P02: Laboratoire de cognition et de mémoire
Sevda Montakhaby Nodeh
Laboratoire de cognition et de mémoire
Bienvenue ! Dans le cadre de cette tâche, nous allons entrer dans un laboratoire de cognition et de mémoire de l'Université McMaster. Plus précisément, nous examinerons les données d'une étude fascinante de psychologie cognitive qui explore le rôle de la répétition dans la mémoire de reconnaissance.
La plupart d'entre nous connaissent l'expression "c'est en forgeant qu'on devient forgeron". Cette expression motivante correspond à l'intuition et est confirmée par de nombreuses observations dans le monde réel. De nombreuses recherches empiriques soutiennent également ce point de vue : les occasions répétées d'encoder un stimulus améliorent la récupération ultérieure de la mémoire et l'identification perceptuelle. Ces observations suggèrent que la répétition d'un stimulus renforce les représentations sous-jacentes dans la mémoire.
La présente étude se concentre sur une idée contradictoire, à savoir que la répétition d'un stimulus peut affaiblir l'encodage de la mémoire. L'expérience comprenait trois étapes : une phase d'étude, une phase de distraction et un test de mémoire de reconnaissance surprise.
La présente étude se concentre sur une idée contradictoire, à savoir que la répétition du stimulus peut affaiblir l'encodage de la mémoire. L'expérience comprenait trois étapes : une phase d'étude, une phase de distraction et un test de mémoire de reconnaissance par surprise.
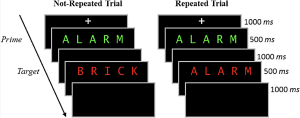
Dans la phase d'étude, les participants prononcent à haute voix un mot cible rouge précédé d'un mot premier vert brièvement présenté. Sur la moitié des essais, le mot principal et le mot cible étaient identiques (essais répétés), et sur l'autre moitié des essais, le mot principal et le mot cible étaient différents (essais non répétés). La figure ci-dessous donne un aperçu des deux types d'essais. Après la phase d'étude, les participants se sont livrés à une tâche de distraction de 10 minutes consistant en des problèmes mathématiques qu'ils devaient résoudre à la main.
La phase finale consistait en un test de mémoire de reconnaissance surprise où, à chaque essai, on leur montrait un mot rouge et on leur demandait de répondre "ancien" si le mot du test était un mot qu'ils avaient déjà vu à l'étude, et "nouveau" s'ils n'avaient jamais rencontré ce mot auparavant. La moitié des essais du test étaient des mots de la phase d'étude et l'autre moitié des mots nouveaux.
Commençons par exécuter le code suivant pour charger les bibliothèques requises. Veillez à lire les commentaires intégrés dans le code pour comprendre ce que fait chaque ligne de code.
Remarque : les cases grisées contiennent le code R, le signe "#" indiquant un commentaire qui ne s'exécutera pas dans RStudio
# Load necessary libraries
library(rstatix) #for performing basic statistical tests
library(dplyr) #for sorting data
library(readxl) #for reading excel files
library(tidyr) #for data sorting and structure
library(ggplot2) #for visualizing your data
library(plotrix) #for computing basic summary stats
Assurez-vous d'avoir téléchargé l'ensemble de données requis ("RepDecrementdataset.xlsx") pour cet exercice. Définissez le répertoire de travail de votre session R actuelle dans le dossier contenant l'ensemble de données téléchargé. Vous pouvez le faire manuellement dans le studio R en cliquant sur l'onglet "Session" en haut de l'écran, puis en cliquant sur "Set Working Directory".
Si le fichier de données téléchargé et votre session R se trouvent dans le même dossier, vous pouvez choisir de définir votre répertoire de travail sur "l'emplacement du fichier source" (l'emplacement où votre session R actuelle est sauvegardée). S'ils se trouvent dans des dossiers différents, cliquez sur l'option "choisir un répertoire" et recherchez l'emplacement du jeu de données téléchargé.
