5.1 Introduction
This chapter will introduce the concept of backdoor poisoning, explain how it works, discuss its implications, and explore mitigation strategies. Backdoor poisoning is a poisoning attack where an attacker manipulates the training data to embed a hidden trigger in the model. The model learns to associate this trigger with a specific target label during training. When the model is deployed, any input containing the trigger will cause the model to misclassify it as the target label, even if the input is otherwise correctly classified.
Example
For example, consider an image classifier trained to recognize different types of animals. An attacker could introduce a small patch (the trigger) into a subset of cat images and label them as dogs. Any image containing the patch will be misclassified as a dog during testing, regardless of its actual content. Figure 5.1.1
For a backdoor attack to be effective, the adversary should obtain high accuracy on clean samples and a high attack success rate on target-triggered samples simultaneously. Meanwhile, the trigger perturbation bug and the number of poisoning samples are also crucial for stealthiness concerns. The threat model and attack scenario mentioned in Chapter 4 also apply to Backdoor attacks.
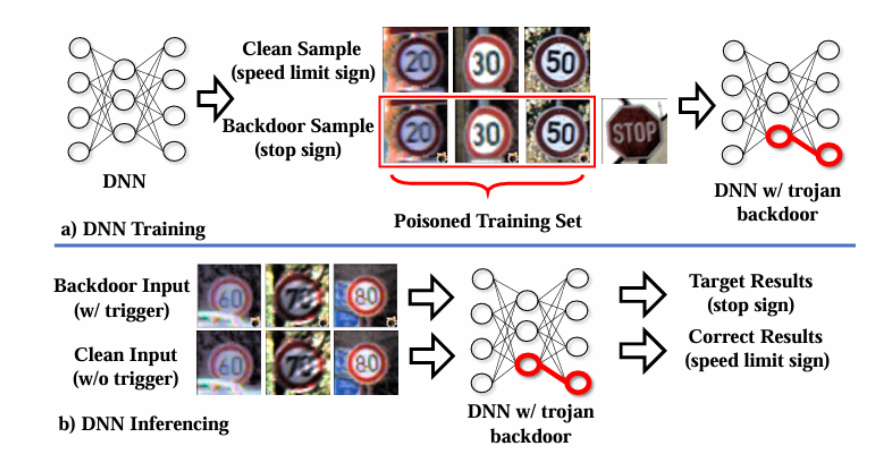
Figure 5.1.1 Description
Diagram showing a backdoor attack in deep neural networks (DNNs). During training, clean speed limit sign samples and backdoor samples (stop signs with trigger patterns) are included in a poisoned dataset. The resulting model contains a trojan backdoor. During inference, clean inputs are correctly classified as speed limit signs, but backdoor inputs with the trigger cause the model to misclassify them as stop signs, showing the effect of the trojan backdoor.
