2 Research Designs
Original chapter by Christie Napa Scollon adapted by the Queen’s University Psychology Department
This Open Access chapter was originally written for the NOBA project. Information on the NOBA project can be found below.
Psychologists test research questions using a variety of methods. Most research relies on either correlations or experiments. With correlations, researchers measure variables as they naturally occur in people and compute the degree to which two variables go together. With experiments, researchers actively make changes in one variable and watch for changes in another variable. Experiments allow researchers to make causal inferences. Other types of methods include longitudinal and quasi-experimental designs. Many factors, including practical constraints, determine the type of methods researchers use. Often researchers survey people even though it would be better, but more expensive and time consuming, to track them longitudinally.
Learning Objectives
- Articulate the difference between correlational and experimental designs.
- Understand how to interpret correlations.
- Understand how experiments help us to infer causality.
- Understand how surveys relate to correlational and experimental research.
- Explain what a longitudinal study is.
- List a strength and weakness of different research designs.
Research Designs
In the early 1970’s, a man named Uri Geller tricked the world: he convinced hundreds of thousands of people that he could bend spoons and slow watches using only the power of his mind. In fact, if you were in the audience, you would have likely believed he had psychic powers. Everything looked authentic—this man had to have paranormal abilities! So, why have you probably never heard of him before? Because when Uri was asked to perform his miracles in line with scientific experimentation, he was no longer able to do them. That is, even though it seemed like he was doing the impossible, when he was tested by science, he proved to be nothing more than a clever magician.
When we look at dinosaur bones to make educated guesses about extinct life, or systematically chart the heavens to learn about the relationships between stars and planets, or study magicians to figure out how they perform their tricks, we are forming observations—the foundation of science. Although we are all familiar with the saying “seeing is believing,” conducting science is more than just what your eyes perceive. Science is the result of systematic and intentional study of the natural world. And psychology is no different. In the movie Jerry Maguire, Cuba Gooding, Jr. became famous for using the phrase, “Show me the money!” In psychology, as in all sciences, we might say, “Show me the data!”
One of the important steps in scientific inquiry is to test our research questions, otherwise known as hypotheses. However, there are many ways to test hypotheses in psychological research. Which method you choose will depend on the type of questions you are asking, as well as what resources are available to you. All methods have limitations, which is why the best research uses a variety of methods.
Most psychological research can be divided into two types: experimental and correlational research.
Experimental Research
If somebody gave you $20 that absolutely had to be spent today, how would you choose to spend it? Would you spend it on an item you’ve been eyeing for weeks, or would you donate the money to charity? Which option do you think would bring you the most happiness? If you’re like most people, you’d choose to spend the money on yourself (duh, right?). Our intuition is that we’d be happier if we spent the money on ourselves.

Knowing that our intuition can sometimes be wrong, Professor Elizabeth Dunn (2008) at the University of British Columbia set out to conduct an experiment on spending and happiness. She gave each of the participants in her experiment $20 and then told them they had to spend the money by the end of the day. Some of the participants were told they must spend the money on themselves, and some were told they must spend the money on others (either charity or a gift for someone). At the end of the day she measured participants’ levels of happiness using a self-report questionnaire. (But wait, how do you measure something like happiness when you can’t really see it? Psychologists measure many abstract concepts, such as happiness and intelligence, by beginning with operational definitions of the concepts. See the Noba modules on Intelligence [http://noba.to/ncb2h79v] and Happiness [http://noba.to/qnw7g32t], respectively, for more information on specific measurement strategies.)
In an experiment, researchers manipulate, or cause changes, in the independent variable, and observe or measure any impact of those changes in the dependent variable. The independent variable is the one under the experimenter’s control, or the variable that is intentionally altered between groups. In the case of Dunn’s experiment, the independent variable was whether participants spent the money on themselves or on others. The dependent variable is the variable that is not manipulated at all, or the one where the effect happens. One way to help remember this is that the dependent variable “depends” on what happens to the independent variable. In our example, the participants’ happiness (the dependent variable in this experiment) depends on how the participants spend their money (the independent variable). Thus, any observed changes or group differences in happiness can be attributed to whom the money was spent on. What Dunn and her colleagues found was that, after all the spending had been done, the people who had spent the money on others were happier than those who had spent the money on themselves. In other words, spending on others causes us to be happier than spending on ourselves. Do you find this surprising?
