P04: Laboratoire de perception et de sensorimotricité
Sevda Montakhaby Nodeh
Laboratoire de perception et de sensorimotricité
Bienvenue au laboratoire de perception et de sensorimotricité de l'université McMaster. En tant que psychologue cognitif en herbe, vous êtes sur le point d'entreprendre un voyage exploratoire sur l'effet de profondeur, un phénomène psychologique captivant qui suggère que les événements visuels se produisant à proximité (espace proche) sont traités plus efficacement que ceux qui sont plus éloignés (espace lointain). Cet effet offre une fenêtre unique sur l'architecture cognitive qui sous-tend nos expériences sensorielles, impliquant probablement l'implication du flux visuel dorsal, qui traite les relations spatiales et les mouvements dans l'espace proche, et le flux ventral, connu pour son rôle dans la reconnaissance d'informations visuelles détaillées.
Votre objectif est de déterminer si l'effet de profondeur est dépendant de la tâche, s'alignant strictement sur la dichotomie flux dorsal/flux ventral, ou s'il représente un avantage de traitement universel pour les stimuli dans l'espace proche à travers diverses tâches cognitives.
Votre parcours de recherche commence dans votre laboratoire. Imaginez le laboratoire comme une passerelle vers un monde tridimensionnel, où le concept de profondeur n'est pas seulement un sujet d'étude, mais aussi une expérience sensorielle vécue par vos participants ! Assis à l'intérieur d'une tente sombre, chaque participant tient un volant, son principal outil d'interaction et de saisie de réponses. Devant eux, un écran prend vie avec un environnement virtuel en 3D méticuleusement conçu pour tester les limites de la perception de la profondeur.
Le paysage virtuel auquel les participants sont confrontés est un modèle de simplicité et de complexité ; comme l'illustre la figure ci-dessous, devant les participants, un plan au sol s'étend dans la profondeur de l'écran, entrecoupé par deux séries de murs verticaux à des profondeurs variables - proches et éloignés. Les murs se trouvent de part et d'autre de l'axe central et se reflètent parfaitement sur la ligne médiane. Les textures du sol et des espaces réservés - une matrice de points aléatoires et un motif en damier, respectivement - conservent une densité constante. Ces indices visuels, ainsi que les gradients texturaux et la différence de taille rétinienne entre les objets proches et éloignés, agissent comme des repères subtils pour la perception de la profondeur.

De leur point de vue à la première personne, les participants sont invités à :
- Soit discriminer l'orientation d'une cible triangulaire rouge, soit localiser un carré à carreaux dans un environnement immersif en 3D.
- Les cibles peuvent apparaître dans des espaces proches ou éloignés, ce qui exige une discrimination et une localisation sensorielles poussées.
Grâce à cette expérience, vous ne vous contentez pas d'observer l'effet de profondeur ; vous le disséquerez, en découvrant les processus cognitifs qui permettent aux humains de naviguer dans la danse complexe de la profondeur dans notre vie quotidienne !
Commençons par charger les bibliothèques requises et le jeu de données. Pour ce faire, téléchargez le fichier "NearFarRep_Outlier.csv" et exécutez le code suivant.
Remarque : les cases grisées contiennent le code R, le signe "#" indiquant un commentaire qui ne s'exécutera pas dans RStudio.
# Loading the required
libraries library(tidyverse) # for data manipulation
library(rstatix) # for statistical analyses
library(emmeans) # for pairwise comparisons
library(afex) # for running anova using aov_ez and aov_car
library(kableExtra) # formatting html ANOVA tables
library(ggpubr) # for making plots
library(grid) # for plots
library(gridExtra) # for arranging multiple ggplots for extraction
library(lsmeans) # for pairwise comparisons
Lisez l'ensemble de données téléchargé "NearFarRep_Outlier.csv" en tant que "NearFarData". N'oubliez pas de remplacer "path_to_your_downloaded_file" par le chemin réel de l'ensemble de données sur votre système.
NearFarData <- read.csv('path_to_your_downloaded_file/NearFarRep_Outlier.csv')
L'ensemble de données contient les temps de réponse des participants et comprend les colonnes suivantes :
- "Response" indique le type de tâche (discrimination ou localisation)
- "Con" indique la profondeur de la cible (proche ou lointaine)
- "TarRT" représente les temps de réponse de la cible.
