2.2 DNA Structure and Function
Learning Objectives
- Describe the structure of DNA.
- Explain the process of DNA replication.
- Describe mechanisms of DNA repair.
- Explain the central dogma.
- Explain the main steps of transcription.
- Discuss why every cell does not express all of its genes.
- Identify how eukaryotic gene expression occurs at the epigenetic, transcriptional, post-transcriptional, translational, and post-translational levels.
- Describe the different steps in protein synthesis.
- Describe the genetic code and how the nucleotide sequence determines the amino acid and the protein sequence.
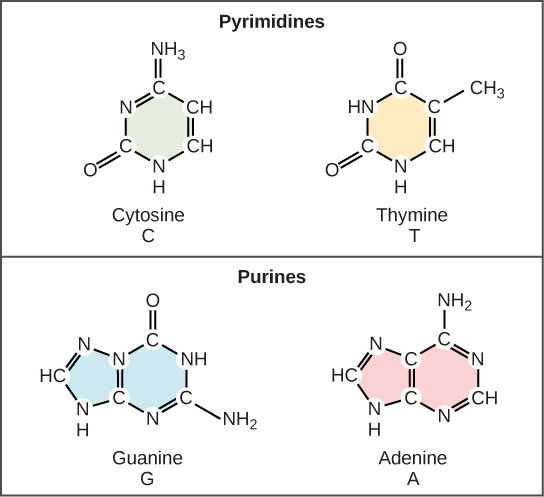
Let’s begin with a review the structure of the two types of nucleic acids, deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). The building blocks of DNA are nucleotides, which are made up of three parts: a deoxyribose (5-carbon sugar), a phosphate group, and a nitrogenous base (Figure 2.1). There are four types of nitrogenous bases in DNA. Adenine (A) and guanine (G) are double-ringed purines, and cytosine (C) and thymine (T) are smaller, single-ringed pyrimidines. The nucleotide is named according to the nitrogenous base it contains.
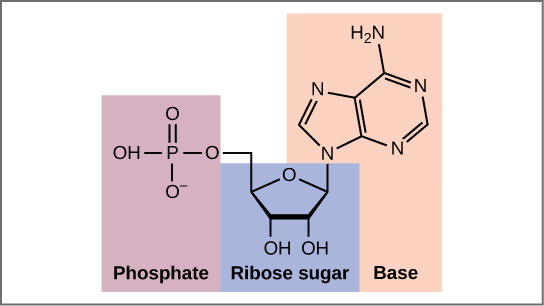
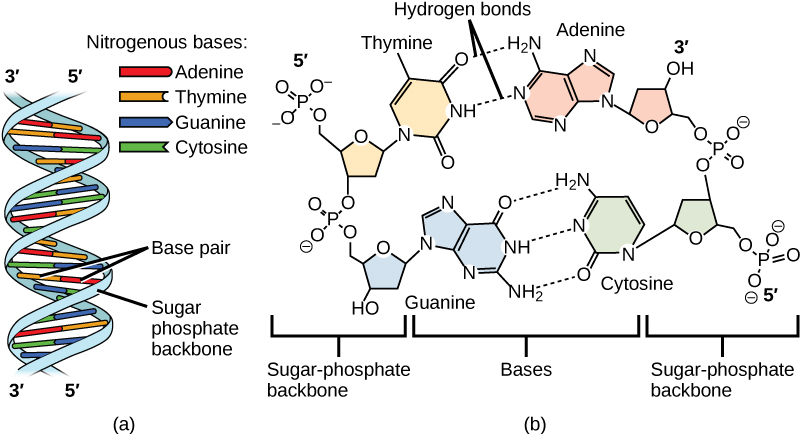
The phosphate group of one nucleotide bonds covalently with the sugar molecule of the next nucleotide, and so on, forming a long polymer of nucleotide monomers. The sugar–phosphate groups line up in a “backbone” for each single strand of DNA, and the nucleotide bases stick out from this backbone. The carbon atoms of the five-carbon sugar are numbered clockwise from the oxygen as 1′, 2′, 3′, 4′, and 5′ (1′ is read as “one prime”). The phosphate group is attached to the 5′ carbon of one nucleotide and the 3′ carbon of the next nucleotide. In its natural state, each DNA molecule is actually composed of two single strands held together along their length with hydrogen bonds between the bases.
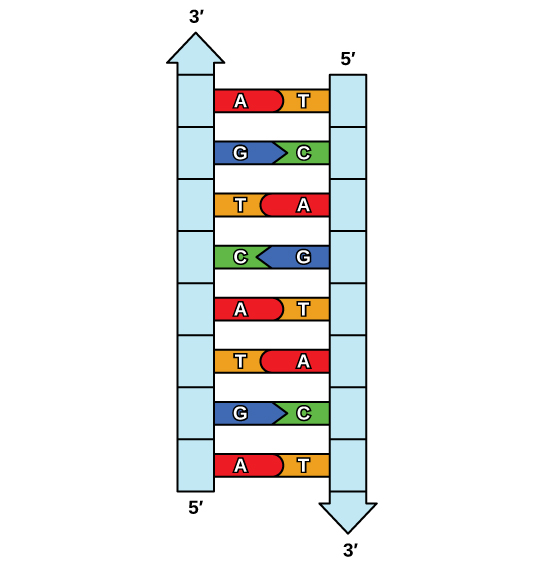
DNA is made up of two strands that are twisted around each other to form a right-handed helix, called a double helix. Base pairing occurs between a purine and pyrimidine: A pairs with T, and G pairs with C. In other words, adenine and thymine are complementary base pairs, and cytosine and guanine are complementary base pairs. This is the basis for Chargaff’s rule; because of their complementarity, there is as much adenine as thymine in a DNA molecule and as much guanine as cytosine. Two hydrogen bonds, connect adenine and thymine and cytosine and guanine are connected by three hydrogen bonds. The two strands are anti-parallel; one strand will have the 3′ carbon of the sugar in the “upward” position, whereas the other strand will have the 5′ carbon in the upward position. The diameter of the DNA double helix is uniform throughout because a purine (two rings) always pairs with a pyrimidine (one ring), and their combined lengths are always equal. (Figure 2.3).
The Structure of RNA
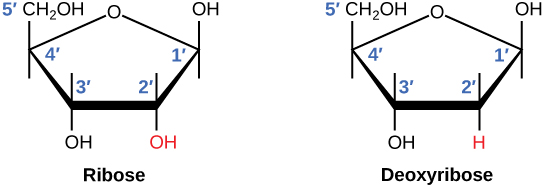
A second nucleic acid in all cells is called ribonucleic acid, or RNA. Like DNA, RNA is a polymer of nucleotides. Each of the nucleotides in RNA is made up of a nitrogenous base, a five-carbon sugar, and a phosphate group. In the case of RNA, the five-carbon sugar is ribose, not deoxyribose. Ribose has a hydroxyl group at the 2′ carbon, unlike deoxyribose, which has only a hydrogen atom (Figure 2.4).
RNA nucleotides contain the nitrogenous bases adenine, cytosine, and guanine. However, they do not contain thymine, which is replaced by uracil, symbolized by a “U.” RNA exists as a single-stranded molecule rather than a double-stranded helix. Molecular biologists have named several kinds of RNA based on their function. These include messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA)—molecules that are involved in the production of proteins from the DNA code.
How DNA Is Arranged in the Cell
DNA is a working molecule; it must be replicated when a cell is ready to divide, and it must be “read” to produce the molecules, such as proteins, to carry out the functions of the cell. For this reason, the DNA is protected and packaged in particular ways. In addition, DNA molecules can be very long. Stretched end-to-end, the DNA molecules in a single human cell would come to a length of about 2 meters. Thus, the DNA for a cell must be packaged in a very ordered way to fit and function within a structure (the cell) that is not visible to the naked eye.
