5 Chapitre 5 : Développer les compétences en littératie évaluative
Lisa Levesque

Vue d’ensemble
Ce chapitre traite de la littératie évaluative, c’est-à-dire de la capacité d’exercer un jugement critique sur Internet : utiliser les outils de recherche sur le Web et reconnaître leurs faiblesses, comprendre la nécessité d’être critique en ligne et développer sa capacité d’évaluer l’information en ligne. Il abordera les discours de haine en ligne et les « fausses nouvelles » afin d’illustrer la nécessité d’être conscient des faiblesses inhérentes aux façons de consulter et d’évaluer l’information. Il propose également une trousse pour évaluer l’information en ligne et hors ligne.
Thèmes des chapitres
-
- Introduction : Réseaux invisibles
- Recherche sur le Web : Fonctionnement de Google
- Critiquer les résultats des recherches sur le Web
- Le clic tout-puissant : Internet et les médias
- Trousse d’évaluation
Objectifs d’apprentissage
À la fin du chapitre, vous devriez être en mesure de faire ce qui suit :
- « Comprendre comment les systèmes d’information (c’est-à-dire les collections d’informations enregistrées) sont organisés pour permettre l’accès aux informations pertinentes » (ACRL, 2015, p. 22).
- « Formuler des questions pour la recherche en fonction des lacunes en matière d’information » (ACRL, 2015, p. 18).
- « Développer et maintenir une ouverture d’esprit [et une position critique] face à des perspectives variées et parfois contradictoires » (ACRL, 2015, p. 13).
- « Surveiller [les informations que vous recueillez] et évaluer [leurs] lacunes ou faiblesses » (ACRL, 2015, p. 18).
- « Suspendre votre jugement sur la valeur d’une étude particulière jusqu’à ce que le contexte élargi de la conversation de recherche soit mieux compris » (ACRL, 2015, p. 21).
Introduction : Réseaux invisibles
Partout où nous allons, nous sommes entourés de réseaux invisibles. La nourriture que nous mangeons, l’électricité que nous consommons et les routes que nous empruntons sont autant d’éléments des systèmes que sont l’agriculture, les infrastructures et les transports. Bien sûr, il n’est pas nécessaire d’être agriculteur.trice pour apprécier une pomme ou d’être électricien.ne pour actionner un interrupteur. Cependant, être un.e citoyen.ne informé.e exige une certaine maîtrise de vastes domaines de connaissances ou de systèmes, ou réseaux, dont certains aspects nous échapperont probablement. Même si vous n’êtes pas un spécialiste de l’électricité, vous devez tout de même en savoir assez sur le câblage électrique pour éviter de vous électrocuter lors de réparations mineures à la maison.
Internet est un autre réseau invisible. Ce qui le rend unique, c’est son rôle déterminant dans la manière d’acquérir l’information. Comme un interrupteur, Internet est d’une simplicité trompeuse. Il n’est pas nécessaire de comprendre le codage ou le protocole de transfert hypertexte (HTTP) pour mettre à jour les médias sociaux ou chercher dans Wikipédia. Ces outils sont conçus pour être simples. Safiya Noble, bibliothécaire, professeure adjointe à l’Université de Californie du Sud et spécialiste des biais dans les algorithmes des moteurs de recherche, écrit : « Lorsque vous allez sur Google, il s’agit d’une boîte simple sur un fond simple. Par son esthétique, il donne l’impression qu’il ne se passe rien. La logique de sa conception est aussi simple : tapez un mot et obtenez un résultat » (Noble et Roberts, 2018, par. 18). La conception simple d’outils tels que les moteurs de recherche masque leur complexité réelle, et leur propre marketing les présente souvent comme des machines à répondre. Comme Google l’écrit sur sa page Web, « Vous voulez la réponse, pas des milliards de pages Web » (Google, s. d., par. 1). Les moteurs de recherche tentent de fournir le type de résultats que les internautes souhaitent en toute simplicité.
Cette simplicité ne signifie pas qu’utiliser Internet n’exige pas de compétences ni de littératie. Comme nous l’avons vu dans le premier chapitre, la littératie numérique et les autres littératies connexes (médiatique et visuelle) sont essentielles pour naviguer dans le monde en ligne. En outre, les internautes participent à l’élaboration et à la création du paysage de l’information en ligne. Pour être des participant.e.s actif.ve.s, engagé.e.s et capables de discernement, nous devons faire preuve de jugement et d’esprit critique. En d’autres mots, nous devons développer une littératie évaluative.
La littératie évaluative est la capacité d’évaluer l’information, c’est-à-dire de la contextualiser, de la critiquer et d’en confirmer la véracité. Elle consiste à développer la capacité de penser de manière critique : savoir que vous participez à un réseau plus grand que vous. Lorsque vous êtes devant une simple réponse d’une simple boîte de recherche, faites preuve d’esprit critique. Ce type de littératie fera de vous un citoyen numérique plus avisé, capable de déceler les mauvaises informations et de rechercher des faits mieux étayés. Il améliorera également vos autres compétences en littératie, ce qui vous permettra d’être mieux informé.e lorsque vous contribuerez aux communautés en ligne et d’être plus critique lorsque vous consommerez des médias.
La métalittératie, ou littératie de sa propre littératie, contribue à la littératie évaluative, car elle vous permet de signaler les lacunes de vos connaissances. Mackey et Jacobson définissent la métalittératie ainsi :
La métalittératie exige que les personnes comprennent leurs forces en matière de littératie, sachent ce qu’ils doivent améliorer et prennent des décisions concernant leur apprentissage. La capacité d’évaluer de manière critique ses différentes compétences et de reconnaître son besoin de littératies intégrées dans les environnements d’information actuels est une métalittératie. (Mackey et Jacobson, 2014, p. 2).
La métalittératie requiert de la curiosité et un peu d’humilité, soit de reconnaître ce que vous ne savez pas d’un sujet, puis d’être prêt à en apprendre davantage pour mieux comprendre.
Ce chapitre aborde les bases des réseaux d’information en ligne, à savoir les moteurs de recherche et les biais de l’information numérique. Ensuite, nous verrons comment développer des compétences en littératie évaluative et en métalittératie afin d’interagir avec ce réseau. Si nous comprenons mieux ce qui est souvent inconscient et non remis en question, nous pouvons tous devenir des citoyen.ne.s numériques plus vigilant.e.s.
Recherche sur le Web : Fonctionnement de Google
Les moteurs de recherche sont des outils essentiels pour naviguer sur Internet. Ils permettent aux internautes d’accéder rapidement au grand nombre de sites Web disponibles en ligne. Bien qu’il soit possible de taper des adresses Internet, la plupart des internautes utilisent les moteurs de recherche pour trouver du contenu en ligne (Forrester, 2016). Pour commencer, il est important de savoir comment ceux-ci fonctionnent pour comprendre l’organisation de l’information en ligne et nos interactions avec celle-ci. Comme l’écrit Alexander Halavais, professeur agrégé de sociologie (Université d’État de l’Arizona) et ancien président de l’Association of Internet Researchers, les moteurs de recherche « intéressent non seulement les technologues et les spécialistes du marketing, mais aussi quiconque veut comprendre comment nous donnons un sens à un monde nouvellement réseauté » (2009, p. 1). Il est important de les considérer non pas comme des « objets de vérité », mais comme des outils présentant des forces et des faiblesses de conception spécifiques (Halavais, 2009, p. 1 et 2).
