self-taught amateurs, quickly began inventing platforms that would allow other people without programming skills to contribute content, whether as personal “home pages,” as sites for groupwork, or as some other kind of content. Some platforms emerged to support large collaborative writing projects—highly imaginative experiments in collaborative writing as well as visionary knowledge repositories.
The speed with which all of this occurred was dizzying. The wave of participatory web applications invented in the 2000s, known collectively as social media, included social networking platforms (such as Facebook, invented in 2004), blog platforms (such as WordPress, available as a service since 2003), a massively successful microblogging platform (Twitter, invented in 2006), plus several platforms for rapid dissemination of image data, several platforms for distributing user-made video, platforms for citizen science and citizen journalism, book publishing platforms, and much more. These were not the first participatory media, but their clustered appearance created a sense that the web itself was changing (from “Web 1.0” to “Web 2.0” as the shift was described in industry news).
The significance of social media for critical thinking is mostly in the way they have affected the status of published information, including what is found in “old media.” Print technologies and broadcast technologies both restricted the ability to publish to those who controlled production and distribution resources. A certain level of thoughtfulness was a natural practical consequence of the costs and effort associated with print and broadcast media. The web too is dependent on material technologies, and building the web has required massive worldwide investment. But for the content producer, there is no cost other than one’s own labor for publishing an idea on the web; publishing is an immediate result of interacting with social media. Information on the web can be completely unreviewed, and it can also be published with little or no information on its own provenance.
One challenge this presents to critical thinking seems rather obvious: Much of the information a person can find on the web has no serious claim on anyone’s attention or belief, and quite a lot of it is false. Bad information can circulate easily on the web, and it is not always easy to track down its source. But there is a second risk for critical thinking: the categorical rejection of information that does not satisfy the standards associated with earlier media ecologies. Unreviewed content is not necessarily poor quality content, and it is a mistake to reject it categorically.
An instructive example is Wikipedia, the free online encyclopedia launched by Jimmy Wales in 2007, during the great wave of social media inventions. The premise behind Wikipedia is that allowing everyone to contribute and everyone to edit will produce high quality information that can expand without limit (in a way that print encyclopedias cannot). The fact that an article can be written or edited by anyone in the world was regarded at first as a fatal flaw. Experience has shown that for topics that matter, communities form around curating the content of Wikipedia, reversing edits that are outright errors and engaging in lengthy behind-the-scenes argumentation over content that is in any way controversial. Wikipedia has evolved a style, a “neutral point of view” that handles unresolved controversy within an editing group by presenting arguments without arguing.
As Wikipedia has developed, it has acquired some of the attributes of review, but reviewing means something different for Wikipedia than for a traditional publication process. Nothing prevents an author from publishing in Wikipedia, but scrutiny follows immediately and does not end until an article arrives at a form that no one sees a need to edit further. Articles do not have authors; to see who participated in any way requires going behind the article (to its revision history or to its discussion pages), and even then the authors’ identities and credentials are rarely available. It is a participant-administered system in which abuse is controlled only through tireless vigilance and enforcement of evidence standards.
For sensibilities trained by print and broadcast eras, unreviewed content is immediately suspect. In a desire for simple rules to guide reliance on the web, one might suggest that users rely only on trusted websites, rejecting information that cannot pass tests for conventional legitimacy. This would be a mistake, though. The web allows for accumulation of new kinds of information, information that in earlier media configurations would not have been considered worth saving, let alone publishing. One important category of such information is individual reports of experience. These range from satisfaction ratings that are central to the business models of e-commerce platforms like eBay, to observational data collected by citizen scientists, to self-observation related to health and medicine. To take just health as an example, no sensible person relies on web discussions to learn whether the rash on the bottom of her foot is shingles, but if (having been properly treated by a doctor) that person needs to know how to get along for a week or two with shingles blisters on the bottom of her foot, there is nothing quite as useful as the ideas of the very small fraction of other humans who have actually had this experience.
A critical thinker will certainly not believe everything found on the web, but it is equally uncritical to reject all unreviewed content out of hand. Distinguishing between experience and expertise as bases for knowledge and appreciating when content gains credibility through some form of expert review are new skills needed by everyone who uses the web, a point to which I return in the second section of this chapter.
1.2 Algorithmic search
In the context of the web, an algorithm is a bit of computer programming that performs some task. Algorithms can cooperate with other algorithms, especially if one algorithm can take another’s output as its own input. Algorithmic search means a search conducted by a computer program in response to a user’s query—the leading example being a Google search. The user enters a query, and Google’s army of algorithms combine this user input with both stored and transactional data (such as the user’s current location) to decide what the user is looking for and deliver a list of results. Google maintains a good general explanation (https://www.google.com/search/howsearchworks/) of the many individual algorithms that are required for its search engine to cater to our needs. What a user experiences as a simple query/response transaction is a set of powerful tools that maintain comprehensive, continuously updated index information that can be combined with rapidly improving methods for inferring users’ intentions and calculating which of the items in the index are most likely to satisfy the needs of particular users.
