28 Introduction aux bases de données relationnelles
Les bases de données relationnelles sont présentes depuis un certain nombre d’années et constituent la conception standard choisie pour les besoins quotidiens de la plupart des entreprises. De la même façon que nous décrivons notre relation avec ceux qui nous entourent, une base de données est constituée de tables qui sont liées les unes aux autres d’une certaine manière.
Considérez une table de base de données relationnelle comme un onglet de tableur avec des informations spécifiques répertoriées dans la ligne du haut, comme le titre d’un livre, et des informations correspondantes répertoriées dans chaque colonne, comme l’auteur, la date de publication, etc.
Cette méthode traditionnelle permet de stocker les données à un seul endroit, de réduire les redondances et de minimiser les risques qu’elles ne soient pas mises à jour lors de l’édition.
Bases de données relationnelles
Les bases de données relationnelles stockent les détails d’une entité, telle qu’un constructeur automobile, et ceux qui lui sont liés, comme la marque du véhicule, ce qui permet de relier formellement des enregistrements significatifs. Cette approche minimise les enregistrements en double et fait en sorte que les modifications soient faites sur un élément de données à un seul endroit.
Les bases de données relationnelles sont souvent associées aux sites Web et à d’autres applications liées aux transactions.
Prenons un exemple :
Une librairie peut avoir besoin de stocker des données relatives aux livres, aux auteurs et aux achats. Ces données doivent être stockées dans des tables distinctes, comme illustré ci-dessous. La table Livres contiendrait des informations uniques telles que le titre, le prix et la date de publication, tandis que la table Auteurs contiendrait le prénom et le nom de famille des auteurs. Le graphique ci-dessous montre comment les tables Livres et Auteurs sont liées. La table LivreAuteur est issue du processus de normalisation, que nous aborderons plus tard !
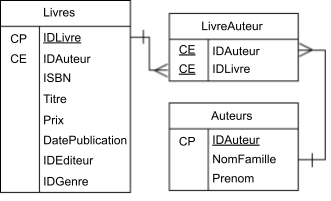
Une représentation d’une base de données relationnelle simple
Qu’est-ce qu’une entité ?
Une entité est tout ce qui existe, comme une personne, un lieu ou un objet, qui peut être décrit d’une manière ou d’une autre.
Par exemple, une personne est une entité qui peut être décrite par son nom, sa date de naissance, son adresse, son film préféré, etc.
Voyons maintenant comment les bases de données relationnelles sont constituées à partir d’entités. Vous avez vu que les bases de données relationnelles sont essentiellement constituées de tables qui stockent des données. Une entité se traduit par une table. Ainsi, le modèle logique des livres et des données d’auteur ci-dessus, organisé en trois entités, se traduira par trois tables dans une base de données.
Décrire des entités avec des attributs
Maintenant que vous avez défini les entités, examinons les qualités qui décrivent chacune d’elles. Dans une base de données, ces qualités sont appelées attributs.
Par exemple, si vous avez un véhicule en tant qu’entité, l’un de ses attributs peut être sa couleur. Ou, si votre restaurant préféré est une entité, son code postal serait l’un de ses attributs.
Alors que les entités deviennent les tables de la base de données, les attributs deviennent les champs de ces tables.
Par exemple, une table Véhicule peut avoir une colonne de couleur, et pour chaque enregistrement représentant un véhicule spécifique, vous trouverez un champ où la couleur de ce véhicule peut être stockée comme donnée. De même, une table Restaurant peut avoir une colonne de code postal.
Les attributs sont très spécifiques et atomiques ; en d’autres termes, ils sont décomposés en leurs plus petits composants.
Par exemple, une adresse n’est pas atomique car elle a plusieurs composants. Ainsi, une adresse complète ne serait pas considérée comme un attribut ; vous la décomposeriez plutôt en plusieurs éléments. Dans le cas de votre restaurant préféré, le numéro de la rue et du bâtiment serait l’un de ses attributs, la ville en serait un autre, l’état ou la province ou le comté un autre, et enfin, le code postal en serait encore un autre. Lors de la définition des attributs, assurez-vous qu’ils soient aussi petits que fonctionnellement possible.
Certains attributs ont de nombreuses variations potentielles. Par exemple, il existe plusieurs variétés de couleur : rouge, bleu, orange, etc. Il est utile d’utiliser une table de recherche pour stocker les possibilités d’un attribut qui a des valeurs spécifiques et fixes. Dans ce cas, il s’agirait de créer une table Couleurs dans laquelle des couleurs spécifiques peuvent être stockées.