Bien qu’il existe des différences entre les moteurs de recherche concurrents, ils fonctionnent tous essentiellement de la même manière. Le moteur de recherche envoie un outil de recherche automatique, un « collecteur » ou « robot d’indexation », pour explorer les pages Web accessibles au public. Le robot est un petit logiciel qui parcourt les liens et compile les informations des pages Web dans l’index du moteur de recherche. Lorsqu’un moteur de recherche reçoit une requête, il la compare à l’index et son algorithme complexe affiche les résultats. Le rôle de cet algorithme est de trouver des mots-clés qui correspondent à des pages Web pertinentes et d’afficher les résultats que vous souhaitez voir.
Ces trois éléments, le robot, l’index et l’algorithme, sont tous essentiels à la rapidité et au succès des moteurs de recherche. Les robots automatisent la collecte des données et récupèrent les informations plus rapidement qu’un humain ne pourrait jamais le faire, alors les résultats de la recherche peuvent suivre les mises à jour fréquentes des sites Web. L’index permet une recherche rapide des informations. Imaginez le temps qu’il faudrait pour traiter chaque requête si les moteurs de recherche devaient vérifier chaque page Web au lieu de se référer à un index. L’augmentation du trafic ferait planter le Web. L’algorithme augmente la pertinence, ce qui permet aux internautes de trouver une réponse plus rapidement parmi les résultats. Plus les résultats d’un moteur de recherche sont pertinents, plus ils sont satisfaisants pour les internautes.
Le saviez-vous?
Un site Web est un ensemble de pages Web. Par exemple, le site Web de l’Université Ryerson http://www.ryerson.ca/ contient la page Web « About », http://www.ryerson.ca/about/, la page Web « Campus Life » https://www.ryerson.ca/campus-life/ et ainsi de suite.
Bien qu’il existe un certain nombre de moteurs de recherche importants, tels que Bing et Yahoo, aucun ne domine autant que Google. Depuis 2006 environ, Google détient la majorité des parts de marché des moteurs de recherche* (Google Gains Search Market Share). Il génère ainsi des revenus croissants chaque année et s’impose comme le moteur de recherche « dominant » en Amérique du Nord* (Frommer, 2014). Pour justifier sa position dominante et son « statut de monopole », Safiya Noble cite les chercheurs universitaires de renom Siva Vaidhyanathan et Elad Segev, ainsi que la sous-commission de la commission judiciaire du Sénat américain sur la politique antitrust, la concurrence et les droits des consommateurs (Noble, 2018, p. 26 à 28, 36). En février 2017, comme le montre la figure 5.1 ci-dessous, Google détient la majorité des parts de marché sur tous les types d’appareils, devançant de loin ses concurrents. En raison de la domination de Google, les moteurs de recherche concurrents ont copié une grande partie de ses fonctionnalités. Par conséquent, apprendre comment fonctionne Google est un bon moyen de comprendre la recherche sur le Web en général. Ce chapitre se concentre surtout sur Google car, en ce moment, sa fonctionnalité inégalée et sa position dominante sur le marché font en sorte qu’il est plus important que les autres moteurs de recherche. Si les moteurs de recherche étaient des étendues d’eau, certains seraient les Grands Lacs ou la mer Baltique et Google, lui, serait l’océan Atlantique.
*Une exception importante à la domination de Google : Google est bloqué en Chine et y est donc supplanté par d’autres moteurs de recherche, par exemple Baidu.
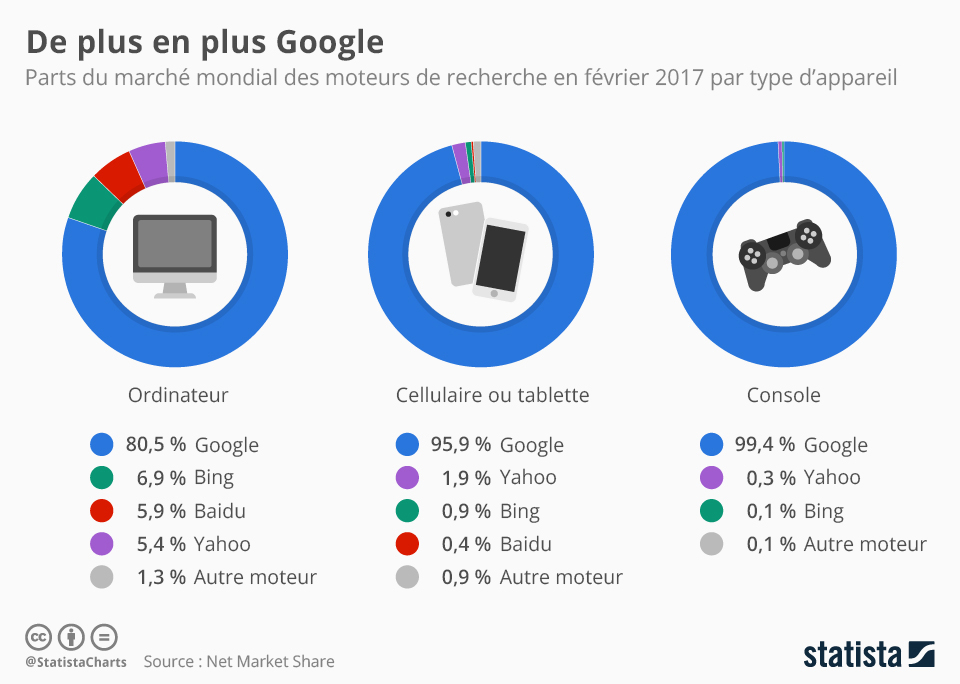
La domination de Google peut en partie être attribuée à son succès précoce. PageRank a été développé par les fondateurs de Google, Sergey Brin et Lawrence Page (1998), alors qu’ils étaient à Stanford. Cet algorithme classe les sites Web en fonction du nombre de liens qu’ils ont avec d’autres sites. Plus il y a de liens entrants ou de liens vers un site Web, plus le classement est élevé; comme pour les élections au secondaire, la popularité est essentielle pour atteindre le sommet. La logique veut que plus un site est populaire, plus il est pertinent pour l’internaute. L’algorithme PageRank, une idée extrêmement influente, a permis à Google de connaître un succès précoce, d’influencer ses concurrents et d’amener les moteurs de recherche à se concentrer sur la pertinence.
Activité 5.1 : Liens entrants et PageRank
Plusieurs outils permettent d’analyser les statistiques du trafic Web et les liens entrants, notamment Moz Open Site Explorer et Alexa. Essayez d’utiliser l’un de ces outils (vous devrez peut-être créer un compte) pour visualiser les liens entrants, le trafic et le classement d’un site Web tel que https://www.nytimes.com. Si l’algorithme de Google peut être caché, de nombreux aspects de la recherche sur le Web sont vérifiables par des tests empiriques.
Principaux apprentissages
Selon les algorithmes de recherche qui tiennent compte des liens entrants, créer un lien vers un site, c’est voter pour lui. Il est préférable de ne pas créer un lien vers un site, un message en ligne ou une publication si vous ne voulez pas contribuer à son succès.