Fichiers à télécharger :
Veuillez compléter les exercices ci-joints au mieux de vos capacités.
Solutions
Exercice 1 : préparer et explorer les données
Remarque : les cases grisées contiennent le code R, tandis que les cases blanches affichent la sortie du code, telle qu'elle apparaît dans RStudio.
Le signe "#" indique un commentaire qui ne sera pas exécuté dans RStudio.
1. Affichez les premières lignes pour comprendre votre ensemble de données. Affichez tous les noms de colonnes de l'ensemble de données.
head(NearFarData) #Displaying the first few rows## X ID Response Con TarRT
## 1 1 10 Loc Near 0.6200754
## 2 2 10 Loc Near 0.2219719
## 3 3 1 Loc Near 0.2270377
## 4 4 9 Loc Near 0.5270686
## 5 5 25 Loc Near 0.2272455
## 6 6 18 Loc Near 0.2292785
colnames(NearFarData)
## [1] "X" "ID" "Response" "Con" "TarRT"
2. Définissez "Response" et "Con" comme facteurs, puis vérifiez la structure de vos données pour vous assurer que vos facteurs et niveaux sont correctement définis.
NearFarData <- NearFarData %>% convert_as_factor(Response, Con)str(NearFarData)## 'data.frame': 11154 obs. of 5 variables:
## $ X : int 1 2 3 4 5 6 7 8 9 10 ...
## $ ID : int 10 10 1 9 25 18 4 9 8 18 ...
## $ Response: Factor w/ 2 levels "Disc","Loc": 2 2 2 2 2 2 2 2 2 2 ...
## $ Con : Factor w/ 2 levels "Far","Near": 2 2 2 2 2 2 2 2 2 2 ...
## $ TarRT : num 0.62 0.222 0.227 0.527 0.227 ...
3. Effectuer des contrôles de base des données pour vérifier les valeurs manquantes et la cohérence des données.
sum(is.na(NearFarData)) # Checking for missing values in the dataset## [1] 0
4. Convertissez les valeurs de votre colonne de mesures dépendantes "TarRT" en secondes.
NearFarData$TarRT <- NearFarData$TarRT * 1000
Exercice 2 : Visualiser les données
- En utilisant le paquetage "dplyr", écrivez un code R pour calculer le temps de réponse moyen et l'erreur standard de la moyenne (SERT) pour chaque combinaison de vos deux facteurs (Response et Con).
# Calculate means and standard errors for each combination of 'Response' and 'Con'
summary_df <- NearFarData %>%
group_by(Response, Con) %>%
summarise(
MeanRT = mean(TarRT),
SERT = sd(TarRT) / sqrt(n())
)
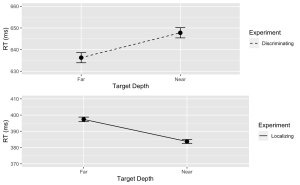
6. En utilisant le package "ggplot2", créez un graphique linéaire avec des barres d'erreur pour la tâche de discrimination.
- (a) L'axe des x doit représenter la profondeur de la cible (Con) et être étiqueté "Profondeur de la cible".
- (b) L'axe des y doit représenter le temps de réponse moyen (MeanRT) et être étiqueté "RT (ms)"
- (c) Les barres d'erreur doivent représenter l'erreur standard de la moyenne (SERT).
- (d) Assurez-vous que le type de ligne est solide.
- (e) Fixez la valeur minimale de l'axe des y à 630 et la valeur maximale à 660.
# Now, using ggplot to create the plotDisc.plot <- ggplot(data = filter(summary_df, Response=="Disc"), aes(x = Con, y = MeanRT, group = Response)) + geom_line(aes(linetype = "Discriminating")) + # Add a linetype aesthetic geom_errorbar(aes(ymin = MeanRT - SERT, ymax = MeanRT + SERT), width = 0.1) + geom_point(size = 3) + theme_gray() + labs( x = "Target Depth", y = "RT (ms)", color = "Experiment", linetype = "Experiment") + scale_linetype_manual(values = "dashed") + # Set the linetype for "Disc" to dashed ylim(630, 660) # Set the y-axis limits
7. De même, créez un graphique linéaire avec des barres d'erreur pour la tâche Localisation. Utilisez une ligne pointillée pour ce tracé, avec les exceptions suivantes :
- (a) Assurez-vous que le type de ligne est en pointillés.
