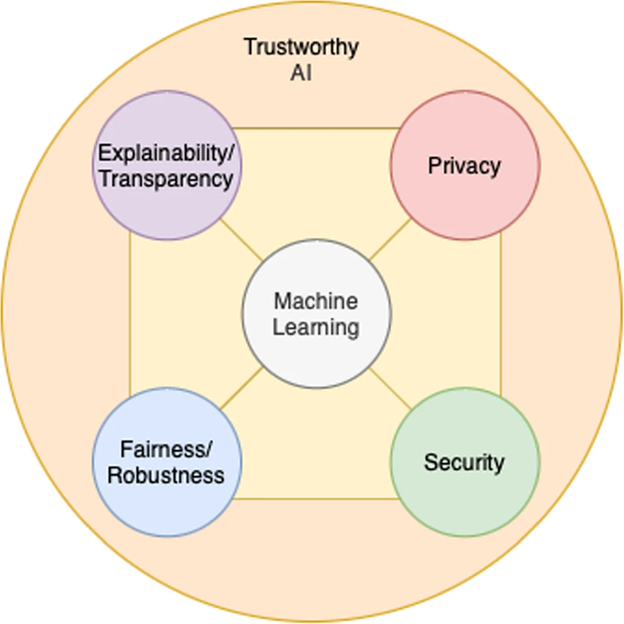
6.1 Introduction
Privacy attacks have emerged as a major threat to data security, enabling adversaries to infer sensitive details from information collected from user records. These attacks exploit vulnerabilities in statistical datasets and machine learning models to reconstruct private data, infer membership in datasets, or extract model parameters. This section explores key categories of privacy attacks and their implications, along with mitigation strategies.
A real-world concern
The Android operating system is one of the most widely used operating systems in smartphones, wearable devices, IoT devices, etc. Google needs a lot of user data to provide different types of features and a better user experience on the Android OS. However, it has been a big challenge for Google to collect user data due to privacy issues, new laws, and the complexity of storing and processing user data. Moreover, several studies show that more data will result in a better model. Therefore, Google needed an efficient solution to deal with these problems.
Solution: Federated Learning
In 2016, a research team from Google came across a new solution to preserve privacy while leveraging the data from its users’ devices. They coined this new approach, Federated Learning (FL), as shown in Fig. 6.1.2.
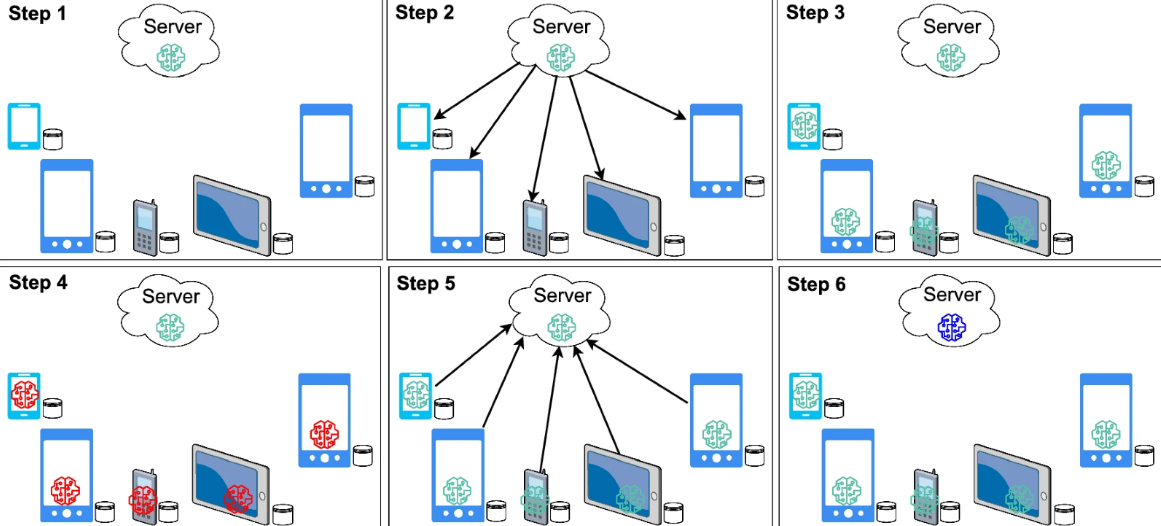
FL is the new paradigm in the ML family. In FL, the user no longer needs to share the data, as the data is always with the user. FL introduces the concept of sharing the model parameters instead of data. Therefore, it is also called the learning-by-parameters approach. The server creates and shares the global model with all users in this approach. Then, each user trains the model with local data on their own device and sends the model training parameters to the server. The server receives the parameters from each user, applies the aggregation to the parameters and updates the model parameters. The updated set of parameters will be shared with all users for the next round. The process will continue until convergence, after some pre-defined number of iterations or in a periodic fashion.
An important feature is that the training process is shifted from the central server to each user device (local device). Initially, FL was introduced for smartphone applications by Google, but its applicability is equally important in many contexts, e.g., hospitals, banks, and the Internet of Things.
Trust Model
The context of its deployment largely determines the trust model of any ML-based system as it relates to the trust placed in the relevant actors. We can think of several actors relevant to a deployed ML-based system to abstract a bit.
- First, there are data owners, the owners or trustees of the data/environment the system is deployed within, e.g., an IT organization deploying a face recognition authentication service.
- Second, system providers construct the system and algorithms, e.g., the authentication service software vendors.
- Third, there may be consumers of the system’s service, e.g., the enterprise users.
- Lastly, there are outsiders who may have explicit or incidental access to the systems or may be able to influence the system inputs, e.g., other users or adversaries within the enterprise.
Note that multiple users, providers, data owners, or outsiders may be involved in a given deployment.
A trust model for the given system assigns a level of trust to each actor within that deployment. Any actor can be trusted, untrusted, or partially trusted (trusted to perform or not perform certain actions). The sum of those trust assumptions forms the trust model and identifies how bad actors may attack the system.
“Trustworthy machine learning in the context of security and privacy” by Ramesh Upreti, Pedro G. Lind, Ahmed Elmokashfi & Anis Yazidi is licensed under Creative Commons Attribution 4.0 International, except where otherwise noted.
Trust Model from SoK: Security and Privacy in Machine Learning by

{kind=link}