Dans l’algorithme actuel de Google, PageRank reste un élément important de la structure globale (Luh, Yang et Huang, 2016), mais ce n’est qu’un facteur parmi des centaines d’autres. Pour Google et d’autres moteurs de recherche, le nombre d’occurrences d’un terme de recherche, l’endroit où il apparaît, l’actualité, la date de la dernière mise à jour et le temps de chargement déterminent le classement d’une page Web. Des informations sur l’internaute influencent également la pertinence des résultats générés, notamment son emplacement et son historique de recherche. Cet historique de recherche est tiré des informations du compte, par exemple Gmail pour Google, Microsoft pour Bing ou d’autres comptes pour les moteurs de recherche correspondants. Les témoins des navigateurs stockent également des informations qu’un moteur de recherche peut exploiter. Les navigateurs peuvent stocker des informations sur l’activité en ligne des internautes, même lorsqu’ils n’effectuent pas de recherche ou n’utilisent pas de comptes de recherche. L’utilisation d’un mode « incognito » ou d’un mode de navigation privée limite la quantité d’informations personnelles collectées, mais elle ne l’empêche pas complètement.
Bien entendu, il est impossible de déterminer tous les facteurs de l’algorithme de Google. Même si des chercheur.euse.s d’Internet diligents ont déchiffré certains aspects de l’algorithme et que Google en a dévoilé quelques-uns (voir l’article « How Search Works » de Google), la formule exacte de ce secret bien gardé rapporte des milliards de dollars. L’algorithme actuel, composé d’autres algorithmes, est incroyablement complexe, et de nombreux facteurs compliqués s’influencent entre eux. Il inclut des algorithmes tels que RankBrain, qui détermine l’intention de l’internaute pour évaluer la pertinence au moyen de l’intelligence artificielle, également appelée apprentissage automatique ou apprentissage profond. L’algorithme traite d’immenses quantités de données pour apprendre à définir l’intention de l’internaute. La force des systèmes d’intelligence artificielle est de pouvoir traiter plus de données que les humains ne pourront jamais le faire (Metz, 2016). Un moteur de recherche comme Google est, dans le jargon informatique, une boîte noire : ses mécanismes de détermination des résultats sont invisibles et il est impossible de savoir exactement pourquoi ils ont été obtenus. Ce principe a toujours été vrai pour les internautes en général et, aujourd’hui, en raison des progrès de l’intelligence artificielle, même les ingénieur.e.s qui ont conçu l’algorithme pourraient difficilement expliquer les résultats d’une requête.
Voici quelques caractéristiques majeures de la recherche sur le Web que tous les internautes devraient connaître. En voici quelques exemples : les résultats des recherches sur le Web ne comprennent que des informations accessibles au public. Puisque l’accent est mis sur les résultats les plus populaires, les informations les plus récentes ont plus de chances d’apparaître que les plus anciennes. De plus, les résultats varieront selon la personne qui effectue la requête et l’endroit où elle se trouve. Les sites optimisés pour la publication sur le Web apparaîtront également plus haut dans les ensembles de résultats et seront plus facilement consultables. C’est le principe de l’optimisation pour les moteurs de recherche (SEO). Même si les sites Web gérés à peu de frais peuvent avoir un excellent référencement, plus le budget d’un site Web est important, plus il est probable que son équipe de création ait investi temps et argent dans l’amélioration du référencement. En conséquence, la structure de la recherche sur le Web favorise les sites plus commerciaux, qui constituent au départ une grande partie du contenu du Web.
Le saviez-vous?
La devise officieuse de Google est « Ne soyez pas malveillants ». C’était sa devise officielle, incluse dans son code de conduite d’entreprise, jusqu’en 2015 (Bock, 2011). Il peut être surprenant de voir le mot « malveillant » dans une déclaration d’entreprise. Mais si Google avait l’intention de faire le mal, elle pourrait le faire : elle détient un énorme pouvoir sur l’accès aux informations du monde entier. En revanche, voici l’énoncé de mission de Google : « Notre objectif est d’organiser les informations à l’échelle mondiale pour les rendre accessibles et utiles à tous. » Si l’accès universel à l’information est un objectif noble, comme la plupart d’entre nous le reconnaissent, cette seule entreprise peut à la fois engendrer un bien et un mal incroyables.
Articles connexes
Pour en savoir plus sur les algorithmes, consultez la liste de lecture Critical Algorithm Studies du Microsoft Research Lab (Gillespie et Seaver, 2016).
Pour en savoir plus sur PageRank, consultez l’entrée de Wikipédia sur ce sujet, qui en donne un aperçu et le compare à d’autres algorithmes de classement (contributeur.trice.s de Wikipédia, 2019). L’article de Wikipédia sur PageRank sera probablement mis à jour si Google cesse d’utiliser cet algorithme pour déterminer les résultats de recherche. Puisque Wikipédia peut être modifiée par n’importe qui à tout moment, c’est une bonne occasion de s’entraîner à lire avec un œil critique.
Critiquer les résultats des recherches sur le Web
Comprendre la structure des moteurs de recherche sur le Web est le premier pas pour les aborder avec une attitude critique, c’est-à-dire en connaître les forces, les faiblesses et les biais inhérents. En raison de leur structure, certains moteurs de recherche traitent les requêtes mieux que d’autres. Par exemple, si vous recherchez « sushi », Google peut montrer des évaluations et emplacements de restaurants, voire des itinéraires vers les plus proches. Ces résultats seraient pertinents si vous cherchiez un endroit où manger. Ils le seraient moins si vous vouliez des recettes de sushi ou en savoir plus sur l’histoire de ce mets. Dans ce cas, il faudrait ajouter des mots-clés pour préciser la recherche.
Activité 5.2 : Comparaison des différents moteurs de recherche
Examinez les résultats de la recherche de « sushi » dans différents moteurs de recherche.
- Recherchez « sushi » dans trois moteurs de recherche : Google, DuckDuckGo et Ask.
- Comparez la première page de résultats. En quoi sont-ils identiques? Qu’est-ce qui est différent?
- Les trois séries de résultats comprennent-elles des informations spécifiques à votre emplacement? Pourquoi?
- Combien de résultats de la première page de recherche sont de nature commerciale (liés à l’achat et à la vente)?
Pendant l’activité ci-dessus, vous avez peut-être remarqué une différence entre la place des sites Web commerciaux et des sites Web non commerciaux dans les résultats de recherche. Autrement dit, de nombreux contenus en ligne ont des fins commerciales. Ces résultats, dus en partie à un bon référencement, arrivent souvent en tête. L’interface du moteur de recherche peut renforcer l’accent mis sur le mercantilisme. Plusieurs moteurs de recherche, dont Google, affichent des publicités sur leur première page de résultats, ce qui les rend difficiles à distinguer pour les internautes. La majorité des revenus de Google provient de la publicité (Alba, 2017), un fait dont il convient de tenir compte lors de l’évaluation de la proéminence des publicités dans la conception de l’interface et de l’algorithme.