Vous pouvez également effectuer cette opération en exécutant le code suivant
setwd(file.choose())
Une fois que vous avez défini votre répertoire de travail, manuellement ou par code, la console ci-dessous affiche le répertoire complet de votre dossier.
Lisez l'ensemble de données téléchargé en tant que "MemoryData" et effectuez les exercices qui l'accompagnent au mieux de vos capacités.
MemoryData <- read_excel('RepDecrementdataset.xlsx')
Fichiers à télécharger :
Solutions
Exercice 1 - Préparation et exploration des données
Remarque : les cases grisées contiennent le code R, tandis que les cases blanches affichent la sortie du code, telle qu'elle apparaît dans RStudio.
Le signe "#" indique un commentaire qui ne sera pas exécuté dans RStudio.
1. Affichez les premières lignes de votre jeu de données pour vous familiariser avec sa structure et son contenu.
head(MemoryData) #Displaying the first few rows
## # A tibble: 6 × 7
## ID Hits_NRep Hits_Rep FalseAlarms Misses_Nrep Misses_Rep CorrectRej
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 46 34 13 14 26 107
## 2 2 43 44 27 17 16 93
## 3 3 43 35 23 17 24 97
## 4 4 37 36 56 23 24 64
## 5 5 39 35 49 21 25 71
## 6 6 38 43 28 22 17 92
str(MemoryData) #Checking structure of dataset
## tibble [24 × 7] (S3: tbl_df/tbl/data.frame)
## $ ID : num [1:24] 1 2 3 4 5 6 7 8 9 10 ...
## $ Hits_NRep : num [1:24] 46 43 43 37 39 38 20 24 36 38 ...
## $ Hits_Rep : num [1:24] 34 44 35 36 35 43 11 29 43 27 ...
## $ FalseAlarms: num [1:24] 13 27 23 56 49 28 4 11 46 9 ...
## $ Misses_Nrep: num [1:24] 14 17 17 23 21 22 40 36 23 22 ...
## $ Misses_Rep : num [1:24] 26 16 24 24 25 17 49 31 17 33 ...
## $ CorrectRej : num [1:24] 107 93 97 64 71 92 116 109 74 111 ...
colnames(MemoryData)
## [1] "ID" "Hits_NRep" "Hits_Rep" "FalseAlarms" "Misses_Nrep"
## [6] "Misses_Rep" "CorrectRej"
2. Calculer le nombre total d'essais pour chaque condition :
- (a) Pour chaque participant, additionnez le nombre de réponses positives pour les essais non répétés et les essais non répétés manqués. Enregistrez ce total dans une nouvelle colonne intitulée "TotalNRep". La valeur doit être de 60 pour tous les participants, ce qui correspond au nombre total de types d'essais non répétés.
- (b) Répétez le processus pour les essais répétés, en enregistrant la somme dans "TotalRep" (60 essais).
- (c) De même, additionnez le nombre de fausses alarmes et de rejets corrects pour représenter le nombre total de nouveaux essais (120 essais) et enregistrez cette somme dans "TotalNew".
Notez que si la valeur de "TotalNRep" et "TotalRep" est inférieure à 60 pour un participant, cela indique que certains essais de mots ont été exclus pendant la phase d'étude en raison de problèmes (par exemple, le participant a lu à haute voix le mot principal au lieu du mot cible, ce qui a entraîné la détérioration de l'essai).
MemoryData <- MemoryData %>%
mutate(TotalNRep = Hits_NRep + Misses_Nrep)
MemoryData <- MemoryData %>%
mutate(TotalRep = Hits_Rep + Misses_Rep)
MemoryData <- MemoryData %>%
mutate(TotalNew = FalseAlarms + CorrectRej)
3. Transformez les nombres des colonnes "hits", "misses", "false alarms" et "correct rejections" en proportions. Pour ce faire, divisez chaque nombre par le nombre total d'essais pour la condition concernée (par exemple, divisez les réponses positives pour les essais non répétés par "TotalNRep").