In the very early days of the web, efforts were made to provide guides to the web modeled on a library catalogue, with hierarchies of categories such as “Art” and “Travel,” through which a user could browse. Yahoo! started out in this fashion, trying to curate web pages using methods that had worked well for physical collections of books and other objects. All such efforts at curation were immediately and completely obsolesced by the invention of search engines. Without algorithmic search, most of the content on the web would be undiscoverable.
In principle, everything in a physical library can be found by simply being thorough, moving along item by item and inspecting each one. The same is not true for web content, because an item on the web has no fixed physical location in a space navigable by a human. But algorithmic search is not just a virtualized form of library search. It is a different kind of search based on different principles.
To get a sense of the difference between physical browsing and searching, imagine a library where, as you walk through the bookstacks, certain titles push themselves out, some pushing out just a little and others pushing themselves all the way out so they cannot be ignored. Imagine further that these pushy books recede until they are flush with their shelf-mates when you have walked on, and that when your colleague walks through the same stacks, different books push out. Imagine still further that your actions, and those of your colleague, affect future pushing-out. If you or your colleague remove a book from the shelf, an invisible mechanism records that action. If you finger a book but do not remove it from the shelf, that is recorded too. A book that pushes out over and over without being selected becomes less pushy, and what is more, other books that share any commonality with that book also become less pushy.
Information retrieval tools of the past relied on the codable characteristics of the items to be located (such as topic, author, date of publication, and so on). Web search differs in relying on social and relational data as well. Algorithms deliver information in response to queries, but they also continuously collect data on what is being searched for and how people react to what is delivered. This means that the curation of the information environment is delegated to computer programs whose outputs are not controlled even by the programmers. A new area of scholarly inquiry has emerged around this fact known as algorithm studies. Critical algorithm studies (e.g., Introna, 2006; Introna & Nissenbaum, 2000) problematize the delegation of so many matters of importance to systems that are subject to no governance by their users. For example, scholars working on algorithms have already shown how the behaviour of an algorithm like Google’s PageRank can be shaped to reproduce biases and prejudices present within a population of users (Noble, 2013).
For teaching critical thinking there is very little point in focusing on any particular algorithm, such as Google’s PageRank algorithm or Facebook’s news feed algorithm. The instructional goal should be creating an intuitive foundation for reasoning about algorithms in general, including those that will emerge in the future. The ones that matter most (MacCormick, 2012) are changing constantly as their programmers try to make them better in some sense.
Any individual algorithm should be examined and critiqued in such a way as to focus on the more abstract point that algorithmic search and many other algorithms that control other web business introduce their own poorly understood influence on the information environment. Section 2 offers some suggestions for how to apply this abstract lesson both to search strategies and to the management of one’s overall relationship with the web.
1.3 Personalization
Mass media deliver the same message content to all who choose to pay attention. The web takes note of its interactional partner and personalizes information in myriad ways. Users seek this as a convenience, and it is widely regarded by web developers as a competitive advantage for any product or service offered on the web. In the early days of the web, personalization meant that users could affect the content displayed by entering data, such as a bit of personal information or as a choice from a menu of options. Early online courses could personalize lessons by creating multiple paths through content based on a student’s responses to quiz questions (or to instruments designed to measure preference in “learning style”). Personalization has since become ubiquitous on the web, operating below the level of the user’s awareness and beyond the user’s control.
Personalization in the context of the web means that the web itself remembers users and exploits all of what it knows about the user. The technologies that are most important to personalization are changing rapidly, so in trying to work out implications for critical thinking, it is not worthwhile to focus on any particular example. A critical thinker needs to understand personalization as a broad media trend and to grasp intuitively its consequences for personal point of view.
At the time of this writing, personalization has two expressions that are of central importance to critical thinking: filtering of information to fit a model of the user’s interests, and deliberate targeting of content to particular users.
1.3.1 Filtering and feeding
Eli Pariser (2011) first called attention to what he called the “filter bubble”: the tendency of people getting most of their information from the web to see only information that confirms their prior expectations. As noted earlier, many algorithms that deliver web content take the user’s prior behaviour into account in guessing what the user would like to see. Google’s search engine may rank results one way for one user and a different way for another user, leading to dramatic differences in what the two users see when making the very same query. Each choice a user makes from a list of search results is captured as data that can be used to better personalize future search results. One way to look at this is as the user “training” the algorithm to deliver a certain kind of content. But that would be a very misleading view, because users typically have no idea that they are in this way limiting their own access to information.
