P05 : Laboratoire d’éducation et de cognition
Sevda Montakhaby Nodeh
Laboratoire d’éducation et de cognition
Vous êtes chercheur au sein du laboratoire EdCog de l’Université McMaster. Le laboratoire mène une étude visant à comprendre les croyances des enseignants sur les capacités des étudiants dans les disciplines STIM (sciences, technologie, ingénierie et mathématiques). Cette étude est motivée par un nombre croissant de publications suggérant que les croyances des enseignants sur l’intelligence et la réussite – classées en croyances sur la brillance (l’idée que la réussite requiert un talent inné), croyances sur l’universalité (la croyance que la réussite est accessible à tous plutôt qu’à quelques privilégiés), et croyances sur l’état d’esprit (l’idée que l’intelligence et les compétences sont soit fixes, soit peuvent évoluer avec le temps) – jouent un rôle crucial dans les pratiques éducatives et les résultats des élèves. La compréhension de ces croyances est particulièrement importante dans les domaines des STIM, où les perceptions du talent inné par rapport aux compétences acquises peuvent influencer de manière significative les approches pédagogiques et l’engagement des étudiants.
Conception expérimentale :
L’enquête a été distribuée via LimeSurvey à des instructeurs des facultés de Sciences, de Sciences de la Santé et d’Ingénierie. Les participants ont été interrogés à travers une série de questions à l’échelle de Likert (allant de tout à fait en désaccord à tout à fait d’accord) visant à évaluer leurs croyances dans chacun des trois domaines. Des questions supplémentaires sur les données démographiques et le contexte ont été incluses pour contrôler des variables telles que les années d’expérience en enseignement, le domaine de spécialisation et le niveau d’éducation.
- Croyance en la Brilliance : La croyance que seuls ceux qui ont un talent brut et inné peuvent réussir dans leur domaine.
- Croyance en l’Universalité : La croyance que le succès est réalisable pour tout le monde, à condition que les bons efforts et stratégies soient employés.
- Croyances sur l’État d’Esprit : Les points de vue des instructeurs sur la nature de l’intelligence et des compétences – qu’ils soient des traits fixes ou qu’ils puissent être développés au fil du temps.
Le fichier de données d’échantillon (“EdCogData.xlsx”) pour cet exercice est structuré comme suit :
- ID : Un identifiant unique pour chaque répondant.
- Brilliance1 à Brilliance5 : Réponses aux déclarations mesurant la croyance en la brilliance comme une exigence pour le succès.
- Un score plus élevé dans ces colonnes indique une croyance que la brilliance est une exigence pour le succès.
- MindsetGrowth1 à MindsetGrowth5 : Réponses aux questions visant à évaluer la croyance en un état d’esprit de croissance, suggérant que l’intelligence et les capacités peuvent se développer avec le temps.
- Un score plus élevé dans ces colonnes indique un fort état d’esprit de croissance.
- Nonuniversality1 à Nonuniversality5 : Réponses aux déclarations mesurant les croyances contraires à l’universalité, signifiant que tout le monde ne peut pas réussir (c’est-à-dire que le succès n’est pas universel).
- Un score plus élevé dans ces colonnes indique un état d’esprit non universel face au succès.
- Universality1 à Universality5 : Réponses aux déclarations mesurant la croyance en l’universalité, ou l’idée que le succès est réalisable par n’importe qui avec un effort suffisant.
- Un score plus élevé dans ces colonnes indique une croyance qu’avec assez d’effort le succès est réalisable (c’est-à-dire que le succès est universel)
- MindsetFixed1 à MindsetFixed5 : Réponses aux questions visant à évaluer la croyance en un état d’esprit fixe concernant l’intelligence et les capacités. Un état d’esprit fixe croit que l’intelligence, les talents et les capacités sont des traits fixes. Ils pensent que ces traits sont innés et ne peuvent pas être significativement développés ou améliorés par l’effort ou l’éducation.
- Un score plus élevé dans ces colonnes indique un fort état d’esprit fixe.
Commencer : Charger les progiciels , définir le répertoire de travail et charger l’ensemble de données
Commençons par exécuter le code suivant dans RStudio pour charger les bibliothèques requises. Assurez-vous de lire les commentaires intégrés tout au long du code pour comprendre ce que chaque ligne de code fait.
Note : Les boîtes ombragées contiennent le code R, avec le signe “#” indiquant un commentaire qui ne s’exécutera pas dans RStudio.