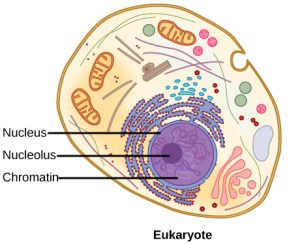
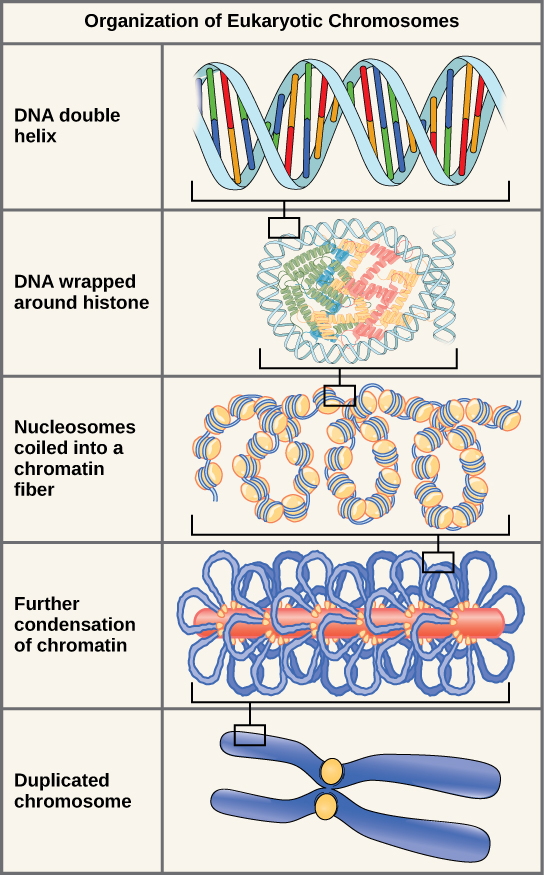
Eukaryotes, whose chromosomes each consist of a linear DNA molecule, have a specific packing strategy to fit their DNA inside the nucleus. At the most basic level, DNA is wrapped around proteins known as histones to form structures called nucleosomes. The DNA is wrapped tightly around the histone core. This nucleosome is linked to the next one by a short strand of DNA that is free of histones. This is also known as the “beads on a string” structure; the nucleosomes are the “beads,” and the short lengths of DNA between them are the “string.” With their DNA coiled around them, the nucleosomes stack compactly onto each other to form a 30-nm–wide fiber. This fibre is further coiled into a thicker and more compact structure. At the metaphase stage of mitosis, when the chromosomes are lined up in the center of the cell, the chromosomes are at their most compacted. They are approximately 700 nm in width, and are associated with scaffold proteins.
In interphase, the phase of the cell cycle between mitoses at which the chromosomes are decondensed, eukaryotic chromosomes have two distinct regions that can be distinguished by staining. There is a tightly packaged region that stains darkly and a less dense region. The darkly staining regions usually contain genes that are not active and are found in the centromere and telomere regions. The lightly staining regions usually contain active genes, with DNA packaged around nucleosomes but not further compacted.
Concept in Action – DNA
Use the interactive slideshow to review this concept in action, or access the videos and questions using the text version.
Concept in Action – DNA (text version)
Watch How DNA is Packaged (Advanced) (2 mins) on YouTube
Watch the video DNA is the Genetic Material (4 mins) on BCCampus and try the following knowledge check:
Pause the video at 1:55 and match the terms to the correct blanks for this statement:
Terms: copied, changes, encode
Genetic material must be able to [Blank A] information. Genetic material must be [Blank B] when cells divide. Mutations are [Blank C] to a DNA sequence.
Check your answer in footnote[1]
Activity source: Concept in Action – DNA by Andrea Gretchev is licensed under CC BY-NC 4.0, except where otherwise noted.
When a cell divides, each daughter cell must receive an identical copy of the DNA. The process of DNA replication accomplishes this. DNA replication occurs during the synthesis phase, or S phase, of the cell cycle before the cell enters mitosis or meiosis.
The elucidation of the structure of the double helix provided a hint as to how DNA is copied. Recall that adenine nucleotides pair with thymine nucleotides and cytosine with guanine. This means that the two strands are complementary to each other. For example, a strand of DNA with a nucleotide sequence of AGTCATGA will have a complementary strand with the sequence TCAGTACT (Figure 2.7).
Because of the complementarity of the two strands, having one strand makes it possible to recreate the other strand. This model for replication suggests that the two strands of the double helix separate during replication, and each strand serves as a template from which the new complementary strand is copied (Figure 2.8).
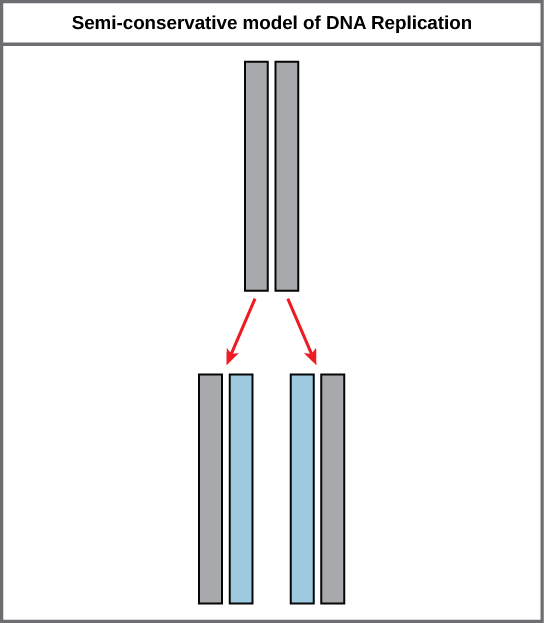
During DNA replication, each of the two strands that make up the double helix serves as a template from which new strands are copied. The new strand will be complementary to the parental or “old” strand. Each new double strand consists of one parental strand and one new daughter strand. This is known as semiconservative replication. When two DNA copies are formed, they have an identical sequence of nucleotide bases and are divided equally into two daughter cells.
DNA Replication in Eukaryotes
Because eukaryotic genomes are very complex, DNA replication is a very complicated process that involves several enzymes and other proteins. It occurs in three main stages: initiation, elongation, and termination.
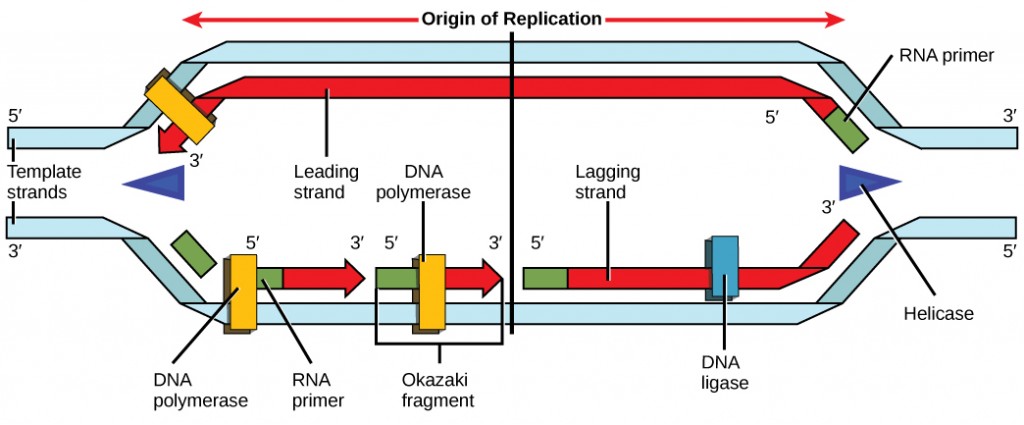
Recall that eukaryotic DNA is bound to proteins known as histones to form structures called nucleosomes. During initiation, the DNA is made accessible to the proteins and enzymes involved in the replication process. How does the replication machinery know where on the DNA double helix to begin? It turns out that there are specific nucleotide sequences called origins of replication at which replication begins. Certain proteins bind to the origin of replication while an enzyme called helicase unwinds and opens up the DNA helix. As the DNA opens up, Y-shaped structures called replication forks are formed (Figure 2.9). Two replication forks are formed at the origin of replication, which are extended in both directions as replication proceeds. There are multiple origins of replication on the eukaryotic chromosome, such that replication can occur simultaneously from several places in the genome.