The 2016 U.S. Presidential election exposed a fact that should have been widely known but that was not: Facebook’s news feed algorithm was discerning users’ political tastes and introducing dramatically different views of the world for those on the left and those on the right. The filtering of content affects not only the political information that a user sees, but also what social information a user sees (that is, whose status updates are called to the user’s attention). The Wall Street Journal produced a powerful infographic demonstration of this, showing side-by-side “red feed” and “blue feed” content updated in real time (http://graphics.wsj.com/blue-feed-red-feed/; as of this writing, the infographic remains active). One screenshot from the site is shown in Figure 1.
Filtering and feeding are output from automatic processes. Add human intentionality and strategic thinking to these processes and the result is a form of highly individualized persuasion known as behavioral targeting (common in product advertising) or micro-targeting (when applied in political campaigning).

Fig. 1. Screenshot of “Blue Feed Red Feed” from May 18, 2016.
1.3.2 Behavioral targeting
Behavioural targeting is a technique for individual-level tailoring of message content. Originally developed to improve the return on investment from product advertising (Turow et al., 2009), behavioural targeting is now being used more and more extensively in political campaigning and other forms of non-commercial persuasion, where it is often called micro-targeting (Turow et al., 2012).
A well-known peculiarity of the American electoral system (the Electoral College) has made it essential for every candidate for national office to design campaigns around the prospects of winning particular states. Since the invention and institutionalization of public opinion polling, campaigns have been able to engage in geographic targeting of campaign messages, with heavy investment in battleground states to the neglect of states considered safe for one party or the other. From the perspective of political theorists (e.g., Gimpel et al., 2007), this is a matter of concern for the health of democracy, with possible harmful consequences for “political socialization.” Without exposure to candidates’ arguments, citizens can still vote, so they are not exactly disenfranchised; but they have been excluded from a discourse that might have been helpful to them in other contexts (such as reasoning about the Affordable Care Act also known as Obamacare).
In the American presidential campaigns of 2008, 2012, and 2016, not only did geographic targeting achieve higher levels of precision, but behavioral targeting emerged at the individual level, with likely supporters receiving intense attention while likely opponents received none. Behavioural targeting is a creature of the new media environment: it is not simply a shift from mass media to social media platforms, but is much more importantly an exploitation of the rise of powerful algorithms for profiling consumers and voters based on increasingly detailed information about their behaviour. The first Obama campaign, in 2008, used social media extensively to concentrate on known supporters; the second Obama campaign, in 2012, introduced an unprecedented reliance on Big Data and algorithmic techniques for targeting particular voters with messages tailored to their profiles (Jamieson, 2013; Murphy, 2012; Tufecki, 2012). In the 2016 presidential campaign, these techniques were taken to a new and frightening level, with targeted delivery of fake news aimed at harming a candidate (Calabresi, 2017). Though exactly who was responsible remains a matter of inquiry at the time of this writing, it is highly likely that future campaigns will find more-or-less legitimate ways to target opponents’ supporters (with conventional attack messages). A looming threat is the possibility of tailoring messages based not just on political leaning but on “psychographics” inferred from massive datasets of personal information stored on the web (Confessore & Hakim, 2017).
The importance of this for critical thinking is to realize that persuasive messages directed to one’s email and other personal accounts may have been crafted quite purposefully to exploit knowledge about the recipient that is growing ever more specific. A candidate for political office will have positions on many issues, only some of which will be a match with a particular voter’s views. Rather than presenting campaign messages that disclose an array of policy positions, candidates using micro-targeting technologies can send an environmentally engaged voter information on the candidate’s views on climate change but omit information on any other issues on which the voter might disagree. Or, if targeting an opponent’s supporters, a micro-targeted message might focus on a single issue on which the voter can be assumed to disagree with the opponent. Every individual should try to notice when messages appear to have been targeted—being especially alert to messages with uncanny personal relevance. Playing on specific fears of specific individuals appears to be possible.
To whatever extent these technologies confer competitive advantage to candidates, candidates can be expected to use them aggressively. Setting aside what this will mean for winning and losing, political micro-targeting can affect the overall health of a democracy. Elections have outcomes beyond who wins and who loses, such as political participation, belief polarization, and contempt for those who disagree. One difficulty in anticipating serious societal consequences of this emerging practice is that consequences of this kind unfold very slowly, over multiple election cycles. Denying candidates the competitive advantage that motivates micro-targeting is one way to push back against these damaging effects. Others will be described in Section 2.
2 New expressions of critical thinking
Earlier chapters have thoroughly discussed both the evaluation of individual arguments a person may encounter and the construction of strong arguments, so there is no need to repeat here that a critical thinker will approach the web with many of the same skills and dispositions that apply wherever argumentation occurs. But as argued above, the web is a new and still evolving ecology of data and applications, a new communication environment that transforms humanity’s relationship with information. In this section, I explore a small set of new critical thinking skills and dispositions that have already become important for using the web. These often involve either reflection on the communication environment itself or meta-cognitive skills related to the limits of one’s own knowledge and judgment.