Dans Google, les résultats par défaut pour « sushi » concernent les restaurants proches, car l’algorithme a déterminé que ce sont les informations les plus pertinentes pour la plupart des internautes. Il s’agit d’un exemple banal, quoique consumériste, qui illustre comment les moteurs de recherche privilégient certains types d’informations par rapport à d’autres. Pour voir des exemples moins anodins, il faut se tourner vers des types d’informations plus controversés. Lorsqu’une recherche d’informations géographiques est effectuée dans Google, les cartes de Google Maps s’affichent souvent en premier. Les représentations cartographiques de Google des frontières contestées politiquement, telles que celles entre Israël et la Palestine ou la Chine et le Tibet, reflèteront les délimitations acceptées par le gouvernement du pays dans lequel la recherche est effectuée. Les frontières présentées à un.e internaute en Israël ne seront pas les mêmes que pour un.e autre en Palestine. D’une certaine façon, ils verront une version différente du monde. Google prétend qu’elle tente de rester neutre dans la mesure du possible en pratiquant une « cartographie agnostique », mais elle respecte également les lois des pays dans lesquels elle est présente (Usborne, 2016). Si un gouvernement déclare qu’il est illégal de représenter les frontières d’une certaine manière ou même de partager des informations sur un territoire occupé, la version locale de Google s’y conformera.
Principaux apprentissages
La popularité n’est pas synonyme d’autorité ou de crédibilité. D’ailleurs, les résultats des recherches sur le Web reflètent des biais culturels.
Les litiges frontaliers sont un bon exemple de la manière dont Google déforme les informations, mais il y en a d’innombrables autres. L’experte en biais algorithmiques Safiya Noble (2016) décrit très bien les recherches problématiques liées à la race et au genre dans Google. Étant donné que Google privilégie les informations populaires, actuelles et adaptées aux algorithmes, souvent, ses résultats reflètent, voire amplifient les idées culturelles dominantes, y compris le racisme et le sexisme. Dans la vidéo ci-dessous, Noble décrit comment le racisme et le sexisme se manifestent dans les corrections automatiques des moteurs de recherche, les résultats de recherche biaisés et la préférence pour les informations fausses, mais populaires par rapport aux faits. Par exemple, elle décrit comment les résultats de recherche concernant Trayvon Martin s’articulent autour du récit de sa mort. Ce constat dérange, car il dresse un portrait incomplet de sa vie, comme s’il n’était que la victime d’un crime racialisé. Analyser les résultats du moteur de recherche pour Trayvon Martin permet de réfléchir aux lacunes des informations à notre disposition en ligne. Noble décrit également comment Dylann Roof, le tireur de masse raciste, a trouvé la confirmation de ses croyances suprémacistes en plein essor sur un site haineux. Parce qu’il affiche un semblant de crédibilité et arrive en tête des résultats de recherche sur les « crimes des Noirs contre les Blancs », le site trouvé par Roof a pu perpétuer des mythes racistes et inspirer un tueur. Contrairement à l’outil de référence classique qu’est l’encyclopédie, Google ne dispose pas d’éditeur.trice.s responsables de vérifier les faits, de rapports équilibrés ou de restrictions sur des sujets tels que les discours haineux. De plus, une encyclopédie ne change pas en fonction des informations lues précédemment, alors que le classement de pertinence de Google évolue constamment. Par conséquent, plus les internautes cherchent du contenu raciste, plus ils en trouvent.
Jetez un coup d’œil à la présentation de Safiya Noble lors du Personal Democracy Forum 2016 : « Challenging the Algorithms of Oppression » (remettre en question les algorithmes d’oppression). Droits d’auteur : Safiya Noble, Personal Democracy Forum.
Pause et réflexion
La vidéo de Safiya Noble (2016) est dérangeante pour plusieurs raisons. Elle décrit comment Internet est un outil puissant, mais il est important de se rappeler que les informations qu’il contient ne sont qu’une partie des informations disponibles dans le monde. Il est très facile de se retrouver dans une chambre d’écho, un environnement en ligne qui renforce vos biais préexistants sans remettre en question votre opinion ou vous exposer à de nouvelles idées. Les chambres d’écho peuvent être activées par des structures Web, telles que l’algorithme de Google, qui sont spécifiquement conçues pour prévoir les informations que vous trouverez pertinentes et vous les présenter.
Ces exemples soulignent certains des problèmes inhérents à l’utilisation des moteurs de recherche. Ces lacunes ne signifient pas que les moteurs de recherche sont mauvais ou qu’il ne faut pas les utiliser. Il faut plutôt comprendre leurs biais et leurs limites inhérentes en tant qu’outils. Les moteurs de recherche comme Google fondent leurs algorithmes sur le comportement des internautes et sur le contenu disponible en ligne. Ils reflètent ainsi la société qui les a créés, réaffirmant souvent les systèmes de pouvoir, soit le capitalisme, les régimes politiques dominants et la suprématie blanche. Lors de l’évaluation des informations, il est important de se poser les questions suivantes : Quel est le métarécit, ou l’histoire globale, qui est racontée? Quelles voix ne sont pas entendues? Nous aimons croire qu’Internet est un lieu où toutes les voix peuvent être entendues, mais c’est malheureusement faux. Comme l’écrit Alexander Halavais (2009), l’information sur le Web n’est pas plate ni égale; elle est « morcelée », c’est-à-dire organisée de telle sorte que les sites et les voix les plus populaires représentent la majeure partie du trafic (p. 60). La conception des moteurs de recherche et des algorithmes de classement par pertinence « accroît le déséquilibre actuel » (p. 68). Même les programmeur.euse.s de Google admettent que leurs conceptions contiennent des biais sociétaux, bien qu’ils soient plus enclins à utiliser un mot comme « équité » pour atténuer le choc (Lovejoy, 2018).
Outre le fait qu’il favorise les sites populaires et les biais courants, Internet est également un outil puissant pour gagner les cœurs et les esprits aux causes extrémistes. Les groupes haineux sont en augmentation en Amérique du Nord et, selon les spécialistes, le recrutement en ligne en est l’une des causes. Un examen systématique de dix années de recherche sur le cyberracisme (Bliuc, Faulkner, Jakubowicz et McGarty, 2018) a révélé que les « groupes et individus racistes » partagent « une créativité et un niveau de compétence remarquables dans l’exploitation des possibilités offertes par la technologie moderne pour faire avancer leurs objectifs », qui comprennent le recrutement, le développement de communautés haineuses en ligne et la diffusion de contenus racistes (p. 85). Dans le monde numérique, « ceux et celles qui ont des programmes politiques régressifs ancrés dans le pouvoir blanc se connectent à travers les frontières nationales via Internet » (Daniels, 2012, p. 710). Contrairement au monde en ligne, il est peu probable que vous trouviez de la propagande raciste dans les collections de la plupart des bibliothèques ou des librairies, car les documents de ces collections sont soigneusement sélectionnés par des spécialistes de l’information afin d’exclure un tel contenu. En revanche, les recherches sur Internet sont sélectionnées et filtrées au moyen d’un processus hautement automatisé.
Les contenus racistes n’étant pas filtrés des recherches, les internautes non critiques peuvent devenir des cibles faciles pour les sites haineux. La pertinence que Google et d’autres moteurs de recherche s’efforcent de produire a pour effet que les internautes sont prêts à faire confiance à ces services pour obtenir des résultats, un phénomène que le bibliothécaire et ethnographe de l’Université de l’Indiana Andrew Asher appelle le « biais de confiance » (2015). Autrement dit, les internautes ont tendance à faire confiance aux résultats de recherche sans poser de questions, car, la plupart du temps, ils sont fiables. Par conséquent, ils sont vulnérables quand ces résultats sont mauvais. Les résultats de recherche doivent toujours être abordés avec une bonne dose de scepticisme. C’est à vous, en tant qu’internautes, d’évaluer les résultats d’une recherche en ligne et de repérer les biais. Pensez à la structure des moteurs de recherche tels que Google pour déterminer quand et comment il convient de les utiliser.