But wait! Doesn’t happiness depend on a lot of different factors—for instance, a person’s upbringing or life circumstances? What if some people had happy childhoods and that’s why they’re happier? Or what if some people dropped their toast that morning and it fell jam-side down and ruined their whole day? It is correct to recognize that these factors and many more can easily affect a person’s level of happiness. So how can we accurately conclude that spending money on others causes happiness, as in the case of Dunn’s experiment?
The most important thing about experiments is random assignment. Participants don’t get to pick which condition they are in (e.g., participants didn’t choose whether they were supposed to spend the money on themselves versus others). The experimenter assigns them to a particular condition based on the flip of a coin or the roll of a die or any other random method. Why do researchers do this? With Dunn’s study, there is the obvious reason: you can imagine which condition most people would choose to be in, if given the choice. But another equally important reason is that random assignment makes it so the groups, on average, are similar on all characteristics except what the experimenter manipulates.
By randomly assigning people to conditions (self-spending versus other-spending), some people with happy childhoods should end up in each condition. Likewise, some people who had dropped their toast that morning (or experienced some other disappointment) should end up in each condition. As a result, the distribution of all these factors will generally be consistent across the two groups, and this means that on average the two groups will be relatively equivalent on all these factors. Random assignment is critical to experimentation because if the only difference between the two groups is the independent variable, we can infer that the independent variable is the cause of any observable difference (e.g., in the amount of happiness they feel at the end of the day).
Here’s another example of the importance of random assignment: Let’s say your class is going to form two basketball teams, and you get to be the captain of one team. The class is to be divided evenly between the two teams. If you get to pick the players for your team first, whom will you pick? You’ll probably pick the tallest members of the class or the most athletic. You probably won’t pick the short, uncoordinated people, unless there are no other options. As a result, your team will be taller and more athletic than the other team. But what if we want the teams to be fair? How can we do this when we have people of varying height and ability? All we have to do is randomly assign players to the two teams. Most likely, some tall and some short people will end up on your team, and some tall and some short people will end up on the other team. The average height of the teams will be approximately the same. That is the power of random assignment!
Other considerations
In addition to using random assignment, you should avoid introducing confounds into your experiments. Confounds are things that could undermine your ability to draw causal inferences. For example, if you wanted to test if a new happy pill will make people happier, you could randomly assign participants to take the happy pill or not (the independent variable) and compare these two groups on their self-reported happiness (the dependent variable). However, if some participants know they are getting the happy pill, they might develop expectations that influence their self-reported happiness. This is sometimes known as a placebo effect. Sometimes a person just knowing that he or she is receiving special treatment or something new is enough to actually cause changes in behavior or perception: In other words, even if the participants in the happy pill condition were to report being happier, we wouldn’t know if the pill was actually making them happier or if it was the placebo effect—an example of a confound. A related idea is participant demand. This occurs when participants try to behave in a way they think the experimenter wants them to behave. Placebo effects and participant demand often occur unintentionally. Even experimenter expectations can influence the outcome of a study. For example, if the experimenter knows who took the happy pill and who did not, and the dependent variable is the experimenter’s observations of people’s happiness, then the experimenter might perceive improvements in the happy pill group that are not really there.
One way to prevent these confounds from affecting the results of a study is to use a double-blind procedure. In a double-blind procedure, neither the participant nor the experimenter knows which condition the participant is in. For example, when participants are given the happy pill or the fake pill, they don’t know which one they are receiving. This way the participants shouldn’t experience the placebo effect, and will be unable to behave as the researcher expects (participant demand). Likewise, the researcher doesn’t know which pill each participant is taking (at least in the beginning—later, the researcher will get the results for data-analysis purposes), which means the researcher’s expectations can’t influence his or her observations. Therefore, because both parties are “blind” to the condition, neither will be able to behave in a way that introduces a confound. At the end of the day, the only difference between groups will be which pills the participants received, allowing the researcher to determine if the happy pill actually caused people to be happier.
Correlational Designs
When scientists passively observe and measure phenomena it is called correlational research. Here, we do not intervene and change behavior, as we do in experiments. In correlational research, we identify patterns of relationships, but we usually cannot infer what causes what. Importantly, with correlational research, you can examine only two variables at a time, no more and no less.
