1.2 Adversarial Attack Types: Model Processing and Development
The security landscape in machine learning is diverse and evolving. Threats can originate from adversaries targeting different stages of the ML pipeline, including data collection, training, model deployment, and inference.
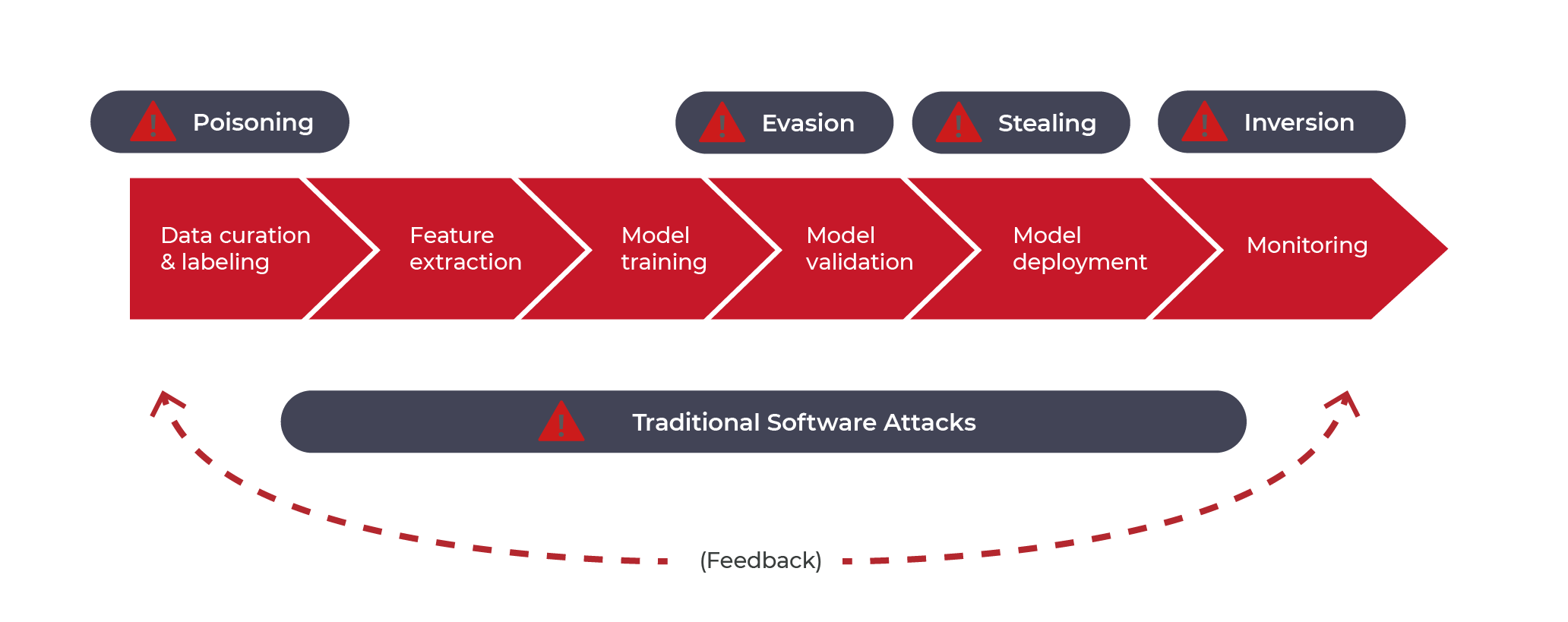
Figure 1.2.1 Description
This graph highlights various security threats in the lifecycle of an AI/ML model (Top Red Arrows) at various stages of development and deployment (Dark Labels) such as: Poisoning Attacks (Affecting data curation, feature extraction, and training), Evasion Attacks (Affecting validation and deployment), Stealing Attacks (Affecting deployed models), Inversion Attacks (Affecting monitoring and privacy) on the other hand (Bottom Dark Bar) Traditional Software attacks (cybersecurity threats) can interact with AI security risks, creating vulnerabilities and might cause new attack vectors for traditional software threats, and vice versa.(Feedback Loop (Dashed Arrow))
Adversarial attack types can be based on model processing and development, knowledge adversary, and capability and intention of the adversary.