2.1 Acknowledging the vulnerabilities of algorithmic search
The unwarranted confidence people have in their own web searches is a new threat to critical thinking. Algorithmic search is a powerful resource for locating information on any issue of interest, but it is also a potent source of bias. Being critical of specific information encountered on the web is not enough, if what is selected for you by algorithms is already a slanted view of the world.
Search engines do not deliver the same information in response to the same query by different people; they use social and behavioral data to tailor results to what are assumed to be the user’s interests and preferences. A critical thinker aware of this fact will not only evaluate the content returned by a search, but will also take into account that algorithmic search may filter out content that would challenge the searcher’s sense of what is true. In other words, in using web search to form an impression of a person, an event, or an issue, a critical thinker will not assume that the results of this search are an accurate representation of what there is to know about the subject. In particular, a critical thinker will be conscious of the filter bubble and cautious about relevance ranking.
To avoid the filter bubble, a web user can choose incognito browsing, accomplished by installing a browser that allows incognito mode. Fully anonymized browsing is also possible. But although incognito and anonymized browsing eliminate personalization of the results list, they cannot eliminate the influence of social information, such as data on other searchers’ choices of which search results to select. Safiya Noble (2013) reported that querying for “black girls” returned large amounts of sexualized and even pornographic content, exposing the fact that many people in the past have searched for “black girls” intending to find pornography; going incognito will not prevent these past searches from affecting the results of any new search, even one motivated by an interest in how to parent a black girl.
Search results have the capacity to mislead in other ways even when the content returned, taken item by item, is pretty good. One error to avoid is thinking that the best items appear at the top of a list of results. Recall the metaphor of the library whose items push out to attract attention of passers-by. Items found in a search push themselves toward the top of the list, and their success in reaching the top is not an assurance of quality. Users may assume that position in a results list indicates information quality. This is false. In a study of search designers’ own rationale for search algorithms, van Couvering (2007) found little interest in values like source credibility. Commercial goals drive most design decisions.
Good search techniques mitigate some of the effects of filtering, and one good general practice is to look (far) beyond the first page of results returned from a search to see results that might be ranked highly for other users. Humility is a useful disposition for a critical thinker: The goal is to avoid placing more confidence than is warranted in the competence and completeness of one’s own searching. Search makes it easy to find information; it does not make it easy to master the subject of the search, nor to spot the gaps in one’s own understanding.
2.2 Respecting both expertise and experience as sources of knowledge
A considerable amount of work on digital literacy has focused on how to discriminate between credible information and the vast bodies of false or unfounded information that can be found on the web (see, e.g., Rheingold, 2012, Ch. 2). Students are often urged, when writing academic papers, to use specific databases (such as EBSCO or ProQuest) or specific search tools (such as Google Scholar) to locate credible information. They may also be taught to seek curated information sources for their non-academic purposes, preferring government sponsored sources for public health information over popular sources like WebMD, and avoiding altogether sources that are maintained by uncredentialed health advocates.
As I have already suggested in Section 1.1, there is reason to worry that advice of this kind may be ill-adapted to the new media. Information curated by experts is certainly to be preferred when a question is one that can be answered only with the judgment and research resources of experts. But experts take no interest in many matters of importance, and their special skills are not needed for many questions ordinary people may ask. The web encourages sharing of information among members of the public who share an interest or a life circumstance, and rejecting this for lack of expert authority is a waste of an important new possibility for extending human knowledge. Rather than building critical thinking skills around a preference for credentialed information over uncredentialed information, an approach more suited to the web cultivates at least general understanding of the myriad ways in which knowledge can be produced. A critical thinker should be able to reflect on what basis there could be for answering any question and should have a flexible repertoire of tools for assessing the quality of all kinds of information.
Evaluating the credibility of information that has been assembled from contributions of many ordinary people is a new problem for critical thinking. However, this new problem does not have to be entrusted to the forms of individual analysis that have been taught as critical thinking skills. Thinking ecologically, humanity can choose to develop new roles and resources for sharing the work of evaluating credibility. Many resources of this kind are already familiar, especially those that have emerged around the problem of fact-checking. Well-established resources provided by trusted investigative agencies include (among many others) factcheck.org, snopes.com, and verificationjunkie.com.
In addition to resources built around trusting human investigators, certain problems can be addressed algorithmically. Customer reviews are one important and pervasive form of web content requiring an ability to discriminate between authentic and inauthentic reviews. It is possible that assessing authenticity will require tools that bear no resemblance to critical thinking skills as they have been taught in the past. For example, detecting inauthenticity may be impossible when examining an individual bit of content like a product review, but possible when comparing the content with large collections of other content. Credible scholarly research has demonstrated that fake content can be identified algorithmically (see Heydari et al., 2015, for a useful survey and assessment of many different approaches). Websites like fakespot.com offer analysis of reviews for selected sites (Amazon and Yelp at the time of this writing). Figure 2 shows output from an algorithmic analysis of all of the 338 customer reviews of a Chinese restaurant posted to Yelp, with the overall conclusion that the reviews can be trusted. In the rapidly changing information environment, tools that operate above the level of individual judgment of individual texts may become important accessories for critical thinkers.