During elongation, an enzyme called DNA polymerase adds DNA nucleotides to the 3′ end of the template. Because DNA polymerase can only add new nucleotides at the end of a backbone, a primer sequence, which provides this starting point, is added with complementary RNA nucleotides. This primer is removed later, and the nucleotides are replaced with DNA nucleotides. One strand, which is complementary to the parental DNA strand, is synthesized continuously toward the replication fork so the polymerase can add nucleotides in this direction. This continuously synthesized strand is known as the leading strand. Because DNA polymerase can only synthesize DNA in a 5′ to 3′ direction, the other new strand is put together in short pieces called Okazaki fragments. The Okazaki fragments each require a primer made of RNA to start the synthesis. The strand with the Okazaki fragments is known as the lagging strand. As synthesis proceeds, an enzyme removes the RNA primer, which is then replaced with DNA nucleotides, and the gaps between fragments are sealed by an enzyme called DNA ligase.
The process of DNA replication can be summarized as follows:
- DNA unwinds at the origin of replication.
- New bases are added to the complementary parental strands. One new strand is made continuously, while the other strand is made in pieces.
- Primers are removed, new DNA nucleotides are put in place of the primers and the backbone is sealed by DNA ligase.
Telomere Replication
Because eukaryotic chromosomes are linear, DNA replication comes to the end of a line in eukaryotic chromosomes. As you have learned, the DNA polymerase enzyme can add nucleotides in only one direction. In the leading strand, synthesis continues until the end of the chromosome is reached; however, on the lagging strand, there is no place for a primer to be made for the DNA fragment to be copied at the end of the chromosome. This presents a problem for the cell because the ends remain unpaired; over time, these ends get progressively shorter as cells continue to divide. The ends of the linear chromosomes are known as telomeres, which have repetitive sequences that do not code for a particular gene. As a consequence, it is telomeres that are shortened with each round of DNA replication instead of genes. For example, in humans, a six base-pair sequence, TTAGGG, is repeated 100 to 1000 times. The discovery of the enzyme telomerase (Figure 2.10) helped in the understanding of how chromosome ends are maintained. The telomerase attaches to the end of the chromosome, and complementary bases to the RNA template are added on the end of the DNA strand. Once the lagging strand template is sufficiently elongated, DNA polymerase can add nucleotides complementary to the ends of the chromosomes. Thus, the ends of the chromosomes are replicated.
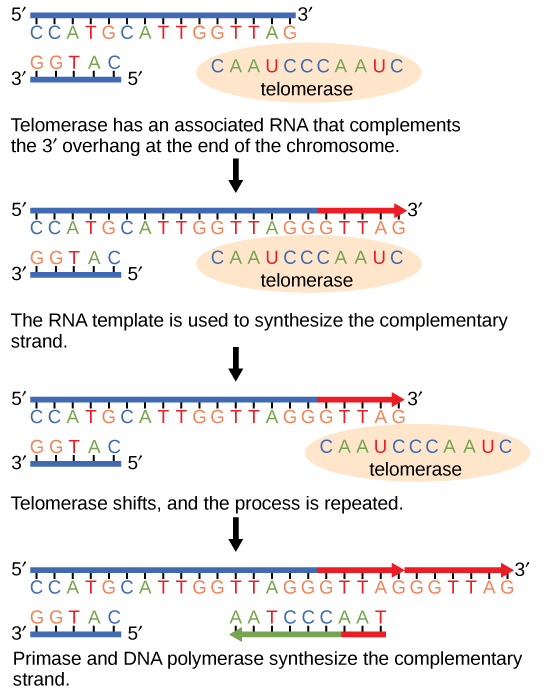
Telomerase is typically found to be active in germ cells, adult stem cells, and some cancer cells. Elizabeth Blackburn (Figure 2.11) received the Nobel Prize for Medicine and Physiology in 2009 for her discovery of telomerase and its action.

Telomerase is not active in adult somatic cells. Adult somatic cells that undergo cell division continue to have their telomeres shortened. This essentially means that telomere shortening is associated with aging. In 2010, scientists found that telomerase can reverse some age-related conditions in mice, which may have potential in regenerative medicine.[2] Telomerase-deficient mice were used in these studies; these mice have tissue atrophy, stem-cell depletion, organ system failure, and impaired tissue injury responses. Telomerase reactivation in these mice caused extension of telomeres, reduced DNA damage, reversed neurodegeneration, and improved functioning of the testes, spleen, and intestines. Thus, telomere reactivation may have the potential to treat age-related diseases in humans.
Concept in Action – DNA Replication
Watch DNA replication animation by interact Medical (1 min) on YouTube
Video source: Colucci, S. (2009, July 7). DNA replication animation by Interact Medical [Video]. YouTube. https://www.youtube.com/watch?v=zdDkiRw1PdU
DNA Repair
DNA polymerase can make mistakes while adding nucleotides. It edits the DNA by proofreading every newly added base. Incorrect bases are removed and replaced by the correct base, then polymerization continues (Figure 2.12 a). Most mistakes are corrected during replication, although the mismatch repair mechanism is employed when this does not happen. Mismatch repair enzymes recognize the wrongly incorporated base and excise it from the DNA, replacing it with the correct base (Figure 2.12 b). In yet another type of repair, nucleotide excision repair, the DNA double-strand is unwound and separated, the incorrect bases are removed along with a few bases on the 5′ and 3′ end, and these are replaced by copying the template with the help of DNA polymerase (Figure 2.12 c). Nucleotide excision repair is particularly important in correcting thymine dimers, which are primarily caused by ultraviolet light. In a thymine dimer, two thymine nucleotides adjacent to each other on one strand are covalently bonded to each other rather than their complementary bases. If the dimer is not removed and repaired, it will become a variant. Individuals with flaws in their nucleotide excision repair genes show extreme sensitivity to sunlight and develop skin cancers early in life.