Based on Model Processing and Development
Poisoning Attack
Training a machine learning model with the pre-processed dataset is the initial development phase, allowing adversaries to poison it. Poisoning attacks manipulate datasets by injecting falsified samples or perturbing the existing data samples to infect the training process and mislead the classification at test time. Poisoning the dataset in two formats can disrupt the victim model’s labelling strategy, known as a label poisoning attack (Gupta et al., 2023). Feature perturbation, leaving the integrated label as is, is known as a clean-label poisoning attack (Zhao & Lao, 2022). The attack surface for poisoning attacks on machine learning is highlighted in Figure 1.2.2.
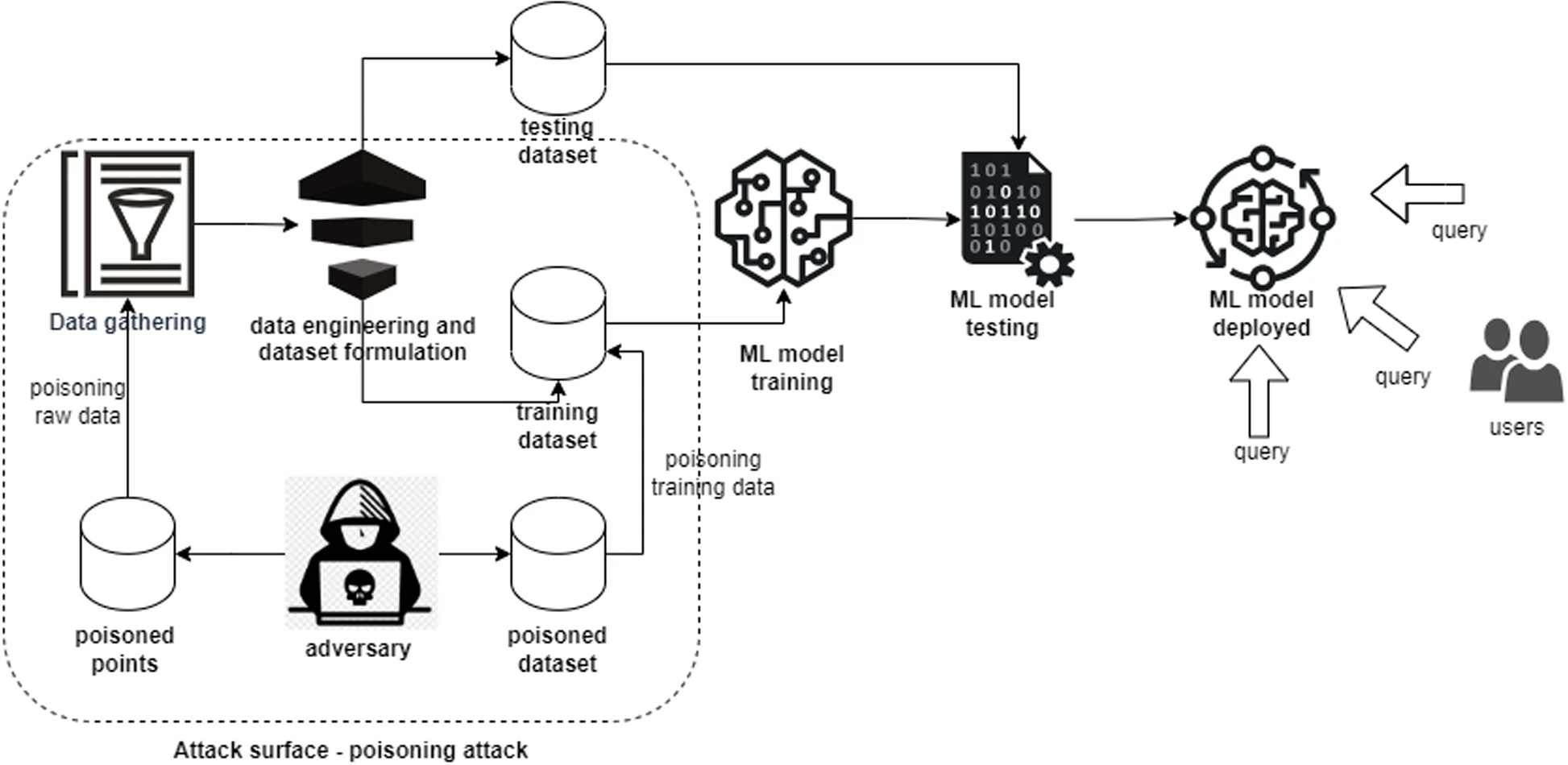
Figure 1.2.2 Description
A flowchart diagram illustrating a machine learning poisoning attack. The process starts with ‘Data gathering,’ which is influenced by an ‘Adversary’ injecting ‘Poisoned points’ into the dataset. These poisoned data points are incorporated into ‘Data engineering and dataset formulation,’ forming a ‘Poisoned dataset’ that is used for ‘ML model training.’ The trained model undergoes ‘ML model testing’ and is eventually ‘ML model deployed’ for user queries. The attack surface, marked with a dashed border, highlights the poisoning of raw and training data, which affects the integrity of the final machine-learning model.