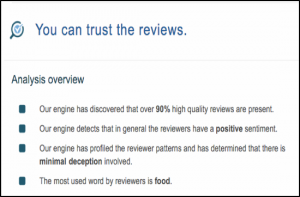
Fig. 2. Results from a fakespot.com analysis of Yelp reviews.
Other novel features of the web environment make it worthwhile to reconsider even instruction in the use of expertise-based knowledge. Before digitization and algorithmic search, encounters with primary research reports involved exposure to at least some of the social context for scholarly research. Expert writing is discoverable through algorithmic search and increasingly accessible to the public as more resources shift to digital open access. But context is degraded in this environment. When primary research reports of experts are as easy to find as blog columns by non-experts, there may be as much threat to critical thinking in the one source as in the other. Theoretical explorations of the nature of expertise (notably Collins & Evans, 2007) make clear that exposure to the primary literature of an expert field, without appreciation of the tacit knowledge possessed by all contributors to that field, does not necessarily provide knowledge of the field. Critical thinking instruction should take into account how easily nonexperts can misinterpret what an expert, writing for other experts, is actually saying.
A well-documented metacognitive bias is the Dunning-Kruger effect, a tendency for people with poor skills in an area to greatly overestimate their skills (Dunning, 2011). This effect occurs when the skills needed to perform a task are the same as the skills needed to evaluate the performance. If the Dunning-Kruger effect occurs for interpretation of expert opinion, a person who misunderstands what an expert is saying is unlikely to accurately assess his or her own understanding. A critical thinker should be able to question, and even doubt, his or her own ability to make sense of what experts say about a question.
In the changed information environment of the web, a critical thinker should have an open mind about potential sources of information, paired with strategies for assessing the quality of the new kinds of information found on the web. A critical thinker will try to cultivate good individual judgment, but will also know its limits and rely when possible on tools developed to augment individual judgment.
2.3 Managing the cognitive environment
As the web becomes ever more fully integrated into daily life, its influence becomes less noticeable. It becomes an invisible part of the environment. Information flows whether or not a person has turned on the tap, and this flow of information shapes what a person experiences as familiar, as plausible, and as natural. Allowing the flow to be controlled by algorithms optimized for commercial value or political success is a danger to critical thinking, both at the individual level and at the societal level. To begin with, it is likely to involve systematic overexposure to information biased in one way or another (the filter bubble problem), and in the extreme, it opens the door to large-scale manipulation by micro-targeters.
The societal level effects are beyond the scope of this chapter, and managing these effects depends on developments in new areas of inquiry like critical algorithm studies and value-centered design. But it is possible to mitigate the individual level effects by managing one’s own cognitive environment—the part of the information environment that any individual inhabits. To manage the cognitive environment means, first, making a deliberate decision about how to allocate one’s attention. For news, having a set of reliable news sources to review daily is far better than absorbing news from Facebook or other social media. Giving attention to social media is fine, so long as that is not a person’s primary (or only) source of news. Choosing multiple news sources is preferable to a single source, and deliberately introducing diversity of political slant is even more preferable. The goal is to avoid a view of the world that is chosen by algorithms designed to cater to the user’s known preferences.
Convenient ways to routinize a decision like this include bookmarking the websites of several good newspapers or using a smartphone app that delivers news daily from the same selected sources. Carefully choosing and curating social media sources is another good practice (e.g., on Twitter, “unfollowing” sources that routinely retweet suspect material).
Another issue to consider is how aggressively to resist personalization. Personalization is a source of bias, but also a very handy feature of the web. Managing one’s cognitive environment includes balancing the value of personalization against its biasing effects. Various browser extensions are available for pushing back against tracking and targeting. For example, Ghostery (http://www.ghostery.com) is a web privacy tool that can detect efforts to track a person’s movements on the web and can block those the user does not want. (For up-to-date options, search for “browser extensions that block tracking”). Preventing collection of data on one’s behavior gives targeters (whether commercial or political) less to work with. Going incognito is a more drastic alternative, but it involves sacrifice of all personalization (at least while remaining incognito). More difficult but also more impactful are various resources for controlling what the web knows about the user. Users of Google can log in to https://myactivity.google.com to review and edit data Google uses to deliver personalized content. For example, Google invites users to fine-tune the product classes of ads they are interested in seeing, allows users to delete items from their search history, and so on. Choosing a personalized environment is not wrong, but because it means handing over control to algorithms, it is a choice that should be made deliberately.