So, what if you wanted to test whether spending on others is related to happiness, but you don’t have $20 to give to each participant? You could use a correlational design—which is exactly what Professor Dunn did, too. She asked people how much of their income they spent on others or donated to charity, and later she asked them how happy they were. Do you think these two variables were related? Yes, they were! The more money people reported spending on others, the happier they were.
More details about the correlation
To find out how well two variables correspond, we can plot the relation between the two scores on what is known as a scatterplot (Figure 1). In the scatterplot, each dot represents a data point. (In this case it’s individuals, but it could be some other unit.) Importantly, each dot provides us with two pieces of information—in this case, information about how good the person rated the past month (x-axis) and how happy the person felt in the past month (y-axis). Which variable is plotted on which axis does not matter.
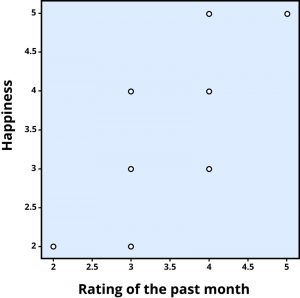
The association between two variables can be summarized statistically using the correlation coefficient (abbreviated as r). A correlation coefficient provides information about the direction and strength of the association between two variables. For the example above, the direction of the association is positive. This means that people who perceived the past month as being good reported feeling more happy, whereas people who perceived the month as being bad reported feeling less happy.
With a positive correlation, the two variables go up or down together. In a scatterplot, the dots form a pattern that extends from the bottom left to the upper right (just as they do in Figure 1). The r value for a positive correlation is indicated by a positive number (although, the positive sign is usually omitted). Here, the r value is .81.
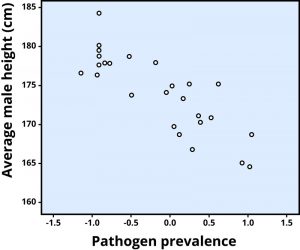
A negative correlation is one in which the two variables move in opposite directions. That is, as one variable goes up, the other goes down. Figure 2 shows the association between the average height of males in a country (y-axis) and the pathogen prevalence (or commonness of disease; x-axis) of that country. In this scatterplot, each dot represents a country. Notice how the dots extend from the top left to the bottom right. What does this mean in real-world terms? It means that people are shorter in parts of the world where there is more disease. The r value for a negative correlation is indicated by a negative number—that is, it has a minus (–) sign in front of it. Here, it is –.83.
The strength of a correlation has to do with how well the two variables align. Recall that in Professor Dunn’s correlational study, spending on others positively correlated with happiness: The more money people reported spending on others, the happier they reported to be. At this point you may be thinking to yourself, I know a very generous person who gave away lots of money to other people but is miserable! Or maybe you know of a very stingy person who is happy as can be. Yes, there might be exceptions. If an association has many exceptions, it is considered a weak correlation. If an association has few or no exceptions, it is considered a strong correlation. A strong correlation is one in which the two variables always, or almost always, go together. In the example of happiness and how good the month has been, the association is strong. The stronger a correlation is, the tighter the dots in the scatterplot will be arranged along a sloped line.
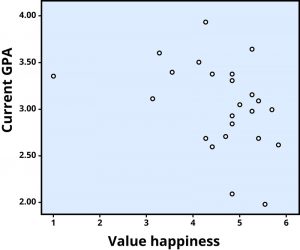
The r value of a strong correlation will have a high absolute value. In other words, you disregard whether there is a negative sign in front of the r value, and just consider the size of the numerical value itself. If the absolute value is large, it is a strong correlation. A weak correlation is one in which the two variables correspond some of the time, but not most of the time. Figure 3 shows the relation between valuing happiness and grade point average (GPA). People who valued happiness more tended to earn slightly lower grades, but there were lots of exceptions to this. The r value for a weak correlation will have a low absolute value. If two variables are so weakly related as to be unrelated, we say they are uncorrelated, and the r value will be zero or very close to zero. In the previous example, is the correlation between height and pathogen prevalence strong? Compared to Figure 3, the dots in Figure 2 are tighter and less dispersed. The absolute value of –.83 is large. Therefore, it is a strong negative correlation.
Can you guess the strength and direction of the correlation between age and year of birth? If you said this is a strong negative correlation, you are correct! Older people always have lower years of birth than younger people (e.g., 1950 vs. 1995), but at the same time, the older people will have a higher age (e.g., 65 vs. 20). In fact, this is a perfect correlation because there are no exceptions to this pattern. I challenge you to find a 10-year-old born before 2003! You can’t.