Evasion Attack
Attacking the machine learning model at test time is called an evasion attack. This attack intends to mislead the testing data to reduce the testing accuracy of the targeted model (Ayub, 2020). The ultimate objective of this attack is to misconstruct the testing input to harm the test-time integrity of machine learning. Malware generative recurrent neural network (MalRNN) is a deep learning-based approach developed to trigger evasion attacks on machine learning-based malware detection systems (Ebrahimi et al., 2021). MalRNN evades three malware detection systems that show the expedience of evasion attacks. In addition, this attack triggers the importance of reliable security solutions to mitigate vulnerabilities in machine learning against evasion attacks. The attack surface for evasion attacks on machine learning is highlighted in Figure 1.2.3.
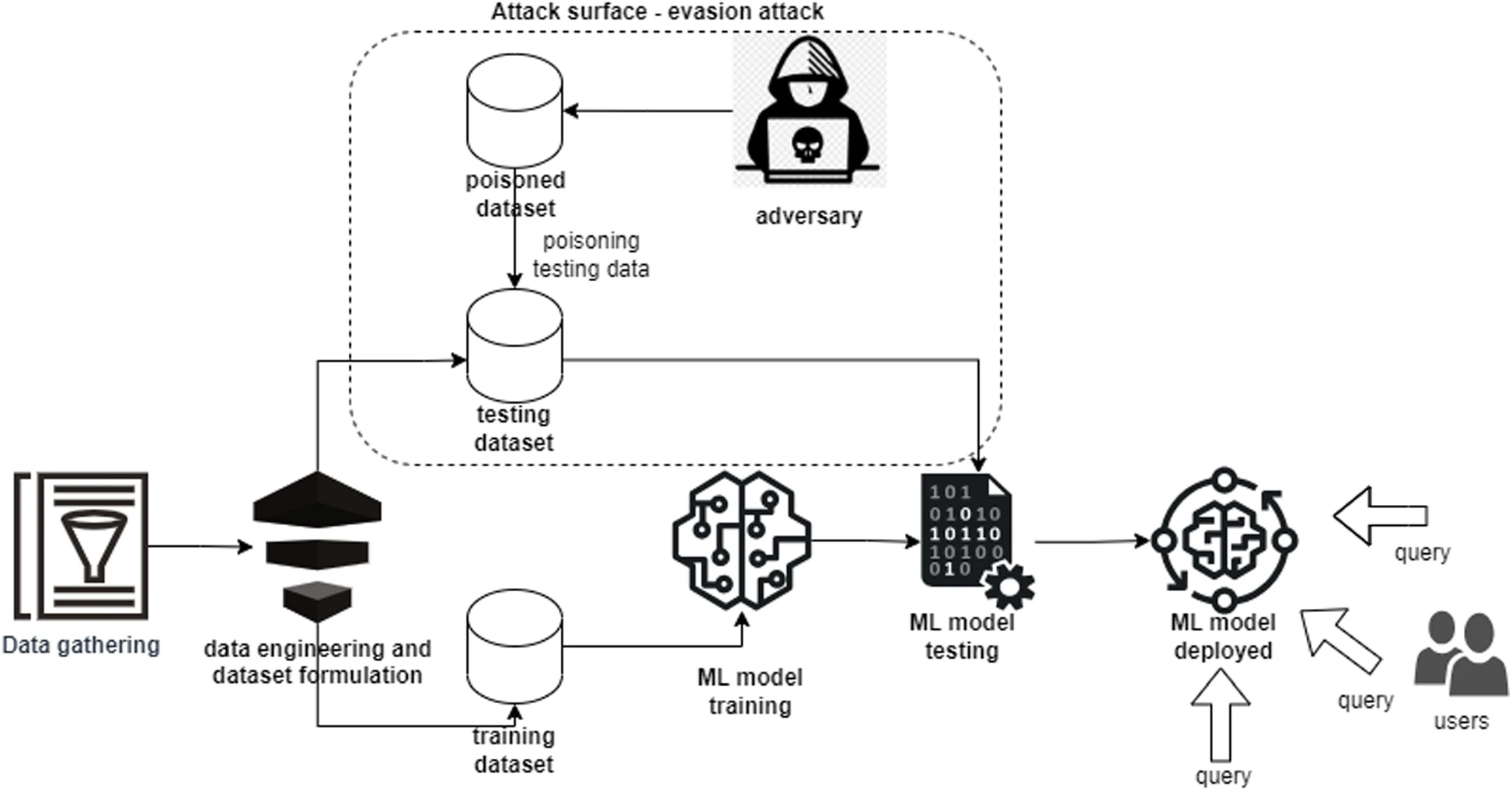
Figure 1.2.3 Description
A flowchart diagram illustrating an evasion attack on a machine learning model. The process starts with ‘Data gathering,’ followed by ‘Data engineering and dataset formulation,’ which prepares both a ‘Training dataset’ and a ‘Testing dataset.’ An ‘Adversary’ manipulates the testing dataset by injecting ‘Poisoned data,’ creating a ‘Poisoned dataset.’ This attack surface, labelled an ‘Evasion attack,’ influences the ‘ML model testing’ phase. The compromised model is then the ‘ML model deployed’ for user queries. Users interact with the deployed model by submitting queries, but the model may produce incorrect or manipulated outputs due to the evasion attack.
Model Inversion Attack
The objective of this attack is to disrupt the privacy of machine learning. A model inversion attack is the type of attack in which an adversary tries to steal the developed ML model by replicating its underlying behaviour and querying it with different datasets. An adversary extracts the baseline model representation through a model inversion attack and can regenerate the model’s training data. Usynin et al. (2023) designed a framework for a model inversion attack on a collaborative machine learning model, demonstrating its success. It also highlights the impact of model inversion attacks on transfer machine learning models. The attack surface for model inversion attacks on machine learning is highlighted in Figure 1.2.4.
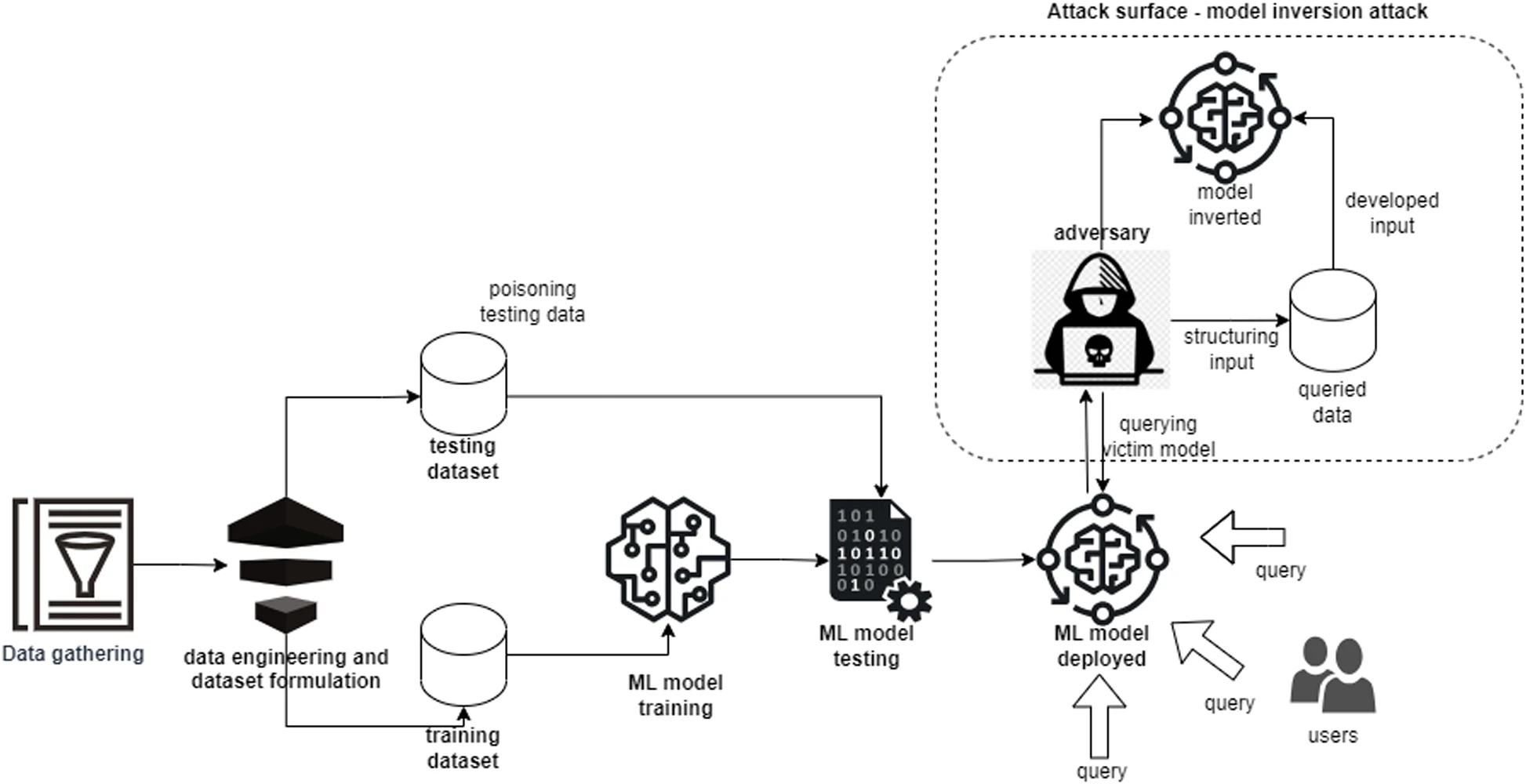
Figure 1.2.4 Description
A flowchart diagram illustrating a model inversion attack on a machine learning system. The process starts with ‘Data gathering’ and ‘Data engineering and dataset formulation,’ which produces both a ‘Training dataset’ and a ‘Testing dataset.’ The ‘ML model training’ process is followed by ‘ML model testing’ before the final’ ML model deployed’ stage. An ‘Adversary’ exploits the deployed model by submitting structured queries to extract sensitive information. This attack surface, labelled ‘Model inversion attack,’ involves querying the victim model to retrieve ‘Queried data,’ which is then used to generate ‘Developed input’ and reconstruct the original data. The adversary effectively inverts the model to reveal private information, posing a security risk.
Membership Inference Attack
A membership inference attack is another privacy attack that infers the victim model and extracts its training data, privacy settings, and model parameters. In this type of attack, the adversary has access to query the victim model under attack and can analyze the output gathered from the queried results. The adversary can regenerate the training dataset of the targeted adversarial machine learning model by analyzing the gathered queried results. The attack surface for membership inference attacks on machine learning is highlighted in Figure 1.2.5.