Pause et réflexion
Google prétend collecter et partager les informations en toute neutralité, mais qu’en est-il? Il est toujours pertinent de rappeler que les algorithmes sur lesquels s’appuient Google et tous les autres services Web ont été programmés par des gens qui ont leurs propres biais. De ce point de vue, tous les algorithmes reflètent l’idée qu’une autre personne se fait de la neutralité. Cette notion peut varier d’une personne à l’autre.
Articles connexes
Pour en savoir plus sur le mythe des crimes des Noirs contre les Blancs et sa diffusion dans les médias numériques, consultez l’article de 2018 du Southern Poverty Law Centre intitulé « The Biggest Lie in the White Supremacist Propaganda Playbook: Unraveling the Truth About ‘Black-on-White Crime’ » (le plus grand mensonge du manuel de propagande de la suprématie blanche : découvrir la vérité sur les « crimes des Noirs contre les Blancs »). L’article fait l’historique de ce concept et souligne que « Internet a rendu infiniment plus facile pour les nationalistes blancs de se rassembler, de publier des articles, de discuter d’idées et d’atteindre les gens qui, comme Roof, pourraient être réceptifs à leurs messages » (Staff, 2018, par. 105).
Le clic tout-puissant : Internet et les médias
Les liens entrants entre les sites Web contribuent à façonner le Web, car ils rendent certains types de contenu plus faciles à trouver que d’autres. Cependant, il n’est pas nécessaire d’être un.e éditeur.trice de sites Web pour prendre part aux changements. Même si vous n’utilisez pas les médias sociaux ou n’avez jamais écrit de blogue, vous avez tout de même contribué à façonner Internet en consommant du contenu. En effet, les moteurs de recherche sont dynamiques et réactifs. Chaque clic d’une page Web contribue à son rang de trafic et à sa popularité. Les clics sont un facteur important du classement de chaque site Web dans les moteurs de recherche, de Wikipédia au site officiel de la Maison-Blanche. De nombreux sites, y compris ceux de médias réputés comme le New York Times, dépendent des revenus publicitaires pour rester en activité. C’est l’une des raisons d’être des appâts à clics : même si leur contenu est généralement décevant, leur titre est si intrigant qu’ils attirent du trafic et, par conséquent, ils génèrent des revenus publicitaires.
Par conséquent, les sites Web qui reçoivent des clics prospèrent. Prenons l’exemple du phénomène connu sous le nom de cyberchondrie, l’anxiété provoquée par la recherche d’informations médicales en ligne. Une étude réalisée en 2009 par White et Horvitz décrit comment « les moteurs de recherche sur le Web peuvent aggraver les préoccupations médicales ». En effet, une recherche sur la « douleur thoracique » donnera des résultats sur des problèmes de santé graves, par exemple une crise cardiaque. Parce qu’ils craignent le pire, les internautes risquent de cliquer sur des résultats liés à cette grave maladie. Étant donné que ces clics façonnent ensuite la structure du Web, une recherche sur la douleur thoracique classera les résultats relatifs aux crises cardiaques plus haut que d’autres affections moins graves. C’est un cercle vicieux d’anxiété qui fait que la plupart des personnes qui cherchent de l’information médicale sur des troubles bénins en concluent que leur mort est imminente.
L’un des effets les plus importants a été le phénomène récent des « fausses nouvelles », une expression qui a gagné en popularité en 2016 lors de la campagne et de l’élection présidentielles aux États-Unis. La désinformation a toujours existé – pensez au vieil adage selon lequel l’histoire est écrite par les vainqueurs – mais les « fausses nouvelles » sont une version distincte et contemporaine de la désinformation. Les revenus générés par les clics ont eu une influence majeure sur les médias en ligne, comme nous l’avons vu au chapitre 2. Par exemple, les lecteur.trice.s peuvent parcourir les titres sur les sites d’agrégation de nouvelles, comme Facebook ou Flipboard, sans prêter attention à l’auteur.trice ou à la source d’information. Les fausses nouvelles se concentrent généralement sur un contenu d’actualité sensationnel ou émotionnel, tel qu’un événement électoral de dernière minute. Ce type de contenu exige une lecture et une réponse rapides, plutôt qu’une analyse approfondie. Les fausses nouvelles s’appuient sur le format des nouvelles en ligne pour réussir : elles sont facilement accessibles, survolées et partagées. Cependant, elles s’inspirent aussi profondément des principales faiblesses du comportement humain. Elles font appel à nos émotions et, par conséquent, nous sommes moins enclins à être critiques. De plus, lorsque les informations correspondent à nos croyances et à nos biais préexistants, nous les remettons moins souvent en question. En psychologie, il s’agit du biais de confirmation. Les fausses nouvelles ont du succès parce qu’elles sont scintillantes et attrayantes sur le plan émotionnel. Tout comme les informations médicales alarmantes, les fausses nouvelles se nourrissent de leur propre popularité. Plus elles reçoivent de clics, plus elles se diffusent.
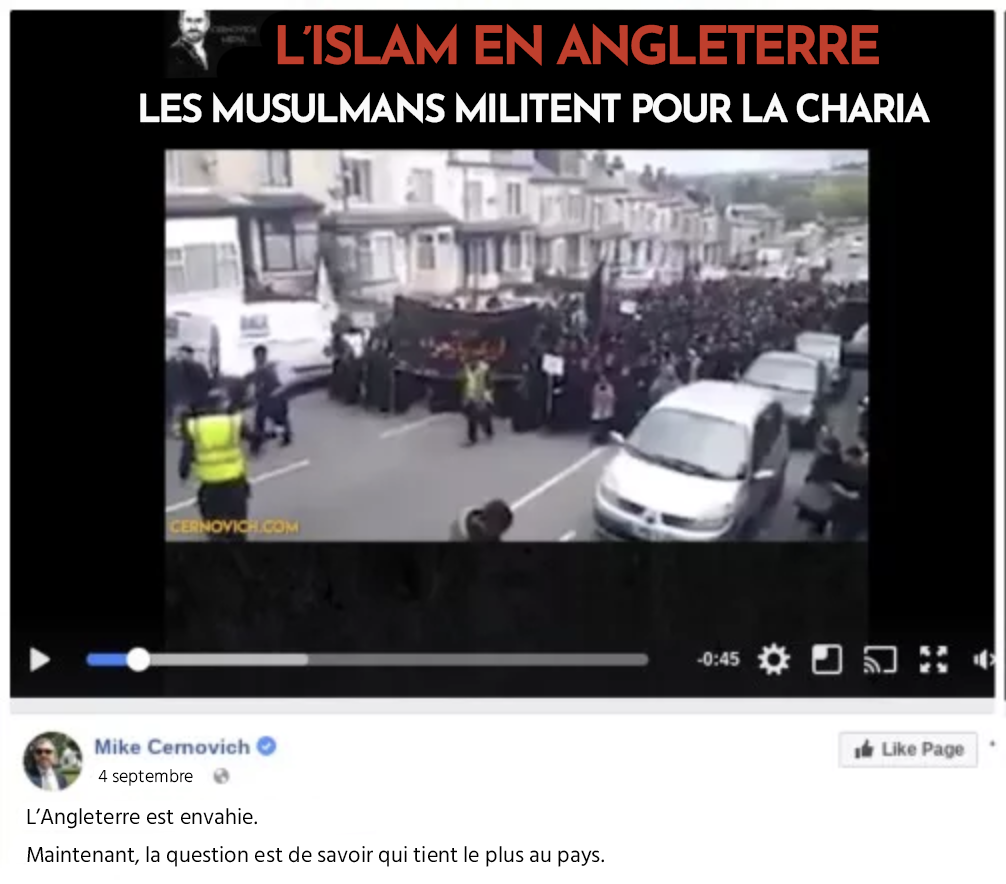
Le succès des fausses nouvelles est également dû à notre préférence très humaine pour la commodité. Il est facile de lire les titres. Intellectuellement, il est beaucoup plus exigeant et plus long d’exercer son esprit critique, de faire des recherches approfondies et de remettre régulièrement les sources en question. C’est pourtant ce qu’il faut pour être un cybercitoyen responsable et un.e internaute efficace. Plus vous serez conscients des biais qui existent dans les systèmes d’information numériques, ainsi que de vos propres biais et angles morts émotionnels, mieux vous serez armés pour contrecarrer les biais de tous types.