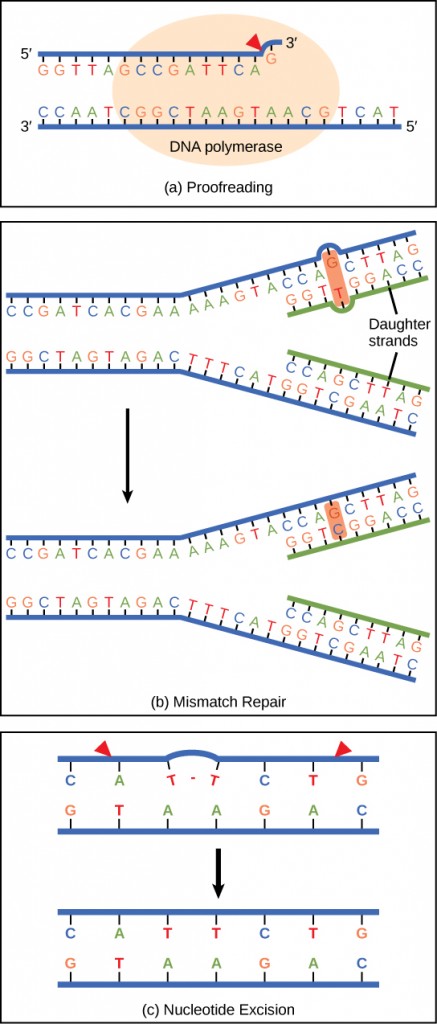
Most mistakes are corrected; if not, they may result in a variant—defined as a permanent change in the DNA sequence. Variants in repair genes may lead to serious consequences like cancer.
The second function of DNA (the first was replication) is to provide the information needed to construct the proteins necessary so that the cell can perform all of its functions. To do this, the DNA is “read” or transcribed into an mRNA molecule. The mRNA then provides the code to form a protein by a process called translation. Through the processes of transcription and translation, a protein is built with a specific sequence of amino acids that was originally encoded in the DNA. This module discusses the details of transcription.
The Central Dogma: DNA Encodes RNA; RNA Encodes Protein
The central dogma describes the flow of genetic information in cells from DNA to mRNA to protein (Figure 2.13), which states that genes specify the sequences of mRNAs, which in turn specify the sequences of proteins.
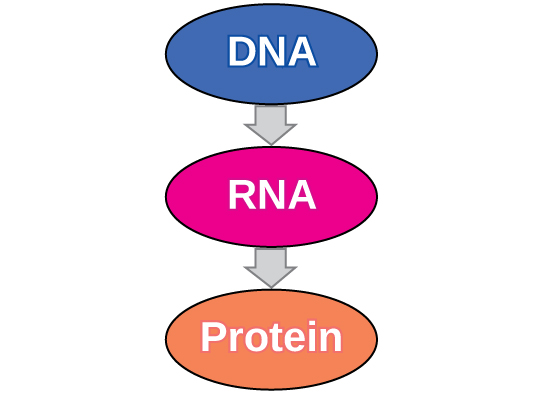
Copying DNA to mRNA is relatively straightforward, with one nucleotide being added to the mRNA strand for every complementary nucleotide read in the DNA strand. The translation to protein is more complex because groups of three mRNA nucleotides correspond to one amino acid of the protein sequence. However, as we shall see in the next module, the translation to protein is still systematic, such that nucleotides 1 to 3 correspond to amino acid 1, nucleotides 4 to 6 correspond to amino acid 2, and so on.
Transcription: from DNA to mRNA
In eukaryotes, the genes are bound in the nucleus, so transcription occurs in the nucleus of the cell and the mRNA transcript must be transported to the cytoplasm. Transcription occurs in three main stages: initiation, elongation, and termination.
Initiation
Transcription requires the DNA double helix to partially unwind in the region of mRNA synthesis. The region of unwinding is called a transcription bubble. The DNA sequence onto which the proteins and enzymes involved in transcription bind to initiate the process is called a promoter. In most cases, promoters exist upstream of the genes they regulate. The specific sequence of a promoter is very important because it determines whether the corresponding gene is transcribed all of the time, some of the time, or hardly at all (Figure 2.14).
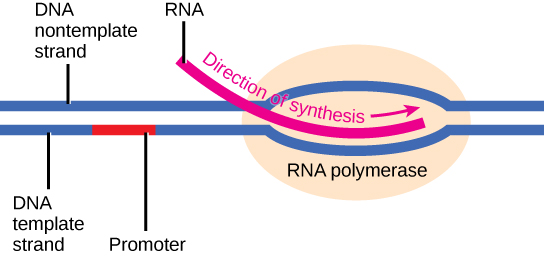
Elongation
Transcription always proceeds from one of the two DNA strands, which is called the template strand. The mRNA product is complementary to the template strand and is almost identical to the other DNA strand, called the non-template strand, except that RNA contains a uracil (U) in place of the thymine (T) found in DNA. During elongation, an enzyme called RNA polymerase proceeds along the DNA template adding nucleotides by base pairing with the DNA template in a manner similar to DNA replication, with the difference that an RNA strand is being synthesized that does not remain bound to the DNA template. As elongation proceeds, the DNA is continuously unwound ahead of the core enzyme and rewound behind it (Figure 2.15).
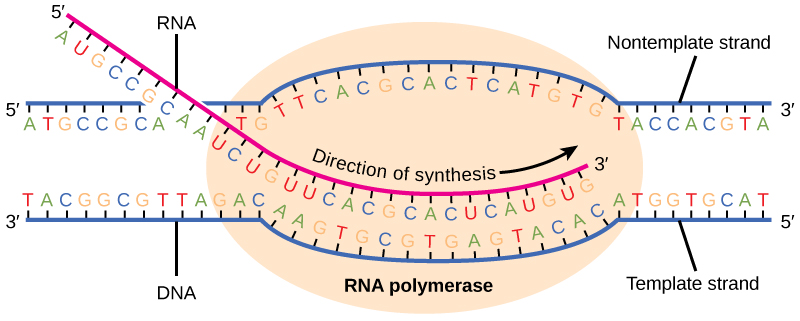
Termination
Depending on the gene being transcribed, there are two kinds of termination signals, but both involve repeated nucleotide sequences in the DNA template that result in RNA polymerase stalling, leaving the DNA template, and freeing the mRNA transcript. On termination, the process of transcription is complete.
Eukaryotic RNA Processing
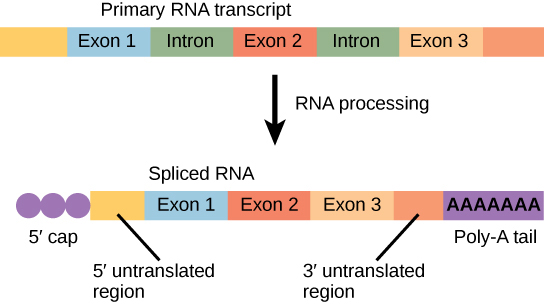
The newly transcribed eukaryotic mRNAs must undergo several processing steps before they can be transferred from the nucleus to the cytoplasm and translated into a protein. The mRNA transcript is first coated in RNA-stabilizing proteins to prevent it from degrading while it is processed and exported out of the nucleus. This occurs while the pre-mRNA is still being synthesized by adding a special nucleotide “cap” to the 5′ end of the growing transcript. In addition to preventing degradation, factors involved in protein synthesis recognize the cap to help initiate translation by ribosomes.
Once elongation is complete, an enzyme then adds a string of approximately 200 adenine residues to the 3′ end, called the poly-A tail. This modification further protects the pre-mRNA from degradation and signals to cellular factors that the transcript needs to be exported to the cytoplasm.
Eukaryotic genes are composed of protein-coding sequences called exons (ex-on signifies that they are expressed) and intervening sequences called introns (int-ron denotes their intervening role). Introns are removed from the pre-mRNA during processing. Intron sequences in mRNA do not encode functional proteins. It is essential that all of a pre-mRNA’s introns be completely and precisely removed before protein synthesis so that the exons join together to code for the correct amino acids. If the process errs by even a single nucleotide, the sequence of the rejoined exons would be shifted, and the resulting protein would be nonfunctional. The process of removing introns and reconnecting exons is called splicing (Figure 2.16). Introns are removed and degraded while the pre-mRNA is still in the nucleus.