New resources for management of the cognitive environment may be invented at any time. Eslami et al. (2015) have developed a piece of software, called FeedViz, that allows Facebook users to see what Facebook chooses not to include in their news feeds. FeedViz assembles all items generated by a user’s social network and presents these in direct comparison with the items selected from this pool by Facebook’s news feed algorithm. Users may or may not prefer the algorithm-curated news feed, but by allowing users a choice, FeedViz could be considered a tool for managing the user’s cognitive environment.
In the same spirit, the artist Ben Grosser has focused on Facebook’s penchant for quantification and how that might affect users’ evaluations of particular items viewed on Facebook. He created a browser extension, Facebook Demetricator[2], to strip quantitative information from a user’s view of Facebook (so that items are not accompanied by counts of people who “liked” the item or counts of people who commented on the item). In terms of legacy critical thinking concepts, Facebook feeds the user a steady stream of information on popularity, constantly whispering the message that what is popular is also valuable. One way to address this is to train people to resist these whispered messages; Grosser’s work illustrates another, completely new way to address the problem, giving the user a tool for control of the cognitive environment.
One point to take from this discussion is that individuals have more control over their cognitive environments than they suppose they do, and this means that a person can choose whether or not to live in a personalized filter bubble and whether or not to go with the flow of suspect information. Those who aspire to critical thinking can start by pushing back against distortion and manipulation that have been designed in to the information environment under the guise of providing a more satisfying online experience.
3 Critical thinking about the web
Part of what is necessary for critical thinking in use of the web is critical thinking about the web as an information environment. Neil Postman (2000) argued for a certain kind of critical assessment of media themselves in a keynote address to the Media Ecology Association, saying “I believe that rational thinking is one of humanity’s greatest gifts, and that, therefore, any medium that encourages it, such as writing or print, is to be praised and highly valued. And any medium that does not, such as television, is to be feared.” He proposed a number of critical questions to ask about any medium of communication, the most relevant being “To what extent does a medium contribute to the uses and development of rational thought?” Postman (who died just as the web was exploding with new social media platforms) would have us ask, what kind of medium is the web, taken as a whole? Does it encourage or inhibit rational thinking? Should it be valued for the vast stores of information it contains, or feared for its shallowness and defiance of intellectual standards?
As should be clear, these questions cannot be answered straightforwardly, or at least not just yet. Postman’s case against television was that regardless of content, the medium itself was dangerous, putting entertainment and distraction at the center of human existence. He would surely note similar tendencies in the web if writing today. But along with the web’s infinite capacity for distraction and disinformation, its capacity for reorganizing human experience must be considered. For human rationality, the web enables new arrangements for shifting responsibility for critical thinking from individuals to various kinds of sociotechnical systems, ranging from algorithms that perform human decision-making tasks more dependably than humans themselves do, to institutions that conduct the work of critical thinking on behalf of an entire society. There is little point for now in trying to guess whether this will degrade rational thought or greatly enhance it.
The future of the web, and especially its long term impact on human rationality, is unknowable because it is undetermined. Postman and other media ecologists (such as Marshall McLuhan) were often criticized for the technological determinism they embraced, but this sort of thinking has fallen out of fashion, in part because it so badly underestimates human inventiveness. Nowadays, instead of asking Postman’s question (does the web contribute to rational thought?), theorists would be more likely to pose a design-oriented question: How can the web contribute to rational thought? Put just a little differently, we might ask how the deepest insights of critical thinking can be designed into the new media ecology.
Explorations of this reframed question are already well underway. Closest to the field of critical thinking are the many argumentation support systems that have flourished online (Schneider et al., 2013). Some of these systems, such as debate.org and debatewise.org, rely on disagreement to force arguers into deeper thought, providing little else in the way of intervention. Others, such as Carneades (Walton & Gordon, 2012) and Agora (Hoffman, 2016a), attempt to support critical thinking by encouraging reflection on the quality of the individual arguer’s own reasoning. For example, Agora asks users to input a claim and prompts for what grounds can be advanced in support of those claims. The system then supplies a linking premise (generated automatically to assure a valid argument) and lets the user decide whether this linking premise is true. In theory, a linking premise that is obviously not true should alert the user to grounds that are insufficient to justify the claim (but see Hoffman, 2016b, and Jackson, 2016, for discussion of the limitations of this form of support for critical thinking).
An idea mentioned earlier has broad possibilities for designing an information environment that supports critical thinking: the idea that critical thinking can be accessorized with online tools that perform certain parts of the assessment of an argument. Certain difficult information assessment problems that cannot be solved by humans are more easily solved by algorithms. Spotting fake product reviews and other fake opinion content is not a matter of knowing what to look for in an individual message, but a matter of searching for anomalous patterns in large bodies of messages. Something similar is true for detecting bias. It is often impossible to detect bias in a single evaluation, while patterns observable in large numbers of assessments may be incontrovertible evidence of bias. An important and unanswerable question this raises is whether it is better to keep trying to rid human reasoning of bias or to search for inventions that ingest biased human reasoning and deliver unbiased results.