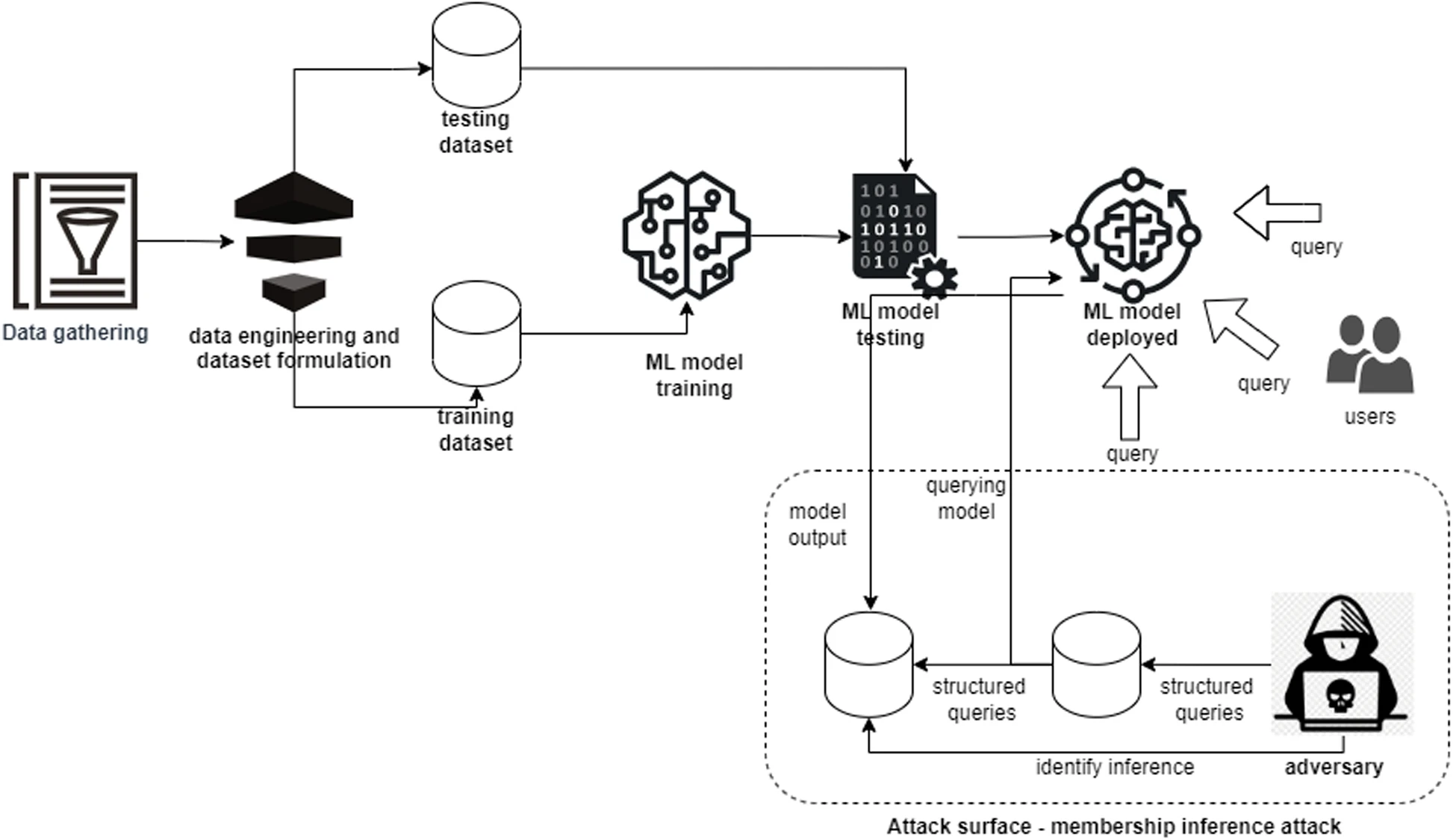
Figure 1.2.5 Description
A flowchart diagram illustrating a membership inference attack on a machine learning system. The process starts with ‘Data gathering’ and ‘Data engineering and dataset formulation,’ producing both a ‘Training dataset’ and a ‘Testing dataset.’ The ‘ML model training’ and ‘ML model testing’ phases follow, leading to the final ‘ML model deployed’ stage, where users submit queries.
An ‘Adversary’ exploits the deployed model by submitting ‘Structured queries’ to infer whether specific data points were part of the training dataset. This attack surface, labelled ‘Membership inference attack,’ involves querying the model, analyzing its ‘Model output,’ and using structured queries to ‘Identify inference,’ potentially revealing sensitive information about the training data.
“Machine learning security and privacy: a review of threats and countermeasures” by Anum Paracha, Junaid Arshad, Mohamed Ben Farah & Khalid Ismail is licensed under a Creative Commons Attribution 4.0 International license
