4.1 Introduction
While adversarial attacks cannot change a model’s training process and can only modify the test instance, data poisoning attacks, on the contrary, can manipulate the training process (Figure 4.1.1). Specifically, in data poisoning attacks, attackers aim to manipulate the training data (e.g., poisoning features, flipping labels, manipulating the model configuration settings, and altering the model weights) to influence the learning model. It is assumed that attackers can contribute to the training data or have control over the training data itself. The main objective of injecting poison data is to influence the model’s learning outcome. Recent studies on adversarial ML have demonstrated particular interest in data poisoning attack settings.
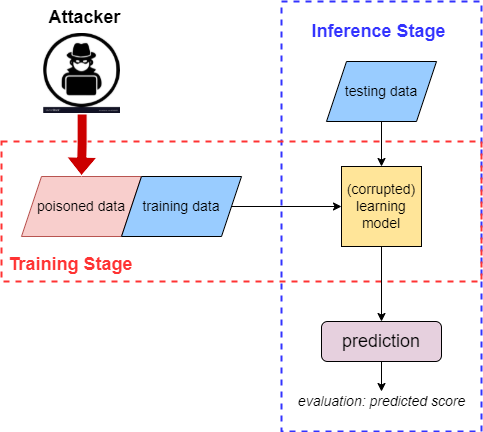
Figure 4.1.1 Description
A data poisoning attack on a machine learning pipeline. It is divided into two main sections: the Training Stage (highlighted with a red dashed border) and the Inference Stage (highlighted with a blue dashed border).
In the Training Stage, an attacker injects poisoned data into the training dataset, which also includes normal training data. These are combined and fed into the next phase. In the Inference Stage, testing data is input into a (corrupted) learning model, the result of training on the poisoned dataset. The corrupted model produces a prediction, which is evaluated by a predicted score.
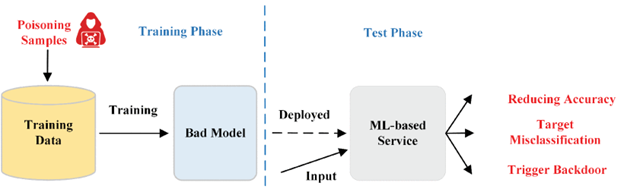
Figure 4.1.2 Description
A data poisoning attack on a machine learning model. In the training stage, an attacker injects poisoned data alongside legitimate training data, resulting in a corrupted learning model. During the inference stage, testing data is fed into the corrupted model, leading to manipulated predictions. The process concludes with an evaluation of the predicted score.
“ML Attack Models: Adversarial Attacks and Data Poisoning Attacks” by Jing Lin, Long Dang, Mohamed Rahouti, and Kaiqi Xiong is licensed under an Attribution-NonCommercial-ShareAlike 4.0 International, except where otherwise noted.

{kind=link}