4 Conclusion
As observed very early in this chapter, a new media ecology can challenge old assumptions and old habits of thought while requiring new skills and new tools. What have we observed so far, in the very short time since the invention of the web?
To begin with, the web (or the new media ecology generally) does not make critical thinking irrelevant, but it does change the relevance of some component skills associated strongly with prior media ecologies, and it does seem to call for some entirely new skills. For example, skill in reconstructing and evaluating what is argued in a particular text has long been considered a central component of critical thinking. The web changes the scale of this task, as can be seen by considering the effort required to reconstruct and evaluate any fraction of the information returned by algorithmic search. New parents searching for authoritative content on whether to vaccinate their baby, for example, will find an overwhelming amount of information, including an overwhelming amount of content produced by indisputable experts and an equally overwhelming amount of content produced by other parents who have had the same question. Deciding what deserves any attention at all is as much a matter of critical thinking as is the detailed assessment of items that manage to claim some share of attention. Preferring authoritative sources becomes a rule of thumb that applies in many cases, but not all.
As argued earlier, when large bodies of experience-based content are being examined, new skills are needed for evaluating the body of content as a whole. The authenticity of product reviews, for example, cannot be judged reliably by applying tests to an individual review, but the overall trustworthiness of a collection of reviews can be assessed algorithmically. The search for patterning in large bodies of content requires an ability to zoom out from any one bit of argument. The meta-cognitive lesson of this applies broadly, not only to collections of product reviews, but also to collections of much more serious content, including medical advice extracted from primary research literature. Too much focus on evaluating one such text can produce unwarranted confidence in one’s own grasp of a subject (Jackson and Schneider, 2017). Learning to investigate the provenance of evidence (roughly, where it comes from and how it has “traveled” through cyberspace) is a subtle transformation of skill in evaluating the credibility of the person who states (or re-states) a claim. As the web becomes more and more integrated into daily life, many such transformations are to be expected.
Earlier in the chapter I pointed out the value of delegating some kinds of critical questioning to algorithms that can improve on individual judgment. In an information environment like the web, it is well worth considering what other cognitive work can be better done by new inventions that might truly augment human reasoning. The web’s most lasting effect on human reasonableness is likely to come from tools invented to improve on human reasoning—that is, tools that lead to better inferences than humans can draw without the aid of the tools. These can include not only the sort of workaday algorithms that figure so heavily in selection and presentation of content, but also novel ways of aggregating the cognitive work of many individual humans (requiring other sorts of algorithms). New theorizing will be needed around what should count as an improvement over (or in) human reasoning. New methods will be needed for judging the overall dependability of tools that purport to extend or substitute for human reasoning, and new standards will be needed (such as overall track record) for deciding when unaided human reasoning really should not be trusted.
Ultimately, critical thinking is a means to an end, rather than an end in itself, inviting questions about whether humanity can seek the end served by critical thinking through new means. If the end served by critical thinking is greater reasonableness, depending on individuals trained in critical thinking techniques may need complementary strategies aimed at exploiting new possibilities presented by the web, including not only the new possibilities associated with computational tools but also the new possibilities associated with the web’s ability to mobilize human effort at massive scale. What might be possible for humanity now that has never been possible before? How might new tools be designed to meet Postman’s standard of contribution to rational thought? As Shirky (2010, p. 162) put it, “Upgrading one’s imagination about what is possible is always a leap of faith.” The web itself is such a leap, and its long-term contribution to human reasonableness is yet to be determined.
References
Abbate, J. (1999) Inventing the Internet, Cambridge, MA: MIT Press.
Berners-Lee, T. (1996). The Worldwide Web: Past, present, and future. https://www.w3.org/People/Berners-Lee/1996/ppf.html
Calabresi, M. (2017, May 18). Inside Russia’s social media war on America. Time. Retrieved from http://time.com/4783932/inside-russia-social-media-war-america/.
Collins, H.M., and R.J. Evans. (2007). Rethinking expertise. Chicago: University of Chicago Press.
Confessore, N., & Hakim, D. (2017, March 6). Data firm says ‘secret sauce’ aided Trump; many scoff. New York Times. Retrieved from https://www.nytimes.com/2017/03/06/us/politics/cambridge-analytica.html
Dunning, D. (2011). The Dunning-Kruger effect: On being ignorant of one’s own ignorance. In Advances in Experimental Social Psychology, 44, 247-296. doi: 10.1016/B978-0-12-385522-0.00005-6
Eslami, M., Aleyasen, A., Karahalios, K., Hamilton, K., & Sandvig, C. (2015) FeedVis: A path for exploring news feed curation algorithms. In Proceedings of the 18th ACM Conference Companion on Computer Supported Cooperative Work & Social Computing (CSCW’15 Companion). ACM, New York, NY, USA, 65-68. doi:10.1145/2685553.2702690
Finneman, N. O. (2011). Mediatization theory and digital media. European Journal of Communication, 36, 67-89. doi:10.1515/COMM.2011.004
Gimpel, J. G., Kaufmann, K. M., & Pearson-Merkowitz, S. (2007). Battleground states versus blackout states: The behavioral implications of modern presidential campaigns. The Journal of Politics, 69(3), 786–797.