# Here we create a list called "my_packages" with all of our required libraries
my_packages <- c("tidyverse", "readxl", "xlsx", "dplyr", "ggplot2")
# Checking and extracting packages that are not already installed
not_installed <- my_packages[!(my_packages %in% installed.packages()[ , "Package"])]
# Install packages that are not already installed
if(length(not_installed)) install.packages(not_installed)
# Loading the required libraries
library(tidyverse) # for data manipulation
library(dplyr) # for data manipulation
library(readxl) # to read excel files
library(xlsx) # to create excel files
library(ggplot2) # for making plots
Assurez-vous d’avoir téléchargé l’ensemble de données requis (“EdCogData.xlsx”) pour cet exercice. Définissez le répertoire de travail de votre session R actuelle dans le dossier contenant l’ensemble de données téléchargé. Vous pouvez le faire manuellement dans le studio R en cliquant sur l’onglet “Session” en haut de l’écran, puis en cliquant sur “Set Working Directory”.
Si le fichier de données téléchargé et votre session R se trouvent dans le même dossier, vous pouvez choisir de définir votre répertoire de travail sur “l’emplacement du fichier source” (l’emplacement où votre session R actuelle est sauvegardée). S’ils se trouvent dans des dossiers différents, cliquez sur l’option “choisir un répertoire” et recherchez l’emplacement du jeu de données téléchargé.
Vous pouvez également effectuer cette opération en exécutant le code suivant :
setwd(file.choose())
Une fois que vous avez défini votre répertoire de travail manuellement ou par code, la console ci-dessous affiche le répertoire complet de votre dossier en sortie.
Lisez l’ensemble de données téléchargé en tant que “edcogData” et effectuez les exercices qui l’accompagnent au mieux de vos capacités.
# Read xlsx file
edcog = read_excel("EdCogData.xlsx")
Fichiers à télécharger :
Solutions
Exercice 1 : Préparation et exploration des données
Note : Les boîtes ombragées contiennent le code R, tandis que les boîtes blanches affichent la sortie du code, telle qu’elle apparaît dans RStudio. Le signe “#” indique un commentaire qui ne s’exécutera pas dans RStudio.
Chargez l’ensemble de données dans RStudio et inspectez sa structure.
- Combien de lignes et de colonnes y a-t-il dans l’ensemble de données ?
- Quels sont les noms des colonnes ?
head(edcogData) # View the first few rows of the datasetncol(edcogData) #Q1#[1] 26
colnames(edcogData) #Q2
#[1] "ID" "Brilliance1" "Brilliance2" "Brilliance3" "Brilliance4"
#[6] "Brilliance5" "MindsetGrowth1" "MindsetGrowth2" "MindsetGrowth3" "MindsetGrowth4"
#[11] "MindsetGrowth5" "MindsetFixed1" "MindsetFixed2" "MindsetFixed3" "MindsetFixed4"
#[16] "MindsetFixed5" "Nonuniversality1" "Nonuniversality2" "Nonuniversality3" "Nonuniversality4"
#[21] "Nonuniversality5" "Universality1" "Universality2" "Universality3" "Universality4"
#[26] "Universality5"
Exercice 2 : Prétraitement des données
Préparez les données pour l’analyse en vous assurant qu’elles sont dans le bon format.
1. Y a-t-il des valeurs manquantes dans l’ensemble de données ?
sum(is.na(edcogData))
[1] 0
Exercice 3 : Agrégation des scores
1. Créez des scores agrégés pour chaque dimension (Brilliance, Fixed, Growth, Nonuniversal, Universal).
edcogData$Brilliance <- rowMeans(edcogData[,c("Brilliance1", "Brilliance2", "Brilliance3", "Brilliance4", "Brilliance5")])
edcogData$Growth <- rowMeans(edcogData[,c("MindsetGrowth1", "MindsetGrowth2", "MindsetGrowth3", "MindsetGrowth4", "MindsetGrowth5")])
edcogData$Fixed <- rowMeans(edcogData[,c("MindsetFixed1", "MindsetFixed2", "MindsetFixed3", "MindsetFixed4", "MindsetFixed5")])
edcogData$Universal <- rowMeans(edcogData[,c("Universality1", "Universality2", "Universality3", "Universality4", "Universality5")])
edcogData$Nonuniversal <- rowMeans(edcogData[,c("Nonuniversality1", "Nonuniversality2", "Nonuniversality3", "Nonuniversality4", "Nonuniversality5")])
2. Créez un nouveau dataframe nommé “edcog.agg.wide” qui ne contient que la colonne ID et les colonnes de scores agrégés de “edcogData”.
edcog.agg.wide <- edcogData %>% select(ID, Brilliance, Fixed, Growth, Nonuniversal, Universal)
3. Convertissez “edcog.agg.wide” d’un format large à un format long nommé “edcog.agg.long”, avec les colonnes suivantes :
- ID
- Dimension (avec des valeurs de Brilliance, Fixed, Growth, Universal, et Nonuniversal)
- AggregateScore
edcog.agg.long <- edcog.agg.wide %>%
select(ID, Brilliance, Fixed, Growth, Nonuniversal, Universal) %>%
pivot_longer(
cols = -ID, # Select all columns except for ID
names_to = "Dimension",
values_to = "AggregateScore" )
Exercice 4 : Création de graphiques
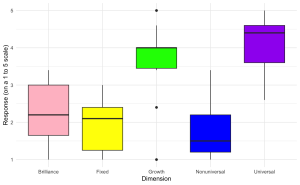
1. Créez un boxplot pour visualiser la distribution des scores agrégés à travers différentes dimensions (Brilliance, Fixed, Growth, Nonuniversal, Universal) à partir des données de l’enquête avec les spécifications suivantes :
- L’axe des x doit représenter différentes ‘Dimensions’ de croyances.