Trousse d’évaluation
Jusqu’à présent, ce chapitre a abordé la question de la critique des résultats de recherche. Nous allons maintenant nous concentrer sur l’évaluation des sources en ligne elles-mêmes. D’ici à ce que, en tant que société, nous puissions réinventer Google ou limiter les discours haineux et les autres informations erronées en ligne, des objectifs compliqués, notre meilleure ligne de défense, c’est nous-mêmes. Développer une littératie évaluative est essentiel pour se protéger des mauvaises informations, et la meilleure façon d’y arriver est de s’y exercer régulièrement. Remettez en question l’auteur.trice que vous lisez. Vérifiez ses méthodes de recherche. Examinez les publications dans lesquelles il ou elle écrit et sa raison de le faire. Des spécialistes, des recherches bien fondées et des publications crédibles peuvent résister à ce type d’examen. La curiosité est la meilleure forme de défense contre la désinformation.
Bien entendu, une trousse peut aussi vous aider à déterminer quelles informations sont utiles ou non. La trousse suivante est divisée en deux parties : l’évaluation de tous les types d’information et l’évaluation de l’information numérique.
Évaluez tous les types d’information
Le test PARCA est un outil classique qui peut être utilisé pour évaluer tout type d’information (en ligne et hors ligne), qu’il s’agisse de sources universitaires ou populaires, matérielles ou numériques. Cet outil peut vous aider à receler les forces, les faiblesses et les biais d’une ressource. Le test PARCA permet une évaluation approfondie, mais il peut également servir d’exercice rapide une fois que vous avez bien assimilé le test et le questionnement critique.
PARCA signifie « purpose, accuracy, relevancy, currency and authority » (objectif, exactitude, pertinence, actualité et autorité).
- Purpose (objectif)
- Quel est l’objectif de l’auteur.trice?
- Quel est le public cible?
- Quel est l’argument central? Quels sont les arguments implicites?
- Est-ce que l’auteur.trice participe à une conversation élargie sur ce sujet?
- Accuracy (exactitude)
- Est-ce que l’auteur.trice cite des preuves précises pour étayer son argumentation?
- Si oui, pouvez-vous les vérifier?
- Est-ce que la publication prend des mesures pour améliorer l’exactitude des informations, par exemple un processus d’évaluation par les pairs?
- Pouvez-vous distinguer les faits présentés de l’opinion qu’en a l’auteur.trice?
- Relevancy (pertinence)
- Ces travaux sont-ils pertinents par rapport à votre recherche?
- Comment les intégreriez-vous à votre propre rédaction ou création?
- Proviennent-ils d’une discipline pertinente?
- La pertinence de cette ressource modifiera-t-elle votre stratégie de recherche?
- Currency (actualité)
- Quand cet ouvrage a-t-il été publié?
- Les faits relevés par l’auteur.trice sont-ils actuels?
- Si l’auteur.trice écrit à propos d’une époque et d’un lieu particuliers, les circonstances ont-elles changé?
- Quelle est l’importance de l’actualité dans ce domaine d’étude? Par exemple, l’actualité est très importante pour la recherche scientifique de pointe, mais peut l’être moins pour l’analyse littéraire.
- Autorité (Authority)
- Qu’est-ce qui fait de l’auteur.trice un.e spécialiste? Tenez compte des références, de l’expérience, des publications antérieures, de l’identité et de tout autre indicateur.
- Est-ce que l’auteur.trice a déjà publié sur ce sujet? Quand et où?
- S’agit-il d’une publication réputée?
- Ce travail provient-il d’un courant dominant ou d’une perspective marginalisée?
Évaluer l’information numérique
Le test PARCA vous permet d’examiner en profondeur le contenu d’une ressource. Cependant, il ne se penche pas sur le format ni sur le contexte élargi de l’œuvre. Les deux sections suivantes, « Outils techniques » et « Vérification des faits », vous aideront à le faire. Les publications Web et les sites Web, qu’il s’agisse d’articles du New York Times ou de blogues, sont les produits d’un réseau en ligne qui doivent être lus dans ce contexte spécifique.
Outils techniques
Cette liste de conseils devrait servir d’introduction de base à certaines caractéristiques propres à l’information numérique. Il ne s’agit pas de règles strictes; par exemple, un site qui se termine par « .edu » est normalement affilié à un établissement d’enseignement, mais ce n’est pas toujours le cas. Les sources de désinformation en ligne copient souvent les signes de légitimité pour passer inaperçues. Comme toujours, faites preuve d’esprit critique. Contrairement au test PARCA, l’utilisation de ces conseils se veut une forme d’évaluation rapide et immédiate.
- Vérifiez l’adresse : Les sources d’information légitimes ont généralement une adresse professionnelle qui correspond au nom de leur organisation. Par exemple, le site Web de Radio-Canada Info est https://ici.radio-canada.ca/info. Les adresses de fausses nouvelles sont moins susceptibles d’avoir une allure professionnelle ou d’être associées à des organes de presse distincts. Elles peuvent avoir une adresse qui décrit leur mission et leur biais; elles peuvent également tenter de paraître légitimes en adoptant un nom formel. Ce n’est pas parce que le titre du site que vous visitez contient les mots « Association » ou « Chronique » qu’il est légitime; vous devrez peut-être vérifier les faits plus en détail.
- Notez le domaine de premier niveau de l’adresse : Le domaine est le nom de l’adresse d’un site Web, par exemple ici.radio-canada.ca. Chacun des éléments de cette adresse Web a une fonction spécifique. La partie « .ca » de cette adresse correspond au domaine de premier niveau. D’autres domaines de premier niveau courants sont « .com », « .org » et « .edu ». Il est facile de s’y méprendre. La réglementation relative à l’enregistrement des noms de domaine est limitée, de sorte qu’un domaine de premier niveau « .org », qui désigne habituellement les sites d’organismes à but non lucratif, ne garantit pas que c’est le cas. Les adresses des sites de fausses nouvelles imitent parfois celles des sites légitimes, mais leur domaine de premier niveau est différent : par exemple, le domaine de premier niveau de http://ici.radio-canada.ca.co/info est « .co ». C’est la partie finale « .co » qui détermine l’emplacement du site Web, et cette adresse n’a rien à voir avec le site ici.radio-canada.ca.