Autre exemple : Si vous avez des livres avec des genres spécifiques tels que le drame ou la romance, vous créeriez une entité pour contenir uniquement ces genres dans une table du même nom. Alors que la table Livres contiendrait les détails relatifs aux livres, la table Genre contiendrait les genres, avec l’IDGenre reliant les deux tables, généralement sous la forme d’une valeur numérique, comme indiqué ci-dessous :
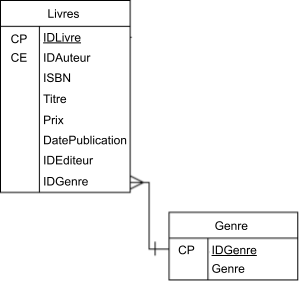
Deux tables, la table Genre étant la table de recherche.
Comment les entités sont-elles liées les unes aux autres ?
Une fois que les entités et les attributs sont établis, vous devez déterminer comment ils sont liés les uns aux autres. Chacun sera lié à au moins un autre, de sorte que vous maintenez au moins une relation entre chaque table.
Bonne question, mais non, c’est très rarement le cas, et nous allons voir quelques exemples. Des diagrammes connus sous le nom de modèle entité-association (Entity-relationship diagram [ERD]), sont créés pour montrer comment les tables sont liées. Lorsque de plus en plus de tables d’entités sont ajoutées, un modèle entité-association devient essentiel pour ne pas se tromper dans leurs relations, comme vous pouvez le voir dans l’image ci-dessous. Pour qu’une base de données relationnelle fonctionne correctement, les entités doivent être liées à une ou plusieurs tables distinctes.
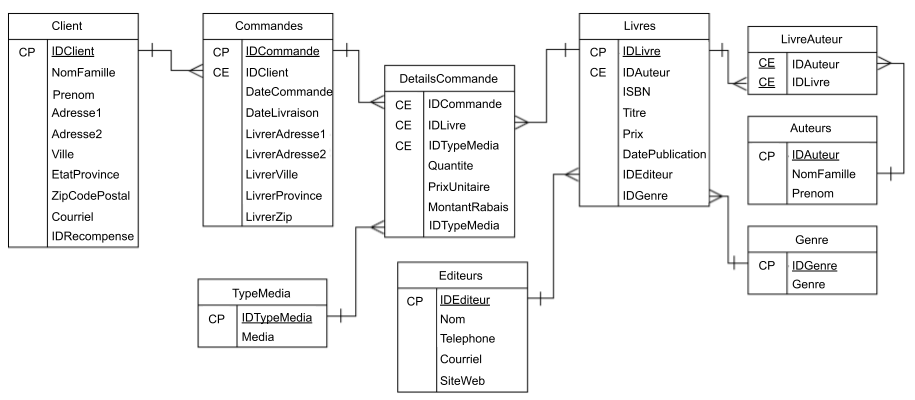
Modèle entité-association pour la base de données CommandeLivre
Les relations sont basées sur la clé primaire (CP) et la clé étrangère (CE). En examinant le diagramme ci-dessus, vous remarquerez que toutes les tables sont liées à au moins une autre, la table Livres étant la plus liée (quatre). Comme chaque entité ne contient que les attributs liés, il doit y avoir un lien entre les tables pour que des données et des enregistrements significatifs puissent être récupérés. Plus tard, nous aborderons les concepts de clés primaires et étrangères, qui sont essentiels à l’existence de relations entre les entités et au maintien d’une base de données saine et à jour.
Éléments clés à retenir
- Les entités sont tout ce que vous pouvez décrire et sont transformées en tables dans la base de données.
- Les attributs décrivent les entités et sont décomposés jusqu’au niveau le plus petit ou atomique.
- Les modèles entité-association sont les plans de votre base de données. Ils définissent les entités, les attributs et les relations entre eux.
Maintenant que nous avons une compréhension de base des bases de données relationnelles, découvrons la valeur des systèmes de gestion de bases de données.
Utiliser un système de gestion de base de données (SGBD)
Après avoir étudié les entités, les attributs et les modèles entité-association, examinons les caractéristiques d’un système de gestion de base de données (Database management system [DBMS]).
Quel est le rôle du SGBD ?
Un système de gestion de base de données, ou SGBD, est un système de gestion complet pour votre base de données. C’est l’intermédiaire, ou l’interface, entre l’utilisateur et les données existantes.
Le SGBD n’est pas la même chose qu’une base de données. Le système de gestion de base de données est le logiciel qui permet à l’utilisateur d’accéder à la base de données et à d’autres objets. Il assure la sécurité et maintient tous les objets, tels que les tables, dans la base de données. Les bases de données sont généralement désignées comme la base de données à l’intérieur du SGBD.