Problems with the correlation
If generosity and happiness are positively correlated, should we conclude that being generous causes happiness? Similarly, if height and pathogen prevalence are negatively correlated, should we conclude that disease causes shortness? From a correlation alone, we can’t be certain. For example, in the first case it may be that happiness causes generosity, or that generosity causes happiness. Or, a third variable might cause both happiness and generosity, creating the illusion of a direct link between the two. For example, wealth could be the third variable that causes both greater happiness and greater generosity. This is why correlation does not mean causation—an often repeated phrase among psychologists.
Qualitative Designs
Just as correlational research allows us to study topics we can’t experimentally manipulate (e.g., whether you have a large or small income), there are other types of research designs that allow us to investigate these harder-to-study topics. Qualitative designs, including participant observation, case studies, and narrative analysis are examples of such methodologies. Although something as simple as “observation” may seem like it would be a part of all research methods, participant observation is a distinct methodology that involves the researcher embedding him- or herself into a group in order to study its dynamics. For example, Festinger, Riecken, and Shacter (1956) were very interested in the psychology of a particular cult. However, this cult was very secretive and wouldn’t grant interviews to outside members. So, in order to study these people, Festinger and his colleagues pretended to be cult members, allowing them access to the behavior and psychology of the cult. Despite this example, it should be noted that the people being observed in a participant observation study usually know that the researcher is there to study them.
Another qualitative method for research is the case study, which involves an intensive examination of specific individuals or specific contexts. Sigmund Freud, the father of psychoanalysis, was famous for using this type of methodology; however, more current examples of case studies usually involve brain injuries. For instance, imagine that researchers want to know how a very specific brain injury affects people’s experience of happiness. Obviously, the researchers can’t conduct experimental research that involves inflicting this type of injury on people. At the same time, there are too few people who have this type of injury to conduct correlational research. In such an instance, the researcher may examine only one person with this brain injury, but in doing so, the researcher will put the participant through a very extensive round of tests. Hopefully what is learned from this one person can be applied to others; however, even with thorough tests, there is the chance that something unique about this individual (other than the brain injury) will affect his or her happiness. But with such a limited number of possible participants, a case study is really the only type of methodology suitable for researching this brain injury.
The final qualitative method to be discussed in this section is narrative analysis. Narrative analysis centers around the study of stories and personal accounts of people, groups, or cultures. In this methodology, rather than engaging with participants directly, or quantifying their responses or behaviors, researchers will analyze the themes, structure, and dialogue of each person’s narrative. That is, a researcher will examine people’s personal testimonies in order to learn more about the psychology of those individuals or groups. These stories may be written, audio-recorded, or video-recorded, and allow the researcher not only to study what the participant says but how he or she says it. Every person has a unique perspective on the world, and studying the way he or she conveys a story can provide insight into that perspective.
Quasi-Experimental Designs
What if you want to study the effects of marriage on a variable? For example, does marriage make people happier? Can you randomly assign some people to get married and others to remain single? Of course not. So how can you study these important variables? You can use a quasi-experimental design.

A quasi-experimental design is similar to experimental research, except that random assignment to conditions is not used. Instead, we rely on existing group memberships (e.g., married vs. single). We treat these as the independent variables, even though we don’t assign people to the conditions and don’t manipulate the variables. As a result, with quasi-experimental designs causal inference is more difficult. For example, married people might differ on a variety of characteristics from unmarried people. If we find that married participants are happier than single participants, it will be hard to say that marriage causes happiness, because the people who got married might have already been happier than the people who have remained single.
Because experimental and quasi-experimental designs can seem pretty similar, let’s take another example to distinguish them. Imagine you want to know who is a better professor: Dr. Smith or Dr. Khan. To judge their ability, you’re going to look at their students’ final grades. Here, the independent variable is the professor (Dr. Smith vs. Dr. Khan) and the dependent variable is the students’ grades. In an experimental design, you would randomly assign students to one of the two professors and then compare the students’ final grades. However, in real life, researchers can’t randomly force students to take one professor over the other; instead, the researchers would just have to use the preexisting classes and study them as-is (quasi-experimental design). Again, the key difference is random assignment to the conditions of the independent variable. Although the quasi-experimental design (where the students choose which professor they want) may seem random, it’s most likely not. For example, maybe students heard Dr. Smith sets low expectations, so slackers prefer this class, whereas Dr. Khan sets higher expectations, so smarter students prefer that one. This now introduces a confounding variable (student intelligence) that will almost certainly have an effect on students’ final grades, regardless of how skilled the professor is. So, even though a quasi-experimental design is similar to an experimental design (i.e., it has a manipulated independent variable), because there’s no random assignment, you can’t reasonably draw the same conclusions that you would with an experimental design.