- L’axe des y doit représenter le ‘Score’ sur une échelle de 1 à 5.
- Chaque ‘Dimension’ doit avoir une couleur différente pour sa boîte.
- Définissez l’étiquette de l’axe des y à “Réponse (sur une échelle de 1 à 5)” et l’étiquette de l’axe des x à “Dimension”.
- Utilisez un thème minimal et supprimez la légende. Indice :
- Utilisez “edcog.agg.long”
ggplot(edcog.agg.long, aes(x = Dimension, y = AggregateScore, fill = Dimension)) +
geom_boxplot() +
scale_fill_manual(values = c("Brilliance" = "pink", "Fixed" = "yellow",
"Growth" = "green", "Nonuniversal" = "blue",
"Universal" = "purple")) +
labs(y = "Response (on a 1 to 5 scale)", x = "Dimension") +
theme_minimal() +
theme(legend.position = "none") # Hide the legend since color coding is evident
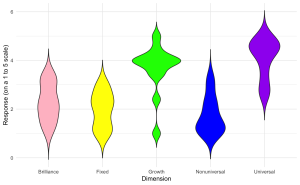
2. Générez un graphique de violon pour visualiser la distribution des scores agrégés pour différentes dimensions (Brilliance, Fixed, Growth, Nonuniversal, Universal) à partir des données de l’enquête avec les spécifications suivantes :
- L’axe des x doit représenter différentes ‘Dimensions’ de croyances.
- L’axe des y doit représenter le ‘Score’ sur une échelle de 1 à 5.
- Chaque ‘Dimension’ doit avoir une couleur distincte.
- Étiquetez les axes de manière appropriée.
- Appliquez un thème minimaliste et envisagez de supprimer la légende si elle n’est pas nécessaire.
ggplot(edcog.agg.long, aes(x = Dimension, y = AggregateScore, fill = Dimension)) +
geom_violin(trim = FALSE) +
scale_fill_manual(values = c("Brilliance" = "pink", "Fixed" = "yellow",
"Growth" = "green", "Nonuniversal" = "blue",
"Universal" = "purple")) +
labs(y = "Response (on a 1 to 5 scale)", x = "Dimension") +
theme_minimal() + theme(legend.position = "none")
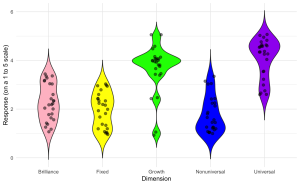
3. Améliorez le graphique de violon en superposant des points de données individuels pour montrer la distribution des données brutes en parallèle avec les estimations de densité agrégées.
ggplot(edcog.agg.long, aes(x = Dimension, y = AggregateScore, fill = Dimension)) +
geom_violin(trim = FALSE) +
geom_jitter(width = 0.1, size = 2, alpha = 0.5) + # Adjust 'width' for jittering, 'size' for point size, and 'alpha' for transparency
scale_fill_manual(values = c("Brilliance" = "pink", "Fixed" = "yellow",
"Growth" = "green", "Nonuniversal" = "blue",
"Universal" = "purple")) +
labs(y = "Response (on a 1 to 5 scale)", x = "Dimension") +
theme_minimal() +
theme(legend.position = "none")
Assurez-vous d’avoir l’ensemble de données requis (“EdCogData.xlsx”) pour cet exercice téléchargé. Définissez le répertoire de travail de votre session R actuelle sur le dossier contenant l’ensemble de données téléchargé. Vous pouvez le faire manuellement dans R studio en cliquant sur l’onglet “Session” en haut de l’écran, puis en cliquant sur “Définir le répertoire de travail”.
Si le fichier de l’ensemble de données téléchargé et votre session R sont dans le même fichier, vous pouvez choisir l’option de définir votre répertoire de travail sur “l’emplacement du fichier source” (l’emplacement où votre session R actuelle est enregistrée). S’ils sont dans des dossiers différents, cliquez sur l’option “choisir le répertoire” et recherchez l’emplacement de l’ensemble de données téléchargé.
Vous pouvez également le faire en exécutant le code suivant :
Une fois que vous avez défini votre répertoire de travail soit manuellement, soit par code, dans la console ci-dessous, vous verrez le répertoire complet de votre dossier en sortie.
Lisez l’ensemble de données téléchargé en tant que “edcogData” et complétez les exercices d’accompagnement au mieux de vos capacités.