Heydari, A., ali Tavakoli, M., Salim, N., & Heydari, Z. (2015). Detection of review spam: A survey. Expert Systems with Applications, 42(7), 3634-3642. doi:10.1016/j.eswa.2014.12.029.
Hoffman, M. H. G. (2016a). Reflective argumentation: A cognitive function of arguing. Argumentation, 30(4), 365–397. doi:10.1007/s10503-015-9388-9
Hoffman, M. H. G. (2016b). Collaborative reframing: How to use argument mapping to cope with ‘wicked problems’ and conflicts. In D. Mohammed & M. Lewinski (Eds.), Argumentation and Reasoned Action: Proceedings of the First European Conference on Argumentation, Lisbon, 9-12, June 2015, Vol. 1. College Publications (Studies in Logic and Argumentation), pp. 187-215.
Introna, L. D. (2016). Algorithms, governance, and governmentality. Science, Technology & Human Values, 41(1), 17-49. doi:10.1177/0162243915587360
Introna, Lucas D., & Nissenbaum, Helen. (2000). Shaping the web: Why the politics of search engines matters. The Information Society, 16(3), 169-185.
Jackson, S. (2016). Comment on Hoffman’s “Collaborative reframing: How to use argument mapping to cope with ‘wicked problems’ and conflicts.” In D. Mohammed & M. Lewinski (Eds.), Argumentation and Reasoned Action: Proceedings of the First European Conference on Argumentation, Lisbon, 9-12, June 2015, Vol. 1. College Publications (Studies in Logic and Argumentation), pp. 217-220.
Jackson, S., & Schneider, J. (2017). Cochrane Review as a “warranting device” for reasoning about health. Argumentation. doi:10.1007/s10503-017-9440-z.
Jamieson, K. H. (2013). Messages, micro-targeting, and new media technologies. The Forum: A Journal of Applied Research in Contemporary Politics, 11(3), 429-435. doi:10.1515/for-2013-0052
MacCormick, J. (2012). Nine algorithms that changed the future: The ingenious ideas that drive today’s computers. Princeton, NJ: Princeton University Press.
Murphy, T. (2012, September/October). Harper Reed’s machine can’t read your mind—yet. Mother Jones, 37:5, 42-47.
Noble, S. U. (2013). Google search: Hyper-visibility as a means of rendering black women and girls invisible. InVisible Culture: An Electronic Journal of Visual Culture. http://ivc.lib.rochester.edu/google-search-hyper-visibility-as-a-means-of-rendering-black-women-and-girls-invisible/
Pariser, E. (2011). The filter bubble: How the new personalized web is changing what we read and how we think. New York: Penguin Press.
Postman, N. (2000). The humanism of media ecology. Proceedings of the Media Ecology Association, 1, pp. 10-16. http://media-ecology.org/publications/MEA_proceedings/v1/postman01.pdf
Rheingold, H. (2012). Crap detection 101: How to find what you need to know, and how to decide if it’s true. Netsmart: How to thrive online, ch. 2. Cambridge, MA: MIT Press.
Schneider, J., Groza, T., & Passant, A. (2013). A review of argumentation for the Social Semantic Web. Semantic Web, 4, 159–218 159. doi:10.3233/SW-2012-0073
Shirky, C. (2010). Cognitive surplus: Creativity and generosity in a connected age. New York: Penguin Press.
Tufekci, Z. (2012, November 16). Beware the smart campaign. The New York Times. http://www.nytimes.com/
Turow, J., King, J., Hoofnagle, C. J., Bleakley, A., & Hennessy, M. (2009). Americans reject tailored advertising and three activities that enable it. Available at SSRN: https://ssrn.com/abstract=1478214 or http://dx.doi.org/10.2139/ssrn.1478214
Turow, J., Delli Carpini, M. X., Draper, N. A., & Howard-Williams, R. (2012). Americans roundly reject tailored political advertising. Annenberg School for Communication, University of Pennsylvania. Retrieved from http://repository.upenn.edu/asc_papers/ 398.
Van Couvering, Elizabeth. (2007). Is relevance relevant? Market, science, and war: Discourses of search engine quality. Journal of Computer-Mediated Communication, 12: 866–887. doi:10.1111/j.1083-6101.2007.00354.x
Walton, D. N., & Gordon, T. F. (2012). The Carneades model of argument invention. Pragmatics & Cognition, 20(1), 1–31. Doi:10.1075/pc.20.1.01wal