- (b) Fixez la valeur minimale de l'axe des y à 370 et la valeur maximale à 410.
Loc.plot <- ggplot(data = filter(summary_df, Response=="Loc"), aes(x = Con, y = MeanRT, group = Response)) +
geom_line(aes(linetype = "Localizing")) + # Add a linetype aesthetic
geom_errorbar(aes(ymin = MeanRT - SERT, ymax = MeanRT + SERT), width = 0.1) +
geom_point(size = 3) +
theme_gray() +
labs(
x = "Target Depth",
y = "RT (ms)",
color = "Experiment",
linetype = "Experiment") +
scale_linetype_manual(values = "solid") + # Set the line type for "Disc" to dashed
ylim(370, 410) # Set the y-axis limits
8. Enfin, utilisez la fonction grid.arrange() du package "gridExtra" pour superposer les tracés des tâches de discrimination et de localisation.
grid.arrange(Disc.plot, Loc.plot, ncol = 1) # Stack the plots on top of each other
Exercice 3 : Analyse de la variance (ANOVA)
9. À l'aide de la fonction "anova_test", effectuez une ANOVA à deux voies entre sujets pour étudier les effets de Con (condition) et de Response (type de tâche) sur les temps de réponse cibles (TarRT). Après avoir exécuté l'ANOVA, utilisez la fonction "get_anova_table" pour présenter les résultats.
anova <- anova_test(
data = NearFarData, dv = TarRT, wid = ID,
between = c(Con, Response), detailed = TRUE, effect.size = "pes")
## Warning: The 'wid' column contains duplicate ids across between-subjects
## variables. Automatic unique id will be created
get_anova_table(anova)
## ANOVA Table (type III tests)
##
## Effect SSn SSd DFn DFd F p p<.05
## 1 (Intercept) 2.972143e+09 111582983 1 11150 296993.268 0.00e+00 *
## 2 Con 3.185839e+03 111582983 1 11150 0.318 5.73e-01
## 3 Response 1.762985e+08 111582983 1 11150 17616.741 0.00e+00 *
## 4 Con:Response 4.390483e+05 111582983 1 11150 43.872 3.67e-11 *
## pes
## 1 9.64e-01
## 2 2.86e-05
## 3 6.12e-01
## 4 4.00e-03
Exercice 4: Analyse Post-Hoc
- Utilisez la fonction "lm" pour ajuster un modèle linéaire à vos données. Veillez à spécifier votre variable dépendante, vos variables indépendantes et vos termes d'interaction.
## Fitting a linear model to data
lm_model <- lm(TarRT ~ Con * Response, data = NearFarData)
- Utilisez la fonction "emmeans" pour obtenir les moyennes marginales estimées pour vos facteurs et leur interaction. Utilisez ensuite la fonction "pairs" pour effectuer des comparaisons par paire.
- (a) Réglez le paramètre adjust de la fonction test sur "Tukey" pour le test de différence significative honnête de Tukey, afin d'ajuster les comparaisons multiples et de contrôler le taux d'erreur de la famille.
# Get the estimated marginal means
emm <- emmeans(lm_model, specs = pairwise ~ Con * Response)
# View the results
print(post_hoc_results)
## contrast estimate SE df t.ratio p.value
## Far Disc - Near Disc -11.5 2.70 11150 -4.250 0.0001
## Far Disc - Far Loc 238.9 2.67 11150 89.348 <.0001
## Far Disc - Near Loc 252.6 2.67 11150 94.581 <.0001
## Near Disc - Far Loc 250.4 2.69 11150 93.131 <.0001
## Near Disc - Near Loc 264.0 2.68 11150 98.341 <.0001
## Far Loc - Near Loc 13.6 2.66 11150 5.124 <.0001
##
## P value adjustment: tukey method for comparing a family of 4 estimates