The synthesis of proteins is one of a cell’s most energy-consuming metabolic processes. In turn, proteins account for more mass than any other component of living organisms (with the exception of water), and proteins perform a wide variety of the functions of a cell. Translation, or protein synthesis, involves decoding an mRNA message into a polypeptide product. Amino acids are covalently strung together in lengths ranging from approximately 50 amino acids to more than 1,000.
The Protein Synthesis Machinery
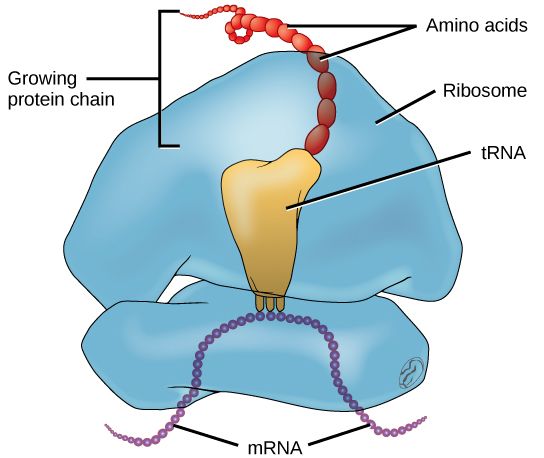
In addition to the mRNA template, many other molecules contribute to the process of translation. The composition of each component may vary across species; for instance, ribosomes may consist of different numbers of ribosomal RNAs (rRNA) and polypeptides, depending on the organism. However, the general structures and functions of the protein synthesis machinery are comparable to those of bacteria and human cells. Translation requires the input of an mRNA template, ribosomes, tRNAs, and various enzymatic factors (Figure 2.17).
In E. coli, there are 200,000 ribosomes present in every cell at any given time. A ribosome is a complex macromolecule composed of structural and catalytic rRNAs, and many distinct polypeptides. In eukaryotes, the nucleolus is completely specialized for the synthesis and assembly of rRNAs.
Ribosomes are located in the cytoplasm and endoplasmic reticulum of eukaryotes. Ribosomes are made up of a large and a small subunit that come together for translation. The small subunit is responsible for binding the mRNA template, whereas the large subunit sequentially binds tRNAs, a type of RNA molecule that brings amino acids to the growing chain of the polypeptide. Each mRNA molecule is simultaneously translated by many ribosomes, all synthesizing protein in the same direction.
Depending on the species, 40 to 60 types of tRNA exist in the cytoplasm. Serving as adaptors, specific tRNAs bind to sequences on the mRNA template and add the corresponding amino acid to the polypeptide chain. Therefore, tRNAs are the molecules that actually “translate” the language of RNA into the language of proteins. For each tRNA to function, it must have its specific amino acid bonded to it. In the process of tRNA “charging,” each tRNA molecule is bonded to its correct amino acid.
The Genetic Code
Use the interactive slides to watch two videos and check your knowledge, or access the text version of the activity below.
The Genetic Code (text version)
Watch the video: Universality of the Genetic Code (5 mins) on BCCampus.
- After watching the first video fill in the missing words in the following statement:
There are [Blank A] different ways to arrange 4 bases of DNA i groups of [Blank B].
Since there are 20 amino acids there are more than one codon for each amino acid. This makes the genetic code [Blank C].
Watch the video: Mutations (5 mins) on BCCampus
- Pause at 2:01. True or false? DNA can have mutations occur spontaneously.
- Pause at 3:33. True or false? Agents that cause mutations are rarely cancer causing as well.
Check your answers in footnote[3]
Activity source: Concepts of Biology – 1st Canadian Edition, CC BY 4.0
To summarize what we know to this point, the cellular process of transcription generates messenger RNA (mRNA), a mobile molecular copy of one or more genes with an alphabet of A, C, G, and uracil (U). Translation of the mRNA template converts nucleotide-based genetic information into a protein product. Protein sequences consist of 20 commonly occurring amino acids; therefore, it can be said that the protein alphabet consists of 20 letters. Each amino acid is defined by a three-nucleotide sequence called the triplet codon. The relationship between a nucleotide codon and its corresponding amino acid is called the genetic code.
Given the different numbers of “letters” in the mRNA and protein “alphabets,” combinations of nucleotides corresponded to single amino acids. Using a three-nucleotide code means that there are a total of 64 (4 × 4 × 4) possible combinations; therefore, a given amino acid is encoded by more than one nucleotide triplet (Figure 2.18).
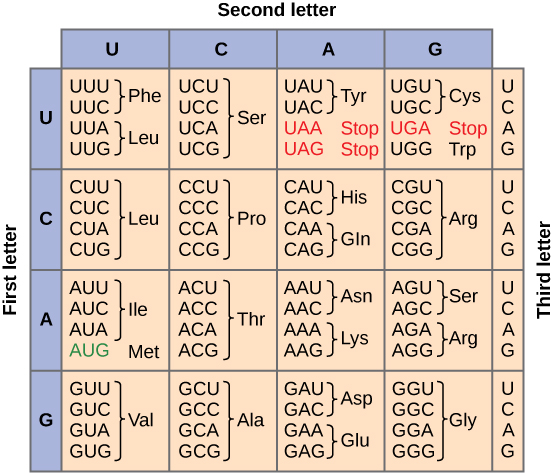
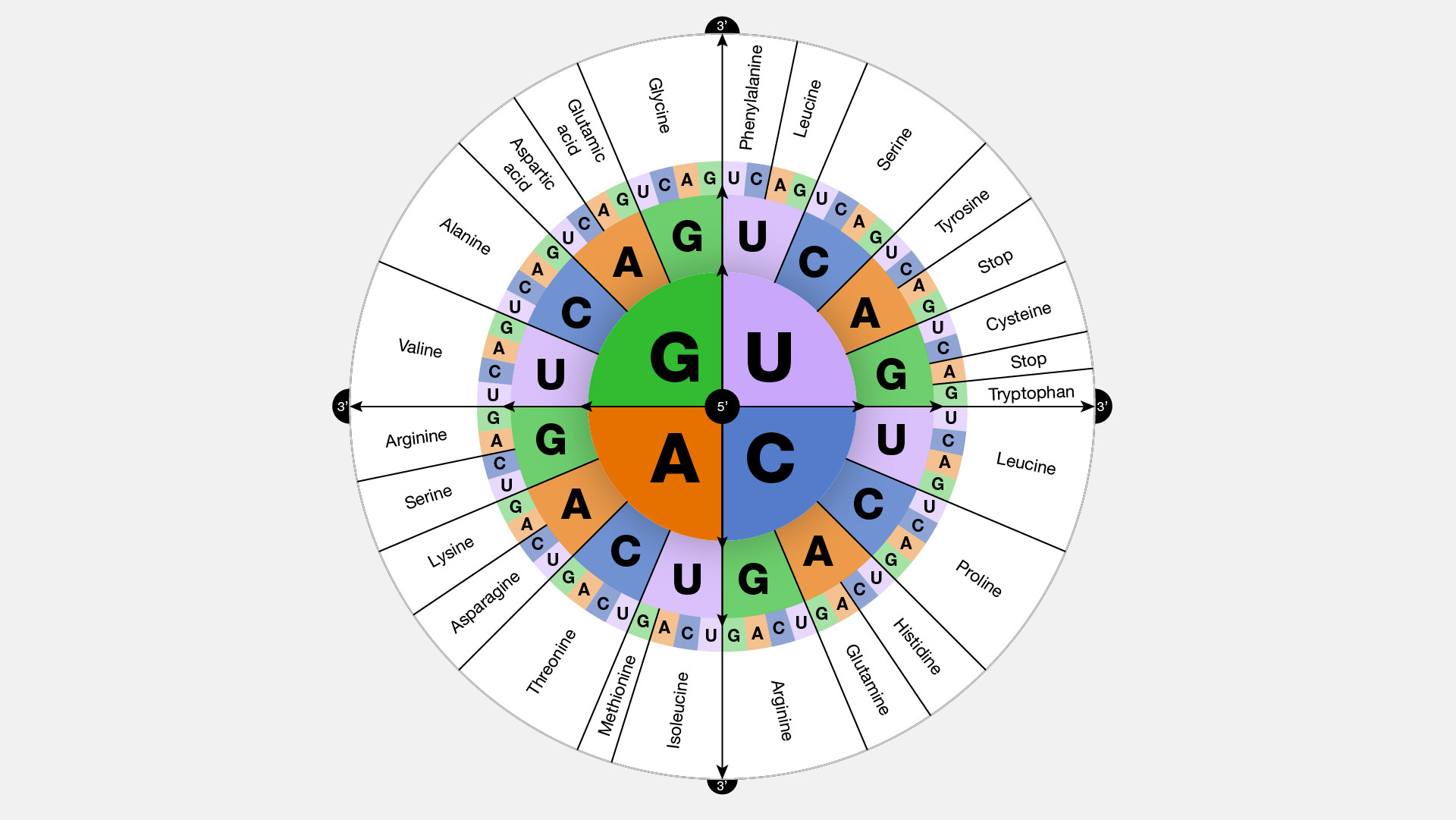
Three of the 64 codons terminate protein synthesis and release the polypeptide from the translation machinery. These triplets are called stop codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also serves as the start codon to initiate translation. The reading frame for translation is set by the AUG start codon near the 5′ end of the mRNA. The genetic code is universal. With a few exceptions, virtually all species use the same genetic code for protein synthesis, which is powerful evidence that all life on Earth shares a common origin.