MemoryData$Hits_NRep <- (MemoryData$Hits_NRep/MemoryData$TotalNRep)
MemoryData$Misses_Nrep <- (MemoryData$Misses_Nrep/MemoryData$TotalNRep)
MemoryData$Hits_Rep <- (MemoryData$Hits_Rep/MemoryData$TotalRep)
MemoryData$Misses_Rep <- (MemoryData$Misses_Rep/MemoryData$TotalRep)
MemoryData$CorrectRej <- (MemoryData$CorrectRej/MemoryData$TotalNew)
MemoryData$FalseAlarms <- (MemoryData$FalseAlarms/MemoryData$TotalNew)
4. Une fois les proportions calculées, supprimez les colonnes "TotalNew", "TotalRep" et "TotalNRep" de l'ensemble de données, car elles ne sont plus nécessaires pour la suite de l'analyse.
MemoryData <- MemoryData[, !names(MemoryData) %in% c("TotalNew", "TotalRep","TotalNRep")]
5. Utilisez la fonction pivot_longer() du package tidyr pour convertir vos données du format large au format long. Effectuez un pivot des colonnes "Hits_NRep", "Hits_Rep" et "FalseAlarms", en définissant les nouveaux noms de colonnes "Condition" et "Proportion" pour les données remodelées.
long_df <- MemoryData %>%
pivot_longer(
cols = c(Hits_NRep, Hits_Rep, FalseAlarms),
names_to = "Condition",
values_to = "Proportion"
)
Exercice 2 : Calcul des statistiques sommaires et correction de la variabilité intra-sujet
6. À l'aide de votre ensemble de données au format long, regroupez vos données par ID et calculez la moyenne par sujet et la moyenne générale de la colonne Proportions.
- (a) Ajustez le score de chaque individu en soustrayant sa moyenne et en ajoutant la moyenne générale.
- (b) Calculez la moyenne et le SEM des scores ajustés pour chaque condition.
- (c) Utilisez les scores ajustés pour calculer le SEM intra-sujet. d.Regroupez les données par condition et calculez la moyenne et le SEM.
data_adjusted <- long_df %>%
group_by(ID) %>%
mutate(SubjectMean = mean(Proportion, na.rm = TRUE)) %>%
ungroup() %>%
mutate(GrandMean = mean(Proportion, na.rm = TRUE)) %>%
mutate(AdjustedScore = Proportion - SubjectMean + GrandMean)
# Calculate the mean and SEM of the adjusted scores
summary_df <- data_adjusted %>%
group_by(Condition) %>%
summarize(
AdjustedMean = mean(AdjustedScore, na.rm = TRUE),
AdjustedSEM = sd(AdjustedScore, na.rm = TRUE) / sqrt(n())
)
Exercice 3 : Visualisation des données
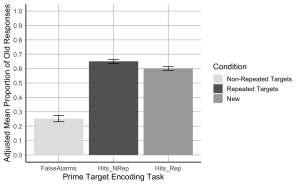
7. Créez un diagramme à barres où l'axe x représente les conditions de la tâche d'encodage de l'amorce et de la cible, l'axe y montre la proportion moyenne ajustée des anciennes réponses, et les barres d'erreur représentent le SEM ajusté. Commencez par définir des couleurs personnalisées pour chaque condition. La couleur de la barre présentant les fausses alarmes ou "New" doit être "gray89" ; la couleur de la barre "Hits_Nrep" ou "Non-Repeated Targets" doit être "gray39" ; la couleur de la barre "Hits_Rep" ou "Repeated Targets" doit être "darkgrey".
- (a) L'axe des x doit être intitulé "tâche d'encodage de la cible principale".
- (b) L'axe des ordonnées doit être intitulé "Proportion moyenne corrigée des anciennes réponses"
- (c) Ajoutez des barres d'erreur à chaque barre pour représenter le SEM corrigé.
- (d) Faites en sorte que les lignes des axes x et y soient noires et pleines.
- (e) Veillez à ce que le graphique soit minimaliste et ne comporte que les principales lignes de la grille.