Parmi les exemples de systèmes de gestion de base de données, citons Access, SQL Server, Oracle, MySQL, PostgreSQL et MariaDB.
Quelles sont les fonctionnalités courantes d’un SGBD ?
Je suis content que vous ayez demandé ! Les objets de SGBD courants sont les tables, les procédures stockées, les déclencheurs, les vues, les synonymes et la sécurité.
Un SGBD héberge également la logique pour récupérer et manipuler les données en fonction du SQL exécuté. L’utilisateur n’a pas à se soucier de la façon dont les données sont récupérées puisque le SGBD gère la logique en fonction du SQL exécuté. Les fonctions de sécurité conservent les mots de passe, ainsi que les utilisateurs et leur niveau d’accès aux données ou à d’autres structures au sein de la base de données.
Une autre fonctionnalité est la possibilité de planifier et d’exécuter des tâches à une heure spécifique, qui est souvent pendant les heures creuses, comme la nuit.
En termes simples, une tâche est une automatisation qui exécute une instruction SQL, une procédure stockée ou un autre code SQL pré-écrit à un jour et une heure donnée. La sauvegarde de données ou le transfert d’informations sur les transactions quotidiennes sont deux exemples d’utilisation des tâches pour automatiser des tâches répétitives. Des options peuvent être définies pour envoyer un courriel à des personnes spécifiques lorsque la tâche échoue, réussit ou se termine. L’option d’achèvement informe le destinataire lorsque la tâche est terminée, qu’elle soit réussie ou non. Cela peut être plus fiable que de se souvenir de les exécuter à la main, et cela n’oblige pas non plus l’administrateur de la base de données (Database administrator [DBA]) à se réveiller à 3 heures du matin pour exécuter le code !
Access, SQL Server, Oracle, MySQL, PostgreSQL ou MariaDB ?
Un certain nombre de facteurs, y compris l’expérience personnelle et les préférences, peuvent aider à prendre cette décision. Le coût, la fonctionnalité globale et la quantité de données stockées et consultées doivent également être pris en compte. La plupart des bases de données peuvent traiter des quantités de données petites ou moyennes, allant de centaines à des milliers ou des dizaines de milliers d’enregistrements. Dans cette situation, il peut être judicieux de choisir un logiciel libre (open source) ou gratuit. Les systèmes contenant de grandes quantités de données bénéficieront davantage d’une option basée sur un abonnement ou une licence, comme SQL Server ou Oracle, cette dernière étant meilleure pour maintenir et récupérer des données à grande échelle.
Le choix appartient au développeur de la base de données, mais il doit tenir compte des besoins actuels et futurs de l’organisation. Planifier pour l’avenir est un excellent moyen de déterminer quel SGBD serait le plus approprié et le plus rentable. Si vous avez besoin d’un certain nombre de licences et que vous vous souciez de l’argent, les logiciels libres tels que MariaDB et PostgreSQL seraient le meilleur choix. Les alternatives sous licence telles que SQL Server ou Oracle nécessitent habituellement une licence pour chaque utilisateur, mais sont souvent accompagnées d’une assistance de la part de la société de logiciels ; alors que les alternatives libres ne le sont généralement pas, à l’exception des forums techniques en ligne.
| Données du classement de DB-Engines | Oracle | MySQL | SQL Server | PostgreSQL |
Access |
MariaDB |
|
Rang: (Janvier 2022) |
1 |
2 |
3 |
4 |
9 |
12 |
|
Licence |
Propriétaire |
Publique |
Propriétaire |
Logiciel libre |
Propriétaire |
Publique |
|
Mainteneur |
Oracle Corp. |
Oracle Corp. |
Microsoft |
PostgreSQL |
Microsoft |
Communauté MariaDB |
|
Première sortie publique |
1979 |
1995 |
1989 |
1989 |
1992 |
2010 |
Pour la suite, les exemples seront fournis en utilisant Microsoft Access, mais vous pouvez suivre en utilisant n’importe quel autre SGBD SQL.
Éléments clés à retenir
- Un système de gestion de base de données, SGBD, est un logiciel qui maintient et gère les fonctionnalités d’une base de données.
- Les fonctionnalités courantes du SGBD comprennent les tables, les procédures stockées, les synonymes, les tâches et les fonctions de sécurité.
- De nombreux facteurs peuvent intervenir dans le choix d’un SGBD, notamment le coût, la capacité à traiter des données volumineuses et la nécessité ou non d’acheter une licence.
Maintenant que vous êtes prêt à travailler avec un système de gestion de base de données, examinons l’une des premières étapes de la conception d’une base de données : la définition de vos champs de données avec le bon type de données.