The Mechanism of Protein Synthesis
Just as with mRNA synthesis, protein synthesis can be divided into three phases: initiation, elongation, and termination. Here we will explore how translation occurs in E. coli, a representative prokaryote, and specify any differences between prokaryotic and eukaryotic translation.
Protein synthesis begins with the formation of an initiation complex. In E. coli, this complex involves the small ribosome subunit, the mRNA template, three initiation factors, and a special initiator tRNA. The initiator tRNA interacts with the AUG start codon, and links to a special form of the amino acid methionine that is typically removed from the polypeptide after translation is complete.
In prokaryotes and eukaryotes, the basics of polypeptide elongation are the same, so we will review elongation from the perspective of E. coli. The large ribosomal subunit of E. coli consists of three compartments: the A site binds incoming charged tRNAs (tRNAs with their attached specific amino acids). The P site binds charged tRNAs carrying amino acids that have formed bonds with the growing polypeptide chain but have not yet dissociated from their corresponding tRNA. The E site releases dissociated tRNAs so they can be recharged with free amino acids. The ribosome shifts one codon at a time, catalyzing each process that occurs in the three sites. With each step, a charged tRNA enters the complex, the polypeptide becomes one amino acid longer, and an uncharged tRNA departs. The energy for each bond between amino acids is derived from GTP, a molecule similar to ATP (Figure 2.19). Amazingly, the E. coli translation apparatus takes only 0.05 seconds to add each amino acid, meaning that a 200-amino acid polypeptide could be translated in just 10 seconds.
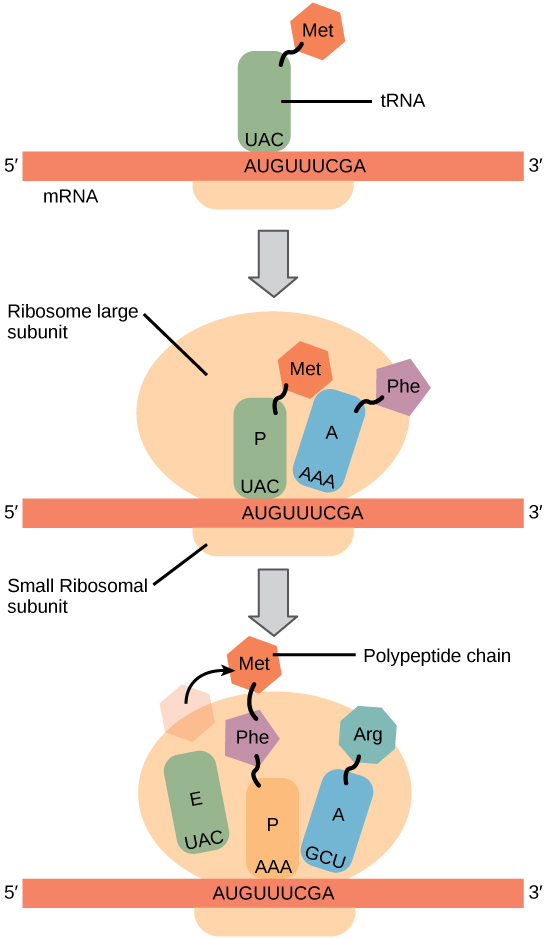
Termination of translation occurs when a stop codon (UAA, UAG, or UGA) is encountered. When the ribosome encounters the stop codon, the growing polypeptide is released and the ribosome subunits dissociate and leave the mRNA. After many ribosomes have completed translation, the mRNA is degraded so the nucleotides can be reused in another transcription reaction.
Concept in Action – Transcribe a gene
Visit the Learn Genetics website to transcribe a gene and translate it to protein using complementary pairing and the genetic code .
For a cell to function properly, necessary proteins must be synthesized at the proper time. All organisms and cells control or regulate the transcription and translation of their DNA into protein. The process of turning on a gene to produce RNA and protein is called gene expression. Whether in a simple unicellular organism or in a complex multicellular organism, each cell controls when and how its genes are expressed. For this to occur, there must be a mechanism to control when a gene is expressed to make RNA and protein, how much of the protein is made, and when it is time to stop making that protein because it is no longer needed.
Cells in multicellular organisms are specialized; cells in different tissues look very different and perform different functions. For example, a muscle cell is very different from a liver cell, which is very different from a skin cell. These differences are a consequence of the expression of different sets of genes in each of these cells. All cells have certain basic functions they must perform for themselves, such as converting the energy in sugar molecules into energy in ATP. Each cell also has many genes that are not expressed, and expresses many that are not expressed by other cells, such that it can carry out its specialized functions. In addition, cells will turn on or off certain genes at different times in response to changes in the environment or at different times during the development of the organism. Unicellular organisms, also turn on and off genes in response to the demands of their environment so that they can respond to special conditions.
The control of gene expression is extremely complex. Malfunctions in this process are detrimental to the cell and can lead to the development of many diseases, including cancer.