- Déterminez la nature du site : Vérifiez la présence d’une page « À propos de nous » ou « Nous contacter ». Comment ce site se décrit-il? Si le site est présent sur les médias sociaux, comment s’y présente-t-il? Recherchez des mots-clés liés aux biais, des déclarations qui semblent incendiaires ou des faits douteux.
- Analyser la qualité de la conception du site Web : Les sites Web mal conçus, par exemple, comportent trop de couleurs, de polices et de GIF animés, en plus de mal utiliser l’espace blanc. La bonne conception d’un site Web est un signe de crédibilité. Un organe de presse comme Radio-Canada peut se permettre d’engager un.e ou plusieurs spécialistes en conception de sites Web; il ne peut pas se permettre d’avoir un site Web d’apparence non professionnelle. Par contre, les sites bien conçus ne sont pas tous légitimes. Le contraire est aussi vrai. Des individus ou groupes condamnables peuvent investir dans la création de beaux sites, tandis que certains organismes admirables ne le peuvent pas; cependant, l’impression visuelle générale d’un site vous dévoilera habituellement ses intentions et son objectif.
- Consultez les liens de l’article : Y en a-t-il et fonctionnent-ils? Dans quelle mesure sont-ils récents ou à jour? Les liens d’une page Web à une autre en disent long sur l’affiliation politique du site et sur ce que l’auteur.trice considère comme faisant autorité. Par exemple, un site politique de droite aura tendance à créer des liens vers d’autres sites politiques de droite. Internet est une grande toile : à quels autres fils de cette toile votre site est-il relié?
Vérification des faits
Dans une étude réalisée en 2017 à l’Université de Stanford, où les participant.e.s ont eu à comparer deux sites Web – celui de la légitime American Academy of Pediatrics et celui du site homophobe dissident American College of Pediatricians – les historien.ne.s et les étudiant.e.s ont obtenu des résultats médiocres par rapport aux vérificateur.trice.s de faits (Wineburg et McGrew, 2017). Les vérificateur.trice.s de faits, en plus d’être bien plus nombreux à reconnaître le site illégitime, l’ont fait en beaucoup moins de temps. Les chercheur.euse.s en ont conclu que la vérification des faits et la lecture latérale sont des compétences essentielles pour évaluer les informations numériques. La lecture latérale consiste à ouvrir de nouveaux onglets et à rechercher des informations sur une ressource ou un site Web, plutôt que de lire le contenu du site lui-même.
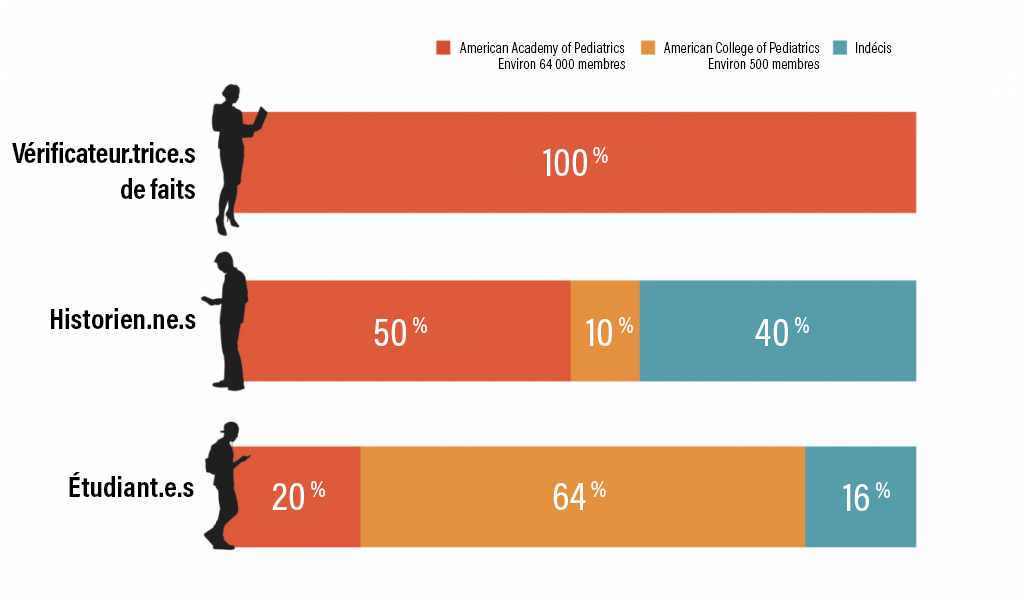
La vérification des faits consiste à confirmer le contexte de la source évaluée auprès de sources indépendantes. Voici quelques suggestions pour découvrir le contexte d’une source :
- Apprenez-en plus sur la publication : De nombreux sites Web peuvent vous aider à vérifier les faits d’un article en ligne et la réputation d’un site Web. Deux des sites les plus connus et les plus fiables sont factcheck.org et snopes.com. Vous pouvez consulter ces sites pour vérifier un fait douteux ou obtenir des informations sur un site. Rechercher une adresse entre guillemets dans un moteur de recherche vous aidera également à évaluer sa réputation. De plus, cette recherche n’entraîne pas de clics vers des sites que vous préféreriez ne pas visiter.
- Triangulez les informations : Lisez sur un sujet et vérifiez les faits à partir de plusieurs sources. Idéalement, les sources que vous comparez devraient avoir des perspectives et des objectifs différents. Pour aller encore plus loin, déterminez l’origine des faits. Ces informations proviennent-elles d’une source directe, telle qu’une étude, un rapport ou une enquête en personne, ou d’ailleurs? Retrouvez le document d’origine si possible. Le document d’origine lui-même provient-il d’une source crédible, par exemple une université ou un groupe de recherche réputé?
- Lisez sur l’auteur.trice : Parcourez d’autres œuvres de l’auteur.trice et trouvez des informations biographiques de base. Vous découvrirez peut-être des biais et des objectifs. Par exemple, un.e journaliste et un.e lobbyiste auront des objectifs différents. Si l’auteur.trice de l’article n’est pas indiqué, il s’agit d’un signal d’alarme que l’article a peut-être été généré par une usine à contenus et qu’il n’est peut-être pas soumis à une révision des publications.
- Faites des recherches sur les images : Si une image dans un article de presse vous semble suspecte, vérifiez dans TinEye ou Google Reverse Image Search si elle a été utilisée ailleurs. Si elle est légitime, la recherche d’autres images de la même scène peut vous fournir plus de détails.
- Vérifiez qui est le propriétaire du domaine : Si vous souhaitez savoir qui possède un site Web, consultez WHOIS. Par exemple, une recherche sur ici.radio-canada.ca montrera qu’il appartient à la Société Radio-Canada, ce qui est normal. Le fait de savoir qui est le propriétaire d’un domaine peut en dire long sur l’objectif du site.
Pause et réflexion
Wineburg et McGrew (2017) utilisent l’expression « lecture latérale » pour décrire la lecture au sujet d’une source, comme une page Web, plutôt que la lecture de la source elle-même. Cependant, il y a plus d’une façon de lire les textes connexes. La translittératie est définie comme « la pratique de la lecture d’un éventail de textes au moyen de plusieurs plateformes, modalités, types de lecture et genres de manière transparente » (Sukovic, 2016). La translittératie est une compétence essentielle pour l’analyse des chaînes de réseaux, qui consiste à suivre des liens, des citations et des idées d’une ressource à l’autre (Sukovic, 2016). Les ressources numériques encouragent la translittératie et l’analyse des chaînes de réseaux grâce à leur interconnexion, et la lecture latérale est une compétence essentielle pour évaluer l’information.