Longitudinal Studies
Another powerful research design is the longitudinal study. Longitudinal studies track the same people over time. Some longitudinal studies last a few weeks, some a few months, some a year or more. Some studies that have contributed a lot to psychology followed the same people over decades. For example, one study followed more than 20,000 Germans for two decades. From these longitudinal data, psychologist Rich Lucas (2003) was able to determine that people who end up getting married indeed start off a bit happier than their peers who never marry. Longitudinal studies like this provide valuable evidence for testing many theories in psychology, but they can be quite costly to conduct, especially if they follow many people for many years.
Surveys

A survey is a way of gathering information, using old-fashioned questionnaires or the Internet. Compared to a study conducted in a psychology laboratory, surveys can reach a larger number of participants at a much lower cost. Although surveys are typically used for correlational research, this is not always the case. An experiment can be carried out using surveys as well. For example, King and Napa (1998) presented participants with different types of stimuli on paper: either a survey completed by a happy person or a survey completed by an unhappy person. They wanted to see whether happy people were judged as more likely to get into heaven compared to unhappy people. Can you figure out the independent and dependent variables in this study? Can you guess what the results were? Happy people (vs. unhappy people; the independent variable) were judged as more likely to go to heaven (the dependent variable) compared to unhappy people!
Likewise, correlational research can be conducted without the use of surveys. For instance, psychologists LeeAnn Harker and Dacher Keltner (2001) examined the smile intensity of women’s college yearbook photos. Smiling in the photos was correlated with being married 10 years later!
Tradeoffs in Research
Even though there are serious limitations to correlational and quasi-experimental research, they are not poor cousins to experiments and longitudinal designs. In addition to selecting a method that is appropriate to the question, many practical concerns may influence the decision to use one method over another. One of these factors is simply resource availability—how much time and money do you have to invest in the research? (Tip: If you’re doing a senior honor’s thesis, do not embark on a lengthy longitudinal study unless you are prepared to delay graduation!) Often, we survey people even though it would be more precise—but much more difficult—to track them longitudinally. Especially in the case of exploratory research, it may make sense to opt for a cheaper and faster method first. Then, if results from the initial study are promising, the researcher can follow up with a more intensive method.
Beyond these practical concerns, another consideration in selecting a research design is the ethics of the study. For example, in cases of brain injury or other neurological abnormalities, it would be unethical for researchers to inflict these impairments on healthy participants. Nonetheless, studying people with these injuries can provide great insight into human psychology (e.g., if we learn that damage to a particular region of the brain interferes with emotions, we may be able to develop treatments for emotional irregularities). In addition to brain injuries, there are numerous other areas of research that could be useful in understanding the human mind but which pose challenges to a true experimental design—such as the experiences of war, long-term isolation, abusive parenting, or prolonged drug use. However, none of these are conditions we could ethically experimentally manipulate and randomly assign people to. Therefore, ethical considerations are another crucial factor in determining an appropriate research design.
Research Methods: Why You Need Them
Research Matters
This video is an advertisement, so the scientific details are not at the threshold we would expect for this class. That said, this video shows the importance of curiosity and the drive to solve problems in research. If you are motivated to understand and solve problems, research is a tool you can use!
Check Your Knowledge
To help you with your studying, we’ve included some practice questions for this module. These questions do not necessarily address all content in this module. They are intended as practice, and you are responsible for all of the content in this module even if there is no associated practice question. To promote deeper engagement with the material, we encourage you to create some questions of your own for your practice. You can then also return to these self-generated questions later in the course to test yourself.
Vocabulary
Confounds
Factors that undermine the ability to draw causal inferences from an experiment.
Correlation
Measures the association between two variables, or how they go together.
Dependent variable
The variable the researcher measures but does not manipulate in an experiment.
Experimenter expectations
When the experimenter’s expectations influence the outcome of a study.
Independent variable
The variable the researcher manipulates and controls in an experiment.
Longitudinal study
A study that follows the same group of individuals over time.