Eukaryotic Gene Expression
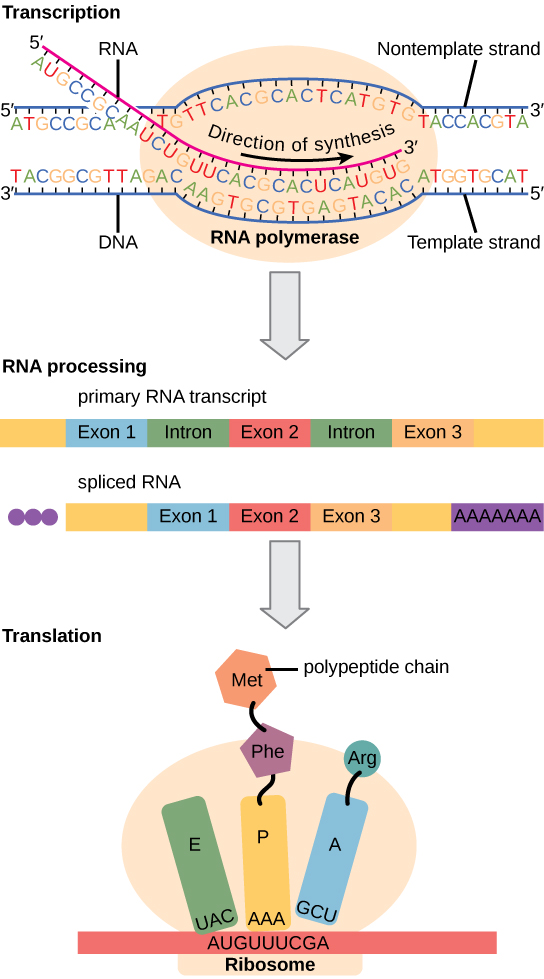
To understand how gene expression is regulated, we must first understand how a gene becomes a functional protein in a cell. Eukaryotic cells have intracellular organelles and are complex. Recall that in eukaryotic cells, the DNA is contained inside the cell’s nucleus and it is transcribed into mRNA there. The newly synthesized mRNA is then transported out of the nucleus into the cytoplasm, where ribosomes translate the mRNA into protein. The processes of transcription and translation are physically separated by the nuclear membrane; transcription occurs only within the nucleus, and translation only occurs outside the nucleus in the cytoplasm. The regulation of gene expression can occur at all stages of the process (Figure 2.20). Regulation may occur when the DNA is uncoiled and loosened from nucleosomes to bind transcription factors (epigenetic level), when the RNA is transcribed (transcriptional level), when RNA is processed and exported to the cytoplasm after it is transcribed (post-transcriptional level), when the RNA is translated into protein (translational level), or after the protein has been made (post-translational level).
Alternative RNA Splicing
In the 1970s, genes were first observed that exhibited alternative RNA splicing. Alternative RNA splicing is a mechanism that allows different protein products to be produced from one gene when different combinations of introns (and sometimes exons) are removed from the transcript (Figure 2.21). This alternative splicing can be haphazard, but more often it is controlled and acts as a mechanism of gene regulation, with the frequency of different splicing alternatives controlled by the cell as a way to control the production of different protein products in different cells, or at different stages of development. Alternative splicing is now understood to be a common mechanism of gene regulation in eukaryotes; according to one estimate, 70% of genes in humans are expressed as multiple proteins through alternative splicing.
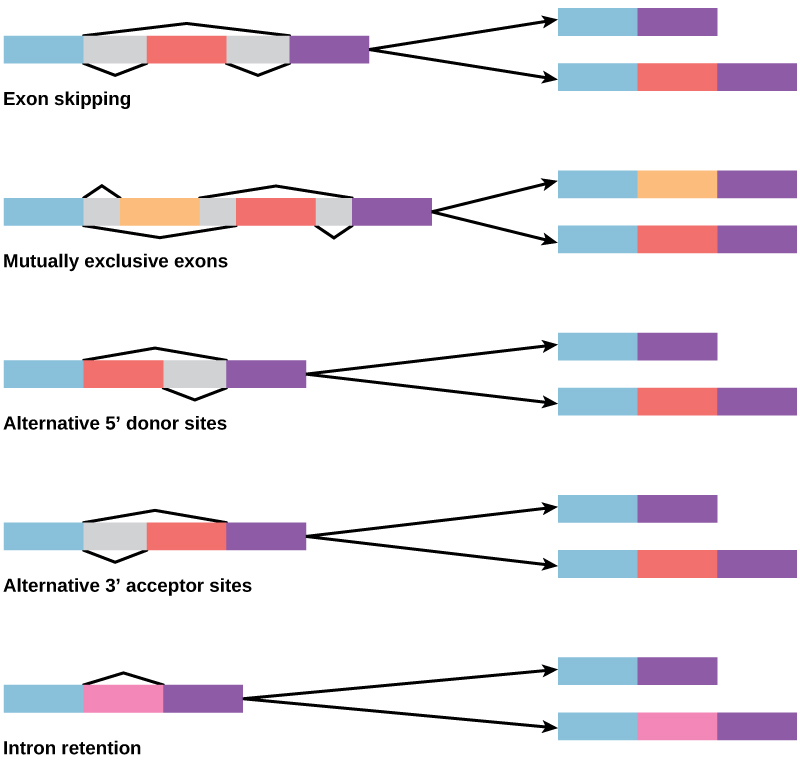
How could alternative splicing evolve? Introns have a beginning and ending recognition sequence, and it is easy to imagine the failure of the splicing mechanism to identify the end of an intron and find the end of the next intron, thus removing two introns and the intervening exon. In fact, there are mechanisms in place to prevent such exon skipping, but variants are likely to lead to their failure. Such “mistakes” would more than likely produce a nonfunctional protein. Indeed, the cause of many genetic diseases is alternative splicing rather than variants in a sequence. However, alternative splicing would create a protein variant without the loss of the original protein, opening up possibilities for adaptation of the new variant to new functions. Gene duplication has played an important role in the evolution of new functions in a similar way—by providing genes that may evolve without eliminating the original functional protein.
Exercises
True or false? Nucleotides are made up of three parts: a base, ribose sugar, and phosphate.
Fill in the blanks in the following statements:
a. The letters of the 4 nucleotides are [Blank 1] and [Blank 2] and [Blank 3] and [Blank 4].
b. The base pairing rules are the A always pairs with [Blank 1] and [Blank 2] always pairs with [Blank 3].
DNA replication is said to be [Blank 1]- conservative.
The enzyme that is crucial in copying DNA strands is called [Blank 1].
The central dogma of molecular biology is:
DNA——1——– arrow to mRNA—2—- arrow to Protein.
The number that represents Translation is [Blank 1]. The number that represents Transcription is [Blank 2].
Since (with a few exceptions) all organisms use the same genetic code, it is said to be [Blank 1].
DNA functions to provide the information needed to construct [Blank 1]*Protein/Proteins/protein/Protein*.
Which of the following does cytosine pair with?
guanine
thymine
adenine
a pyrimidine
How are chromosomes arranged and packaged in a eukaryotic cell (select all that apply)?
double-stranded, linear
single-stranded, circular
wrapped around histones
wrapped around nucleosomes
Match the words to the correct blank to describe the organization of the eukaryotic chromosome.
Words: histones, interphase, fibre, euchromatin, metaphase, heterochromatin
The DNA is wound around proteins called [Blank A]. These proteins then stack together in a compact form that creates a [Blank B]*fiber* 30-nm thick that is further coiled for greater compactness. During [Blank C] of mitosis, the *chromosome* is at its most compact to facilitate *chromosome* movement. During [Blank D]*interphase*, there are denser areas of chromatin, called [Blank E]*heterochromatin*, that contain DNA that is not expressed, and less dense [Blank F]*euchromatin* that contains DNA that is expressed.
Match the words to the correct blank to describe the structure and complementary base pairing of DNA.
Words: double helix, adenine/thymine, two strands, cytosine/guanine, phosphate group, cytosine/guanine, nucleic acids, nitrogenous, covalently, deoxyribose sugar, hydrogen
A single strand of DNA is a polymer of [Blank A] joined [Blank B] between the [Blank C] of one and the [Blank D] of the next to form a “backbone” from which the [Blank E] bases stick out. In its natural state, DNA has [Blank F] wound around each other in a [Blank G]. The bases on each strand are bonded to each other with [Blank H] bonds. Only specific bases bond with each other; [Blank i] bonds with [Blank J], and [Blank K] bonds with [Blank L].