Activité 5.3 : Évaluez vos connaissances
- Avant de lire ce chapitre, quelles hypothèses aviez-vous sur la structure d’Internet? Comment ces hypothèses ont-elles évolué?
- Imaginez que vous avez pour tâche de créer un meilleur moteur de recherche. Comment pourriez-vous organiser les informations pour arriver à un meilleur équilibre entre celles qui montent et celles qui descendent dans le classement?
- Ce chapitre a décrit certains problèmes de la recherche sur le Web, par exemple la tendance à privilégier les informations les plus récentes. Pensez-vous qu’il existe d’autres biais dans les résultats des requêtes en raison de la structure de la recherche sur le Web?
- Si un gouvernement déclare qu’il est illégal de représenter les frontières d’une certaine manière, Google Maps cède-t-il à la censure s’il s’y conforme?
- Évaluez ce site Web en utilisant les techniques de vérification des faits : Qui est l’auteur.trice et quelle est son autorité? Pensez-vous qu’il s’agit d’un site Web fiable? Pourquoi?
- Après avoir vérifié les faits sur le site ci-dessus, évaluez cet article qui en est tiré à l’aide du test PARCA.
Ressources
Vérifier les informations sur le trafic Web :
- Statistiques, analyses et trafic du site Web d’Alexa
- MOZ Open Site Explorer : recherche de liens et vérificateur de liens retour
Vérifier les faits en ligne :
Rechercher des images, y compris des descriptions et des emplacements en ligne :
Déterminer le ou la propriétaire d’un domaine
Références
Alba, D. (2017). Google and Facebook still reign over digital advertising. Wired. https://www.wired.com/story/google-facebook-online-ad-kings/
Armstrong, M. (31 mars 2017). Google, Googler, Googlest. Statista. Retrieved from: https://www.statista.com/chart/8746/global-search-engine-market-share/. 2017.
Asher, A.D. (2015) Search Epistemology: Teaching students about information discovery. T.A. Swanson et H. Jagman (Eds.), Not just where to click: Teaching students how to think about information. (p. 139 à 154). Chicago, IL: Association of College and Research Libraries.
Bliuc, A., Faulkner, N., Jakubowicz, A. et McGarty, C. (2018). Online networks of racial hate: A systematic review of 10 years of research on cyber-racism. Computers in Human Behavior, 87, p. 75 à 86. doi:10.1016/j.chb.2018.05.026
Bock, L. (2011) Passion, not perks. Think with Google. https://www.thinkwithgoogle.com/marketing-resources/passion-not-perks/
Brin, S. et Page L. (1998). The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems, 30, p. 107 à 117. doi:10.1016/S0169-7552(98)00110-X
Caulfield, M.A. (2017). Web literacy for student fact-checkers. Pressbooks. https://Webliteracy.pressbooks.com/
Daniels, J. (2013). Race and racism in internet studies: A review and critique. New Media & Society, 15(5), p. 695 à 719. doi:10.1177/1461444812462849
Forrester Research. (2016). Why search + social = success for brands: The role of search and social in the customer life cycle. https://www.catalystdigital.com/wp-content/uploads/WhySearchPlusSocialEqualsSuccess-Catalyst.pdf
Framework for information literacy for higher education. (2015). Chicago: Association of College and Research Libraries. http://www.ala.org/acrl/standards/ilframework
Frommer, D. (19 août 2014). Google’s growth since its IPO is simply amazing. Quartz.
https://qz.com/252004/googles-growth-since-its-ipo-is-simply-amazing/
Gillespie, T. et Seaver, N. (15 décembre 2016). Critical algorithm studies: A reading list. Blogue de recherche de Social Media Collective. https://socialmediacollective.org/reading-lists/critical-algorithm-studies/
Google. Code of Conduct. Archivé le 19 avril 2010. https://Web.archive.org/Web/20100419172019/https://investor.google.com/corporate/code-of-conduct.html
Google. (s. d.). How search works. Google Inside Search. https://www.google.com/search/howsearchworks/
Halavais, A. (2009). Search engine society. Cambridge, MA: Polity Press.
Lovejoy, J. (2018). Fair is not the default. Google Design. https://design.google/library/fair-not-default/
Luh, C., Yang, S. et Huang, T.D. (2016). Estimating Google’s search engine ranking function from a search engine optimization perspective. Online Information Review, 40(2), p. 239 à 255.
Mackey, T.P., et Jacobson, T.E. (2014). Metaliteracy: Reinventing information literacy to empower learners. Chicago, IL: Neal-Schuman Publishers, Inc.
Metz, C. (4 février 2016). AI is transforming Google search. The rest of the web is next. Wired. https://www.wired.com/2016/02/ai-is-changing-the-technology-behind-google-searches/. 2014.
Noble, S. (15 juin 2016). Challenging the algorithms of oppression. Personal Democracy Forum (PDF). [Fichier vidéo]. https://www.youtube.com/watch?v=iRVZozEEWlE&feature=youtu.be
Noble, S.U. (2018). Algorithms of oppression: How search engines reinforce racism. New York, NY: New York University Press.
Noble, S.U., et Roberts, S.T. (décembre 2017). Engine failure: Safiya Umoja Noble and Sarah T. Roberts on the problems of platform capitalism. Logic, 3. https://logicmag.io/03-engine-failure/
Staff, H. (2018). The biggest lie in the white supremacist propaganda playbook: Unraveling the truth about ‘black-on-white-crime’. Southern Poverty Law Centre. https://www.splcenter.org/20180614/biggest-lie-white-supremacist-propaganda-playbook-unraveling-truth-about-%E2%80%98black-white-crime
Sukovic, S. (2016). Transliteracy in complex information environments. Amsterdam, MA: Chandos Publishing.
Usborne, S. (2016). Disputed territories: Where Google maps draws the line. The Guardian. http://www.theguardian.com/technology/shortcuts/2016/aug/10/google-maps-disputed-territories-palestineishere
White, R.W., Horvitz, E. (2008). Cyberchondria: Studies of the escalation of medical concerns in web search. Microsoft Research. https://www.microsoft.com/en-us/research/publication/cyberchondria-studies-of-the-escalation-of-medical-concerns-in-Web-search/
Contributeur.trice.s de Wikipédia. (26 juillet 2019). PageRank. Dans Wikipédia, l’encyclopédie libre. https://en.wikipedia.org/w/index.php?title=PageRank&oldid=907975070
Wineburg, S. et McGrew, S. (2017). Lateral reading: Reading less and learning more when evaluating digital information. Document de travail du Stanford History Education Group, 2017-A1. doi:10.2139/ssrn.3048994
Attribution des éléments visuels
- Image d’en-tête du chapitre © Hebi B
- Figure 5.1 Part de marché mondial des moteurs de recherche © Net Market Share sous licence CC BY-ND (Attribution NoDerivatives)
- Figure 5.2 © Snopes sous licence Tous droits réservés
- Figure 5.3 © Wineburg et McGrew, 2017. Sous licence Tous droits réservés