Choisir le bon type de données
Maintenant que vous avez vu les fonctionnalités d’un SGBD, examinons exactement comment les données sont stockées dans les tables. Il s’agit d’une autre étape dans le processus de conception d’un modèle logique.
Quels sont les types de données utilisés pour stocker les données ?
Les attributs contiennent les descriptions d’entités qui définissent les données qui peuvent être stockées. Cette description est connue sous le nom de type de données et peut inclure des éléments tels que des nombres, des dates/heures, des valeurs booléennes et du texte. Il est important de choisir le bon type de données lorsqu’il s’agit d’opérations mathématiques.
Les champs numériques (ou nombres) stockent uniquement des valeurs numériques et, dans des situations particulières, peuvent contenir des devises, des décimales ou des entiers. Dans la plupart des cas, vous pouvez également définir les spécificités du nombre. Avec les décimales, vous pouvez définir les valeurs numériques disponibles à droite ou à gauche de la virgule décimale. Les champs entiers ne contiennent que des nombres entiers (y compris les négatifs).
Cela peut arriver, et normalement le SGBD arrondira votre valeur à la hausse ou à la baisse en fonction des conventions d’arrondi. Les applications logicielles ne permettent généralement à l’utilisateur de saisir que le type exact de nombre requis par la table.
Les champs date/heure peuvent contenir une gamme de formats, y compris la date ou l’heure uniquement, ou les deux dans des formats spécifiques. Les champs de date doivent toujours être utilisés pour les opérations de date ou d’heure, car vous êtes plus ou moins assuré d’obtenir des résultats corrects lorsque vous effectuez des opérations telles que l’addition ou la soustraction de dates pour déterminer l’ancienneté d’un employé ou l’âge d’une personne.
Les champs booléens sont très basiques et doivent être utilisés pour les réponses oui ou non. Pratiquement toutes les questions de type “oui ou non” ont intérêt à utiliser ce champ.
Oui, mais ce que les valeurs représentent réellement peut parfois être remis en question. Est-ce que le 1 signifie oui, ou est-ce que le 2 signifie oui? Vous pourriez avoir besoin d’inclure une autre table pour les définir. D’après mon expérience, je dirais qu’il vaut mieux utiliser une valeur booléenne plutôt qu’une valeur entière, surtout si vous prévoyez que quelqu’un d’autre travaillera sur les tables de la base de données.
Comment et quand utiliseriez-vous des types de données spécifiques ?
Excellente question ! Les développeurs expérimentés peuvent souvent sélectionner des types de données spécifiques en examinant ce qui doit être stocké dans une table. Si vous utilisez un champ date/heure pour enregistrer la date d’embauche d’un employé, vous pouvez facilement calculer les années de service à l’aide des fonctions de date SQL intégrées. Les champs date/heure n’attendent que ce type de données, et vous recevrez une erreur si vous tentez de saisir autre chose. Un champ de texte accepte presque tous les types de données, mais les calculs peuvent être difficiles.
Plus tard, nous observerons le niveau plus détaillé des types de données où vous pouvez spécifier ce qu’un champ peut contenir. Microsoft Access dispose de types de données plus spécifiques qui définissent plus précisément le type de données que vous souhaitez capturer. Date enregistre uniquement la date, heure n’enregistre que l’heure et date/heure les enregistre toutes les deux. Il serait logique d’utiliser date/heure comme horodatage indiquant qu’un enregistrement a été créé ou mis à jour. Le type de données heure serait une bonne option pour enregistrer le nombre de minutes d’exécution d’un processus. Vous utiliseriez le type de données date pour capturer l’anniversaire d’un employé. De nombreux autres types de données vous permettent de spécifier la quantité ou la longueur des données enregistrées.
Les images peuvent être enregistrées dans la plupart des tables de base de données, mais ce n’est pas recommandé car elles peuvent être volumineuses. Il est préférable de les enregistrer sur un serveur de fichiers et d’enregistrer le lien de l’image dans un champ de texte.
Éléments clés à retenir
- Les types de données sont les types spécifiques de données qui sont capturés, tels que :
- Numérique
- Date/heure
- Booléen (Oui/Non)
- Texte
- Lorsque vous utilisez les types de données appropriés, cela vous permet d’utiliser des fonctions intégrées, telles que l’addition de nombres ou la détermination de jours entre les dates du calendrier.
Wilkinson, V. (2020). Design the Logical Model of Your Relational Database. OpenClassrooms. https://openclassrooms.com/fr/courses/5671741-design-the-logical-model-of-your-relational-database