Fill in the missing word to complete the statement.
You isolate a cell strain in which the joining together of Okazaki fragments is impaired and suspect that a mutation has occurred in an enzyme found at the replication fork. The enzyme most likely to be altered is [Blank A], as this enzyme joins together Okazaki fragments.
DNA replicates by which of the following models?
conservative
semiconservative
dispersive
none of the above
What is the initial mechanism for repairing nucleotide errors in DNA?
mismatch repair
DNA polymerase proofreading
nucleotide excision repair
thymine dimers
True or false? The linear chromosomes in eukaryotes ensure that its ends are replicated completely because telomerase has an inbuilt RNA template that extends the 3′ end, so a primer is synthesized and extended, and the ends are protected.
What is a promoter?
a specific sequence of DNA nucleotides
a protein that binds to DNA
an enzyme that synthesizes RNA
a specific sequence of RNA nucleotides
What is the term for the portions of eukaryotic mRNA sequence that are removed during RNA processing?
exons
caps
poly-A tails
introns
Where are the RNA components of ribosomes synthesized?
cytoplasm
nucleus
nucleolus
endoplasmic reticulum
How long would the peptide be that is translated from this mRNA sequence: 5′-AUGGGCUACCGA-3′?
0
2
3
4
At what level(s) does the control of gene expression occur in eukaryotic cells?
only the transcriptional level
epigenetic and transcriptional levels
epigenetic, transcriptional, and translational levels
epigenetic, transcriptional, post-transcriptional, translational, and post-translational levels
What does post-translational control refer to?
the regulation of gene expression after transcription
the regulation of gene expression after translation
the control of epigenetic activation
the period between transcription and translation
Match the words into the correct blanks to describe how controlling gene expression will alter the overall protein levels in the cell.
Words: decrease, stages, Prokaryotic, Eukaryotic, translation, lifespan, Eukaryotic, increase, amount, Prokaryotic,
The cell controls which protein is expressed, and to what level that protein is expressed, in the cell. [Blank A] cells alter the transcription rate to turn genes on or off. This method will [Blank B] or [Blank C] protein levels in response to what is needed by the cell. [Blank D] cells change the accessibility (epigenetic), transcription, or translation of a gene. This will alter the [Blank E] and [Blank F] of RNA, to alter how much protein exists. These cells also change the protein’s [Blank G] to increase or decrease its overall levels. [Blank H] organisms are much more complex than [Blank i] organisms and can manipulate protein levels by changing many [Blank J] in the process.
Check your answers in footnote[4]
Activity source: Exercises by Andrea Gretchev is licensed under CC BY-NC 4.0, except where otherwise noted. Rearranged from Concepts of Biology – 1st Canadian Edition
Attribution & References
Except where otherwise noted, content on this page is adapted from 9.1 The Structure of DNA, 9.2 DNA Replication, 9.3 Transcription, 9.4 Translation, and 9.5 How Genes Are Regulated In Concepts of Biology – 1st Canadian Edition by Charles Molnar and Jane Gair, CC BY 4.0. A derivative of Concepts of Biology (OpenStax), CC BY 4.0. Access Concepts of Biology for free at OpenStax / Adaptations: Individual sections have been combined and streamlined, including minor edits to improve student understanding and provide context.
- A - encode, B - copied, C - changes ↵
- Mariella Jaskelioff, et al., “Telomerase reactivation reverses tissue degeneration in aged telomerase-deficient mice,” Nature, 469 (2011):102– ↵
- 1. A - 64, B - 3, C - redundant. 2. True. 3. False. ↵
- True. . a. 1: A/G/T/C/a/t/g/c; 2: A/G/T/C/a/t/g/c; 3: A/G/T/C/a/t/g/c; 4: A/G/T/C/a/t/g/c. b. 1: T/t; 2: G/g; 3: C/c c. 1. semi d. 1. DNA polymerase/DNA Polymerase/dna polymerase*. e. 1: 2, 2: 1. f. 1. universal g. Protein/Proteins/protein/Protein a) guanine a) double-stranded, linear A - histones, B - Fiber, C - metaphase, D - interphase, E - heterochromatin, F - euchromatin A - nucleic acids, B - covalently, C - phosphate group, D - deoxyribose sugar, E - nitrogenous, F - two strands, G - double helix, H - hydrogen, i - adenine/thymine, J - adenine/thymine, K - cytosine/guanine, L - cytosine/guanine. a. Ligase/ligase b. semiconservative b. DNA polymerase proofreading True. a. a specific sequence of DNA nucleotides d. introns c. nucleolus d. 4 epigenetic, transcriptional, post-transcriptional, translational, and post-translational levels b. the regulation of gene expression after translation A - Prokaryotic, B - increase, C - decrease, D - Eukaryotic, E - amount, F - lifespan, G - translation, H - Eukaryotic, i - Prokaryotic, J - stages ↵
a five-carbon sugar molecule with a hydrogen atom rather than a hydroxyl group in the 2' position; the sugar component of DNA nucleotides
a nitrogen-containing molecule that acts as a base; often referring to one of the purine or pyrimidine components of nucleic acids
the molecular shape of DNA in which two strands of nucleotides wind around each other in a spiral shape
transfer RNA; an RNA molecule that contains a specific three-nucleotide anticodon sequence to pair with the mRNA codon and also binds to a specific amino acid
ribosomal RNA; molecules of RNA that combine to form part of the ribosome
the method used to replicate DNA in which the double-stranded molecule is separated and each strand acts as a template for a new strand to be synthesized, so the resulting DNA molecules are composed of one new strand of nucleotides and one old strand of nucleotides
an enzyme that helps to open up the DNA helix during DNA replication by breaking the hydrogen bonds
an enzyme that synthesizes a new strand of DNA complementary to a template strand
the strand that is synthesized continuously in the 5' to 3' direction that is synthesized in the direction of the replication fork
during replication of the 3' to 5' strand, the strand that is replicated in short fragments and away from the replication fork
the enzyme that catalyzes the joining of DNA fragments together
the DNA at the end of linear chromosomes
an enzyme that contains a catalytic part and an inbuilt RNA template; it functions to maintain telomeres at chromosome ends
a form of DNA repair in which non-complementary nucleotides are recognized, excised, and replaced with correct nucleotides
a form of DNA repair in which the DNA molecule is unwound and separated in the region of the nucleotide damage, the damaged nucleotides are removed and replaced with new nucleotides using the complementary strand, and the DNA strand is resealed and allowed to rejoin its complement
three consecutive nucleotides in mRNA that specify the addition of a specific amino acid or the release of a polypeptide chain during translation
Genetic code refers to the instructions contained in a gene that tell a cell how to make a specific protein. Each gene’s code uses the four nucleotide bases of DNA: adenine (A), cytosine (C), guanine (G) and thymine (T) — in various ways to spell out three-letter “codons” that specify which amino acid is needed at each position within a protein.
one of the three mRNA codons that specifies termination of translation
the AUG (or, rarely GUG) on an mRNA from which translation begins; always specifies methionine
processes that control whether a gene is expressed
describing non-genetic regulatory factors, such as changes in modifications to histone proteins and DNA that control accessibility to genes in chromosomes
a post-transcriptional gene regulation mechanism in eukaryotes in which multiple protein products are produced by a single gene through alternative splicing combinations of the RNA transcript