Operational definitions
How researchers specifically measure a concept.
Participant demand
When participants behave in a way that they think the experimenter wants them to behave.
Placebo effect
When receiving special treatment or something new affects human behavior.
Quasi-experimental design
An experiment that does not require random assignment to conditions.
Random assignment
Assigning participants to receive different conditions of an experiment by chance.
References
- Chiao, J. (2009). Culture–gene coevolution of individualism – collectivism and the serotonin transporter gene. Proceedings of the Royal Society B, 277, 529-537. doi: 10.1098/rspb.2009.1650
- Dunn, E. W., Aknin, L. B., & Norton, M. I. (2008). Spending money on others promotes happiness. Science, 319(5870), 1687–1688. doi:10.1126/science.1150952
- Festinger, L., Riecken, H.W., & Schachter, S. (1956). When prophecy fails. Minneapolis, MN: University of Minnesota Press.
- Harker, L. A., & Keltner, D. (2001). Expressions of positive emotion in women\’s college yearbook pictures and their relationship to personality and life outcomes across adulthood. Journal of Personality and Social Psychology, 80, 112–124.
- King, L. A., & Napa, C. K. (1998). What makes a life good? Journal of Personality and Social Psychology, 75, 156–165.
- Lucas, R. E., Clark, A. E., Georgellis, Y., & Diener, E. (2003). Re-examining adaptation and the setpoint model of happiness: Reactions to changes in marital status. Journal of Personality and Social Psychology, 84, 527–539.
How to cite this Chapter using APA Style:
Scollon, C. N. (2019). Research designs. Adapted for use by Queen’s University. Original chapter in R. Biswas-Diener & E. Diener (Eds), Noba textbook series: Psychology.Champaign, IL: DEF publishers. Retrieved from http://noba.to/acxb2thy
Copyright and Acknowledgment:
This material is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. To view a copy of this license, visit: http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_US.
This material is attributed to the Diener Education Fund (copyright © 2018) and can be accessed via this link: http://noba.to/acxb2thy.
Additional information about the Diener Education Fund (DEF) can be accessed here.
These are rules that are learned early in life that specify the management and modification of emotional expressions according to social circumstances. Cultural display rules can work in a number of different ways. For example, they can require individuals to express emotions “as is” (i.e., as they feel them), to exaggerate their expressions to show more than what is actually felt, to tone down their expressions to show less than what is actually felt, to conceal their feelings by expressing something else, or to show nothing at all.
Siegler, R. S., & Ramani, G. B. (2009). Playing linear number board games—but not circular ones—improves low-income preschoolers’ numerical understanding. Journal of Educational Psychology, 101, 545–560.
Nelson, C. A., Thomas, K. M., & de Haan, M. (2006). Neural bases of cognitive development. In W. Damon & R. M. Lerner (Series Eds.) & D. Kuhn & R. S. Siegler (Vol. Eds.), Handbook of child psychology: Volume 2: Cognition, perception, and language (6th ed., pp. 3–57). Hoboken, NJ: Wiley.
Blakemore, S.-J., & Choudhury, S. (2006). Development of the adolescent brain: Implications for executive function and social cognition. Journal of Child Psychiatry and Psychology, 47, 296–312.
Dick, D. M., Meyers, J. L., Latendresse, S. J., Creemers, H. E., Lansford, J. E., … Huizink, A. C. (2011). CHRM2, parental monitoring, and adolescent externalizing behavior: Evidence for gene-environment interaction. Psychological Science, 22, 481–489.
Theory that development occurs through a sequence of discontinuous stages: the sensorimotor, preoperational, concrete operational, and formal operational stages.
This refers to the relationship or interaction between two or more individuals in a group. Thus, the interpersonal functions of emotion refer to the effects of one’s emotion on others, or to the relationship between oneself and others.
Theory founded in large part by Lev Vygotsky that emphasizes how other people and the attitudes, values, and beliefs of the surrounding culture influence children’s development.
Theories that focus on describing the cognitive processes that underlie thinking at any one age and cognitive growth over time.
Levenson, R. W., & Ruef, A. M. (1992). Empathy: A physiological substrate. Journal of Personality and Social Psychology, 63, 234–246.
The environments, starting with the womb, that influence all aspects of children’s development.
Booth, J. L., & Siegler, R. S. (2006). Developmental and individual differences in pure numerical estimation. Developmental Psychology, 41, 189–201.