- (f) Ajouter une légende pour indiquer les catégories de conditions. La légende doit être la suivante : cibles non répétées au lieu de "Hits_Nrep", cibles répétées au lieu de "Hits_Rep", et nouvelles au lieu de "Fausses alarmes".
- (g) Fixez les valeurs minimale et maximale de l'axe des y à 0 et 1, respectivement.
- (h) Les valeurs de l'axe des y doivent augmenter de 0,1.
# Create the bar plot with adjusted SEM error bars
ggplot(summary_df, aes(x = Condition, y = AdjustedMean, fill = Condition)) +
geom_bar(stat = "identity", position = position_dodge()) +
geom_errorbar(aes(ymin = AdjustedMean - AdjustedSEM, ymax = AdjustedMean + AdjustedSEM), width = 0.2, position = position_dodge(0.9)) +
scale_fill_manual(values = c("Hits_NRep" = "gray39", "Hits_Rep" = "darkgrey", "FalseAlarms" = "gray89"),
labels = c("Non-Repeated Targets", "Repeated Targets", "New")) +
labs(
x = "Prime Target Encoding Task",
y = "Adjusted Mean Proportion of Old Responses",
fill = "Condition"
) +
scale_y_continuous(breaks = seq(0, 1, by = 0.1), limits = c(0, 1)) +
theme_minimal(base_size = 14) +
theme(
axis.line = element_line(color = "black"),
axis.title = element_text(color = "black"),
panel.grid.major = element_line(color = "grey", size = 0.5),
panel.grid.minor = element_blank(),
legend.title = element_text(color = "black")
)
Exercice 4 - L’analyse principale
8. À l'aide du fichier de données au format large "MemoryData", effectuez un test t à deux échantillons appariés en comparant le taux de réussite cumulé dans les deux conditions de répétition (répété/non répété) au taux de fausses alarmes pour évaluer la capacité des participants à distinguer les anciens éléments des nouveaux.
- (a) Calculez le taux de réussite moyen en faisant la moyenne des taux de réussite des conditions "Hits_NRep" (non répété) et "Hits_Rep" (répété) pour chaque participant.
- (b) Effectuez un test t pour échantillons appariés afin de comparer le taux de réussite (combiné dans les deux conditions de répétition) au taux de fausses alarmes afin d'évaluer la capacité des participants à distinguer les anciens éléments des nouveaux.
collapsed_hitdata <- MemoryData %>%
mutate(HitRate = (Hits_NRep + Hits_Rep) / 2)
# Conduct paired sample t-tests
t_test_results <- t.test(collapsed_hitdata$HitRate, collapsed_hitdata$FalseAlarms, paired = TRUE)
print(t_test_results)
##
## Paired t-test
##
## data: collapsed_hitdata$HitRate and collapsed_hitdata$FalseAlarms
## t = 11.621, df = 23, p-value = 4.179e-11
## alternative hypothesis: true mean difference is not equal to 0
## 95 percent confidence interval:
## 0.3071651 0.4401983
## sample estimates:
## mean difference
## 0.3736817
#Hit rates were higher than false alarm rates, t(23) = 11.62, p < .001.
9. En utilisant le fichier de données au format large "MemoryData", effectuez un test t à deux échantillons appariés comparant les taux de réussite pour les cibles non répétées et répétées.
# Conduct paired sample t-tests for non-repeated vs repeated hit rates
t_test_results_hits <- t.test(collapsed_hitdata$Hits_NRep, collapsed_hitdata$Hits_Rep, paired = TRUE)
# Print the results for the hit rate comparison
print(t_test_results_hits)
##
## Paired t-test
##
## data: collapsed_hitdata$Hits_NRep and collapsed_hitdata$Hits_Rep
## t = 2.5431, df = 23, p-value = 0.01817
## alternative hypothesis: true mean difference is not equal to 0
## 95 percent confidence interval:
## 0.009071364 0.088174399
## sample estimates:
## mean difference
## 0.04862288
#Hit rates were higher for not-repeated targets than for repeated targets, t(23) = 2.54, p = .018.
